
Vamos aquecer placas de metal na GPU
Todo mundo sabe que Python não brilha com velocidade por si só. Na minha opinião, a linguagem é excelente em sua legibilidade, mas o principal nicho de sua aplicação é onde você espera na maioria das vezes por alguma entrada / saída de dados. Por convenção, você pode escrever código de alto desempenho em Rust ou C, mas 99% das vezes ele apenas espera.
No entanto, Python também é excelente como cola sintática de alto nível. Nesse caso, sua parte interpretada vagarosamente invoca código de alta velocidade escrito em linguagens de programação compiladas. Normalmente, bibliotecas tradicionais como NumPy são usadas para isso.
Mas iremos um pouco mais longe, tentaremos paralelizar os cálculos em CUDA e usar um estranho, mas funcional híbrido de C ++, stdpar e o compilador nvc ++ da Nvidia. Bem, ao mesmo tempo, vamos tentar avaliar o desempenho. Vejamos dois problemas: os números de classificação e o método de Jacobi, que usaremos para calcular o aquecimento de uma placa de metal.
Chamando C ++ de Python
Nosso código de classificação será semelhante a este:
# distutils: language=c++
from libcpp.algorithm cimport sort
def cppsort(int[:] x):
sort(&x[0], &x[-1] + 1)
Na primeira linha, indicamos explicitamente que Cython deve usar C ++, e não o C padrão. Na segunda, importamos a função de classificação de C ++ e, em seguida, a própria lógica segue. Coloque o código no arquivo cppsort.pyx. Observe que a extensão difere do py usual, pois iremos compilá-la ou executar o cythonize na terminologia do Cython.
A compilação pode ser feita manualmente ou incluída em setup.py, onde descrevemos completamente a preparação de nosso ambiente.
Em setup.py, é assim:
from setuptools import setup
from Cython.Build import cythonize
setup(
ext_modules = cythonize("cppsort.pyx")
)
Mas podemos fazer isso apenas na linha de comando:
cythonize -i cppsort.pyx
Sob o capô, algo assim vai acontecer:

- Cython irá traduzir o código Python para C ++ e gerar um cppsort.cpp válido.
- O compilador C ++ (neste caso g ++) compila o código C ++ no módulo de extensão Python
- O módulo de extensão Python é importado para o código como um módulo Python regular.
Após a compilação, podemos importar e testar imediatamente a classificação:
from cppsort import cppsort
import numpy as np
x = np.array([4, 3, 2, 1], dtype="int32")
print(x)
cppsort(x)
print(x)
O array [4, 3, 2, 1] é classificado com sucesso para [1, 2, 3, 4] usando C ++ std :: sort.
Vamos para a GPU?
Os algoritmos da biblioteca padrão C ++ podem ser chamados com o argumento da política de execução paralela . Este argumento informa ao compilador que você deseja dividir o algoritmo em processos paralelos.
Dito isso, C ++ tem várias opções para esta política:
- std :: running :: seq: execução sequencial. O paralelismo é proibido.
- std :: running :: unseq: execução vetorizada dentro do thread de chamada.
- std :: execution :: par: Execução paralela em um ou mais threads.
- std :: execution :: par_unseq: Execução paralela em um ou mais threads. Cada fluxo será vetorizado sempre que possível.
Nesse caso, você mesmo deve monitorar a condição de corrida e o impasse. O compilador g ++ padrão tentará distribuir a computação entre os núcleos da CPU. Mas podemos pegar um compilador proprietário da Nvidia - nvc ++ e alimentá-lo com a opção "-stdpar". stdpar é o paralelismo padrão C ++ da Nvidia com execução paralela de código na GPU.
Vamos reescrever o código, levando em consideração a necessidade de criar uma cópia local do array, já que a GPU não conseguirá acessar o array localizado dentro do NumPy.
from libcpp.algorithm cimport sort, copy_n
from libcpp.vector cimport vector
from libcpp.execution cimport par
def cppsort(int[:] x):
cdef vector[int] temp
temp.resize(len(x))
copy_n(&x[0], len(x), temp.begin())
sort(par, temp.begin(), temp.end())
copy_n(temp.begin(), len(x), &x[0])

Agora, isso precisa ser compilado novamente, mas usando nvc ++. Desta vez, vamos escrever um setup.py normal e chamá-lo de:
CC=nvc++ python setup.py build_ext --inplace
Importamos para o código e tentamos chamar:
x = np.array([4, 3, 2, 1], dtype="int32")
cppsort(x) # GPU
atuação
Tradicionalmente, as GPUs são boas onde há muito do mesmo tipo de computação leve. Tarefas pesadas, tarefas de GPU individuais não funcionarão. Além disso, vale a pena considerar o volume de seus dados. Se você tiver poucos dados, terá uma grande sobrecarga para o processo de paralelização, E / S entre a CPU e a GPU. Como resultado, esse código provavelmente será executado com mais eficiência em uma CPU vazia, às vezes até dentro de um único núcleo, se houver poucos dados. Mas em matrizes grandes, a GPU definitivamente estará à frente.
