Olá! Meu nome é Dmitry Shelamov e trabalho na Vivid.Money como desenvolvedor de back-end no departamento de atendimento ao cliente. Nossa empresa é uma startup europeia que cria e desenvolve serviços de internet banking para países europeus. Esta é uma tarefa ambiciosa, o que significa que a sua implementação técnica requer uma infraestrutura bem pensada, que pode suportar cargas elevadas e escalar de acordo com os requisitos do negócio.
O projeto é baseado em uma arquitetura de microsserviço que inclui dezenas de serviços em diferentes linguagens. Isso inclui Scala, Java, Kotlin, Python e Go. O último é onde escrevo o código, portanto, os exemplos práticos desta série usarão principalmente Go (e alguns docker-compose).
O trabalho com microsserviços tem características próprias, uma das quais é a organização da comunicação entre os serviços. O modelo de interação nessas comunicações pode ser síncrono ou assíncrono e pode ter um impacto significativo no desempenho e na tolerância a falhas do sistema como um todo.
Comunicação assíncrona
Então, vamos imaginar que temos dois microsserviços (A e B). Vamos supor que a comunicação entre eles é realizada por meio da API e eles não sabem nada sobre a implementação interna um do outro, conforme prescrito pela abordagem de microsserviço. O formato dos dados transmitidos entre eles é pré-acordado.
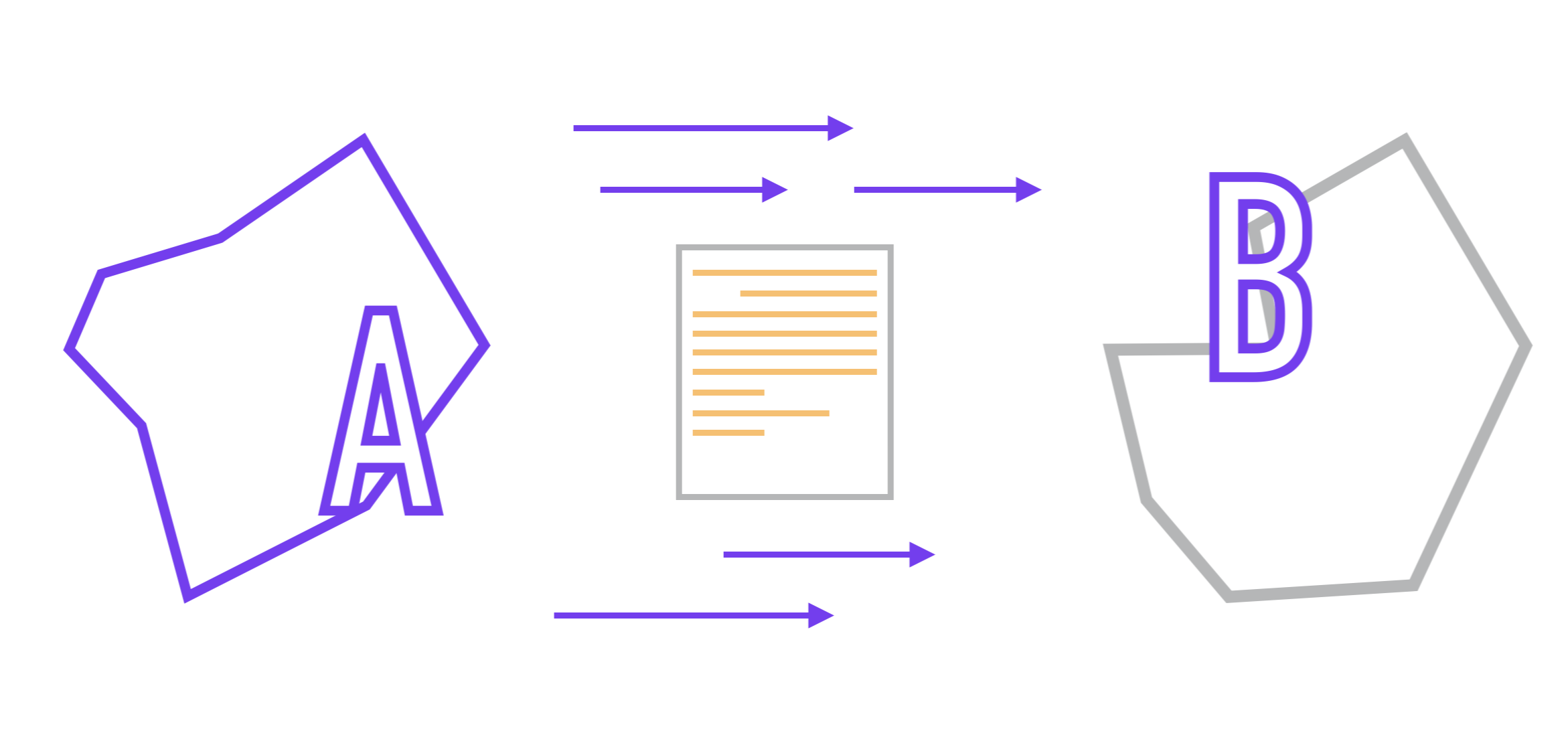
A tarefa que temos pela frente é a seguinte: precisamos organizar a transferência de dados de um aplicativo para outro e, de preferência, com o mínimo de atrasos.
No caso mais simples, a tarefa é realizada por interação síncrona , quando A envia uma solicitação ao aplicativo B, após o que o serviço B a processa e, dependendo se a solicitação foi processada com sucesso ou não, envia uma respostaserviço A que espera essa resposta.
