Para algumas áreas, como PNL, o carro-chefe era o Transformer, que requer grandes quantidades de memória GPU. Modelos realistas simplesmente não cabem na memória. O último método chamado Sharded [lit. 'segmentado'] foi apresentado no artigo Zero da Microsoft, no qual eles desenvolveram um método que aproxima a humanidade de 1 trilhão de parâmetros.
Principalmente para o início de um novo curso de Aprendizado de Máquina, compartilhe com vocês um artigo sobre o Sharded que mostra como usá-lo com o PyTorch hoje para treinar modelos com o dobro da memória e em apenas alguns minutos. Esse recurso no PyTorch agora está disponível por meio de uma colaboração entre as equipes FairScale Facebook AI Research e PyTorch Lightning .

Para quem é este artigo?
Este artigo é para quem usa o PyTorch para treinar modelos. Sharded funciona em qualquer modelo, não importa qual modelo treinar: PNL (transformador), visual (SIMCL, swav, Resnet) ou até mesmo modelos de fala. Aqui está um instantâneo do ganho de desempenho que você pode ver com o Sharded em todos os tipos de modelo.
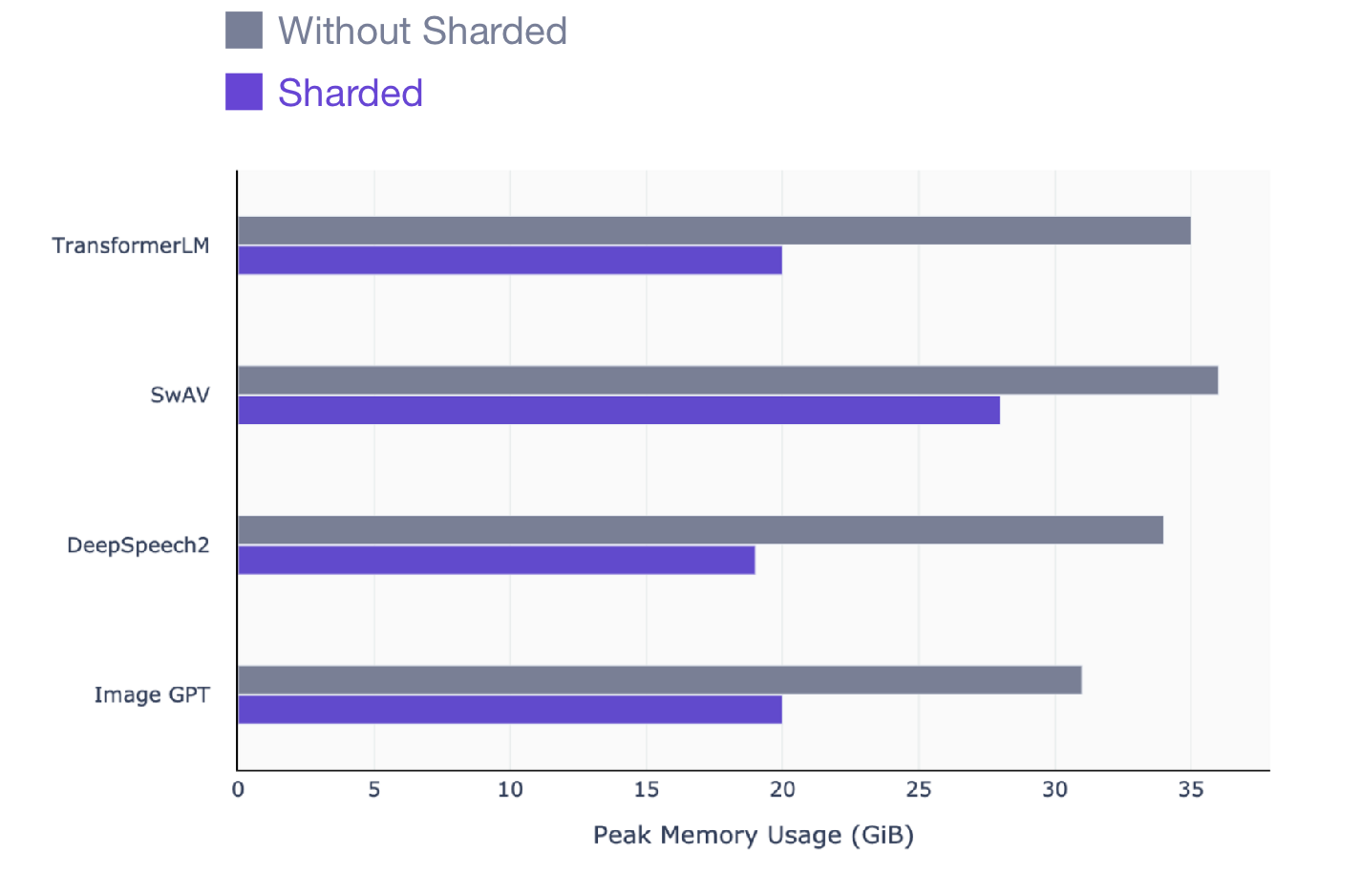
SwAV é um método de aprendizagem baseado em dados de última geração em visão computacional.
