
Sistemas para converter consultas de texto em SQL
O que tal sistema deve ser capaz de fazer:
- Encontre entidades no texto que correspondam a entidades de banco de dados: tabelas, colunas, às vezes valores.
- Tabelas de links, filtros de formulários.
- Defina um conjunto de dados retornados, ou seja, faça uma lista de seleção.
- Determine a ordem de amostragem e o número de linhas.
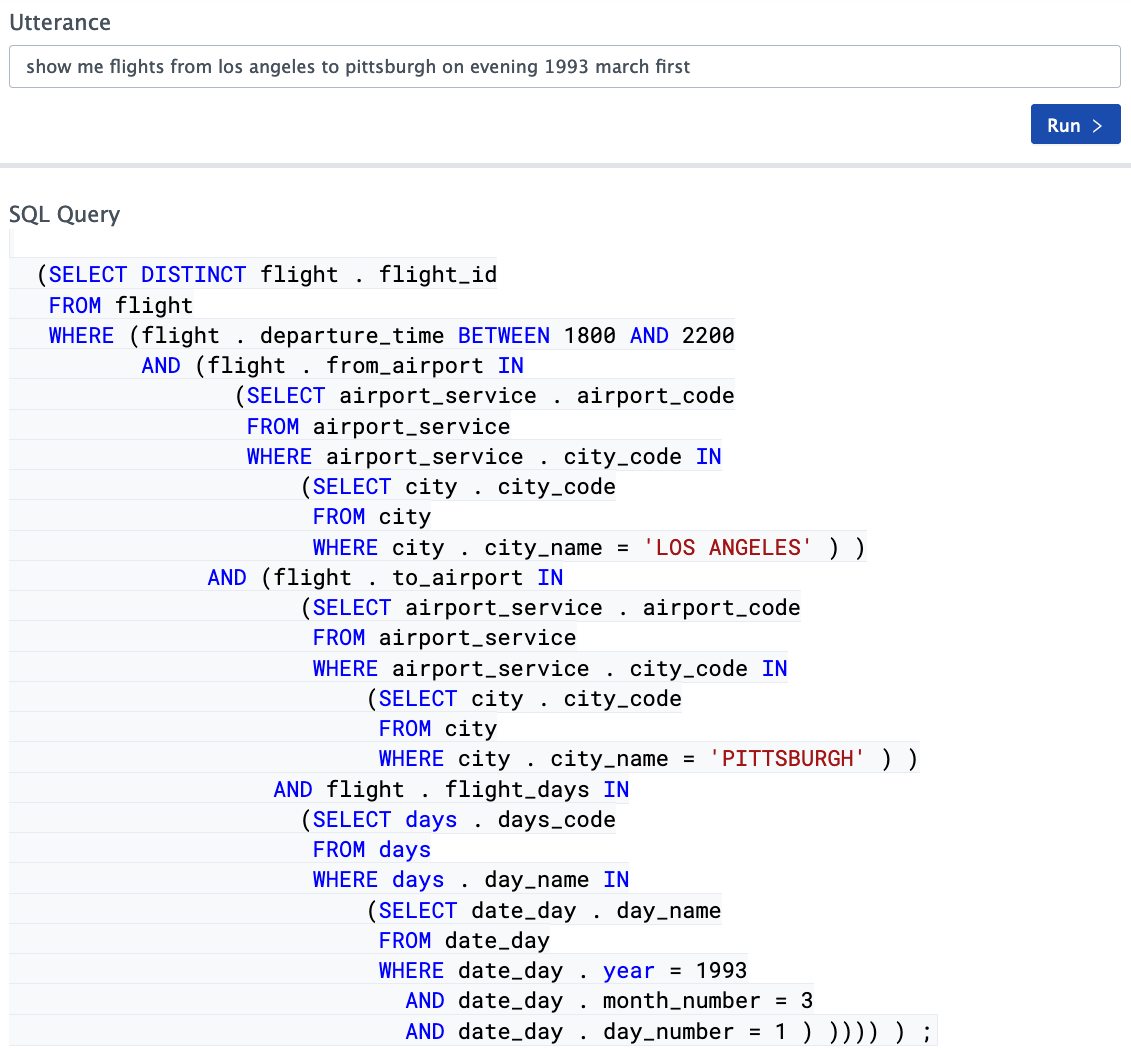
- Identifique, além das relativamente óbvias, algumas dependências ou filtros absolutamente implícitos que são opacos para qualquer pessoa, exceto os designers do esquema base (consulte a condição para o campo bonus_type na imagem acima)
- Resolva ambigüidades ao selecionar entidades. “Dê-me dados sobre Ivanov” - você deve solicitar informações sobre uma contraparte ou um funcionário com esse sobrenome? Dados do funcionário para fevereiro - Limitar a amostra por data de contratação ou data de vendas? etc.