Se a resposta à solicitação não foi recebida (por exemplo, B interrompe a conexão antes de enviar a resposta, ou A cai por tempo limite), o serviço A pode repetir sua solicitação para B.
Por um lado, esse modelo de interação fornece uma certeza do status de entrega de dados para cada solicitação quando o remetente sabe com certeza se os dados foram recebidos pelo destinatário e quais outras ações ele precisa fazer dependendo da resposta.
Por outro lado, o preço a pagar está esperando. Após o envio de uma solicitação, o serviço A (ou thread em que a solicitação é executada) é bloqueado até que receba uma resposta ou considere que a solicitação foi malsucedida de acordo com sua lógica interna, após o que realiza novas ações.
O problema não é apenas a espera e o tempo de inatividade, mas os atrasos na comunicação da rede são inevitáveis. O principal problema é a imprevisibilidade desse atraso. Os participantes da comunicação na abordagem de microsserviço não conhecem os detalhes da implementação uns dos outros, portanto, nem sempre é óbvio para o solicitante se sua solicitação está sendo processada normalmente ou se os dados precisam ser reenviados.
Tudo o que resta com esse modelo de interação é simplesmente esperar. Talvez um nanossegundo, talvez uma hora. E esta figura é bastante real no caso de B, no processo de processamento de dados, realizar alguma operação pesada, como processamento de vídeo.
Talvez o problema não tenha parecido significativo para você - um pedaço de ferro está esperando a resposta do outro, a perda é grande?
Para tornar esse problema mais pessoal, imagine que o serviço A é um aplicativo em execução no seu telefone e, enquanto aguarda uma resposta de B, você vê uma animação de carregamento na tela. Você não pode continuar usando o aplicativo até que o serviço B responda e você terá que esperar. Quantidade de tempo desconhecida. Dado que seu tempo é muito mais valioso do que o tempo de execução de um trecho de código.
Essa aspereza é resolvida da seguinte forma - você divide os participantes da interação em dois "campos": alguns não conseguem trabalhar mais rápido, não importa o quanto você os otimize (processamento de vídeo), enquanto outros não podem esperar mais do que um certo tempo (interface do aplicativo no seu telefone).
Então você substitui a sincronizaçãoa interação entre eles (quando uma parte é forçada a esperar pela outra para se certificar de que os dados foram entregues e processados pelo serviço do destinatário) para assíncrona , ou seja, o modelo de operação enviar e esquecer - neste caso, o serviço A continuará seu trabalho sem esperar por uma resposta de B.
Mas como você pode garantir que a transferência foi bem-sucedida neste caso? Você não pode, por exemplo, depois de enviar um vídeo para um serviço de hospedagem de vídeo, exibir uma mensagem para o usuário: "seu vídeo pode ser processado, mas pode não ser", porque o serviço que baixa o vídeo não recebeu confirmação do processador de serviço de que o vídeo alcançou ele sem incidentes.
Como uma das soluções para este problema, podemos adicionar uma camada entre os serviços A e B, que atuará como um armazenamento temporário e garantidor da entrega de dados a uma taxa conveniente para o remetente e o destinatário. Assim, podemos desacoplar serviços, cuja interação síncrona pode ser potencialmente problemática:
- Os dados perdidos quando o serviço de recebimento é encerrado de forma anormal agora podem ser recuperados do armazenamento temporário novamente enquanto o serviço de envio continua a fazer seu trabalho. Assim, obtemos um mecanismo de garantia de entrega ;
- Essa camada também protege os destinatários de picos de carga, porque o destinatário recebe os dados à medida que são processados, e não quando chegam;
- As solicitações de operações pesadas (como renderização de vídeo) agora podem ser passadas por essa camada, fornecendo menos conectividade entre as partes rápidas e lentas do aplicativo.
Um DBMS comum é bastante adequado para os requisitos acima. Os dados nele podem ser armazenados por um longo tempo sem se preocupar com a perda de informações. A sobrecarga de destinatários também é excluída, pois são livres para escolher o ritmo e os volumes de leitura dos registros que lhes são destinados. A confirmação do processamento pode ser realizada marcando os registros lidos nas tabelas correspondentes.
No entanto, escolher um DBMS como ferramenta de troca de dados pode levar a problemas de desempenho à medida que a carga aumenta. Isso ocorre porque a maioria dos bancos de dados não foi projetada para esse caso de uso. Além disso, muitos DBMS não têm a capacidade de dividir clientes conectados em destinatários e remetentes (Pub / Sub) - neste caso, a lógica de entrega de dados deve ser implementada no lado do cliente.
Provavelmente precisamos de algo mais especializado do que um banco de dados.
Corretores de mensagens
Um corretor de mensagens (fila de mensagens) é um serviço separado responsável por armazenar e entregar dados de serviços de remetente para serviços de destinatário usando o modelo Pub / Sub.
Este modelo assume que a comunicação assíncrona segue a seguinte lógica de duas funções:
- Os editores publicam novas informações como mensagens agrupadas por algum atributo;
- Os assinantes assinam fluxos de mensagens com atributos específicos e os processam.
O atributo de agrupamento de mensagens é a fila , necessária para separar os fluxos de dados - portanto, os destinatários podem se inscrever apenas nos grupos de mensagens de seu interesse.
Por analogia com as assinaturas em várias plataformas de conteúdo - ao assinar um autor específico, você pode filtrar o conteúdo, optando por assistir apenas o que lhe interessa.

