Compiladores AOT e JIT
Os processadores só podem executar um conjunto limitado de instruções - código de máquina. Para que um programa seja executado por um processador, ele deve ser representado como código de máquina.
Existem linguagens de programação compiladas, como C e C ++. Os programas escritos nessas linguagens são distribuídos como código de máquina. Depois que o programa é escrito, um processo especial - o compilador Ahead-of-Time (AOT), geralmente referido simplesmente como o compilador, traduz o código-fonte em código de máquina. O código de máquina é projetado para ser executado em um modelo de processador específico. Processadores com uma arquitetura comum podem executar o mesmo código. Modelos de processadores posteriores geralmente suportam instruções de modelos anteriores, mas não vice-versa. Por exemplo, o código de máquina que usa instruções AVX dos processadores Intel Sandy Bridge não pode ser executado em processadores Intel mais antigos. Existem várias maneiras de resolver esse problema, por exemplo, transferindo partes críticas do programa para uma biblioteca que possui versões para os modelos dos processadores principais.Mas frequentemente os programas são simplesmente compilados para modelos de processador relativamente antigos e não tiram proveito dos novos conjuntos de instruções.
Em contraste com as linguagens de programação compiladas, existem linguagens interpretadas como Perl e PHP. Com essa abordagem, o mesmo código-fonte pode ser executado em qualquer plataforma para a qual exista um interpretador. A desvantagem dessa abordagem é que o código interpretado é mais lento do que o código de máquina que faz o mesmo.
A linguagem Java oferece uma abordagem diferente, um cruzamento entre linguagens compiladas e interpretadas. Os aplicativos Java são compilados em um código intermediário de baixo nível - bytecode.
O nome bytecode foi escolhido porque exatamente um byte é usado para codificar cada operação. Existem cerca de 200 operações em Java 10.
O bytecode é então executado pela JVM, bem como por um programa de linguagem interpretada. Mas como o bytecode tem um formato bem definido, a JVM pode compilá-lo para o código de máquina no tempo de execução. Naturalmente, as versões mais antigas da JVM não serão capazes de gerar código de máquina usando os novos conjuntos de instruções do processador posteriores a elas. Por outro lado, para acelerar um programa Java, ele nem precisa ser recompilado. Basta executá-lo em uma JVM mais recente.
Compilador HotSpot JIT
Diferentes implementações JVM JIT podem implementar o compilador de maneiras diferentes. Neste artigo, examinamos o Oracle HotSpot JVM e sua implementação de compilador JIT. O nome HotSpot vem da abordagem adotada pela JVM para compilar o bytecode. Normalmente, em um aplicativo, apenas pequenas partes do código são executadas com bastante frequência, e o desempenho do aplicativo depende principalmente da velocidade de execução dessas partes específicas. Essas partes do código são chamadas de pontos de acesso e o compilador JIT as compila. Vários julgamentos fundamentam esta abordagem. Se o código for executado apenas uma vez, compilar esse código é uma perda de tempo. Outro motivo são as otimizações. Quanto mais vezes a JVM executa qualquer código, mais estatísticas ela acumula, usando as quais você pode gerar um código mais otimizado.Além disso, o compilador compartilha os recursos da máquina virtual com a própria aplicação, de forma que os recursos gastos na criação de perfil e otimização pudessem ser utilizados para executar a própria aplicação, o que força um certo equilíbrio a ser observado. A unidade de trabalho do compilador HotSpot é um método e um loop.
A unidade de código compilado é chamada de nmethod (abreviação de método nativo).
Compilação em camadas
Na verdade, o HotSpot JVM não tem um, mas dois compiladores: C1 e C2. Seus outros nomes são cliente e servidor. Historicamente, C1 foi usado em aplicativos GUI e C2 em aplicativos de servidor. Os compiladores diferem na rapidez com que começam a compilar o código. C1 começa a compilar o código mais rápido, enquanto C2 pode gerar um código mais otimizado.
Em versões anteriores da JVM, você tinha que escolher um compilador usando os sinalizadores -client para o cliente e -server ou -d64para a sala do servidor. O JDK 6 introduziu o modo de compilação multinível. Grosso modo, sua essência reside em uma transição sequencial do código interpretado para o código gerado pelo compilador C1 e depois C2. No JDK 8, os sinalizadores -client, -server e -d64 são ignorados e no JDK 11 o sinalizador -d64 foi removido e resulta em um erro. Você pode desligar o modo de compilação em camadas com o sinalizador -XX: -TieredCompilation .