Ou seja, na primeira etapa, você precisa analisar a consulta, assim como ao trabalhar com todos os outros sistemas de PNL e, em seguida, gerar SQL em tempo real ou encontrar alguma intenção mais adequada, na função da qual uma consulta SQL parametrizada preparada anteriormente é escrita. À primeira vista, a primeira opção parece muito mais impressionante. Vamos falar sobre isso com mais detalhes.
A peculiaridade de tais sistemas é que, na verdade, apenas um intent é registrado neles, que é disparado para tudo que tem pelo menos alguma relação com o modelo, com alguma superfunção que gera SQL para todos os tipos de consultas. O SQL pode ser criado com base em qualquer regra, algoritmicamente ou com a participação de redes neurais.
Algoritmos e regras
À primeira vista, a tarefa de converter uma frase analisada em SQL é um problema puramente algorítmico, ou seja, pode ser resolvido sem problemas. Parece que temos tudo de que precisamos para converter um modelo forte em outro: entidades reconhecidas, referências, co-referências, etc. Mas, infelizmente, as nuances e ambigüidades, como sempre, complicam tudo e, neste caso, tornam a abordagem 100% universal quase inoperante. Os modelos são imperfeitos (veja os exemplos acima e mais adiante no artigo), as entidades se cruzam, tanto em nomes quanto em significado, o crescimento da complexidade com o aumento do número de entidades e a complexidade da base torna-se não linear.
Redes neurais
O uso de redes neurais para tais sistemas é uma área em rápido desenvolvimento. No âmbito deste artigo, vou me limitar a links e breves conclusões.
Aconselho você a ler uma pequena série de artigos: 1 , 2 , 3 , 4 , 5 , eles contêm um pouco de teoria, uma história sobre como são feitos treinamentos e testes de qualidade, um breve panorama de soluções. Além disso, aqui - mais sobre SparkNLP. Aqui - sobre a solução Photon da SalesForce. De acordo com a referência mais um representante da comunidade open source - Allennlp. Aqui- dados sobre a qualidade dos sistemas, ou seja, taxas de teste. Aqui estão os dados sobre o uso de bibliotecas de PNL e, em particular, soluções semelhantes em uma empresa.
Esta direção tem um grande futuro, mas novamente com ressalvas - ainda não para todos os tipos de modelos. Se, ao trabalhar com um modelo, você não precisa obter números totalmente estritos e resultados precisos, repetíveis e previsíveis garantidos (por exemplo, você precisa determinar uma tendência, comparar indicadores, identificar dependências, etc.) - está tudo bem. Mas o não determinismo e a natureza probabilística das respostas impõem restrições ao uso de tal abordagem para vários sistemas.
Exemplos de trabalho com sistemas baseados em redes neurais
Muitas vezes, empresas que prestam serviços desse tipo apresentam excelentes resultados em vídeos bem feitos e se oferecem para contatá-los para uma conversa detalhada. Mas também existem demos online disponíveis na rede. É especialmente conveniente experimentar o Photon , já que, neste caso, o diagrama básico está bem diante de seus olhos. A segunda demonstração que vi em domínio público é da Allennlp. A análise de algumas consultas é surpreendente em sua sofisticação, algumas opções são um pouco menos bem-sucedidas. A impressão geral é mista, tente jogar com essas demos se estiver interessado e forme sua própria opinião.
Em geral, a situação é bastante interessante. Os sistemas para tradução automática de consultas textuais não estruturadas em SQL com base em redes neurais estão ficando cada vez melhores, a qualidade dos casos de teste está ficando cada vez mais alta, mas ainda assim seu valor não ultrapassa 70% na melhor das hipóteses ( conjunto de dados spider - cerca de 69% hoje dia). Esse resultado pode ser considerado bom? Do ponto de vista do desenvolvimento de tais sistemas, sim, claro, os resultados são impressionantes, mas está longe de ser possível utilizá-los em sistemas reais sem modificação para todos os tipos de tarefas.
Ferramentas Apache NlpCraft
Como o projeto Apache NlpCraft pode ajudar na construção e organização de tais sistemas? Se não houver perguntas sobre a primeira parte da tarefa (análise de uma consulta de texto), tudo é normal, então para a segunda parte (formando consultas SQL com base em dados de PNL), NlpCraft não fornece uma solução 100% completa, mas apenas ferramentas que ajudam a resolver este problema por conta própria ...
Por onde começar? Se quisermos automatizar o processo de desenvolvimento o máximo possível, os metadados do esquema do banco de dados e os próprios dados nos ajudarão. Listaremos quais informações podemos extrair do banco de dados e, para simplificar, nos restringiremos a tabelas, não tentaremos analisar triggers, stored procedures, etc.