A fila pode ser considerada um canal de comunicação estendido entre o gravador e o leitor. Os redatores colocam as mensagens em uma fila, após o que são “enviadas” para os leitores que se inscreveram nessa fila. Um leitor recebe uma mensagem por vez, após o que se torna inacessível para outros leitores.
Uma mensagem, por outro lado, é uma unidade de dados, geralmente consistindo em um corpo de mensagem e metadados do broker.
Em geral, um corpo é uma coleção de bytes em um formato específico.
O destinatário deve conhecer esse formato para poder desserializar seu corpo para processamento posterior após receber uma mensagem.
Você pode usar qualquer formato conveniente, no entanto, é importante lembrar sobre a compatibilidade com versões anteriores, que é suportada, por exemplo, pelo binário Protobuf e a estrutura Apache Avro.
A maioria dos corretores de mensagens baseados em AMQP (Advanced Message Queuing Protocol) trabalham de acordo com esse princípio, um protocolo que descreve um padrão para mensagens tolerantes a falhas por meio de filas.
Essa abordagem nos oferece várias vantagens importantes:
- Coesão fraca. Isso é feito por meio da transmissão de mensagens assíncronas: ou seja, o remetente descarta os dados e continua a trabalhar sem esperar uma resposta do destinatário, e o destinatário lê e processa as mensagens quando é conveniente para ele e não quando foram enviadas. Nesse caso, a fila pode ser comparada a uma caixa de correio em que o carteiro guarda suas cartas e você as apanha quando quer.
- . , ( , ), - .
, . - . - . , , : , , , -, .
- . “at least once” “at most once”.
No máximo uma vez elimina o reprocessamento de mensagens, mas permite que sejam perdidas. Nesse caso, o corretor entregará as mensagens aos destinatários na base do “enviar e esquecer”. Se o destinatário não puder, por algum motivo, processar a mensagem na primeira tentativa, o corretor não a enviará novamente.
Pelo menos uma vez , por outro lado, garante que o destinatário receberá a mensagem, mas existe a possibilidade de reprocessar as mesmas mensagens.
Freqüentemente, essa garantia é alcançada usando o mecanismo Ack / Nack (confirmação / confirmação negativa) , que prescreve o reenvio de uma mensagem se o destinatário, por algum motivo, não puder processá-la.
Assim, para cada mensagem enviada pelo broker (mas ainda não processada), existem três estados finais - o receptor retornou Ack (processamento bem-sucedido), Nack retornou (processamento malsucedido) ou interrompeu a conexão. Os dois últimos cenários resultam no reenvio e reprocessamento da mensagem.
No entanto, o intermediário pode reenviar a mensagem mesmo se o receptor processa a mensagem com êxito. Por exemplo, se o destinatário processou a mensagem, mas saiu sem enviar um sinal de confirmação para o corretor.
Nesse caso, o corretor colocará a mensagem na fila novamente, após o qual será processada novamente, o que pode levar a erros e corrupção de dados se o desenvolvedor não tiver fornecido um mecanismo para eliminar duplicatas do lado do destinatário.
