A análise técnica dos gráficos de ações baseia-se na hipótese da existência de padrões repetidos, padrões que podem trazer lucro. Vimos duas velas pretas e três velas brancas em uma determinada ordem - abrir e receber dinheiro. Mas, por alguma razão, há pouca informação (ou ela está totalmente ausente) sobre a prova dessa hipótese e como e com base no que ela foi geralmente formada. Essa. quantas vezes em dados históricos esta ou aquela figura funcionou como deveria. Onde e quem decidiu que há um triângulo caindo, túneis, uma cabeça com ombros, etc. Quem conferiu sua rentabilidade nas cotações acumuladas ao longo de toda a existência da bolsa? Por que não duas linhas paralelas e um paralelepípedo ou um círculo oval? Falaremos sobre essa prova neste artigo, ou seja, execute o script python para encontrar padrões,obtemos dados históricos copiando gráficos da sala.
Vamos começar com um dos padrões mais populares - cabeça e ombros em gráficos de 6 horas para 10 pares de moedas.
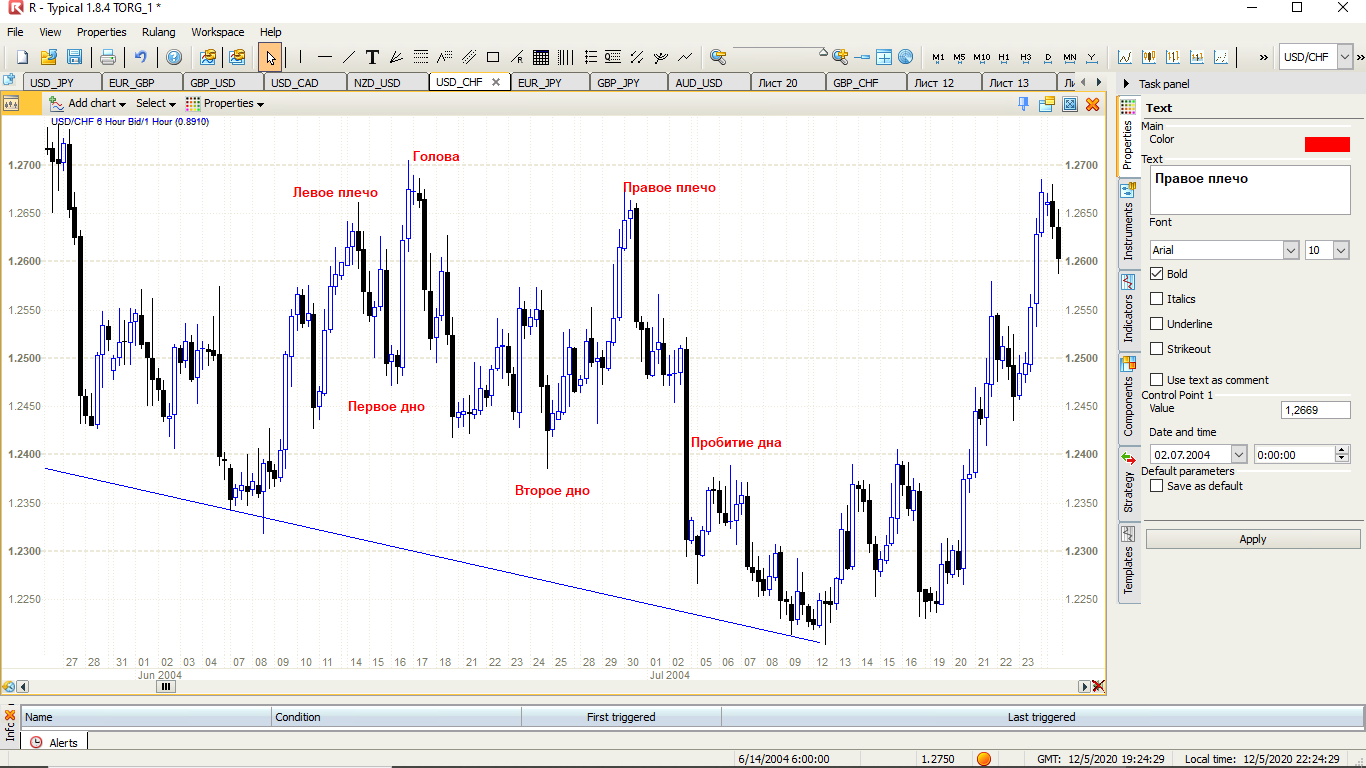
É necessário trazer as estatísticas para a forma de DataFrame no formato (este é um extrato do final, dados sobre 10 pares de moedas em 6 horas em média desde 2005 levarão cerca de 160 mil linhas)
|
|
TEMPO |
ABRIR |
ALTO |
BAIXO |
FECHAR |
TÍTULO |
|---|---|---|---|---|---|
16/09/19 06:00:00 |
1,3213 |
1.3234 |
1,3211 |
1,3232 |
USD_CAD_6H |
16/09/19 12:00:00 |
1,3230 |
1,3265 |
1.3228 |
1,3257 |
USD_CAD_6H |
16/09/19 18:00:00 |
1,3255 |
1,3270 |
1.3231 |
1,3247 |
USD_CAD_6H |
17/09/19 00:00:00 |
1,3248 |
1.3249 |
1,3232 |
1.3239 |
USD_CAD_6H |
17/09/19 06:00:00 |
1.3238 |
1,3253 |
1,3237 |
1,3247 |
USD_CAD_6H |
17/09/19 12:00:00 |
1.3249 |
1,3259 |
1,3240 |
1,3255 |
USD_CAD_6H |
17/09/19 18:00:00 |
1,3256 |
1.3298 |
1.3231 |
1,3247 |
USD_CAD_6H |
18/09/19 00:00:00 |
1,3245 |
1,3252 |
1,3237 |
1.3239 |
USD_CAD_6H |
18/09/19 06:00:00 |