- — . , .
- (null / not null) (where clause).
- , foreign keys , 1:1, 1:0, 1:n, n:m. joins.
- . , , .. , select list.
- . . - — , — enumeration, . .
- . , . .
- Primary and unique keys — , , , .
- (, , Oracle) — .
- Verifique as restrições - o conhecimento das restrições pode ajudar na construção dos mesmos filtros nessas colunas.
Portanto, se você obteve metadados, já sabe muito sobre as entidades do modelo. Então, por exemplo, em algum mundo ideal, você sabe quase tudo sobre a tabela abaixo:
CREATE TABLE users (
id number primary key,
first_name varchar(32) not null,
last_name varchar(64) not null unique,
birthday date null,
salary_level_id number not null foreign key on salary_level(id)
);
Na realidade, nem tudo será tão otimista, os nomes serão abreviados e ilegíveis, os tipos de dados muitas vezes se revelarão completamente inesperados e os campos desnormalizados e as tabelas adicionadas às pressas como 1: 0 estarão espalhadas aqui e ali. Como resultado, para ser realista, a maioria das bases de dados que estão em produção há muito tempo só podem ser utilizadas com grande dificuldade para o reconhecimento de entidades sem qualquer preparação prévia. Isso se aplica a qualquer sistema e com base em redes neurais, talvez até mais do que outros.
Nessa situação, é aconselhável dar ao módulo de PNL acesso a um esquema um tanto refinado - um conjunto pré-preparado de visualizações, com os nomes de campo corretos, um conjunto necessário e suficiente de tabelas e colunas, questões de segurança, etc.
Vamos começar a desenhar
A ideia principal e muito simples é que é quase impossível atender a todas as solicitações do usuário. Se o usuário definir uma meta para enganar o sistema e quiser fazer uma pergunta que o confunda, ele o fará facilmente. A tarefa do desenvolvedor é encontrar um equilíbrio entre as capacidades do sistema que está sendo desenvolvido e a complexidade de sua implementação. Daí, também, um conselho muito simples - não tente apoiar uma intenção universal que responda a todas as perguntas, com um método universal que gera SQL para todas essas opções. Tente abrir mão de 100% de versatilidade, isso tornará o projeto um pouco menos colorido, mas mais realizável.
- Pergunte aos usuários e escreva 30-40 dos tipos mais comuns de perguntas.
- , , , ..
- . SQL, 20-30 . , . SQL ML text2Sql, .
- . — , , , . — SQL . C — , .
Com tal volume de trabalho e recursos suficientes, o tempo necessário para resolver tal problema é medido em dias, e no final você tem 80% de cobertura das necessidades do usuário e com uma qualidade de desempenho bastante elevada. Em seguida, volte ao primeiro ponto e adicione mais intents.
A maneira mais fácil de explicar por que vale a pena apoiar várias intents é com um exemplo. Quase sempre os usuários se interessam por um determinado número de relatórios muito atípicos, algo como “compare-me tal e tal para tal e tal período, mas não incluído em tal e tal período e ao mesmo tempo ...”. Nenhum sistema será capaz de gerar SQL imediatamente para tal consulta, você terá que treiná-lo de alguma forma ou selecionar e programar separadamente tais casos. Ser capaz de responder a uma gama limitada de consultas intrincadas é muito importante para seus usuários. Procure um equilíbrio novamente, não o fato de que haverá recursos suficientes para satisfazer todas essas solicitações, mas ignorar completamente esses desejos significa restringir a funcionalidade do sistema a um nível inaceitável. Se você encontrar a proporção certa,seu sistema levará uma quantidade finita de tempo de desenvolvimento e não será apenas um brinquedo divertido por alguns dias, causando aborrecimento ao invés de utilidade. Um ponto muito importante é que você pode adicionar intents para solicitações complicadas não imediatamente, mas no processo, uma por uma. Temos MVP com apenas uma intenção universal de cada vez.
Kit de ferramentas e API
Apache NlpCraft oferece um kit de ferramentas para simplificar a manipulação de banco de dados.
Procedimento de operação:
- Gere o modelo do modelo a partir do url do banco de dados jdbc. Como mencionei acima, às vezes é melhor preparar um conjunto de visualizações com uma representação mais “correta” dos dados e fornecer acesso a esse conjunto. A maneira mais fácil de gerar um modelo é usar o utilitário CLI . Lançamos o utilitário, especificamos o esquema do banco de dados, driver jdbc, uma lista de tabelas usadas e ignoradas e outros parâmetros como parâmetros, consulte a documentação para mais detalhes .