Há uma ótima comparação de classificação aqui. A velocidade NumPy foi considerada como uma unidade, e então a multiplicidade do aumento de velocidade em cada método foi calculada em relação a ela.
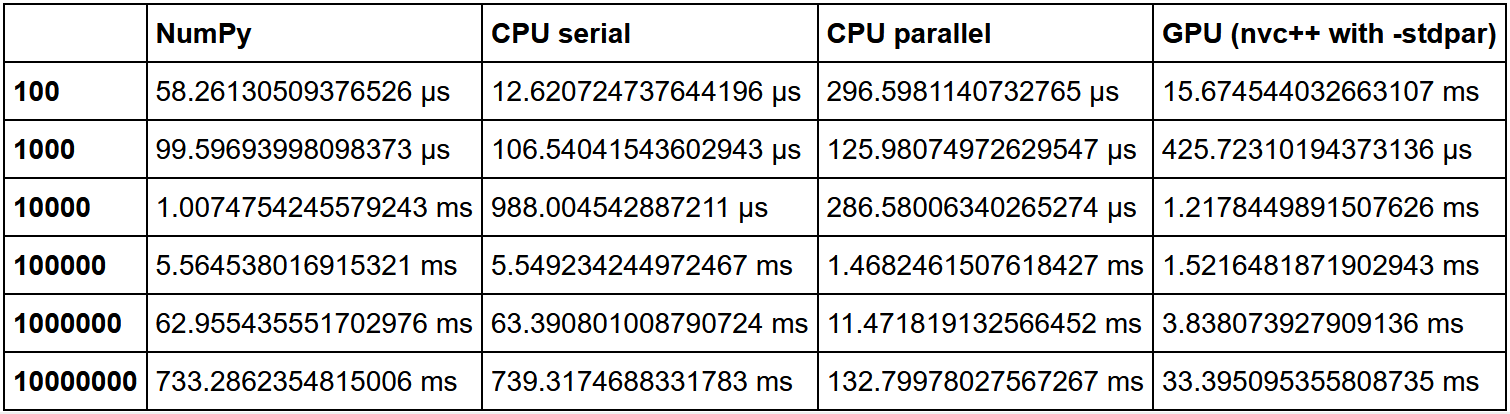
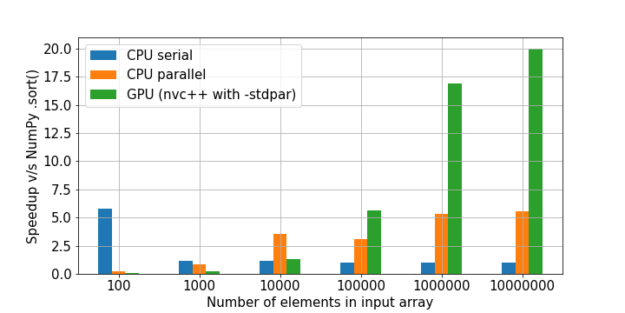
Como podemos ver, confirma-se a hipótese de que o ganho com o uso da GPU em uma grande quantidade de dados é crescente.