1,3240 |
1,3258 |
1.3238 |
1,3254 |
USD_CAD_6H |
18/09/19 12:00:00 |
1,3252 |
1,3270 |
1.3249 |
1,3250 |
USD_CAD_6H |
18/09/19 18:00:00 |
1,3252 |
1,3285 |
1.3238 |
1.3273 |
USD_CAD_6H |
19/09/19 00:00:00 |
1,3277 |
1,3308 |
1,3267 |
1,3295 |
USD_CAD_6H |
19/09/19 06:00:00 |
1,3297 |
1,3305 |
1,3279 |
1.3282 |
USD_CAD_6H |
19/09/19 12:00:00 |
1,3281 |
1.3292 |
1.3272 |
1.3273 |
USD_CAD_6H |
19/09/19 18:00:00 |
1.3274 |
1,3279 |
1.3238 |
1.3243 |
USD_CAD_6H |
20/09/19 00:00:00 |
1,3244 |
1,3268 |
1.3242 |
1,3257 |
USD_CAD_6H |
20/09/19 06:00:00 |
1.3259 |
1.3271 |
1.3256 |
1.3266 |
USD_CAD_6H |
20/09/19 12:00:00 |
1.3265 |
1.3275 |
1.3256 |
1.3264 |
USD_CAD_6H |
20/09/19 18:00:00 |
1.3262 |
1.3299 |
1.3254 |
1.3255 |
USD_CAD_6H |
21/09/19 00:00:00 |
1.3253 |
1.3278 |
1.3251 |
1.3261 |
USD_CAD_6H |
. , , .. , , .. , , , , , .. , . , , , , - … , "" , .. . . , , ( ). , , .. , , - H&S ( ).
#,
list_H_AND_S=[]
# ( , , )
list_NOT_H_AND_S=[]
for i in range(600,len(df_ALL['CLOSE'])-600):
# , ..
if max(df_ALL['HIGH'][i-30:i+15])==df_ALL['HIGH'][i]:
# 15,
for z in range (15,200,15):
left_shoulder=max(df_ALL['HIGH'][i-30:i+15])
#
left_shoulder_index=df_ALL['HIGH'][i-30:i+15].idxmax()
# ,
if max(df_ALL['HIGH'][df_ALL['LOW'][left_shoulder_index:left_shoulder_index+z+1].idxmin():left_shoulder_index+z+1])>left_shoulder and\
(left_shoulder-min(df_ALL['LOW'][left_shoulder_index:left_shoulder_index+z+1]))/((max(df_ALL['HIGH'][df_ALL['LOW'][left_shoulder_index:left_shoulder_index+z+1].idxmin():left_shoulder_index+z+1])-min(df_ALL['LOW'][left_shoulder_index:left_shoulder_index+z+1])))>=0.6:
head=max(df_ALL['HIGH'][df_ALL['LOW'][left_shoulder_index:left_shoulder_index+z+1].idxmin():left_shoulder_index+z+1])
#
head_index=df_ALL['HIGH'][df_ALL['LOW'][left_shoulder_index:left_shoulder_index+z+1].idxmin():left_shoulder_index+z+1].idxmax()
for b in range (15,200,15):