É importante destacar que existe uma outra garantia de entrega chamada “exatamente uma vez” . É difícil de conseguir em sistemas distribuídos, mas também é o mais desejável.
A este respeito, o Apache Kafka, de que falaremos mais tarde, destaca-se favoravelmente no contexto de muitas soluções disponíveis no mercado. Desde a versão 0.11, Kafka oferece uma garantia de entrega exatamente uma vezdentro de um cluster e transações, enquanto os corretores AMQP não podem fornecer tais garantias. Transações em Kafka é um tópico para uma publicação separada, hoje começaremos por conhecer o Apache Kafka.
Apache Kafka
Parece-me que será útil para a compreensão começar a história sobre Kafka com uma representação esquemática do dispositivo de cluster.
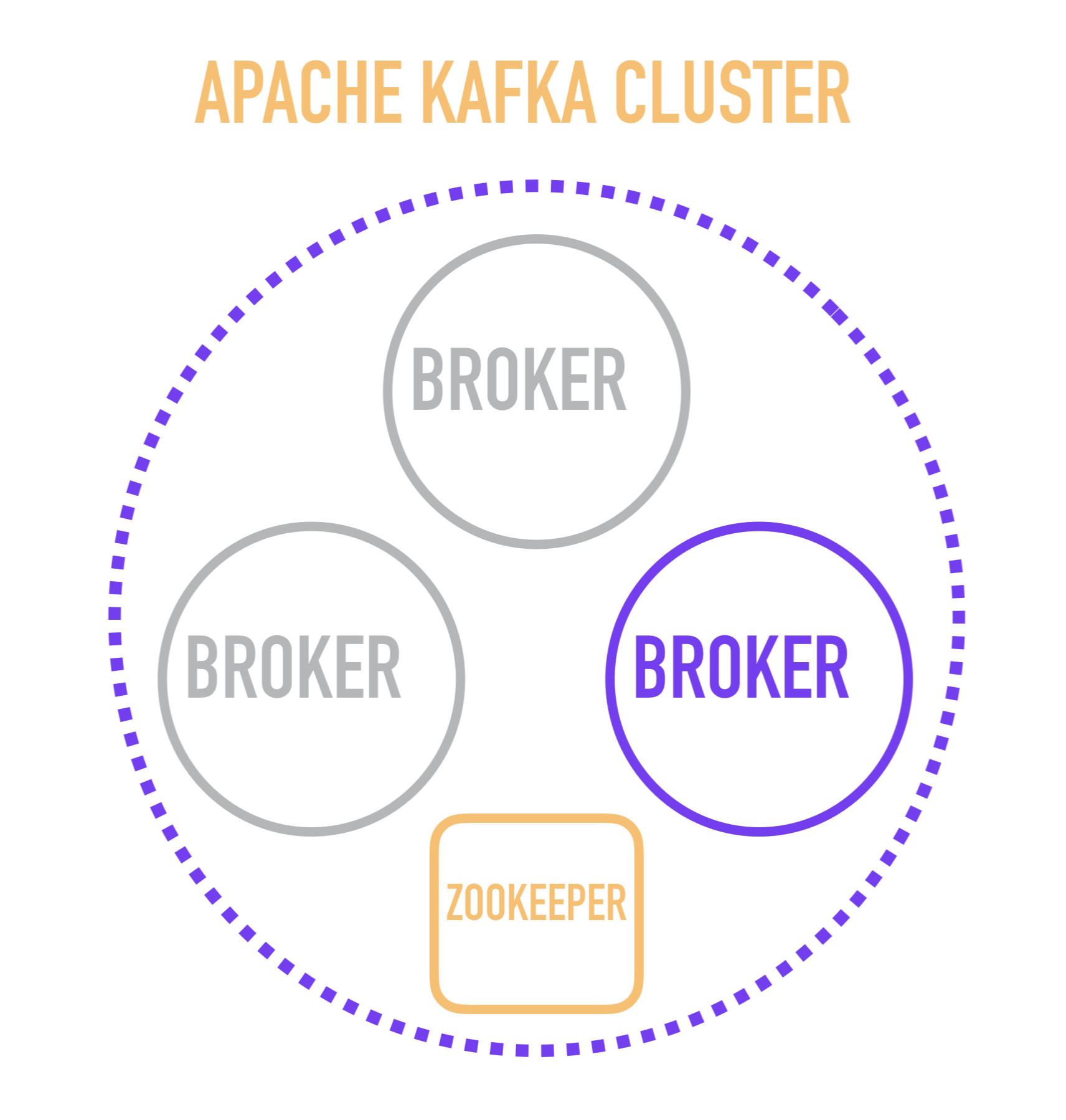
Um servidor Kafka separado é chamado de corretor . Os corretores formam um cluster no qual um desses corretores atua como um controlador que assume algumas das operações administrativas (marcadas em roxo).
A escolha de um corretor-controlador, por sua vez, é de responsabilidade de um serviço separado - ZooKeeper, que também realiza descoberta de serviço de corretores, armazena configurações e participa da distribuição de novos leitores entre corretores e, na maioria dos casos, armazena informações sobre a última mensagem lida para cada um dos leitores. Este é um ponto importante, cujo estudo requer que você desça um nível e considere como um corretor individual funciona internamente.
Registro de confirmação
A estrutura de dados por trás do Kafka é chamada de log de commits ou log de commits.

Novos itens adicionados ao log de confirmação são colocados estritamente no final, e sua ordem depois disso não é alterada, de forma que em cada log individual os itens são sempre listados na ordem em que foram adicionados.
A propriedade de ordenação do log de confirmação permite que ele seja usado, por exemplo, para replicação de acordo com o princípio de consistência eventual entre réplicas de banco de dados: eles armazenam um log de alterações feitas nos dados no nó mestre, cuja aplicação sequencial nos nós escravos permite que você traga os dados neles para aquele acordado com o mestre mente.
No Kafka, esses logs são chamados de partições , e os dados armazenados neles são chamados mensagens .
O que é uma mensagem? É a unidade básica de dados no Kafka e é simplesmente uma coleção de bytes na qual você pode passar informações arbitrárias - seu conteúdo e estrutura são irrelevantes para o Kafka. A mensagem pode conter uma chave, que também é um conjunto de bytes. A chave permite obter mais controle sobre o mecanismo de distribuição de mensagens para partições.
Partições e tópicos
Por que isso pode ser importante? O fato é que uma partição não é análoga a uma fila em Kafka, como pode parecer à primeira vista. Deixe-me lembrá-lo de que, tecnicamente, uma fila de mensagens é um meio de agrupar e gerenciar fluxos de mensagens, permitindo que determinados leitores se inscrevam apenas em determinados fluxos de dados.