Calculamos o aquecimento da placa
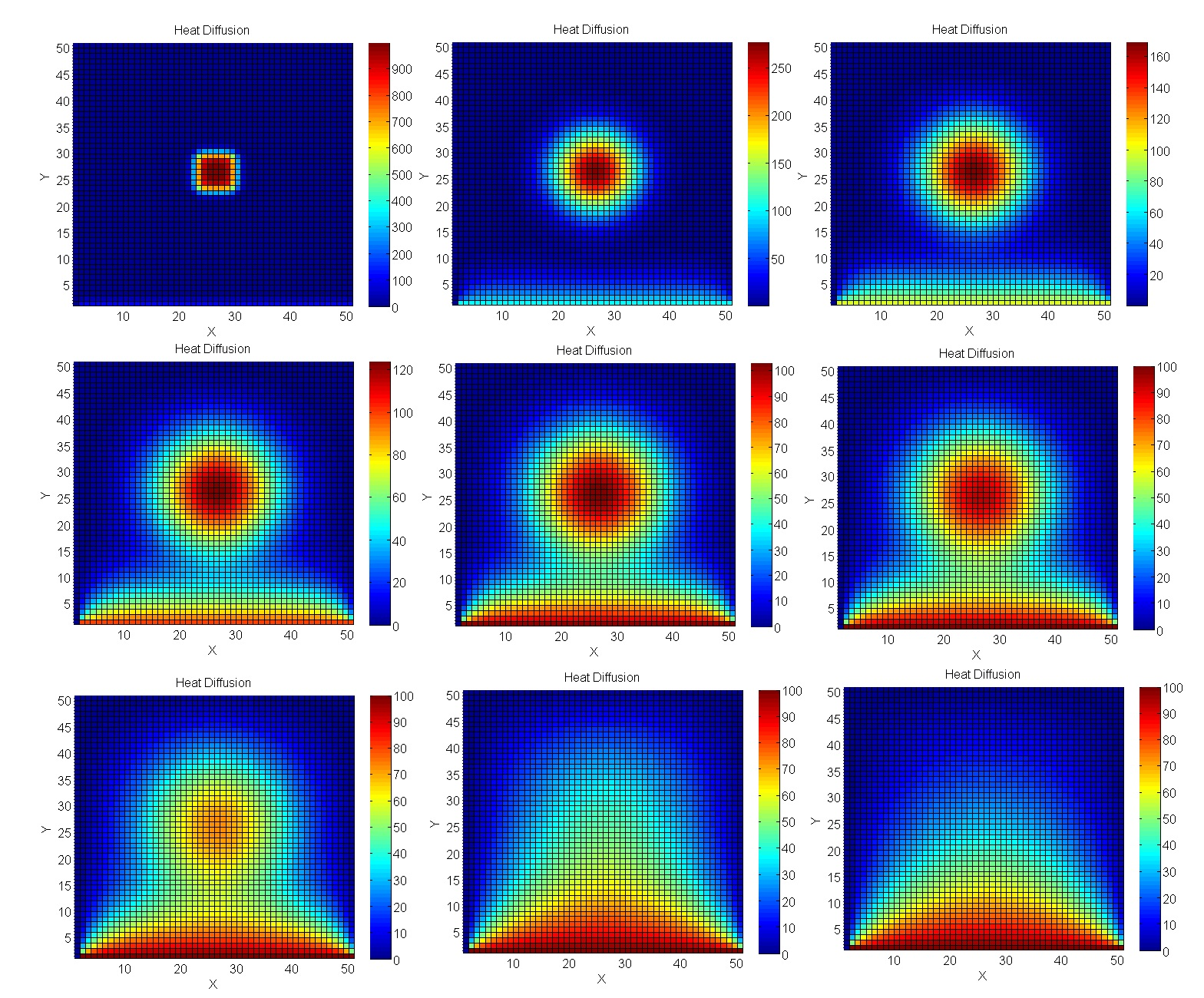
Vamos examinar um problema mais próximo da modelagem de engenharia real - cálculos usando o método de Jacobi. Em particular, eles são excelentes para calcular processos de temperatura no espaço 2D.
Código de simulação
"""
simulates heat equation on rectangle returning a heat map at a number of times
boundary and initial conditions are 0, source represents burner on a stove
This program is based on the script FEniCS tutorial demo program: Diffusion of a Gaussian hill.
u'= Laplace(u) + f in a square domain
u = u_D = 0 on the boundary
u = u_0 = 0 at t = 0
u_D = f = stove burner flame
This program succesfully runs in the fenics docker image, see the book Solving PDEs in Python.
