- Permite que você escreva código em uma linguagem familiar, mas ao mesmo tempo use funções que existem apenas em outra linguagem.
- Permite a colaboração direta com um colega que está programando em outra linguagem.
- Torna possível trabalhar com dois idiomas e, eventualmente, aprender a ser fluente neles.

O que nós precisamos
Para funcionar, você precisa destes componentes:
- R e Python, é claro.
- IDE RStudio (você pode fazer isso em outros IDEs, mas no RStudio é mais fácil).
- Seu gerenciador de ambiente Python favorito (estou usando conda aqui).
- Pacotes
rmarkdown
ereticulate
instalados na R.
Ao escrever documentos R Markdown, estaremos trabalhando em RStudio, mas ao mesmo tempo navegando entre trechos de código escritos em R e em Python. Vou mostrar alguns exemplos simples.
Configurando o ambiente Python
Se você está familiarizado com a programação Python, então sabe que qualquer trabalho realizado em Python deve se referir a um ambiente específico que contém todos os pacotes necessários para o trabalho. Existem muitas maneiras de gerenciar pacotes em Python, as duas mais populares são virtualenv e conda. Aqui, estou assumindo que estamos usando conda e que ele está instalado como gerenciador de ambiente Python.
Você pode usar o pacote reticulate em R para configurar ambientes conda por meio da linha de comando R se quiser (usando recursos como
conda_create()
), mas como um programador Python regular, prefiro configurar meus ambientes manualmente.
Suponha que criamos um ambiente conda nomeado
r_and_python
e instalamos nele
pandas
e
statsmodels
... Portanto, os comandos no terminal:
conda create -name r_and_python conda activate r_and_python conda install pandas conda install statsmodels
Depois de instalar
pandas
,
statsmodels
(e quaisquer outros pacotes que você pode precisar), a configuração do ambiente está completo. Agora execute conda info no terminal e selecione o caminho para o seu ambiente. Você precisará dele na próxima etapa.
Configurando seu projeto R para trabalhar com R e Python
Começaremos um projeto R no RStudio, mas queremos poder rodar Python no mesmo projeto. Para garantir que o código Python seja executado no ambiente que desejamos, precisamos definir a variável de ambiente do sistema
RETICULATE_PYTHON
para o executável Python nesse ambiente. Este será o caminho que você escolheu na seção anterior, seguido por
/bin/python3
.
A melhor maneira de garantir que essa variável seja definida permanentemente em seu projeto é criar um arquivo de texto nomeado no projeto
.Rprofile
e adicionar esta linha a ele.
Sys.setenv(RETICULATE_PYTHON=”path_to_environment/bin/python3")
Substitua pathtoenvironment pelo caminho que você escolheu na seção anterior. Salve o arquivo
.Rprofile
e reinicie a sessão R. Sempre que você reiniciar uma sessão ou projeto, ele é inicializado
.Rprofile
, configurando seu ambiente Python. Se você quiser testar isso, pode executar a linha Sys.getenv ("RETICULATE_PYTHON").
Escrevendo código - primeiro exemplo
Agora você pode configurar um documento R Markdown em seu projeto
.Rmd
e escrever código em duas linguagens diferentes. Primeiro você precisa carregar a biblioteca reticulada em seu primeiro trecho de código.
```{r} library(reticulate) ```
Agora, quando quiser escrever código Python, você pode envolvê-lo com aspas normais, mas marcá-lo como um trecho de código Python com
{python}
e, quando quiser escrever em R, use
{r}
.
Para nosso primeiro exemplo, suponha que você execute um modelo Python em um conjunto de dados de notas de teste de alunos.