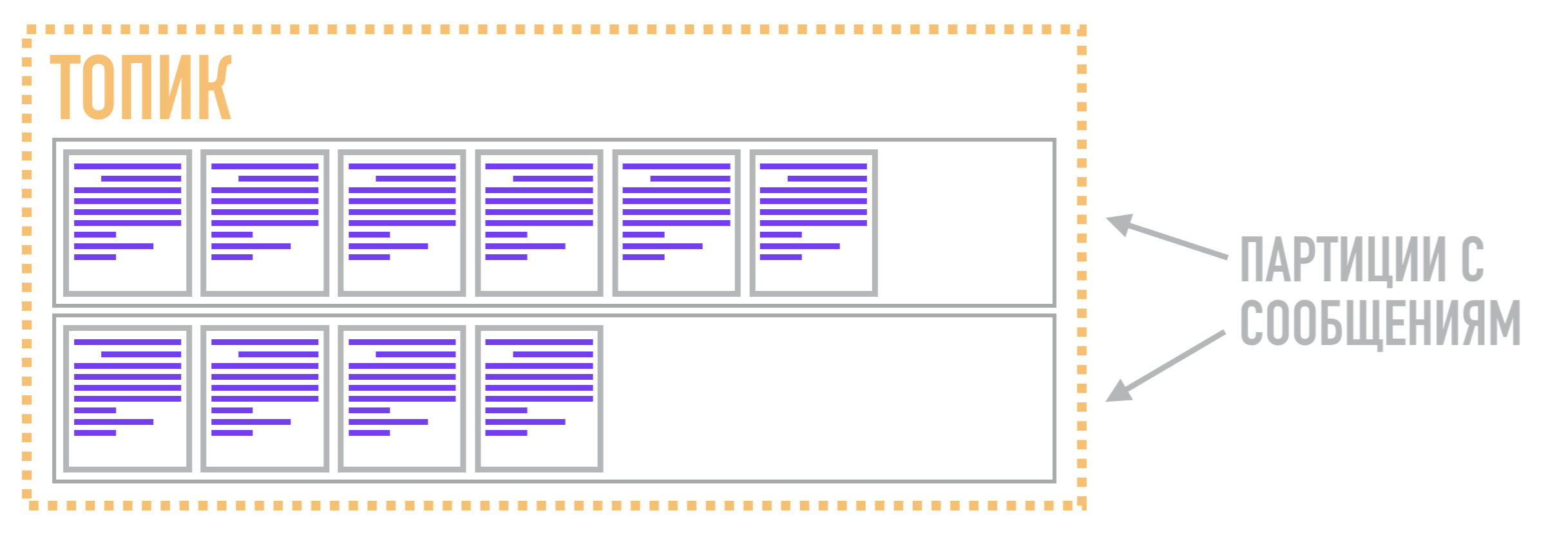
Portanto, no Kafka, a função da fila não é executada pela partição, mas pelo tópico . É necessário combinar várias partições em um fluxo comum. As próprias partições, como dissemos anteriormente, armazenam mensagens em uma forma ordenada de acordo com a estrutura de dados do log de confirmação. Assim, uma mensagem relacionada a um tópico pode ser armazenada em duas partições diferentes, de onde os leitores podem retirá-la mediante solicitação.
Portanto, a unidade de paralelismo no Kafka não é um tópico (ou uma fila nos brokers AMQP), mas uma partição. Devido a isso, o Kafka pode processar diferentes mensagens relacionadas ao mesmo tópico em vários corretores ao mesmo tempo, e também replicar não o tópico inteiro como um todo, mas apenas partições individuais, fornecendo flexibilidade e escalabilidade adicionais em comparação com os corretores AMQP.
Puxe e empurre
Observe que não usei acidentalmente a palavra "puxa" em relação ao leitor.
Nos brokers descritos anteriormente, as mensagens são entregues empurrando-as ( push ) para os destinatários por meio de um canal condicional na forma de uma fila.
No próprio processo de entrega Kafka não é: cada leitor é responsável por puxar ( puxar ) mensagens das partições, que ele lê.
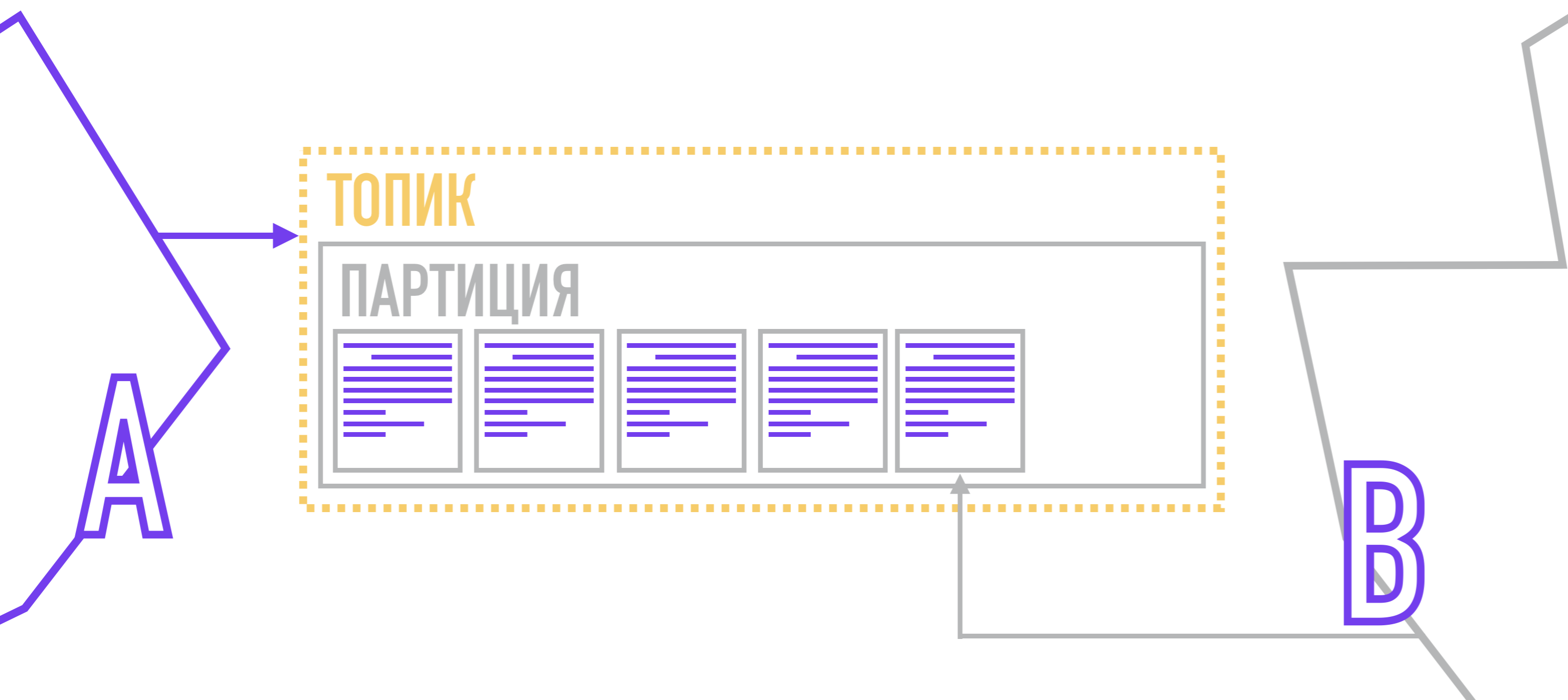
Os produtores, formando mensagens, anexam uma chave e um número de partição a ela. O número da partição pode ser escolhido aleatoriamente (round-robin) se a mensagem não tiver uma chave.
