
O fluxo de dados nesta tabela é um pouco complicado de seguir, então aqui está um gráfico equivalente que representa a tabela como um gráfico:

Arredonde o custo do supervegi burrito El Farolito para $ 8, assim na entrega no valor de $ 2, o valor total será de $ 20.
Oh, eu esqueci completamente! Um dos meus amigos não chega para um burrito, ele precisa de dois. Então, eu realmente quero pedir três. Se atualizado
Num Burritos
, o mecanismo de planilha ingênua pode recalcular todo o documento recalculando as células sem nenhuma entrada primeiro e, em seguida, recalculando cada célula com a entrada pronta até que as células se esgotem. Nesse caso, primeiro calcularemos o preço e a quantidade do burrito, depois o preço do burrito para remessa e um novo total de $ 30.

Essa estratégia simples de recalcular um documento inteiro pode parecer um desperdício, mas na verdade é melhor do que o VisiCalc, a primeira planilha de todos os tempos e o primeiro aplicativo matador que popularizou os computadores Apple II. O VisiCalc recalculou as células da esquerda para a direita e de cima para baixo várias vezes, examinando-as continuamente, embora nenhuma delas tenha mudado. Apesar desse algoritmo "interessante", o VisiCalc permaneceu como o software de planilha principal por quatro anos. Seu reinado terminou em 1983, quando o Lotus 1-2-3 assumiu o controle do mercado de recálculo de ordem natural. É assim que Tracy Robnett Licklider o descreveu na revista Byte :
O Lotus 1-2-3 usava ordenação natural, embora também suportasse os modos de linha e colunar VisiCalc. O recálculo natural manteve uma lista de dependências de células e células recalculadas com base nas dependências.
O Lotus 1-2-3 implementou a estratégia de recalcular todas as mostradas acima. Durante a primeira década de desenvolvimento da planilha, essa foi a abordagem ideal. Sim, recalculamos todas as células do documento, mas apenas uma vez.
Mas e o preço de um burrito com entrega
Mesmo. No meu exemplo com três burritos, não há razão para recalcular o preço de um burrito com entrega, porque alterar a quantidade de burritos no pedido não pode afetar o preço do burrito. Em 1989, um dos concorrentes da Lotus descobriu isso e criou o SuperCalc5, presumivelmente com o nome da teoria do super burrito por trás do algoritmo. SuperCalc5 recalculou "apenas células que dependem das células alteradas", então a atualização da contagem de burritos foi algo assim:
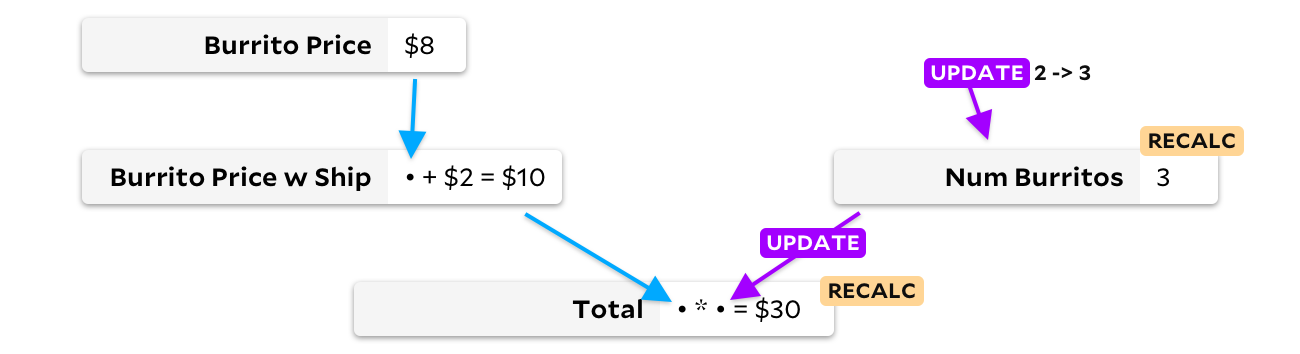
Ao atualizar a célula apenas quando os dados de entrada mudam, podemos evitar o recálculo do preço do burrito com entrega. Nesse caso, salvaremos apenas uma adição, mas em planilhas grandes a economia pode ser muito mais significativa! Infelizmente, temos um problema diferente agora. Digamos que meus amigos agora queiram burritos de carne, que são um dólar mais caros, e El Farolito adiciona $ 2 ao pedido, independentemente da quantidade de burritos. Antes de recalcular algo, vamos olhar o gráfico:
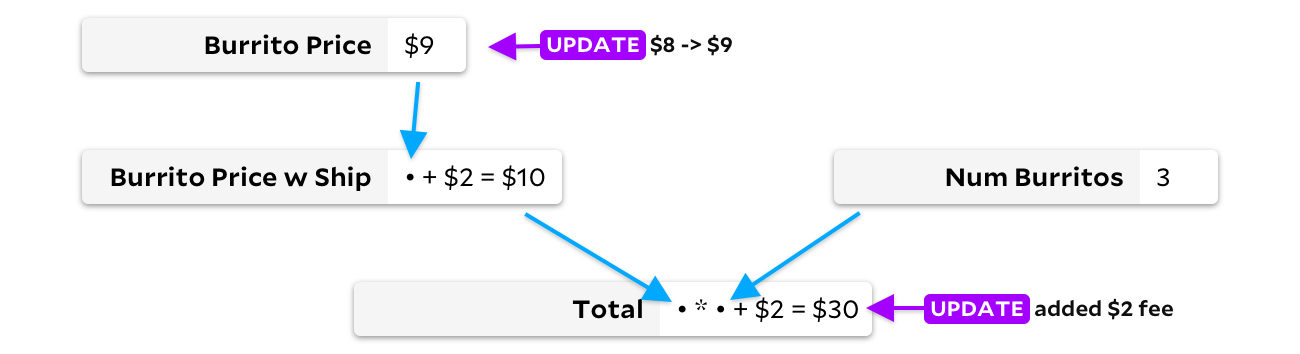
Como existem duas células atualizando aqui, temos um problema. Você deve recalcular o preço de um burrito primeiro ou o total? O ideal é que primeiro calculemos o preço do burrito, observemos a alteração, depois recalculemos o preço do burrito para envio e, finalmente, recalculemos o Total. No entanto, se, em vez disso, recalcularmos o total primeiro, teremos que recalculá-lo uma segunda vez, assim que o novo preço do burrito de $ 9 se espalhar pelas células. Se não computarmos as células na ordem correta, este algoritmo não é melhor do que recalcular o documento inteiro. Tão lento quanto o VisiCalc em alguns casos!