```{python} import pandas as pd import statsmodels.api as sm import statsmodels.formula.api as smf # obtain ugtests data url = “http://peopleanalytics-regression-book.org/data/ugtests.csv" ugtests = pd.read_csv(url) # define model model = smf.ols(formula = “Final ~ Yr3 + Yr2 + Yr1”, data = ugtests) # fit model fitted_model = model.fit() # see results summary model_summary = fitted_model.summary() print(model_summary) ```
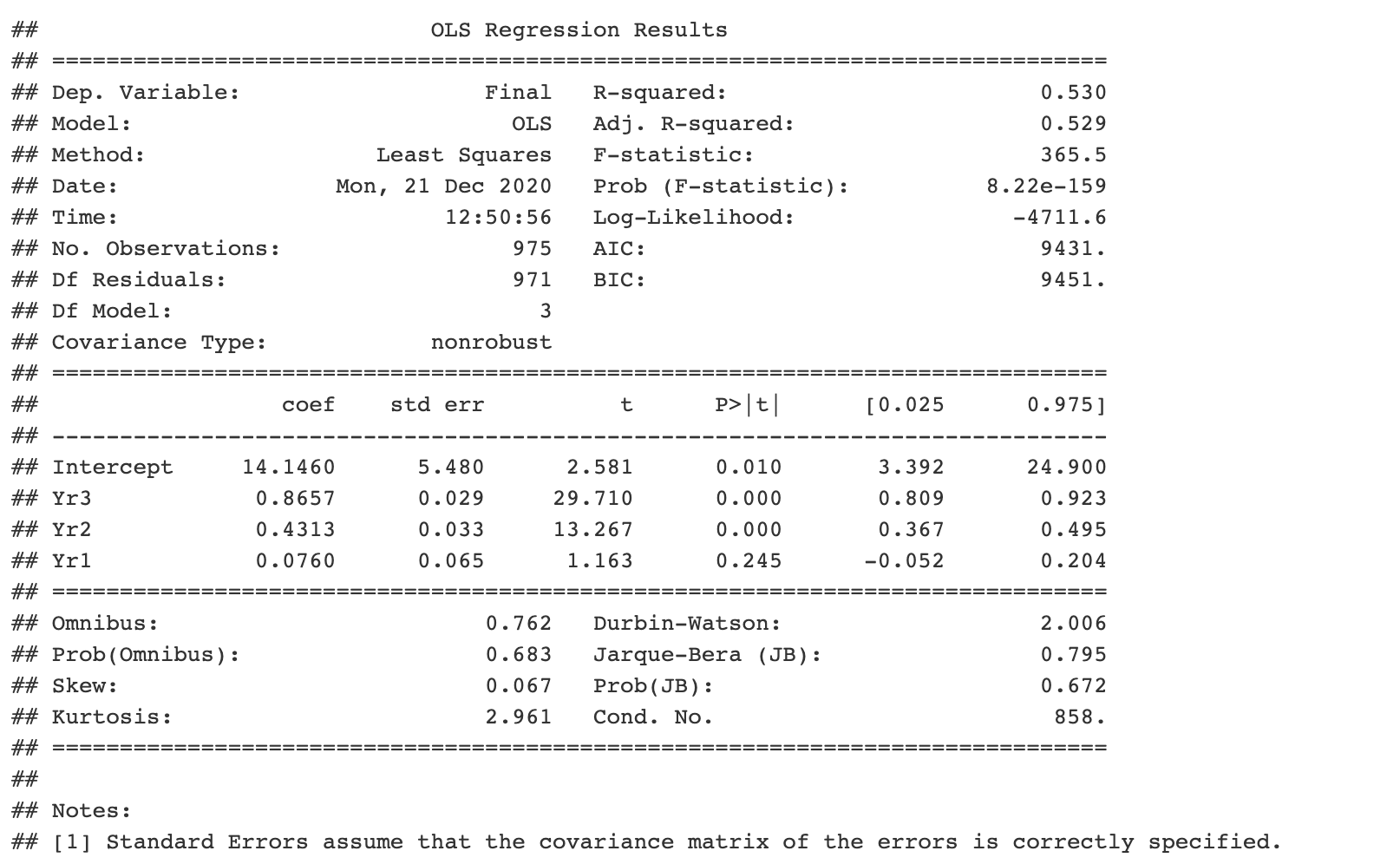
Isso é ótimo, mas digamos que você tenha que sair do emprego por causa de algo mais urgente e passar para o seu colega, o programador R. Você esperava poder diagnosticar o modelo.