# , ..
first_bottom= min(df_ALL['LOW'][left_shoulder_index:head_index+1])
# 1-
first_bottom_index=df_ALL['LOW'][left_shoulder_index:head_index+1].idxmin()
#
if min(df_ALL['LOW'][head_index:head_index+b])<first_bottom and \
(head-first_bottom)/(head-min(df_ALL['LOW'][head_index:head_index+b]))>=0.5:
second_bottom= min(df_ALL['LOW'][head_index:head_index+b])
# 2-
second_bottom_index=df_ALL['LOW'][head_index:head_index+b].idxmin()
for o in range(2,300):
# max(df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1]) -
if max(df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1])>=left_shoulder and \
max(df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1])<head and \
second_bottom_index+o-df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1].idxmax()>0 and \
(second_bottom_index+o+1)-df_ALL['LOW'][df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1].idxmax()]>2 and \
min(df_ALL['LOW'][df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1].idxmax():second_bottom_index+o+1])==df_ALL['LOW'][second_bottom_index+o] and \
min(df_ALL['LOW'][df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1].idxmax():second_bottom_index+o])>second_bottom and \
df_ALL['CLOSE'][second_bottom_index+o]<second_bottom and \
min(df_ALL['LOW'][second_bottom_index:df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1].idxmax()+1])==second_bottom and \
min(df_ALL['LOW'][left_shoulder_index:head_index])==first_bottom and \
max(df_ALL['HIGH'][first_bottom_index:second_bottom_index+1])==head and \
df_ALL['CLOSE'][second_bottom_index+o]-df_ALL['OPEN'][second_bottom_index+o]<=0:
# , H$S
for x in range (2,300):
# ,
# , (- )*2. ,
# -
if max(df_ALL['HIGH'][second_bottom_index+o:second_bottom_index+o+x+1])<=max(df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1]) and \
min(df_ALL['LOW'][second_bottom_index+o:second_bottom_index+o+x+1])<=second_bottom-(head-second_bottom)*2:
if (df_ALL['TIME'][left_shoulder_index]+' '+ df_ALL['TIME'][head_index]+' '+df_ALL['TIME'][second_bottom_index]+' '+df_ALL['TIME'][second_bottom_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_bottom_index+o]+' '+str(df_ALL['CLOSE'][o+second_bottom_index]-df_ALL['OPEN'][o+second_bottom_index])) not in list_H_AND_S:
list_H_AND_S.append(df_ALL['TIME'][left_shoulder_index]+' '+ df_ALL['TIME'][head_index]+' '+df_ALL['TIME'][second_bottom_index]+' '+df_ALL['TIME'][second_bottom_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_bottom_index+o]+' '+str(df_ALL['CLOSE'][o+second_bottom_index]-df_ALL['OPEN'][o+second_bottom_index]))
elif max(df_ALL['HIGH'][second_bottom_index+o:second_bottom_index+o+x+1])>max(df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1]) and \
min(df_ALL['LOW'][second_bottom_index+o:second_bottom_index+o+x+1])>first_bottom-(head-second_bottom):
if (df_ALL['TIME'][left_shoulder_index]+' '+ df_ALL['TIME'][head_index]+' '+df_ALL['TIME'][second_bottom_index]+' '+df_ALL['TIME'][second_bottom_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_bottom_index+o]+' '+str(df_ALL['CLOSE'][o+second_bottom_index]-df_ALL['OPEN'][o+second_bottom_index])) not in list_NOT_H_AND_S and \
(df_ALL['TIME'][left_shoulder_index]+' '+ df_ALL['TIME'][head_index]+' '+df_ALL['TIME'][second_bottom_index]+' '+df_ALL['TIME'][second_bottom_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_bottom_index+o]+' '+str(df_ALL['CLOSE'][o+second_bottom_index]-df_ALL['OPEN'][o+second_bottom_index])) not in list_H_AND_S:
list_NOT_H_AND_S.append(df_ALL['TIME'][left_shoulder_index]+' '+ df_ALL['TIME'][head_index]+' '+df_ALL['TIME'][second_bottom_index]+' '+df_ALL['TIME'][second_bottom_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_bottom_index+o]+' '+str(df_ALL['CLOSE'][o+second_bottom_index]-df_ALL['OPEN'][o+second_bottom_index]))
len(list_H_AND_S),len(list_NOT_H_AND_S)
1/6 ( ), ( -) , . . , , , - H&S , …
(/)
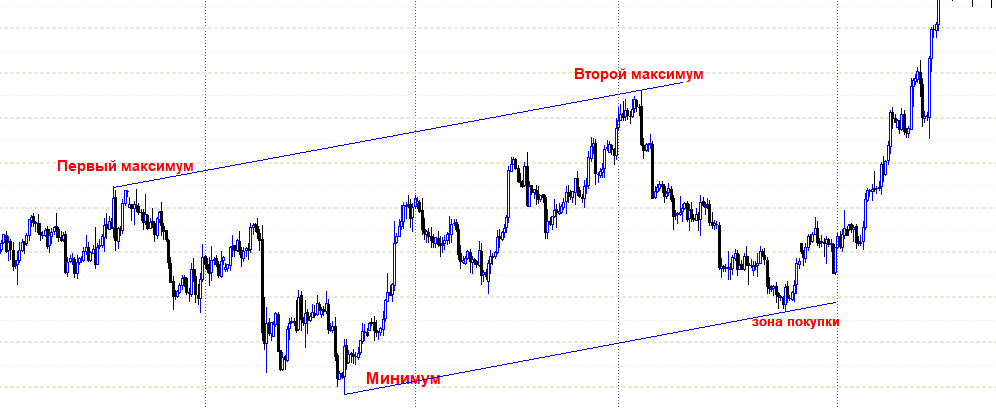
, , . 1 10, . ,
#
list_vimpel=[]
#
list_NOT_vimpel=[]
for i in range(600,len(df_ALL['CLOSE'])-1000):
if max(df_ALL['HIGH'][i-15:i+15])==df_ALL['HIGH'][i]:
for z in range (15,300,15):
#
first_max=max(df_ALL['HIGH'][i-15:i+15])
# 1-
first_max_index=df_ALL['HIGH'][i-15:i+15].idxmax()
if (first_max-min(df_ALL['LOW'][first_max_index:first_max_index+z+1]))>0 and \
max(df_ALL['HIGH'][df_ALL['LOW'][first_max_index:first_max_index+z+1].idxmin():first_max_index+z+1])>first_max and \
(max(df_ALL['HIGH'][df_ALL['LOW'][first_max_index:first_max_index+z+1].idxmin():first_max_index+z+1])-min(df_ALL['LOW'][first_max_index:first_max_index+z+1]))/(first_max-min(df_ALL['LOW'][first_max_index:first_max_index+z+1]))<=2.2 and \
(max(df_ALL['HIGH'][df_ALL['LOW'][first_max_index:first_max_index+z+1].idxmin():first_max_index+z+1])-min(df_ALL['LOW'][first_max_index:first_max_index+z+1]))/(first_max-min(df_ALL['LOW'][first_max_index:first_max_index+z+1]))>=1.3:
second_max=max(df_ALL['HIGH'][df_ALL['LOW'][first_max_index:first_max_index+z+1].idxmin():first_max_index+z+1])
second_max_index=df_ALL['HIGH'][df_ALL['LOW'][first_max_index:first_max_index+z+1].idxmin():first_max_index+z+1].idxmax()
# ,
first_min= min(df_ALL['LOW'][first_max_index:second_max_index+1])
# 1-
first_min_index=df_ALL['LOW'][first_max_index:second_max_index+1].idxmin()
for o in range(2,300):
if (second_max_index-first_min_index)>=25 and \
min(df_ALL['LOW'][second_max_index:second_max_index+o+1])==df_ALL['LOW'][o+second_max_index] and \
df_ALL['LOW'][o+second_max_index]>first_min and \
df_ALL['HIGH'][o+second_max_index]<second_max and \
(second_max_index-first_min_index)>=25 and \
max(df_ALL['HIGH'][first_min_index:o+second_max_index+1])==second_max and \
min(df_ALL['LOW'][first_min_index:second_max_index+1])==df_ALL['LOW'][first_min_index] and \
max(df_ALL['HIGH'][first_max_index:first_min_index+1])==first_max and \
(o+second_max_index)-second_max_index>=16 and \
df_ALL['LOW'][o+second_max_index]<=(first_min+((second_max-first_max)*(((o+second_max_index)-first_min_index)/(second_max_index-first_max_index)))) and \
df_ALL['CLOSE'][o+second_max_index]>=(first_min+((second_max-first_max)*(((o+second_max_index)-first_min_index)/(second_max_index-first_max_index)))):
for x in range (2,300):
if min(df_ALL['LOW'][o+second_max_index:o+second_max_index+x+1])==df_ALL['LOW'][o+second_max_index] and \
max(df_ALL['HIGH'][o+second_max_index:o+second_max_index+x+1])>=second_max:
if (df_ALL['TIME'][first_max_index]+' '+ df_ALL['TIME'][second_max_index]+' '+df_ALL['TIME'][second_max_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_max_index+o]+' '+str(df_ALL['CLOSE'][o+second_max_index]-df_ALL['OPEN'][o+second_max_index])+' '+str((second_max-first_min)/(first_max-first_min))+' '+str((second_max_index-first_min_index)/(first_min_index-first_max_index))+' '+str(((second_max-first_min)/(first_max-first_min))/((second_max-df_ALL['LOW'][o+second_max_index])/(second_max-first_min)))+' '+str(df_ALL['WeekDay'][o+second_max_index])+' '+str((second_max_index-first_max_index)/((o+second_max_index)-second_max_index))) not in list_vimpel:
list_vimpel.append(df_ALL['TIME'][first_max_index]+' '+ df_ALL['TIME'][second_max_index]+' '+df_ALL['TIME'][second_max_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_max_index+o]+' '+str(df_ALL['CLOSE'][o+second_max_index]-df_ALL['OPEN'][o+second_max_index])+' '+str((second_max-first_min)/(first_max-first_min))+' '+str((second_max_index-first_min_index)/(first_min_index-first_max_index))+' '+str(((second_max-first_min)/(first_max-first_min))/((second_max-df_ALL['LOW'][o+second_max_index])/(second_max-first_min)))+' '+str(df_ALL['WeekDay'][o+second_max_index])+' '+str((second_max_index-first_max_index)/((o+second_max_index)-second_max_index)))
elif min(df_ALL['LOW'][o+second_max_index:o+second_max_index+x+1])<df_ALL['LOW'][o+second_max_index] and \
max(df_ALL['HIGH'][o+second_max_index:o+second_max_index+x+1])<second_max:
if (df_ALL['TIME'][first_max_index]+' '+ df_ALL['TIME'][second_max_index]+' '+df_ALL['TIME'][second_max_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_max_index+o]+' '+str(df_ALL['CLOSE'][o+second_max_index]-df_ALL['OPEN'][o+second_max_index])+' '+str((second_max-first_min)/(first_max-first_min))+' '+str((second_max_index-first_min_index)/(first_min_index-first_max_index))+' '+str(((second_max-first_min)/(first_max-first_min))/((second_max-df_ALL['LOW'][o+second_max_index])/(second_max-first_min)))+' '+str(df_ALL['WeekDay'][o+second_max_index])+' '+str((second_max_index-first_max_index)/((o+second_max_index)-second_max_index))) not in list_NOT_vimpel and \
(df_ALL['TIME'][first_max_index]+' '+ df_ALL['TIME'][second_max_index]+' '+df_ALL['TIME'][second_max_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_max_index+o]+' '+str(df_ALL['CLOSE'][o+second_max_index]-df_ALL['OPEN'][o+second_max_index])+' '+str((second_max-first_min)/(first_max-first_min))+' '+str((second_max_index-first_min_index)/(first_min_index-first_max_index))+' '+str(((second_max-first_min)/(first_max-first_min))/((second_max-df_ALL['LOW'][o+second_max_index])/(second_max-first_min)))+' '+str(df_ALL['WeekDay'][o+second_max_index])+' '+str((second_max_index-first_max_index)/((o+second_max_index)-second_max_index))) not in list_vimpel:
list_NOT_vimpel.append(df_ALL['TIME'][first_max_index]+' '+ df_ALL['TIME'][second_max_index]+' '+df_ALL['TIME'][second_max_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_max_index+o]+' '+str(df_ALL['CLOSE'][o+second_max_index]-df_ALL['OPEN'][o+second_max_index])+' '+str((second_max-first_min)/(first_max-first_min))+' '+str((second_max_index-first_min_index)/(first_min_index-first_max_index))+' '+str(((second_max-first_min)/(first_max-first_min))/((second_max-df_ALL['LOW'][o+second_max_index])/(second_max-first_min)))+' '+str(df_ALL['WeekDay'][o+second_max_index])+' '+str((second_max_index-first_max_index)/((o+second_max_index)-second_max_index)))
len(list_vimpel),len(list_NOT_vimpel)
O objetivo deste artigo não é reduzir a análise técnica a pseudo-teorias, mas sim mostrar a natureza não científica de muitos artigos e livros que afirmam que os padrões populares funcionam devido à falta de uma resposta à pergunta principal - por que essa combinação de velas funciona? De onde veio essa informação? Com base na experiência pessoal, como a crença em um criador é comprovada em Scientology como ciência? Talvez alguém tenha descoberto (não sem provas, é claro) um padrão que traz pelo menos algum lucro, como dizem, escreva nos comentários. A opinião dos representantes da esfera cambial é especialmente bem-vinda. Obrigado pela atenção!
PS O autor entende que o código pode não ser escrito perfeitamente, não otimizado, etc.