Se precisar de mais controle, você pode anexar uma chave à mensagem e, em seguida, usar a função hash ou escrever seu próprio algoritmo pelo qual a partição para a mensagem será selecionada. Após a formação, o produtor envia uma mensagem ao Kafka, que a salva em disco, informando a qual partição pertence.
Cada destinatário é atribuído a uma partição específica (ou várias partições) no tópico de interesse, e quando uma nova mensagem aparece, ele recebe um sinal para ler o próximo item no log de commit, enquanto observa a última mensagem que leu. Assim, ao se reconectar, ele saberá qual mensagem ler a seguir.
Quais são as vantagens dessa abordagem?
- . , , . , ( Retention Policy, ), .
- Message Replay. , . , , .
- . , ( ) – , .
- . (batch) , , . : (1 ), .
As desvantagens dessa abordagem incluem trabalhar com mensagens de problemas. Ao contrário dos corretores clássicos, as mensagens interrompidas (que não podem ser processadas levando em consideração a lógica existente do destinatário ou devido a problemas com a desserialização) não podem ser enfileiradas indefinidamente até que o destinatário aprenda a processá-las corretamente.
No Kafka, por padrão, a leitura de mensagens da partição para quando o destinatário chega à mensagem quebrada e até que ela seja ignorada e jogada na fila de “quarentena” (também chamada de “ fila de mensagens mortas ”) para processamento posterior, continue lendo a partição. não funciona.
Também em Kafka é mais difícil (em comparação com brokers AMQP) implementar a prioridade da mensagem. Isso decorre diretamente do fato de que as mensagens nas partições são armazenadas e lidas estritamente na ordem em que foram adicionadas. Uma das maneiras de contornar essa limitação no Kafka é criar vários tópicos para mensagens com prioridades diferentes (os tópicos serão diferentes apenas no nome), por exemplo, events_low, events_medium, events_high e, em seguida, implementar a lógica de leitura de prioridade dos tópicos listados no lado do aplicativo do consumidor.
Outra desvantagem dessa abordagem está relacionada ao fato de ser necessário manter o registro da última mensagem lida na partição por cada um dos leitores. Devido à simplicidade da estrutura das partições, esta informação é apresentada na forma de um valor inteiro denominado deslocamento (deslocamento). O deslocamento permite que você determine qual mensagem está sendo lida por cada um dos leitores. A analogia mais próxima do deslocamento é o índice de um elemento em uma matriz, e o processo de leitura é semelhante a percorrer uma matriz em um loop usando um iterador como índice do elemento.
No entanto, essa desvantagem é nivelada devido ao fato de que Kafka, a partir da versão 0.9, armazena offsets para cada usuário em um tópico especial __consumer_offsets (antes da versão 0.9, offsets eram armazenados no ZooKeeper).
Além disso, você pode controlar os deslocamentos diretamente do lado do destinatário.

O escalonamento também se torna mais complicado: deixe-me lembrá-lo de que nos brokers AMQP, a fim de acelerar o processamento do fluxo de mensagens, você só precisa adicionar várias instâncias do serviço do leitor e inscrevê-los em uma fila, e não precisa fazer nenhuma mudança na configuração do próprio broker.
No entanto, o dimensionamento é um pouco mais complicado no Kafka do que nos corretores AMQP. Por exemplo, se você adicionar outra cópia do leitor e configurá-la na mesma partição, obterá eficiência zero, pois, neste caso, ambas as instâncias lerão o mesmo conjunto de dados.
Portanto, a regra básica para o dimensionamento Kafka é que o número de leitores competitivos (ou seja, um grupo de serviços que implementam a mesma lógica de processamento (réplicas)) de um tópico não deve exceder o número de partições neste tópico, caso contrário, algum par de leitores processará o mesmo conjunto de dados.
Grupo de Consumidores
Para evitar a situação com a leitura de uma partição por leitores concorrentes, é comum em Kafka combinar várias réplicas de um serviço em um grupo de consumidores , dentro do qual o Zookeeper atribuirá não mais do que um leitor a uma partição.
Uma vez que os leitores são vinculados diretamente à partição (embora o leitor geralmente não saiba nada sobre o número de partições no tópico), o ZooKeeper, quando um novo leitor é conectado, redistribui os participantes no Grupo de Consumidores de modo que cada partição tenha um e apenas um leitor.
O leitor designa seu Grupo de Consumidores ao se conectar a Kafka.
