Introdução
Ao trabalhar em tarefas de aprendizado de máquina com dados online, é necessário reunir várias entidades em uma para análise e avaliação adicionais. O processo de coleta deve ser conveniente e rápido. Muitas vezes, também deve proporcionar uma transição contínua do desenvolvimento para o uso industrial, sem esforço adicional e trabalho de rotina. Você pode usar a abordagem de armazenamento de recursos para resolver esse problema. Essa abordagem é descrita em muitos detalhes aqui: Conheça Michelangelo: a plataforma de aprendizado de máquina da Uber . Este artigo descreve como interpretar a solução de gerenciamento de recursos especificada como um protótipo.
Loja de recursos para streaming online
O Feature Store pode ser visto como um serviço que deve executar suas funções estritamente de acordo com sua especificação. Antes de definir esta especificação, um exemplo simples deve ser desmontado.
Exemplo
Que as seguintes entidades sejam fornecidas.
Um filme que possui um ID e um título.
Classificação do filme, que também tem seu próprio identificador, identificador de filme e valor de classificação. A classificação muda com o tempo.
Fonte de classificação, que também possui classificação própria. E isso muda com o tempo.
E você precisa combinar essas entidades em uma.
Aqui está o que acontece.
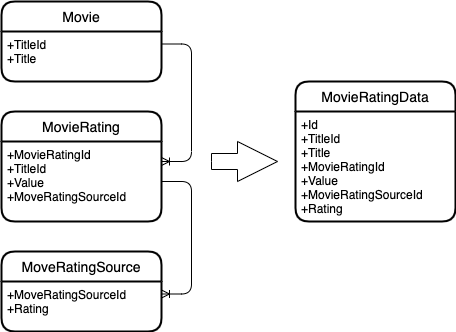
Diagrama de entidade
Como você pode ver, a mesclagem é baseada em chaves de entidade. Essa. todas as classificações de filme são pesquisadas para um filme e todas as classificações de fonte para uma classificação de filme.
Generalização do exemplo
, .
kafka-, : A, B… NN.
: AB, BCD… NM.
: Feature Stream Engine.
Feature Stream Engine kafka-, Feature Stream Store Feature Stream Center, .
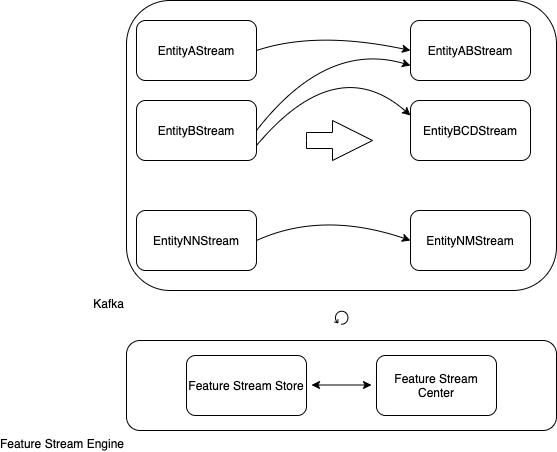
Feature Stream Engine
Feature Stream Store
, .
– (feature).
, , .
.
Feature Stream Center
, , .
Feature Stream Engine
Feature Stream Engine , .
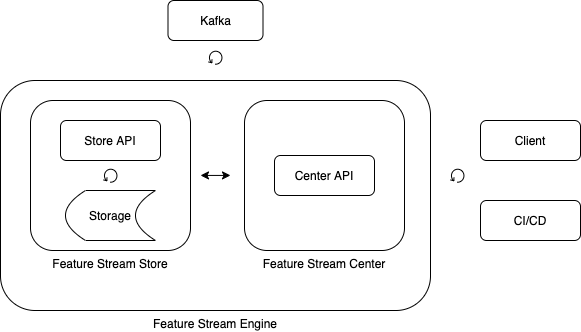
Feature Stream Engine
Feature Stream Engine
Feature Stream Engine , .
Feature Stream Engine .
.
kafka.
.
( ).
, .
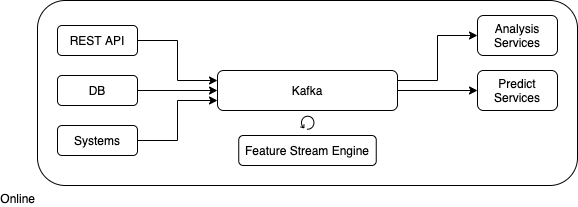
Feature Stream Engine
.