DeepSpeech2 é uma técnica moderna para modelos de fala.
Image GPT é um método avançado para modelos visuais.
O Transformer é uma técnica avançada de processamento de linguagem natural.
Como usar o Sharded com PyTorch
Para aqueles que não têm muito tempo para ler a explicação intuitiva de como o Sharded funciona, explicarei imediatamente como usar o Sharded com seu código PyTorch. Mas eu recomendo que você leia o final do artigo para entender como o Sharded funciona.
Sharded foi projetado para ser usado com várias GPUs para aproveitar ao máximo os benefícios disponíveis. Mas treinar em várias GPUs pode ser assustador e muito doloroso de configurar.
A maneira mais fácil de carregar seu código com Sharded é converter seu modelo para PyTorch Lightning (isso é apenas uma refatoração). Aqui está um vídeo de 4 minutos que mostra como converter seu código PyTorch em Lightning.
Depois de fazer isso, ativar o Sharded em 8 GPUs é tão fácil quanto alterar um único sinalizador: nenhuma alteração é necessária em seu código.

Se o seu modelo for de outra biblioteca de aprendizado profundo, ele ainda funcionará com Lightning (NVIDIA Nemo, fast.ai, Hugging Face). Tudo que você precisa fazer é importar seu modelo para o LightningModule e começar a aprender.
from argparse import ArgumentParser
import torch
import torch.nn as nn
import pytorch_lightning as pl
from pytorch_lightning.metrics.functional import accuracy
from transformers import BertModel
class LitBertClassifier(pl.LightningModule):
def __init__(self, n_classes, pretrained_model_name='bert-base-uncased'):
super().__init__()
self.save_hyperparameters()
self.bert = BertModel.from_pretrained(pretrained_model_name)
self.drop = nn.Dropout(p=0.3)
self.out = nn.Linear(self.bert.config.hidden_size, n_classes)
self.loss_fn = nn.CrossEntropyLoss()
def forward(self, input_ids, attention_mask):
outputs = self.bert(
input_ids=input_ids,
attention_mask=attention_mask,
return_dict=False
)
pooled_output = outputs[1]
output = self.drop(pooled_output)
return self.out(output)
def training_step(self, batch, batch_idx):
loss, acc = self._shared_step(batch, batch_idx)
self.log("acc", acc)
return loss
def validation_step(self, batch, batch_idx):
_, acc = self._shared_step(batch, batch_idx)
self.log("val_acc", acc)
def _shared_step(self, batch, batch_idx):
input_ids = batch["input_ids"]
attention_mask = batch["attention_mask"]
targets = batch["targets"]
outputs = self.forward(
input_ids=input_ids,
attention_mask=attention_mask
)
_, preds = torch.max(outputs, dim=1)
loss = self.loss_fn(outputs, targets)
acc = accuracy(preds, targets)
return loss, acc
def configure_optimizers(self):
return torch.optim.AdamW(self.parameters(), lr=2e-5)
if __name__ == '__main__':
# TODO: add your own dataset
train_dataloader = ...