Existem 5 níveis de compilação:
- 0 - código interpretado
- 1 - C1 totalmente otimizado (sem criação de perfil)
- 2 - C1 levando em consideração o número de chamadas de método e iterações de loop
- 3 - C1 com perfilamento
- 4 - C2
Sequências típicas de transições entre níveis são mostradas na tabela.
| Seqüência
|
Descrição
|
|---|---|
| 0-3-4 | Intérprete, nível 3, nível 4. Mais comum. |
| 0-2-3-4 | , 4 (C2) . 2. , 3 , , 4. |
| 0-2-4 | , 3 . 4 3. 2 4. |
| 0-3-1 | . 3, , 4 . 1. |
| 0-4 | . |
Code cache
O código de máquina compilado pelo compilador JIT é armazenado em uma área de memória chamada cache de código. Ele também armazena o código de máquina da própria máquina virtual, como o código do interpretador. O tamanho desta área de memória é limitado e, quando está cheia, a compilação é interrompida. Neste caso, alguns dos métodos "quentes" continuarão a ser executados pelo interpretador. Em caso de estouro, a JVM exibe a seguinte mensagem:
Java HotSpot(TM) 64-Bit Server VM warning: CodeCache is full. Compiler has been disabled.
Outra maneira de descobrir sobre um estouro desta área de memória é habilitar o registro do compilador (como fazer isso é discutido abaixo).
O cache de código é configurável da mesma maneira que outras áreas de memória na JVM. O tamanho inicial é especificado pelo parâmetro -XX: InitialCodeCacheSize . O tamanho máximo é especificado pelo parâmetro -XX: ReservedCodeCacheSize . Por padrão, o tamanho inicial é 2496 KB. O tamanho máximo é 48 MB quando a compilação em camadas está desativada e 240 MB quando está ativada.
Desde o Java 9, o cache de código é dividido em 3 segmentos (o tamanho total ainda é limitado pelos limites descritos acima):
- JVM internal (non-method code). , JVM, , . . 5.5 MB. -XX:NonNMethodCodeHeapSize.
- Profiled code. . non-method code . 21.2 MB 117.2 MB . -XX:ProfiledCodeHeapSize.
- Non-profiled code. . non-method code . 21.2 MB 117.2 MB . -XX: NonProfiledCodeHeapSize.
Você pode habilitar o registro do processo de compilação com o sinalizador -XX: + PrintCompilation (é desabilitado por padrão). Quando esse sinalizador é definido, a JVM gravará uma mensagem na saída padrão (STDOUT) toda vez que um método ou loop for compilado. A maioria das mensagens tem o seguinte formato: timestamp compilation_id atributos tiered_level method_name size deopt.
O campo de registro de data e hora é a hora desde o início da JVM.
O campo compilation_id é o ID interno do problema. Geralmente, ele cresce sequencialmente com cada mensagem, mas às vezes a ordem pode estar fora de ordem. Isso pode acontecer quando há vários threads de compilação em execução em paralelo.
O campo de atributos é um conjunto de cinco caracteres que contém informações adicionais sobre o código compilado. Se algum dos atributos não for aplicável, um espaço será exibido. Existem os seguintes atributos:
- % - OSR (substituição na pilha);
- s - o método está sincronizado;
- ! - o método contém um manipulador de exceção;
- b - a compilação ocorreu em modo de bloqueio;
- n - o método compilado é um wrapper para o método nativo.
OSR significa substituição na pilha. A compilação é um processo assíncrono. Quando a JVM decide que um método precisa ser compilado, ele é enfileirado. Enquanto o método está sendo compilado, a JVM continua a executá-lo pelo interpretador. Na próxima vez que o método for chamado novamente, sua versão compilada será executada. No caso de um ciclo longo, esperar pela conclusão do método é impraticável - pode não ser concluído de todo. A JVM compila o corpo do loop e deve começar a executar a versão compilada dele. A JVM armazena o estado dos threads em uma pilha. Para cada método chamado, um novo objeto Stack Frame é criado na pilha, que armazena os parâmetros do método, variáveis locais, valor de retorno e outros valores. Durante o OSR, um novo Stack Frame é criado para substituir o anterior.
