Há muito tempo estamos interessados no tópico do uso do Apache Kafka como um data warehouse, considerado de um ponto de vista teórico, por exemplo, aqui . É ainda mais interessante chamar a sua atenção para a tradução de material do blog do Twitter (original - dezembro de 2020), que descreve um uso não convencional do Kafka como banco de dados para processamento e reprodução de eventos. Esperamos que este artigo seja interessante e lhe proporcione novas ideias e soluções ao trabalhar com Kafka .
Introdução
Quando os desenvolvedores consomem dados públicos do Twitter por meio da API do Twitter, eles contam com confiabilidade, velocidade e estabilidade. Portanto, há algum tempo, o Twitter lançou a API Account Activity Replay para a API Account Activity para tornar mais fácil para os desenvolvedores garantir a estabilidade de seus sistemas. A API Account Activity Replay é uma ferramenta de recuperação de dados que permite aos desenvolvedores recuperar eventos de até cinco dias. Essa API restaura eventos que não foram entregues por vários motivos, incluindo travamentos do servidor que ocorreram durante a tentativa de entrega em tempo real.
Os engenheiros do Twitter estavam se esforçando não apenas para criar APIs que fossem bem recebidas pelos desenvolvedores, mas também para:
- Aumentar a produtividade dos engenheiros;
- Torne o sistema fácil de manter. Em particular, para minimizar a necessidade de troca de contexto para desenvolvedores, engenheiros de SRE e todos os outros que lidam com o sistema.
Por isso, ao se trabalhar na criação de um sistema de replay que dependa da API, optou-se por tomar como base o sistema existente de trabalho em tempo real, no qual se baseia a API de Atividade de Conta. Desta forma, foi possível reaproveitar desenvolvimentos existentes e minimizar a troca de contexto e treinamento, o que seria muito mais significativo se um sistema completamente novo fosse criado para o trabalho descrito.
A solução em tempo real é baseada em uma arquitetura publicar-assinar. Para tal, tendo em conta as tarefas e criando o nível de armazenamento da informação a partir do qual será lida, surgiu a ideia de repensar a conhecida tecnologia de streaming - Apache Kafka.
Contexto
Os eventos que ocorrem em tempo real são produzidos em dois data centers. Quando esses eventos são disparados, eles são gravados para publicar-assinar tópicos que são replicados em dois datacenters para redundância.
Nem todos os eventos precisam ser entregues, então todos os eventos são filtrados por um aplicativo interno que consome eventos dos tópicos relevantes, verifica cada um em um conjunto de regras no armazenamento de chave e valor e decide se o evento deve ser entregue a um desenvolvedor específico por meio de uma API pública Os eventos são entregues por meio de um webhook, e cada URL do webhook pertence a um desenvolvedor identificado por um ID exclusivo.
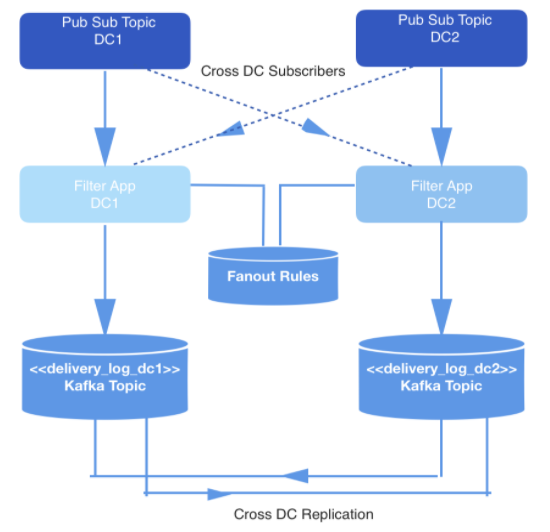
Figura: 1: Pipeline de geração de dados
Armazenamento e segmentação
Normalmente, ao construir um sistema de reprodução que requer tal data warehouse, uma arquitetura baseada em Hadoop e HDFS é escolhida. Nesse caso, ao contrário, o Apache Kafka foi escolhido, por dois motivos:
- O sistema para trabalhar em tempo real era baseado no princípio de publicar-assinar, que era orgânico para o dispositivo Kafka
- A quantidade de eventos que precisam ser armazenados no sistema de reprodução não é em petabytes. Não armazenamos dados por mais de alguns dias. Além disso, lidar com jobs MapReduce para Hadoop é mais caro e mais lento do que consumir dados em Kafka, e a primeira opção não atende às expectativas do desenvolvedor.
Nesse caso, a carga principal recai sobre o pipeline de reprodução de dados em tempo real para garantir que os eventos que precisam ser entregues a cada desenvolvedor sejam armazenados no Kafka. Vamos chamar o tópico Kafka delivery_log; haverá um desses tópicos para cada datacenter. Esses tópicos são replicados para redundância, o que permite que uma solicitação de replicação seja emitida a partir de um único datacenter. Os eventos armazenados dessa forma são desduplicados antes da entrega.
Neste tópico do Kafka, criamos muitas partições usando o sharding semântico padrão. Portanto, as partições correspondem ao hash webhookId do desenvolvedor, e esse id serve como a chave para cada entrada. Era para usar sharding estático, mas no final foi abandonado devido ao risco aumentado de que uma partição contenha mais dados do que outras, se alguns desenvolvedores gerarem mais eventos no decorrer de suas atividades do que outros. Em vez disso, um número fixo de partições foi escolhido para distribuir os dados, e a estratégia de particionamento foi deixada no padrão. Isso reduz o risco de partições desequilibradas e não precisa ler todas as partições no tópico Kafka.