Não tenha medo. Você pode acessar todos os objetos Python que criou na lista geral chamada py. Portanto, se um bloco R for criado dentro do seu documento R Markdown, os colegas terão acesso aos parâmetros do seu modelo:
```{r} py$fitted_model$params ```

ou as primeiras sobras:
```{r} py$fitted_model$resid[1:5] ```

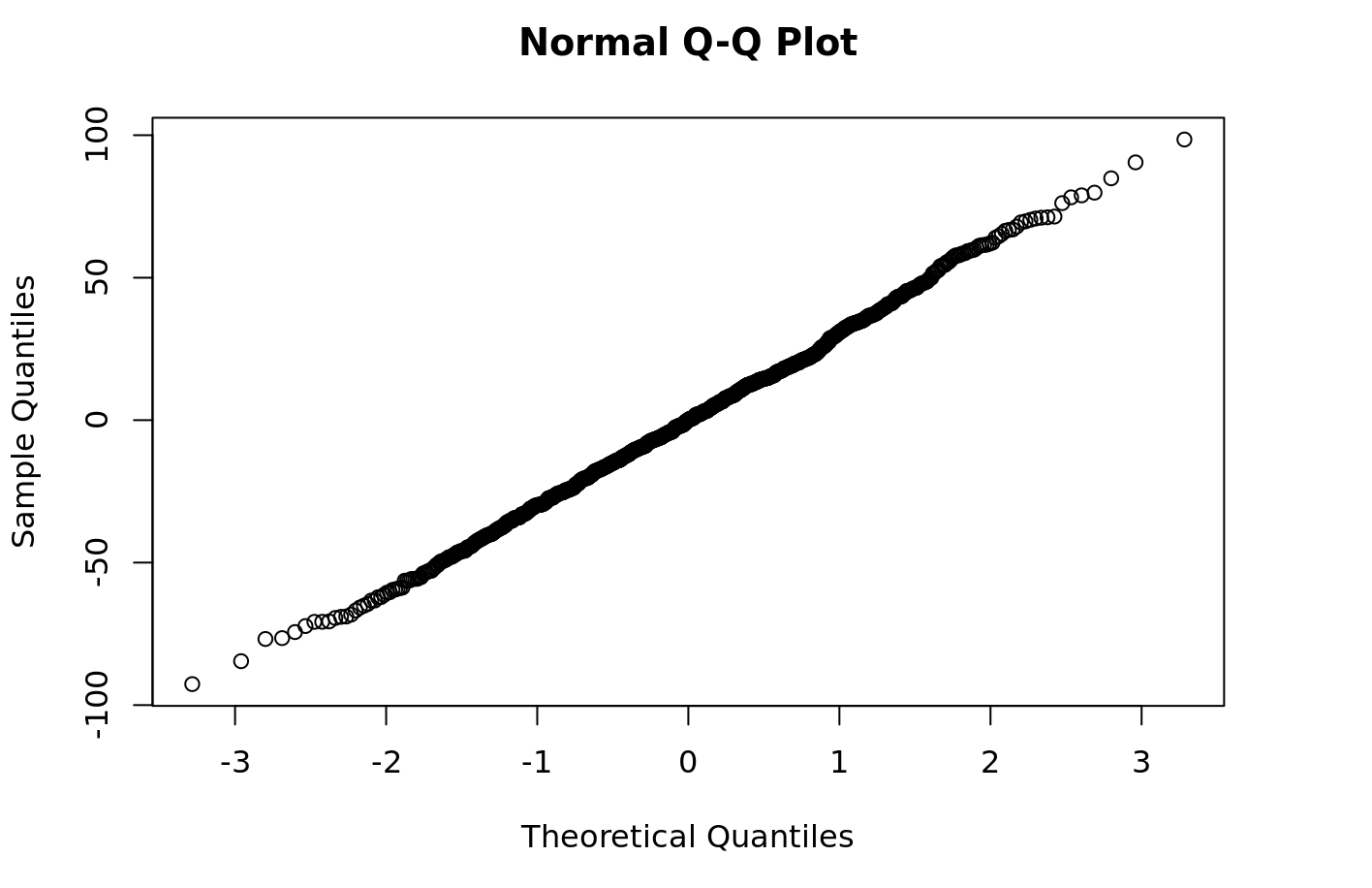
Agora você pode facilmente realizar alguns diagnósticos no modelo, como traçar os resíduos de seu modelo quantil-quantil:
```{r} qqnorm(py$fitted_model$resid) ```
Escrevendo código - segundo exemplo
Você analisou alguns dados de datação do Python e criou um dataframe do pandas com todos os dados nele. Para simplificar, vamos carregar os dados e olhar para eles:
```{python} import pandas as pd url = “http://peopleanalytics-regression-book.org/data/speed_dating.csv" speed_dating = pd.read_csv(url) print(speed_dating.head()) ```

Agora você executou um modelo de regressão logística simples em Python para tentar associar a solução dec com algumas outras variáveis. No entanto, você entende que esses dados são, na verdade, hierárquicos e que o mesmo iid individual pode ter vários conhecidos.