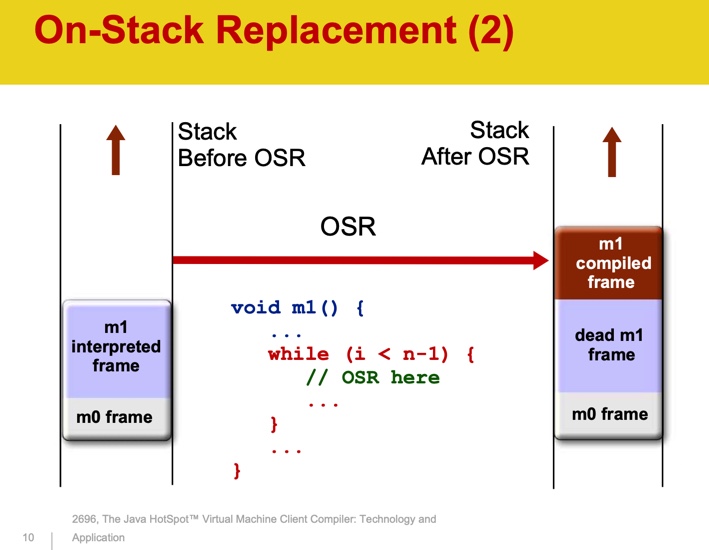
Fonte: The Java HotSpotTM Virtual Machine Client Compiler: Tecnologia e aplicativo
Os atributos "s" e "!" Acho que não precisam de explicação.
O atributo "b" significa que a compilação não ocorreu em segundo plano e não deve ser encontrado nas versões modernas da JVM.
O atributo "n" significa que o método compilado é um wrapper em torno de um método nativo.
O campo tiered_level contém o número do nível no qual o código foi compilado ou pode estar vazio se a compilação em camadas estiver desativada.
O campo method_name contém o nome do método compilado ou o nome do método que contém o loop compilado.
O campo size contém o tamanho do bytecode compilado, não o tamanho do código de máquina resultante. O tamanho está em bytes.
O campo deopt não aparece em todas as mensagens, ele contém o nome da desotimização realizada e pode conter mensagens como “não entrou” e “zumbi feito”.
Às vezes, as seguintes entradas podem aparecer no log: timestamp compile_id COMPILE SKIPPED: reason. Eles significam que algo deu errado quando o método foi compilado. Há momentos em que isso é esperado:
- Cache de código preenchido - é necessário aumentar o tamanho da área de memória do cache de código.
- Carregamento de classe simultâneo - a classe foi modificada em tempo de compilação.
Em todos os casos, exceto para um estouro de cache de código, a JVM tentará recompilar. Caso contrário, você pode tentar simplificar o código.
Se o processo foi iniciado sem o sinalizador -XX: + PrintCompilation, você pode examinar o processo de compilação usando o utilitário jstat . Jstat tem duas opções para exibir informações de compilação.
O parâmetro -compiler exibe um resumo da operação do compilador (5003 é o ID do processo):
% jstat -compiler 5003 Compiled Failed Invalid Time FailedType FailedMethod 206 0 0 1.97 0
Este comando também exibe o número de métodos que falharam na compilação e o nome do último método.
O parâmetro -printcompilation imprime informações sobre o último método compilado. Combinado com o segundo parâmetro, o período de repetição da operação, você pode observar o processo de compilação ao longo do tempo. O exemplo a seguir executa o comando -printcompilation a cada segundo (1000 ms):
% jstat -printcompilation 5003 1000 Compiled Size Type Method 207 64 1 java/lang/CharacterDataLatin1 toUpperCase 208 5 1 java/math/BigDecimal$StringBuilderHelper getCharArray
Planos para a segunda parte
Na próxima parte, veremos os limites do contador nos quais a JVM começa a compilar e como você pode alterá-los. Também veremos como a JVM escolhe o número de threads do compilador, como você pode alterá-lo e quando deve fazê-lo. Finalmente, vamos dar uma olhada rápida em algumas das otimizações realizadas pelo compilador JIT.
Referências e links
- Desempenho do Java: Conselhos detalhados para ajuste e programação do Java 8, 11 e além, Scott Oaks. ISBN: 978-1-492-05611-9.
- Otimizando Java: Técnicas Práticas para Melhorar o Desempenho de Aplicativos JVM, Benjamin J. Evans, James Gough e Chris Newland. ISBN: 978-1-492-02579-5.
- JEP 197: Cache de código segmentado
- O Java HotSpotTM Virtual Machine Client Compiler: Tecnologia e Aplicação