Obviamente, é importante determinarmos a ordem correta de atualização das células. Em geral, existem duas soluções para esse problema: marcação suja e classificação topológica.
A primeira solução envolve rotular todas as células a jusante da célula atualizada. Eles estão marcados como sujos. Por exemplo, quando atualizamos o preço de um burrito, marcamos as células downstream
Burrito Price w Ship
e
Total
, antes de fazer qualquer recálculo:
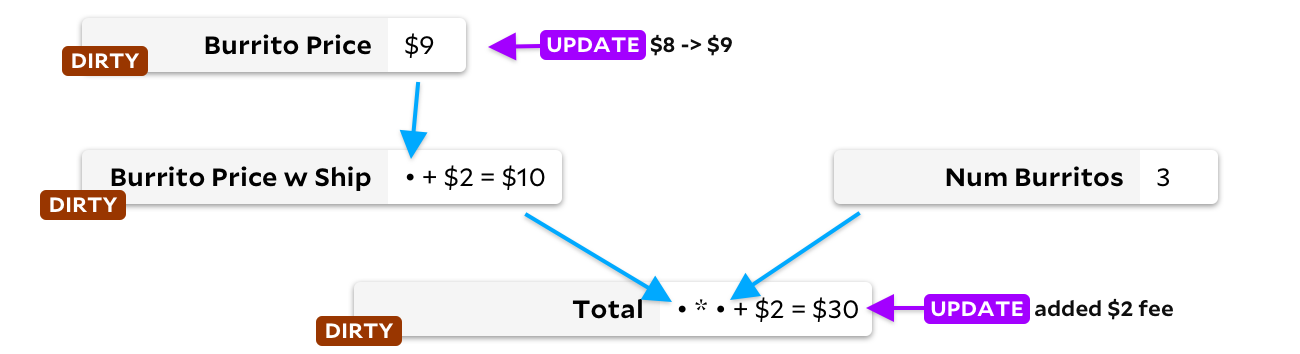
Então, em um loop, encontramos uma célula suja sem entradas sujas - e recalculamos. Quando não houver mais células sujas, pronto! Isso resolve nosso problema de dependência. No entanto, há uma desvantagem - se a célula for recalculada e descobrirmos que o novo resultado é o mesmo que o anterior, iremos recalcular as células subordinadas de qualquer maneira! Um pouco de lógica extra ajudará a evitar o problema, mas infelizmente ainda perdemos tempo marcando células e removendo marcações.
A segunda solução é a classificação topológica. Se uma célula não tem entrada, marcamos sua altura como 0. Se tiver, marcamos a altura como o máximo das células de entrada mais uma. Isso garante que cada célula tenha um valor de altura maior do que qualquer uma das células de entrada, então simplesmente rastreamos todas as células com a entrada alterada, sempre escolhendo a célula com a altura mais baixa para recalcular primeiro:
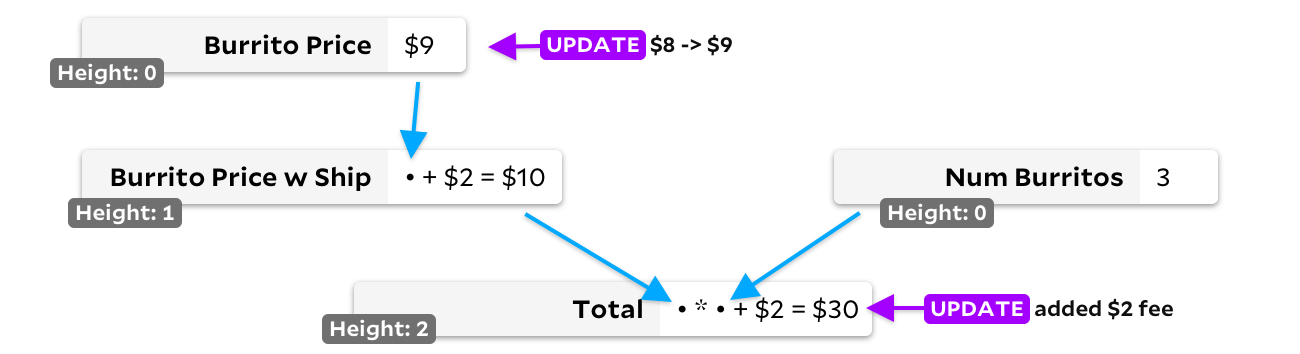
Em nosso exemplo de atualização dupla, o preço do burrito e o valor total será inicialmente adicionado ao heap de conversão. O preço do burrito é menor e será recalculado primeiro. Como o resultado mudou, adicionaremos o preço do burrito de entrega à pilha de recálculo, e uma vez que também tem uma altura menor que
Total
então será recalculado antes de finalmente recontarmos
Total
.