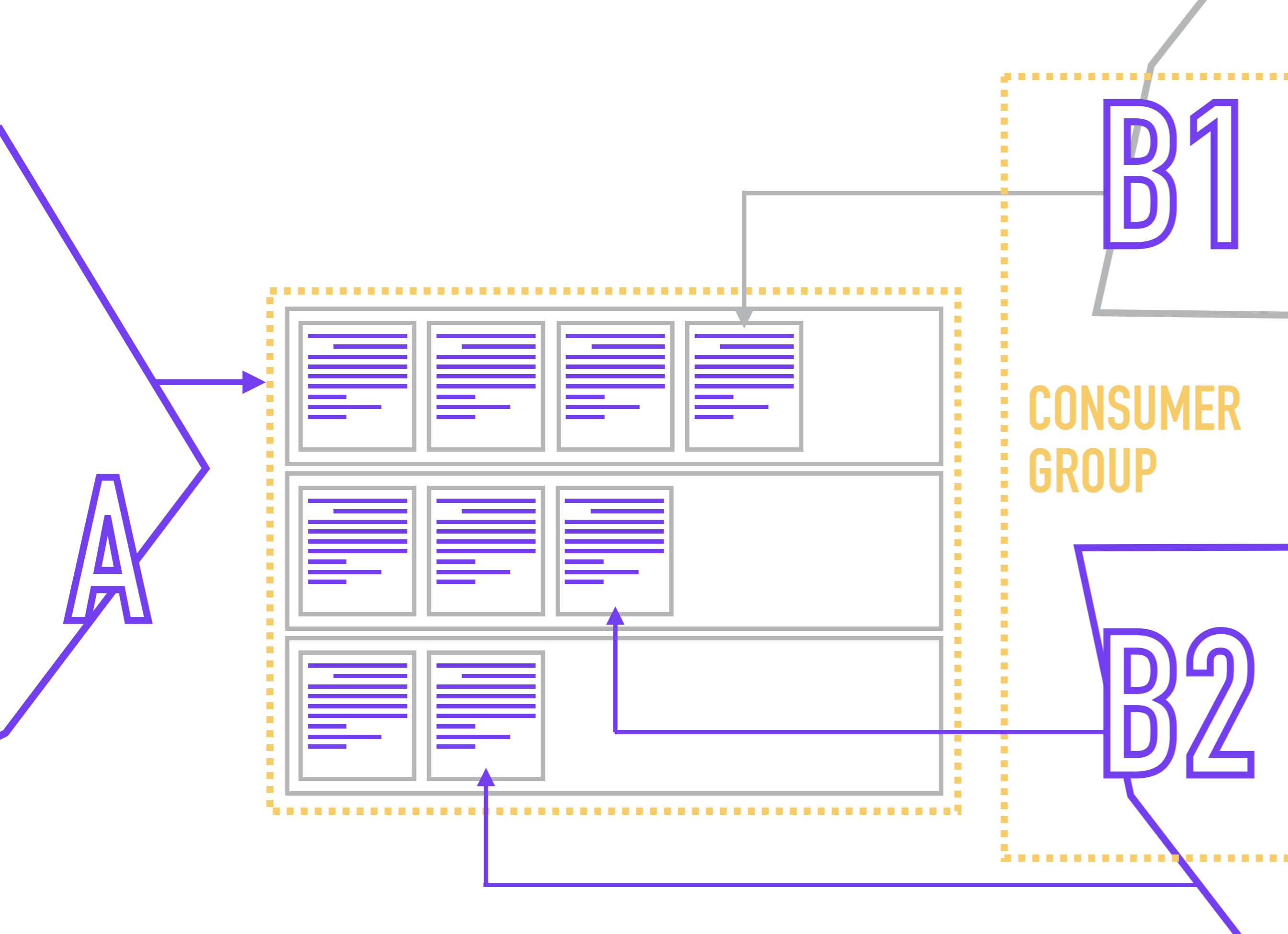
Ao mesmo tempo, nada impede que você pendure vários leitores com diferentes lógicas de processamento em uma partição. Por exemplo, você armazena em um tópico uma lista de eventos por ações do usuário e deseja usar esses eventos para gerar várias visualizações dos mesmos dados (por exemplo, para analistas de negócios, analistas de produto, analistas de sistema e o pacote Yarovaya) e, em seguida, enviá-los para os armazenamentos apropriados.
Mas aqui podemos enfrentar outro problema, causado pelo fato de Kafka usar uma estrutura de tópicos e partições. Recordo que o Kafka não garante a ordenação das mensagens dentro de um tópico, apenas dentro de uma partição, o que pode ser crítico, por exemplo, ao gerar relatórios sobre as ações do usuário e enviá-los para o armazenamento as is.