to animate: convert -delay 4 -loop 100 heatequation10*.png heatstovelinn.gif
to crop:convert heatstovelinn.gif -coalesce -repage 0x0 -crop 810x810+95+15 +repage heatstovelin.gif
"""
from fenics import *
import time
import matplotlib.pyplot as plt
from matplotlib import cm
# Create mesh and define function space
nx = ny = 100
mesh = RectangleMesh(Point(-2, -2), Point(2, 2), nx, ny)
V = FunctionSpace(mesh, 'P', 1)
# Define boundary, source, initial
def boundary(x, on_boundary):
return on_boundary
bc = DirichletBC(V, Constant(0), boundary)
u_0 = interpolate(Constant(0), V)
f = Expression('exp(-sqrt(pow((a*pow(x[0], 2) + a*pow(x[1], 2)-a*1),2)))', degree=2, a=5) #steep guassian centred on the unit sphere
final_time = 0.035
num_pics = 72
for i in range(num_pics):
T = final_time*(i+1.0)/(num_pics+1) #solve time even space
#T = final_time*1.1**(i-num_pics+1) #solve time log space
num_steps = 30
dt = T / num_steps # time step size
# Define variational problem
u = TrialFunction(V)
v = TestFunction(V)
F = u*v*dx + dt*dot(grad(u), grad(v))*dx - (u_0 + dt*f)*v*dx
a, L = lhs(F), rhs(F)
# Time-stepping
u = Function(V)
t = 0
for n in range(num_steps):
t += dt #step
solve(a == L, u, bc) #solve
u_0.assign(u) #update
#plot solution
plot(u,cmap=cm.hot,vmin=0,vmax=0.07)
plt.axis('off')
plt.savefig('heatequation10%s.png'%(i+10),figsize=(8, 8), dpi=220,bbox_inches='tight', pad_inches=0,transparent=True)
Vamos escrever um solucionador semelhante no Cython para compilação subsequente usando CUDA:
# distutils: language=c++
# cython: cdivision=True
from libcpp.algorithm cimport swap
from libcpp.vector cimport vector
from libcpp cimport bool, float
from libc.math cimport fabs
from algorithm cimport for_each, any_of, copy
from execution cimport par, seq
cdef cppclass avg:
float *T1
float *T2
int M, N
avg(float* T1, float *T2, int M, int N):
this.T1, this.T2, this.M, this.N = T1, T2, M, N
inline void call "operator()"(int i):
if (i % this.N != 0 and i % this.N != this.N-1):
this.T2[i] = (
this.T1[i-this.N] + this.T1[i+this.N] + this.T1[i-1] + this.T1[i+1]) / 4.0
cdef cppclass converged:
float *T1
float *T2
float max_diff
converged(float* T1, float *T2, float max_diff):
this.T1, this.T2, this.max_diff = T1, T2, max_diff
inline bool call "operator()"(int i):
return fabs(this.T2[i] - this.T1[i]) > this.max_diff
def jacobi_solver(float[:, :] data, float max_diff, int max_iter=10_000):
M, N = data.shape[0], data.shape[1]
cdef vector[float] local
cdef vector[float] temp
local.resize(M*N)
temp.resize(M*N)
cdef vector[int] indices = range(N+1, (M-1)*N-1)
copy(seq, &data[0, 0], &data[-1, -1], local.begin())
copy(par, local.begin(), local.end(), temp.begin())
cdef int iterations = 0
cdef float* T1 = local.data()
cdef float* T2 = temp.data()
keep_going = True
while keep_going and iterations < max_iter:
iterations += 1
for_each(par, indices.begin(), indices.end(), avg(T1, T2, M, N))
keep_going = any_of(par, indices.begin(), indices.end(), converged(T1, T2, max_diff))
swap(T1, T2)
if (T2 == local.data()):
copy(seq, local.begin(), local.end(), &data[0, 0])
else:
copy(seq, temp.begin(), temp.end(), &data[0, 0])
return iterations
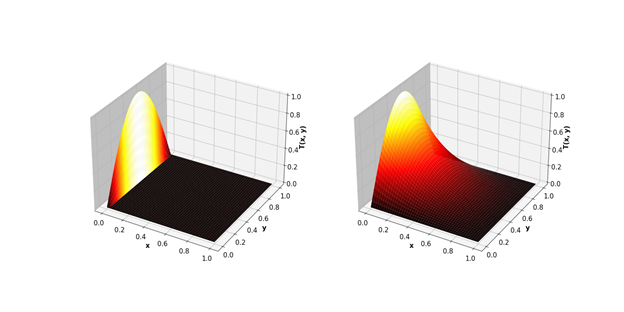

Como resultado, a lacuna da GPU é ainda mais significativa.
Minuses
- Escrever esse tipo de código é um pouco mais complicado do que uma versão pura do Python e requer uma compreensão de como a computação paralela funciona em uma GPU.
- É necessário copiar os dados em uma matriz separada para transferência para a GPU, onde a placa de vídeo não tem acesso. Isso pode ser um problema ao lidar com matrizes muito grandes.