Isso é muito melhor do que a primeira solução: nenhuma célula é marcada como suja, a menos que uma das células de entrada realmente mude. No entanto, isso requer que as células sejam mantidas em ordem de classificação com recálculo pendente. Quando usado no heap, isso resulta em desaceleração
O(n log n)
, que é assintoticamente mais lenta no pior caso do que a estratégia recalculada do Lotus 1-2-3.
O Excel moderno usa uma combinação de contaminação e classificação topológica ; consulte a documentação para obter detalhes.
Avaliação preguiçosa
Agora, mais ou menos alcançamos os algoritmos de recálculo nas planilhas modernas. Suspeito que, em princípio, não haja justificativa comercial para novas melhorias, infelizmente. As pessoas já escreveram fórmulas do Excel suficientes para tornar a migração para qualquer outra plataforma impossível. Felizmente, não tenho experiência em negócios, portanto, consideraremos outras melhorias de qualquer maneira.
Além do armazenamento em cache, um dos aspectos interessantes de um gráfico computacional no estilo planilha é que só podemos computar as células nas quais estamos interessados. Isso às vezes é conhecido como avaliação lenta ou computação orientada pela demanda. Como um exemplo mais específico, aqui está um gráfico de planilha burrito ligeiramente expandido. O exemplo é igual ao anterior, mas adicionamos o que é melhor descrito como “cálculo de salsa”. Cada burrito contém 40 gramas de salsa e fazemos uma multiplicação rápida para descobrir a quantidade de salsa de todo o pedido. Já que temos três burritos em nosso pedido, vamos ter um total de 120 gramas de molho.

Claro, os leitores mais exigentes já perceberam o problema: o peso total da salsa em um pedido é uma métrica bastante inútil. Quem se importa se são 120 gramas? O que devo fazer com essas informações? Infelizmente, uma planilha típica gasta ciclos em cálculos de salsa, mesmo se não precisarmos desses cálculos na maioria das vezes.
É aqui que o recálculo preguiçoso pode ajudar. Se de alguma forma indicarmos que estamos interessados apenas no resultado
Total
, poderíamos recalcular essa célula, suas dependências e não tocar na salsa. Vamos chamá-la de célula
Total
observada , pois estamos tentando observar seu resultado. Também podemos chamar
Total
três de suas dependências de necessárias.células, uma vez que são necessárias para calcular alguma célula observada.
Salsa In Order
e
Salsa Per Burrito
chamá-lo de desnecessário .
Para resolver esse problema, alguns dos colegas de equipe do Rust criaram o framework Salsa , nomeando-o explicitamente com base no cálculo desnecessário de salsa que desperdiçava seus ciclos de computador. Certamente eles podem explicar melhor do que eu como funciona. De maneira geral, a estrutura usa números de revisão para controlar se uma célula precisa de recálculo. Qualquer mutação em uma fórmula ou entrada aumenta o número de revisão global, e cada célula rastreia duas revisões:
verified_at
para a revisão cujo resultado foi atualizado e
changed_at
para a revisão cujo resultado foi realmente alterado.
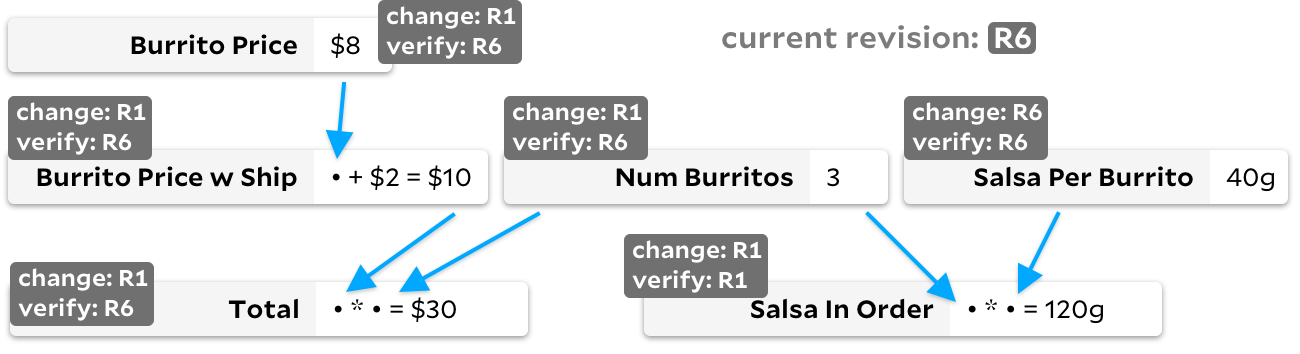
Quando o usuário indica que precisa de um novo valor
Total
, primeiro recursivamente recalculamos todas as células necessárias para
Total
, pulando as células onde a revisão
last_updated
é igual à revisão global. Depois que as dependências são
Total
atualizadas, nós reexecutamos a fórmula real
Total
apenas se o preço do Burrito for enviado ou tiver uma
Num Burrito
revisão
changed_at
maior que a revisão marcada
Total
... Isso é ótimo para Salsa em analisador de ferrugem, onde a simplicidade é importante e cada célula é demorada para calcular. No entanto, no gráfico com o burrito acima, você pode notar as desvantagens - se ele
Salsa Per Burrito
mudar constantemente, nosso número de revisão global frequentemente aumentará. Como resultado, cada observação
Total
exigiria atravessar três células, mesmo que nenhuma delas mudasse. Nenhuma fórmula será recalculada, mas se o gráfico for grande, iterar por todas as dependências da célula pode ser caro.