Portanto, você sabe que precisa executar um modelo de regressão logística de efeitos mistos, mas não consegue encontrar nenhum programa Python que faça isso!
E de novo, não tenha medo de nada, mande o projeto para um colega e ele vai escrever a solução na R.
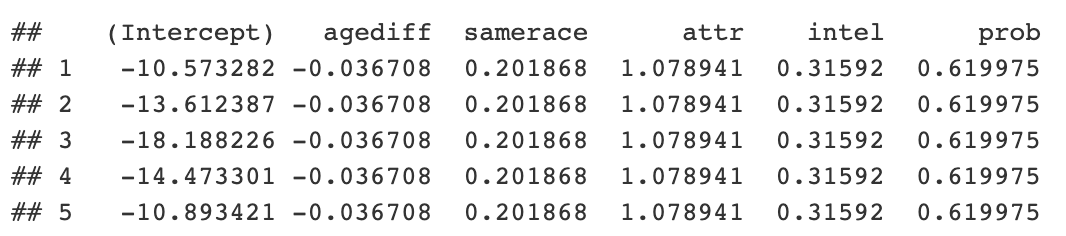
```{r} library(lme4) speed_dating <- py$speed_dating iid_intercept_model <- lme4:::glmer(dec ~ agediff + samerace + attr + intel + prob + (1 | iid), data = speed_dating, family = “binomial”) coefficients <- coef(iid_intercept_model)$iid ```
Agora você pode obter o código e ver as probabilidades. Também é possível acessar objetos Python R dentro de um objeto r genérico.
```{python} coefs = r.coefficients print(coefs.head()) ```
Esses dois exemplos mostram como você pode navegar perfeitamente entre R e Python no mesmo documento R Markdown. Portanto, da próxima vez que você pensar em trabalhar em um projeto de linguagem cruzada, pense em executar todas as etapas em R Markdown. Isso pode evitar o incômodo de alternar entre dois idiomas e ajudar a manter todo o seu trabalho em um só lugar como uma narrativa contínua.
Você pode ver o documento R Markdown finalizado construído em torno da integração da linguagem - com fragmentos de R e Python e objetos movendo-se entre eles - postado aqui . O repositório Github com o código-fonte está aqui .
Os dados de amostra no documento são do meu A referência de modelagem de regressão do People Analytics .

Outras profissões e cursos
PROFISSÃO
CURSOS
- Profissão de desenvolvedor Java
- Profissão de desenvolvedor front-end
- Profissão Web developer
- Profissão Ethical Hacker
- Profissão de desenvolvedor C ++
- Profession Unity Game Developer
- A profissão de desenvolvedor iOS do zero
- A profissão de desenvolvedor Android do zero
CURSOS
- Curso de Aprendizado de Máquina
- Curso avançado "Machine Learning Pro + Deep Learning"
- «Python -»
- JavaScript
- « Machine Learning Data Science»
- DevOps