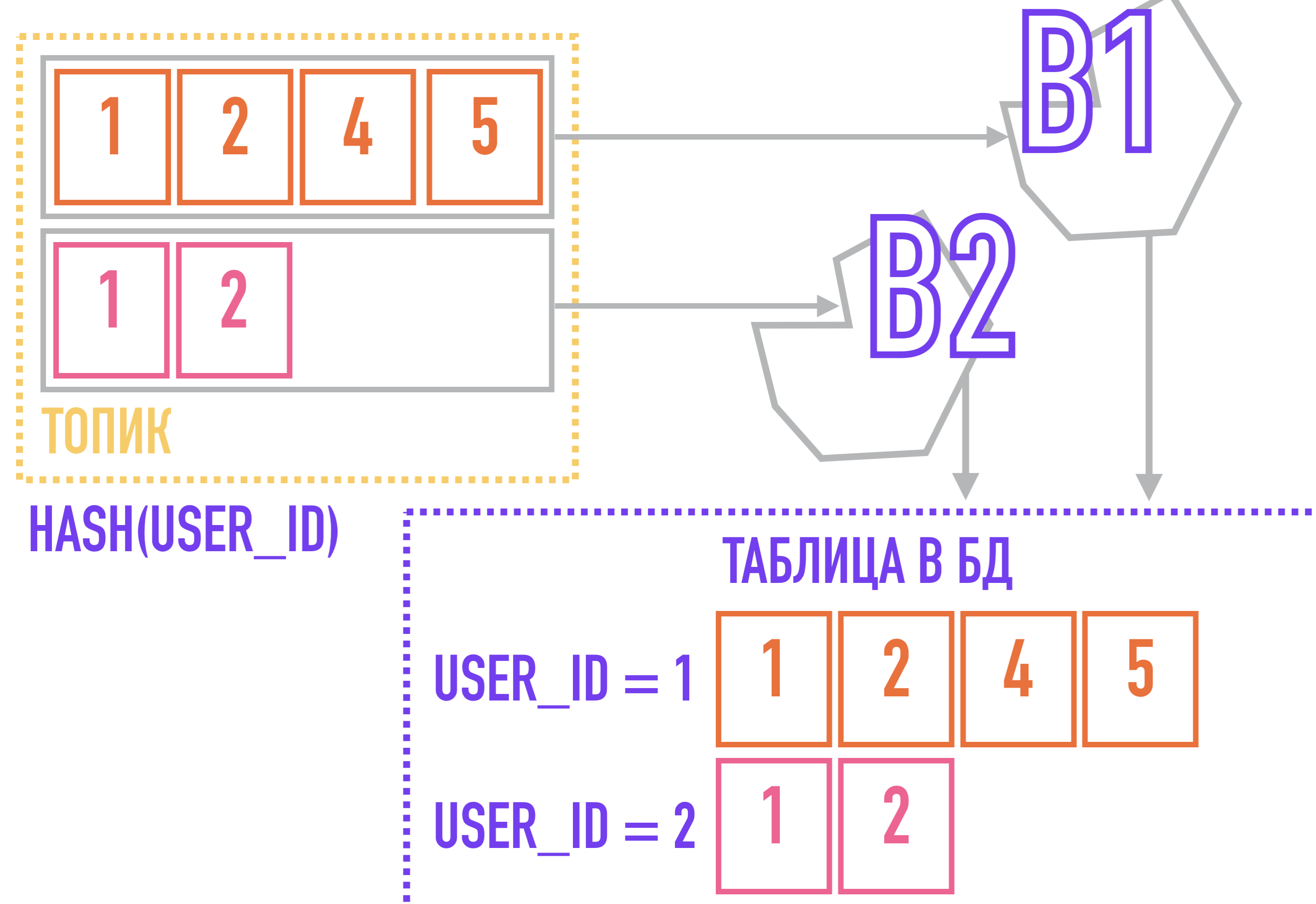
Para resolver este problema, podemos ir do contrário: se todos os eventos relacionados a uma entidade (por exemplo, todas as ações relacionadas ao mesmo user_id) serão sempre adicionados à mesma partição, eles serão ordenados dentro do tópico simplesmente porque estão na mesma partição, cuja ordem é garantida por Kafka.
Para fazer isso, precisamos de uma chave para mensagens: por exemplo, se usarmos um algoritmo que calcula o hash da chave para selecionar a partição à qual a mensagem será adicionada, as mensagens com a mesma chave estarão garantidas em uma partição e, portanto, retirarão o destinatário da mensagem com a mesma chave na ordem em que foram adicionadas ao tópico.
Em um caso com um fluxo de eventos sobre ações do usuário, a chave de particionamento pode ser user_id.
Política de retenção
Agora é hora de falar sobre a Política de Retenção.
Esta é uma configuração que é responsável por excluir mensagens do disco quando os limites para a data de adição ( Política de retenção baseada no tempo ) ou o espaço ocupado no disco ( Política de retenção baseada no tamanho ) são excedidos .
- Se você configurar o TBRP para 7 dias, todas as mensagens com mais de 7 dias serão sinalizadas para exclusão posterior. Em outras palavras, essa configuração garante que as mensagens abaixo do limite de idade estejam disponíveis para leitura a qualquer momento. Pode ser definido em horas, minutos e milissegundos.
- O SBRP funciona de maneira semelhante: quando o limite de espaço em disco é excedido, as mensagens são marcadas para exclusão no final (mais antigas). Deve-se ter em mente: como a exclusão das mensagens não é instantânea, o espaço ocupado em disco será sempre um pouco maior do que o especificado na configuração. Definido em bytes.
A política de retenção pode ser configurada para todo o cluster e para tópicos individuais: por exemplo, as mensagens em um tópico para rastrear ações do usuário podem ser armazenadas por vários dias, enquanto as notificações push podem ser armazenadas por várias horas. Ao excluir os dados de acordo com sua relevância, economizamos espaço em disco, o que pode ser importante na hora de escolher um SSD como armazenamento em disco principal.
Política de Compactação
Outra forma de otimizar o espaço em disco é usar a Política de Compactação - essa configuração permite armazenar apenas a última mensagem de cada chave, excluindo todas as mensagens anteriores. Isso pode ser útil quando estamos interessados apenas nas alterações mais recentes.
Casos de uso do Kafka
- . : . , , , (Clickhouse !) .
Customer Care Vivid.Money CRM. - . , . , - ( ) , , .
, ( ) . , , , , . - . , .
- (commit log). , - / .
, , «» .
Customer Care CRM- .
Kafka
- – , ;
- – (pull) , . (, ) Consumer Group, ZooKeeper, , , , ;
- . , , , . , () ;
- , , AMQP , – . , ;
- . , , --, – .