Opções mais rápidas para avaliação preguiçosa
Em vez de inventar novos algoritmos preguiçosos, vamos tentar os dois algoritmos de planilha clássicos mencionados anteriormente: rotulagem e classificação topológica. Como você pode imaginar, o modelo preguiçoso complica essas duas tarefas, mas ambas ainda são viáveis.
Vejamos primeiro a rotulagem. Como antes, quando alteramos a fórmula de uma célula, marcamos todas as células downstream como sujas. Portanto, ao atualizar,
Salsa Per Burrito
terá a seguinte aparência:

Mas, em vez de recalcular imediatamente todas as células sujas, esperamos até que o usuário observe a célula. Em seguida, executamos o algoritmo Salsa nele, mas em vez de verificar novamente as dependências com números de versão desatualizados
verified_at
, verificamos novamente apenas as células marcadas como sujas. Adapton usa essa técnica . Em tal situação, a observação da célula
Total
revela que ela não está suja e, portanto, podemos pular a passagem do gráfico que a Salsa teria realizado!
Se você observá-lo
Salsa In Order
, ele será marcado como sujo e, portanto, iremos verificar e recalcular e
Salsa Per Burrito
, e
Salsa In Order
. Mesmo aqui, há vantagens sobre o uso apenas de números de revisão, pois podemos pular recursivamente em uma célula ainda em branco
Num Burritos
.
A rotulagem suja preguiçosa funciona de forma fantástica, mudando frequentemente o conjunto de células que estamos tentando observar. Infelizmente, ele tem as mesmas desvantagens do algoritmo de marcação sujo anterior. Se uma célula com muitas células downstream muda, passamos muito tempo marcando e desmarcando as células, mesmo que a entrada não mude de fato quando formos para o recálculo. No pior caso, cada mudança leva ao fato de que marcamos todo o gráfico como sujo, o que nos dá aproximadamente a mesma ordem de desempenho que o algoritmo Salsa.
Além de rotulagem confusa, também podemos adaptar a classificação topológica para avaliação preguiçosa. Este método usa a biblioteca Incrementalda Jane Street, e são necessários alguns truques sérios para fazê-lo funcionar corretamente. Antes de implementar a avaliação preguiçosa, nosso algoritmo de classificação topológica usou um heap para determinar qual célula recalcular a seguir. Mas agora queremos recalcular apenas as células que são necessárias. Quão? Não queremos percorrer a árvore inteira a partir das células observadas, como Adapton, uma vez que uma caminhada completa pela árvore destrói todo o propósito da classificação topológica e nos dá características de desempenho semelhantes a Adapton.
Em vez disso, o Incremental mantém um conjunto de células que o usuário marcou como monitoradas, bem como o conjunto de células necessárias para qualquer célula monitorada. Sempre que uma célula é marcada como observável ou inobservável, Incremental percorre as dependências dessa célula para garantir que os rótulos necessários sejam aplicados corretamente. Em seguida, adicionamos células ao heap de recálculo apenas se forem marcadas conforme necessário. Em nosso gráfico de burrito, desde que faça
Total
parte de um conjunto observável, a mudança
Salsa in Order
não resultará em nenhuma passagem pelo gráfico, já que apenas as células necessárias são recalculadas:

Isso resolve nosso problema sem percorrer ansiosamente o gráfico para marcar as células como sujas! Devemos ainda lembrar que o celular
Salsa per Burrito
é complicado contar mais tarde, se necessário. Mas, ao contrário do algoritmo de Adapton, não precisamos empurrar aquele único rótulo sujo para baixo em todo o gráfico.
Âncoras, uma solução híbrida
Tanto o Adapton quanto o Incremental percorrem o gráfico, mesmo que não recalculem as células. Incremental sobe no gráfico quando o conjunto de células observadas muda e Adapton desce no gráfico quando a fórmula muda. Com gráficos pequenos, o alto custo dessas passagens pode não ser imediatamente aparente. Mas se o gráfico for grande e as células forem relativamente baratas para computar - geralmente é o caso das planilhas - você descobrirá que a maior parte do cálculo é desperdiçada em andar desnecessariamente pelo gráfico! Quando as células são baratas, marcar um bit em uma célula pode custar quase o mesmo que simplesmente recalcular uma célula do zero. Portanto, idealmente, se quisermos que nosso algoritmo seja significativamente mais rápido do que um cálculo simples, devemos evitar andar desnecessariamente pelo gráfico tanto quanto possível.