Em contraste, com base no webhookId para o qual a solicitação é feita, o serviço de reprodução determina a partição específica a ser lida e gera um novo consumidor Kafka para essa partição. O número de partições no tópico não muda, uma vez que o hash de chave e a distribuição de eventos dependem disso.
Para minimizar o espaço de armazenamento, as informações são compactadas por meio do algoritmo ágil , pois se sabe que grande parte das informações da tarefa descrita é processada no lado do consumidor. Além disso, o snappy é mais rápido para descompactar do que outros algoritmos de compactação suportados pelo Kafka: gzip e lz4....
Consultas e processamento
Em um sistema projetado dessa forma, a API envia solicitações de reprodução. Como parte da carga útil de cada solicitação validada, vem um webhookId e uma gama de dados para os quais os eventos devem ser reproduzidos. Essas consultas são armazenadas no MySQL por um longo tempo e são enfileiradas até que sejam selecionadas pelo serviço de replay. O intervalo de dados especificado na solicitação é usado para determinar o deslocamento no qual iniciar a leitura do disco. A função do
offsetForTimes
objeto é
Consumer
usada para obter os deslocamentos.
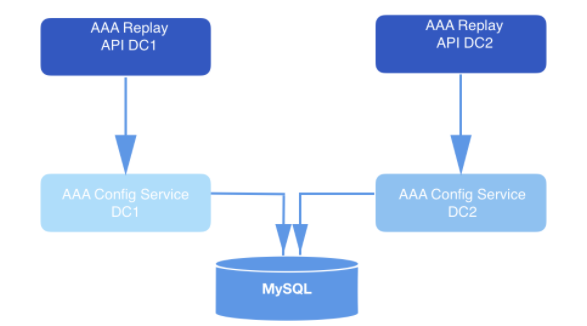
Figura: 2: Sistema de reprodução. Ele recebe a solicitação e a envia ao serviço de configuração (camada de acesso a dados) para posterior armazenamento de longo prazo no banco de dados.
As instâncias do serviço de reprodução tratam de cada solicitação de reprodução. As instâncias são coordenadas entre si usando MySQL para processar o próximo registro de repetição armazenado no banco de dados. Cada processo de trabalho de repetição pesquisa o MySQL periodicamente para ver se há um trabalho para processar. A solicitação vai de um estado para outro. Uma solicitação que não foi selecionada para processamento está no estado ABERTO. A solicitação que acabou de ser removida da fila está no estado INICIADA. A solicitação que está sendo processada atualmente está no estado ONGOING. Uma solicitação que passou por todas as transições está no estado COMPLETED. O fluxo de trabalho de reprodução seleciona apenas solicitações que ainda não iniciaram o processamento (ou seja, no estado ABERTO).
Periodicamente, depois que o processo de trabalho remove a solicitação da fila para processamento, ela é inserida na tabela MySQL, deixando carimbos de data / hora e, portanto, demonstrando que o trabalho de repetição ainda está sendo processado. Nos casos em que uma instância de fluxo de trabalho de reprodução morre antes de concluir o processamento de uma solicitação, esses trabalhos são reiniciados. Portanto, os processos de reprodução desenfileiram não apenas as solicitações no estado ABERTO, mas também selecionam aquelas solicitações que foram transferidas para o estado INICIADO ou EM ANDAMENTO, mas não receberam nenhum feedback no banco de dados após um determinado número de minutos.
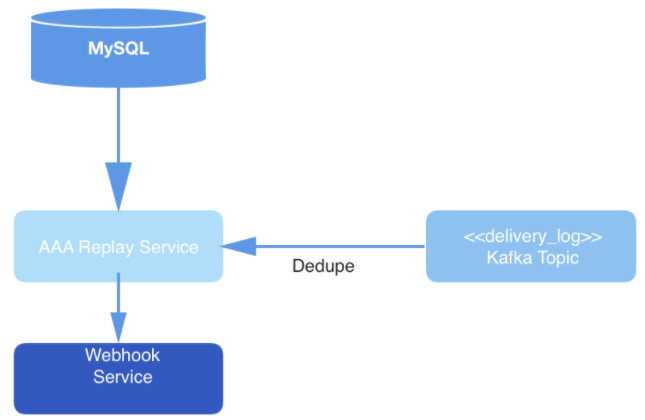
Figura: 3: Camada de entrega de dados: o serviço de replay pesquisa o MySQL para um novo trabalho de processamento de solicitação, consome a solicitação do tópico Kafka e entrega eventos por meio do serviço Webhook.
Eventualmente, os eventos do tópico são desduplicados no processo de leitura e, em seguida, publicados na URL do webhook de um usuário específico. A desduplicação é realizada mantendo um cache de eventos de leitura, que são então hash. Se for detectado um evento com um hash idêntico ao que já está no hash, ele não será entregue.
Em geral, esse uso de Kafka não é tradicional. Mas dentro do framework do sistema descrito, Kafka funciona com sucesso como um data store e participa do trabalho da API, o que contribui tanto para a usabilidade quanto para a facilidade de acesso aos dados na recuperação de eventos. Os pontos fortes do sistema para operação em tempo real foram úteis na estrutura de tal solução. Além disso, a taxa de recuperação de dados em tal sistema atende totalmente às expectativas dos desenvolvedores.