- JSON YAML , , , , .., , .
:
- id: "tbl:orders" groups: - "table" synonyms: - "orders" metadata: sql:name: "orders" sql:defaultselect: - "order_id" - "customer_id" - "employee_id" sql:defaultsort: - "orders.order_id#desc" sql:extratables: - "customers" - "shippers" - "employees" description: "Auto-generated from 'orders' table." ..... - id: "col:orders_order_id" groups: - "column" synonyms: - "{order_id|order <ID>}" - "orders {order_id|order <ID>}" - "{order_id|order <ID>} <OF> orders" metadata: sql:name: "order_id" sql:tablename: "orders" sql:datatype: 4 sql:isnullable: false sql:ispk: true description: "Auto-generated from 'orders.order_id' column."
- — , , . , . , , , , , , .. .
- Com base no modelo avançado, o desenvolvedor pode usar uma API compacta que facilita muito a construção de consultas SQL na função de intenção - consulte um exemplo detalhado .
Abaixo está um snippet de código para maior clareza:
@NCIntent(
"intent=commonReport " +
"term(tbls)~{groups @@ 'table'}[0,7] " +
"term(cols)~{
id == 'col:date' ||
id == 'col:num' ||
id == 'col:varchar'
}[0,7] " +
"term(condNums)~{id == 'condition:num'}[0,7] " +
"term(condVals)~{id == 'condition:value'}[0,7] " +
"term(condDates)~{id == 'condition:date'}[0,7] " +
"term(condFreeDate)~{id == 'nlpcraft:date'}? " +
"term(sort)~{id == 'nlpcraft:sort'}? " +
"term(limit)~{id == 'nlpcraft:limit'}?"
)
def onCommonReport(
ctx: NCIntentMatch,
@NCIntentTerm("tbls") tbls: Seq[NCToken],
@NCIntentTerm("cols") cols: Seq[NCToken],
@NCIntentTerm("condNums") condNums: Seq[NCToken],
@NCIntentTerm("condVals") condVals: Seq[NCToken],
@NCIntentTerm("condDates") condDates: Seq[NCToken],
@NCIntentTerm("condFreeDate") freeDateOpt: Option[NCToken],
@NCIntentTerm("sort") sortTokOpt: Option[NCToken],
@NCIntentTerm("limit") limitTokOpt: Option[NCToken]
): NCResult = {
val ext = NCSqlExtractorBuilder.build(SCHEMA, ctx.getVariant)
val query =
SqlBuilder(SCHEMA).
withTables(tbls.map(ext.extractTable): _*).
withAndConditions(extractValuesConditions(ext, condVals): _*).
...
// SQL
// .
}
Aqui está um fragmento da função de intent padrão que responde a qualquer elemento de base definido na solicitação e é acionado se nenhuma correspondência mais restrita for encontrada durante o processo de correspondência. Ele demonstra o uso da API do extrator de elementos SQL, que está envolvida na construção de consultas SQL, bem como no trabalho com o exemplo do construtor SQL.
Mais uma vez, quero enfatizar que o Apache NlpCraft não fornece uma ferramenta pronta para traduzir uma consulta de texto analisado em SQL, essa tarefa está fora do escopo do projeto, pelo menos na versão atual. O código do construtor de consulta está disponível em exemplos, não na API, ele tem limitações significativas, mas também consiste em apenas 500 linhas de código com comentários, ou cerca de 300 sem eles. Ao mesmo tempo, apesar de toda a sua simplicidade e até limitação, mesmo esta implementação mais simples é capaz de gerar o SQL necessário para um número muito significativo dos mais diversos tipos de consultas do usuário. Nesta versão, sugerimos aos nossos usuários interessados em construir sistemas semelhantes para usar este exemplocomo um modelo e desenvolva-o para atender às suas necessidades. Sim, isso não é uma tarefa para uma noite, mas você obterá um resultado de qualidade incomparavelmente superior do que ao usar soluções universais de frente.
Repito que na função de intenção padrão, você pode apenas modificar os exemplos do exemplo (de acordo com as análises, sua funcionalidade pode ser suficiente) ou usar soluções com redes neurais.
Conclusão
Construir um sistema para acessar um banco de dados não é uma tarefa fácil, mas o Apache NlpCraft já assumiu uma parte considerável da rotina de trabalho e, em grande parte, devido a isso, desenvolver um sistema de qualidade decente exigirá tempo e recursos mensuráveis. Se a comunidade Apache NlpCraft irá desenvolver a direção de automatizar a tradução de consultas de texto em SQL e expandir este exemplo simples de SQL para uma API completa - o tempo e as solicitações do usuário que formam o plano e a direção do projeto serão mostrados.