Quanto mais eu pensava sobre esse problema, mais percebia que eles estavam perdendo tempo percorrendo o gráfico em situações praticamente opostas. Em nosso gráfico de burrito, vamos imaginar que as fórmulas das células raramente mudam, mas mudamos rapidamente, observando primeiro
Total
e depois
Salsa in Order
.
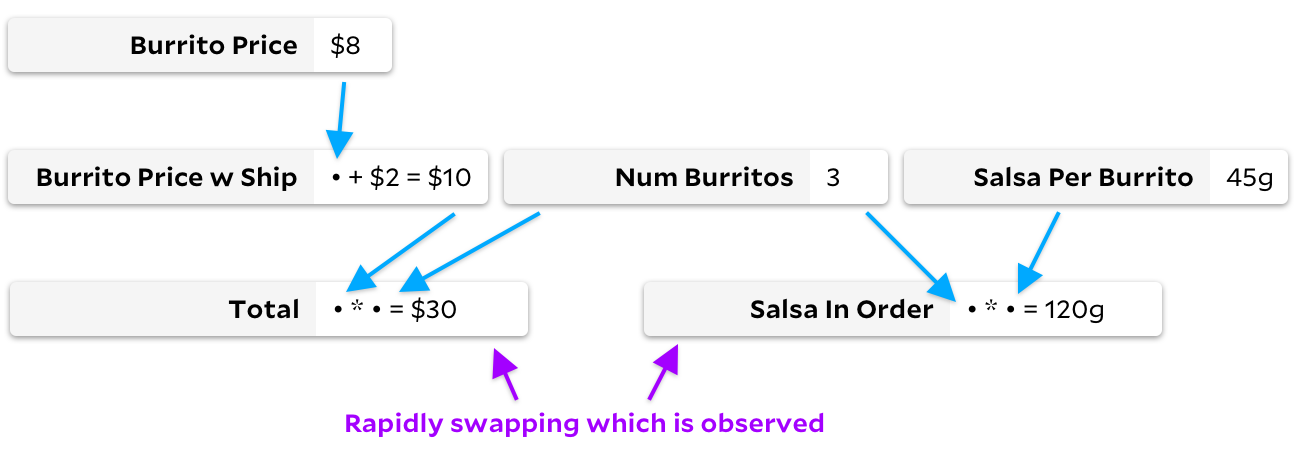
Nesse caso, Adapton não andará na árvore. Nenhum dos dados de entrada muda e, portanto, não precisamos marcar nenhuma célula. Como nada é sinalizado, cada observação é barata porque podemos retornar imediatamente o valor em cache de uma célula em branco. No entanto, Incremental não tem um bom desempenho neste exemplo. Embora nenhum valor seja recalculado, Incremental marcará e desmarcará repetidamente muitas células conforme necessário ou desnecessário.
Do contrário, vamos imaginar um gráfico em que nossas fórmulas mudam rapidamente, mas não mudamos a lista de células observadas. Por exemplo, podemos nos imaginar assistindo
Total
, alterando rapidamente o preço de um burrito de
4+4
para
2*4
.
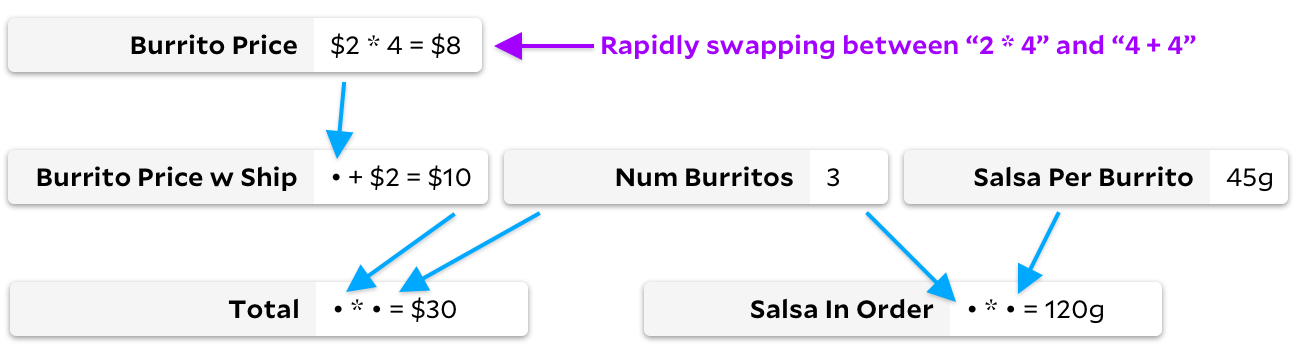
Como no exemplo anterior, não recalculamos muitas células:
4+4
e
2*4
é igual a
8
, então o ideal é que apenas recalculemos essa aritmética quando o usuário fizer essa alteração. Mas, ao contrário do exemplo anterior, Incremental agora evita andar na árvore. Com o Incremental, armazenamos em cache o fato de que o preço do burrito é uma célula necessária, portanto, quando ele mudar, podemos recalculá-lo sem passar pelo gráfico. Com o Adapton, perdemos tempo marcando
Burrito Price w Ship
e
Total
confuso, mesmo que o resultado
Burrito Price
não mude.
Dado que cada algoritmo funciona bem nos casos degenerados do outro, por que não apenas detectar esses casos degenerados e mudar para um algoritmo mais rápido? Isso é o que tentei implementar em minha própria biblioteca Âncoras . Ele executa os dois algoritmos simultaneamente no mesmo gráfico! Se parece louco, desnecessário e muito complicado, provavelmente é porque é.