val_dataloader = ...
bert = LitBertClassifier()
trainer = pl.Trainer(gpus=8, plugins='ddp_sharded')
trainer.fit(bert, train_dataloader)
Explicação intuitiva de como funciona o Sharded
Diversas abordagens são usadas para treinar efetivamente em um grande número de GPUs. Em uma abordagem (DP), cada pacote é dividido entre GPUs. Aqui está uma ilustração de DP em que cada parte do pacote é enviada para uma GPU diferente e o modelo é copiado várias vezes para cada uma.

Treinamento de DP
Essa abordagem é ruim, entretanto, porque os pesos do modelo são transmitidos através do dispositivo. Além disso, a primeira GPU oferece suporte a todos os estados do otimizador. Por exemplo, Adam mantém uma cópia completa adicional dos pesos do seu modelo.
Em outra técnica (distribuição de dados paralela, DDP), cada GPU é treinada em um subconjunto dos dados e os gradientes são sincronizados entre as GPUs. Este método também funciona em muitas máquinas (nós). Nesta figura, cada GPU recebe um subconjunto dos dados e inicializa os mesmos pesos do modelo para todas as GPUs. Então, após o passe de volta, todos os gradientes são sincronizados e atualizados.
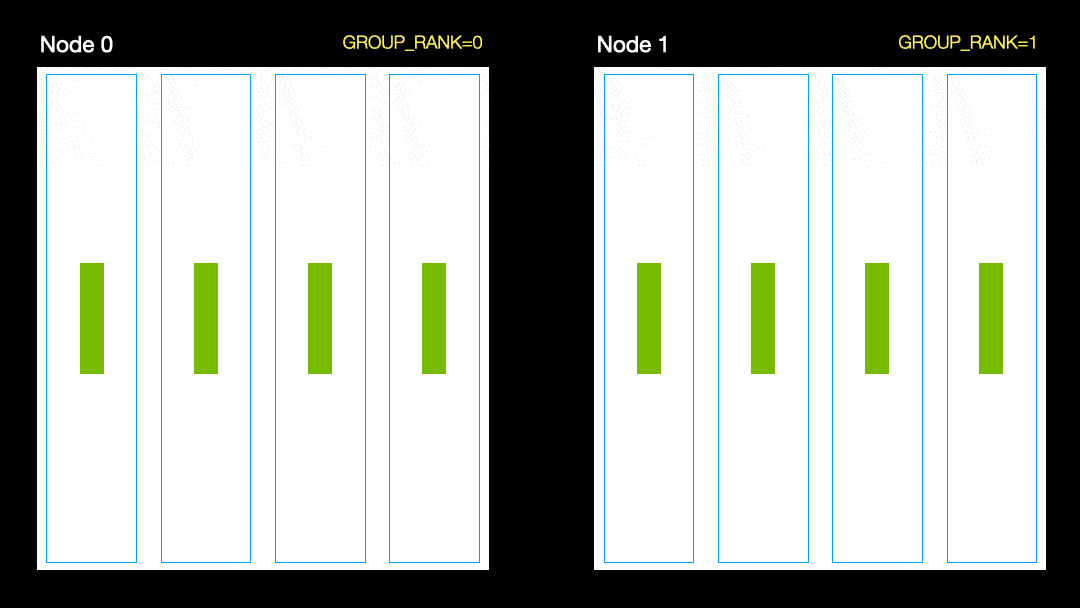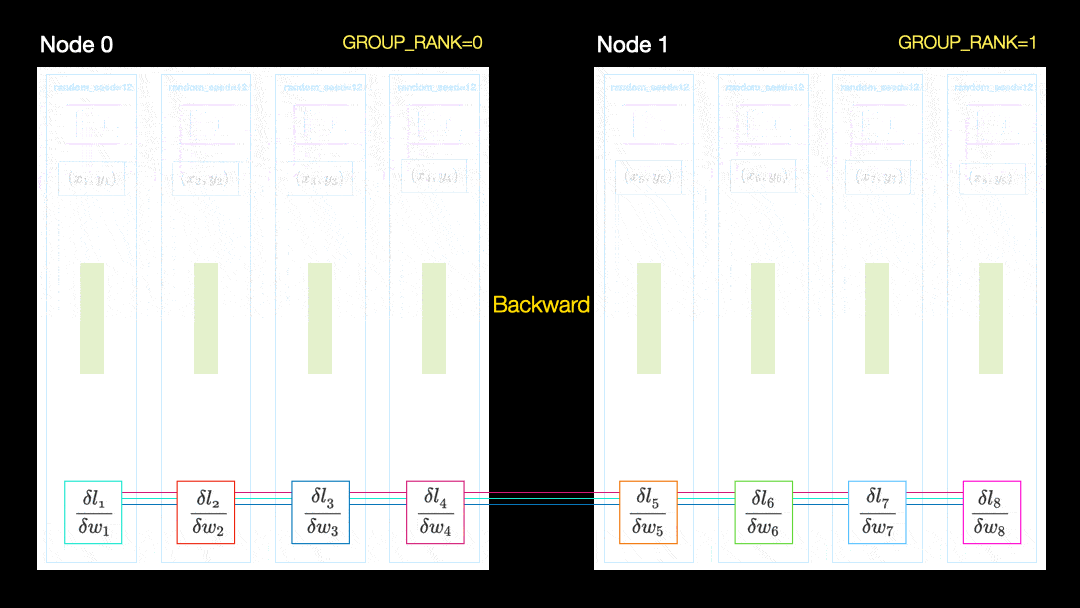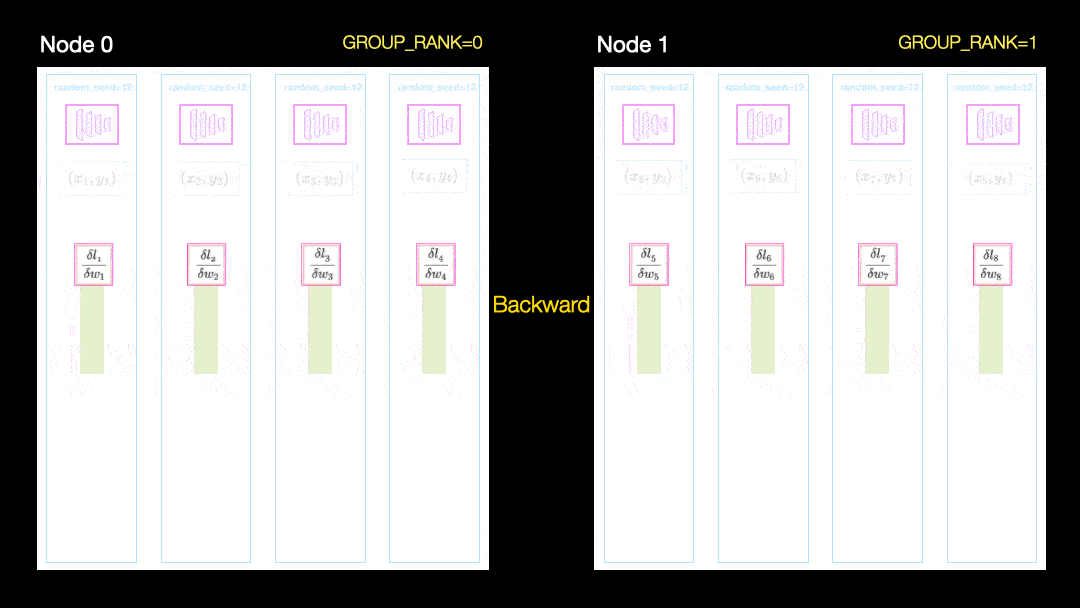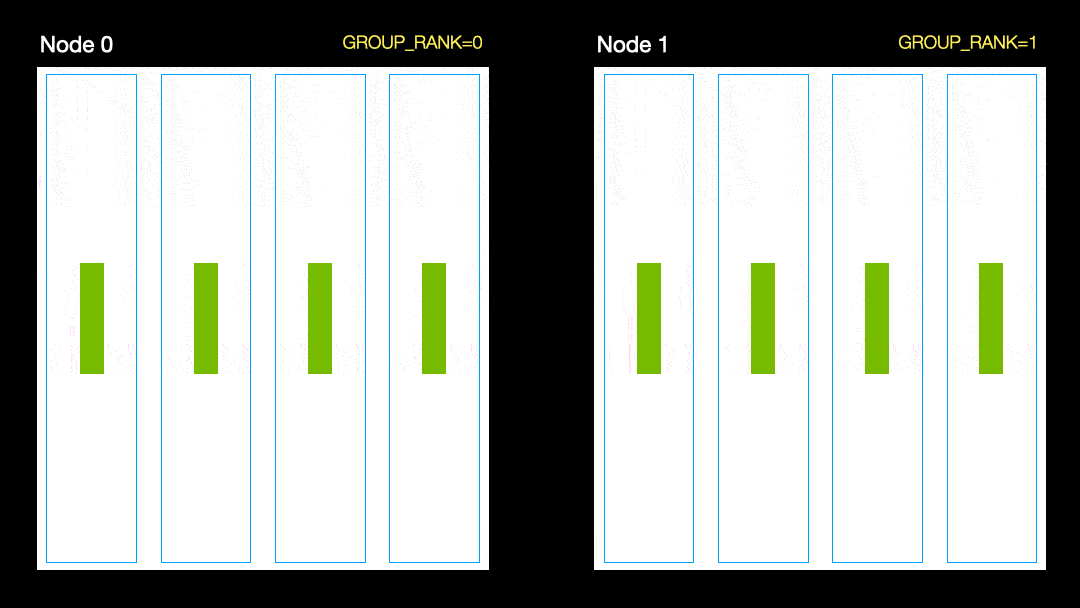
Distribuição de dados paralela
No entanto, este método ainda tem um problema, que é que cada GPU deve manter uma cópia de todos os estados do otimizador (aproximadamente 2 a 3 vezes os parâmetros do modelo), bem como todas as ativações diretas e reversas.
Sharded remove essa redundância. Ele funciona da mesma maneira que o DDP, exceto que toda a sobrecarga (gradientes, estado do otimizador, etc.) é calculada para apenas uma fração dos parâmetros totais e, assim, eliminamos a redundância de armazenar o mesmo gradiente e estados otimizador em todas as GPUs. Em outras palavras, cada GPU armazena apenas um subconjunto de ativações, parâmetros do otimizador e cálculos de gradiente.
Usando algum tipo de modo distribuído

No PyTorch Lightning, mudar os modos de distribuição é trivial.
Como você pode ver, com qualquer uma dessas abordagens de otimização, há muitas maneiras de obter o máximo do aprendizado distribuído.
A boa notícia é que todos esses modos estão disponíveis no PyTorch Lightning sem a necessidade de alterações de código. Você pode experimentar qualquer um deles e ajustar se necessário para o seu modelo específico.
Um método que não existe é o modelo paralelo. No entanto, este método deve ser avisado, pois provou ser muito menos eficaz do que o treinamento segmentado e deve ser usado com cautela. Pode funcionar em alguns casos, mas em geral é melhor usar a fragmentação.
A vantagem de usar o Lightning é que você nunca fica para trás nos últimos avanços na pesquisa de IA! A equipe e a comunidade de código aberto estão empenhados em compartilhar as novidades com você com o Lightning.

- Curso de Aprendizado de Máquina
- Treinamento para a profissão de ciência de dados
- Treinamento de analista de dados
Outras profissões e cursos