Em muitos casos, as âncoras seguem exatamente o algoritmo Incremental, evitando assim o caso de Adapton degenerado acima. Mas quando as células são marcadas como não observáveis, seu comportamento diverge ligeiramente. Vamos ver o que está acontecendo. Vamos começar marcando-a
Total
como uma célula observada:
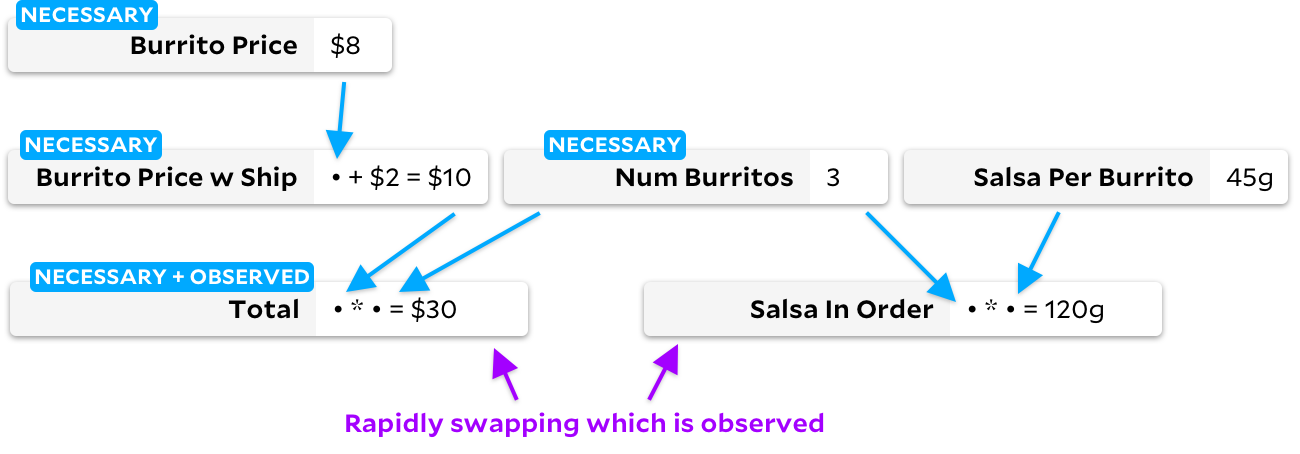
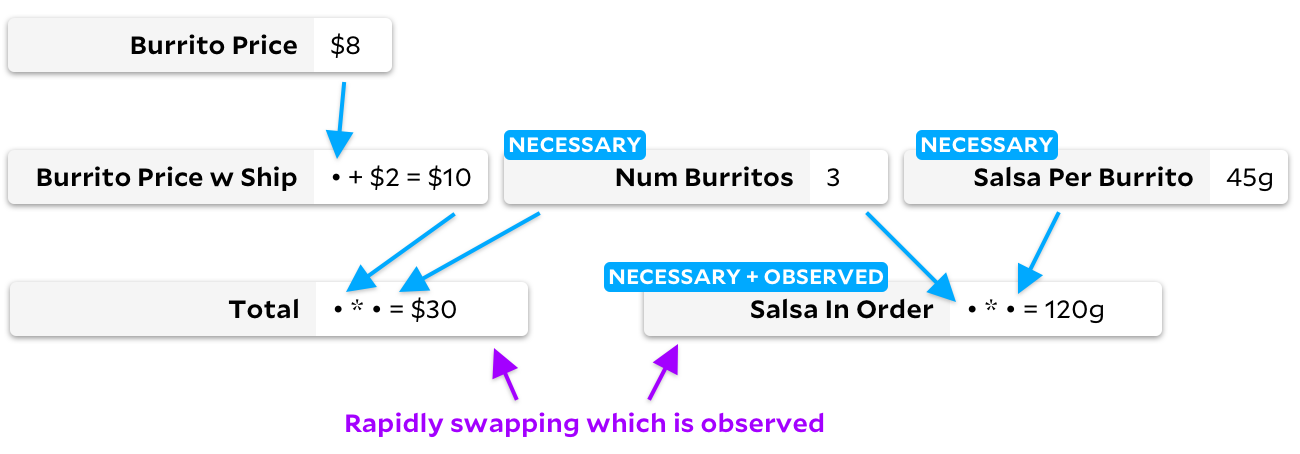
Se você a marcar
Total
como uma célula não observável e
Salsa in Order
como observável, o algoritmo Incremental tradicional mudará o gráfico, passando por todas as células no processo:
Âncoras para esta mudança também ignoram todas as células, mas cria outro gráfico:
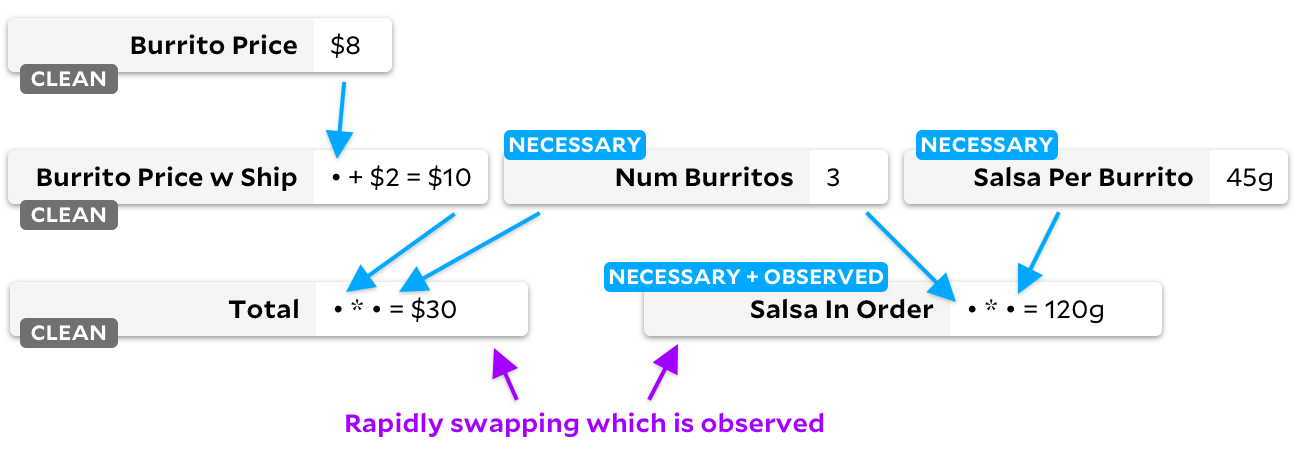
Preste atenção nas bandeiras das células "limpas"! Quando uma célula não é mais necessária, nós a marcamos como em branco. Vamos ver o que acontece quando passamos da observação
Salsa in Order
para
Total
:
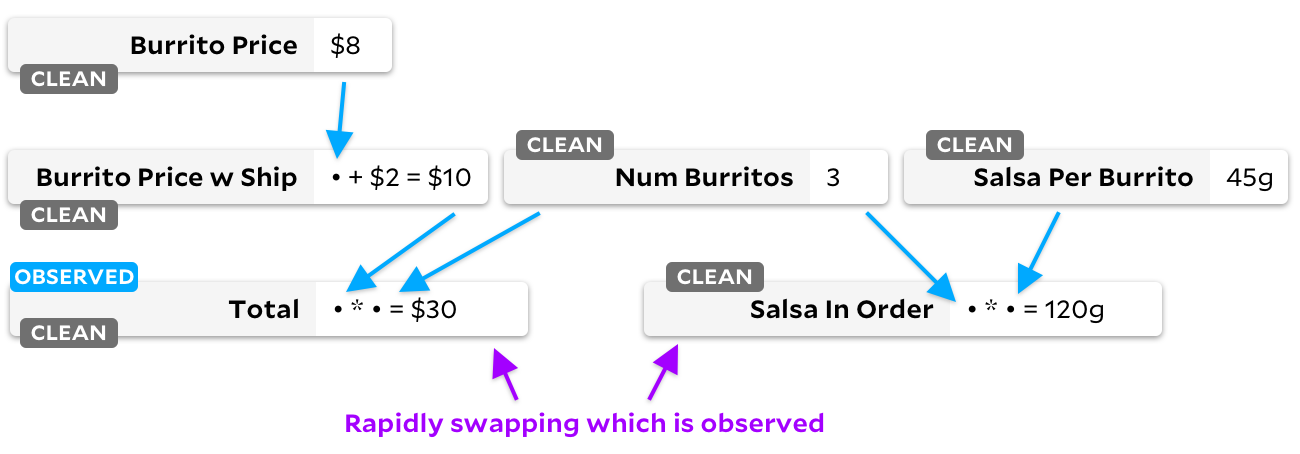
Certo - nosso gráfico agora não tem células "necessárias". Se uma célula tiver um sinalizador "limpo", nunca a marcamos como observável. De agora em diante, não importa qual célula marcarmos como observável ou inobservável, Anchors nunca perderá tempo percorrendo o gráfico - ela sabe que nenhuma das entradas mudou.
Parece que El Farolito anunciou um desconto! Vamos reduzir o preço do burrito em um dólar. Como as âncoras sabem recalcular o valor? Antes de qualquer recálculo, vejamos como Anchors vê o gráfico imediatamente após as mudanças de preço do burrito:

Se a célula tiver um sinalizador claro, executamos o algoritmo Adapton tradicional nela, marcando voluntariamente as células downstream como sujas. Quando mais tarde executamos o algoritmo Incremental, podemos dizer rapidamente que há uma célula observável marcada como suja e sabemos que precisamos recalcular suas dependências. O gráfico final ficará assim:
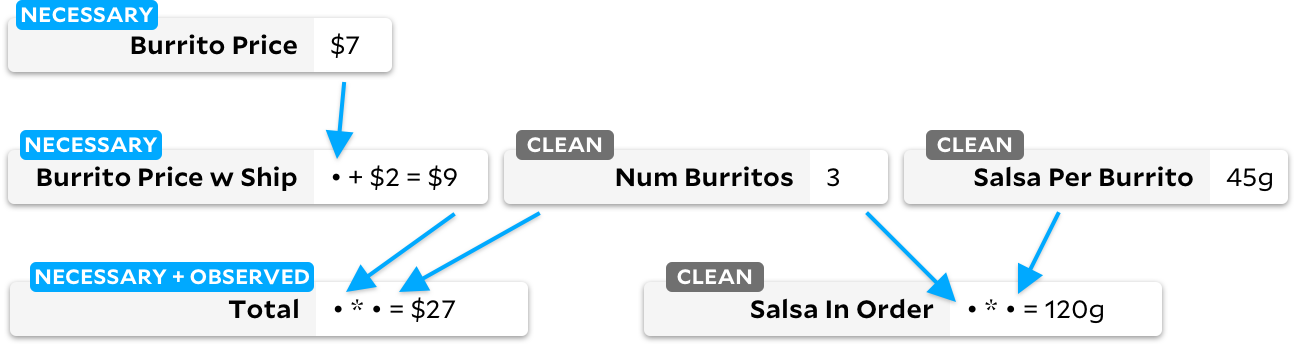
Recalculamos as células apenas quando necessário; portanto, sempre que recalculamos uma célula suja, também a marcamos conforme necessário. Em um nível superior, você pode pensar nesses três estados de células como uma máquina de estado cíclica:

Nas células necessárias, execute o algoritmo de classificação topológica incremental. No resto, executamos o algoritmo Adapton.
Sintaxe Burrito
Para concluir, gostaria de responder à última pergunta: até agora, discutimos muitos problemas que o modelo preguiçoso causa para nossa estratégia de recálculo de tabelas. Mas os problemas não estão apenas no algoritmo: também existem problemas sintáticos. Por exemplo, vamos montar uma mesa para escolher um burrito emoji para nosso cliente. Gostaríamos de escrever uma declaração
IF
em uma tabela como esta:

Como as planilhas tradicionais não são preguiçosas, podemos calcular
B1
,
B2
e
B3
em qualquer ordem, e então calcular a célula
IF
... No entanto, em um mundo preguiçoso, se pudermos calcular o valor de B1 primeiro, podemos olhar o resultado para descobrir qual valor precisa ser recalculado - B2 ou B3. Infelizmente, as planilhas tradicionais
IF
não podem expressar isso!
Problema:
B2
simultaneamente faz referência a uma célula
B2
e recupera seu valor. A maioria das bibliotecas preguiçosas mencionadas no artigo, em vez disso, distingue explicitamente entre uma referência de célula e o ato de recuperar seu valor real. Em Âncoras, nos referimos a essa referência de célula como uma âncora. Assim como na vida real, um burrito envolve um monte de ingredientes, um tipo de
Anchor<T>
embrulho
T
. Então eu acho que nossa célula de burrito vegano
Anchor<Burrito>
, uma espécie de burrito burrito ridículo. As funções podem transferir as nossas
Anchor<Burrito>
tanto quanto desejarem. Mas quando eles realmente desembrulham o burrito para acessar o
Burrito
interior, criamos uma borda de dependência em nosso gráfico, indicando ao algoritmo de recálculo que a célula pode ser necessária e precisa de um novo cálculo.
A abordagem adotada por Salsa e Adapton é usar chamadas de função e fluxo de controle normal como uma forma de expandir esses valores. Por exemplo, em Adapton, poderíamos escrever a célula Burrito for Customer algo assim:
let burrito_for_customer = cell!({
if get!(is_vegetarian) {
get!(vegi_burrito)
} else {
get!(meat_burrito)
}
});
Ao distinguir entre uma referência de célula (aqui
vegi_burrito
) e o ato de expandir seu valor (
get!
), o Adapton pode ser executado em cima de instruções de fluxo de controle do Rust, como
if
. Esta é uma otima soluçao! No entanto, é necessário um pouco de estado mágico global para conectar corretamente as chamadas
get!
às células
cell!
durante a mudança
is_vegetarian
. A biblioteca Anchors com influência incremental tem uma abordagem menos mágica. Como async-pre / await
Future
, Anchors permite lançar
Anchor<T>
operações como
map
e
then
. Portanto, o exemplo acima seria mais ou menos assim:
let burrito_for_customer: Anchor<Burrito> = is_vegetarian.then(|is_vegetarian: bool| -> Anchor<Burrito> {
if is_vegetarian {
vegi_burrito
} else {
meat_burrito
}
});
Leitura adicional
Neste artigo já longo e florido, não havia espaço suficiente para tantos tópicos. Esperançosamente, esses recursos podem lançar um pouco mais de luz sobre este problema muito interessante.
- Sete implementações de Incremental , uma grande análise aprofundada dos internos do Incremental, bem como um monte de otimizações como alturas constantemente crescentes sobre as quais não tive tempo de falar, além de maneiras inteligentes de lidar com células que mudam de dependência. Também vale a pena ler de Ron Minsky: FRP Parsing .
- Vídeo explicando como funciona a Salsa.
- Este é um ingresso de Salsa em que Matthew Hammer, criador do Adapton, explica pacientemente os cortes para um transeunte aleatório (eu) que não tem ideia de como funcionam.
- Rustlab . , « » «: DX CS» — .
- , « », Materialize. , . , (!) « », , . Noira .
- Adapton .
- Acontece que essa maneira de pensar também se aplica à construção de sistemas . Este é um dos primeiros artigos científicos sobre as semelhanças entre sistemas de compilação e planilhas.
- Traçado de raio ligeiramente incremental é um traçador de raio ligeiramente incremental escrito em Ocaml.
- Apenas olhei para "Estado parcial em visualizações materializadas com base no fluxo de dados" e parece relevante.
- Skip e Imp também parecem muito interessantes.
E, claro, você sempre pode verificar minha estrutura Anchors .