.
, ("configration.properties").
.
topic- kafka. “,”.
. “,”.
topic-.
, .
public static FeaturesDescriptor createFromProperties(Properties properties) {
String sources = properties.getProperty(FEATURES_DESCRIPTOR_FEATURE_DESCRIPTORS_SOURCES);
String keys = properties.getProperty(FEATURES_DESCRIPTOR_FEATURE_DESCRIPTORS_KEYS);
String sinkSource = properties.getProperty(FEATURES_DESCRIPTOR_SINK_SOURCE);
String[] sourcesArray = sources.split(",");
String[] keysArray = keys.split(",");
List<FeatureDescriptor> featureDescriptors = new ArrayList<>();
for (int i = 0; i < sourcesArray.length; i++) {
FeatureDescriptor featureDescriptor =
new FeatureDescriptor(sourcesArray[i], keysArray[i]);
featureDescriptors.add(featureDescriptor);
}
return new FeaturesDescriptor(featureDescriptors, sinkSource);
}
public static class FeatureDescriptor {
public final String source;
public final String key;
public FeatureDescriptor(String source, String key) {
this.source = source;
this.key = key;
}
}
public static class FeaturesDescriptor {
public final List<FeatureDescriptor> featureDescriptors;
public final String sinkSource;
public FeaturesDescriptor(List<FeatureDescriptor> featureDescriptors, String sinkSource) {
this.featureDescriptors = featureDescriptors;
this.sinkSource = sinkSource;
}
}
.
void buildStreams(StreamsBuilder builder)
topic-, , , .
Serde<String> stringSerde = Serdes.String();
List<KStream<String, String>> streams = new ArrayList<>();
for (FeatureDescriptor featureDescriptor : featuresDescriptor.featureDescriptors) {
KStream<String, String> stream =
builder.stream(featureDescriptor.source, Consumed.with(stringSerde, stringSerde))
.map(new KeyValueMapperSimple(featureDescriptor.key));
streams.add(stream);
}
.
KStream<String, String> pref = streams.get(0);
for (int i = 1; i < streams.size(); i++) {
KStream<String, String> cur = streams.get(i);
pref = pref.leftJoin(cur,
new ValueJoinerSimple(),
JoinWindows.of(Duration.ofSeconds(1)),
StreamJoined.with(
Serdes.String(),
Serdes.String(),
Serdes.String())
);
}
topic.
pref.to(featuresDescriptor.sinkSource);
.
public void buildStreams(StreamsBuilder builder) {
Serde<String> stringSerde = Serdes.String();
List<KStream<String, String>> streams = new ArrayList<>();
for (FeatureDescriptor featureDescriptor : featuresDescriptor.featureDescriptors) {
KStream<String, String> stream =
builder.stream(featureDescriptor.source, Consumed.with(stringSerde, stringSerde))
.map(new KeyValueMapperSimple(featureDescriptor.key));
streams.add(stream);
}
if (streams.size() > 0) {
if (streams.size() == 1) {
KStream<String, String> stream = streams.get(0);
stream.to(featuresDescriptor.sinkSource);
} else {
KStream<String, String> pref = streams.get(0);
for (int i = 1; i < streams.size(); i++) {
KStream<String, String> cur = streams.get(i);
pref = pref.leftJoin(cur,
new ValueJoinerSimple(),
JoinWindows.of(Duration.ofSeconds(1)),
StreamJoined.with(
Serdes.String(),
Serdes.String(),
Serdes.String())
);
}
pref.to(featuresDescriptor.sinkSource);
}
}
}
.
void run(Properties config)
( ).
FeaturesStream featuresStream = new FeaturesStream(config);
kafka.
StreamsBuilder builder = new StreamsBuilder();
featuresStream.buildStreams(builder);
Topology topology = builder.build();
KafkaStreams streams = new KafkaStreams(topology, featuresStream.buildStreamsProperties());
.
streams.start();
.
public static void run(Properties config) {
StreamsBuilder builder = new StreamsBuilder();
FeaturesStream featuresStream = new FeaturesStream(config);
featuresStream.buildStreams(builder);
Topology topology = builder.build();
KafkaStreams streams = new KafkaStreams(topology, featuresStream.buildStreamsProperties());
CountDownLatch latch = new CountDownLatch(1);
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
streams.close();
latch.countDown();
}));
try {
streams.start();
latch.await();
} catch (Throwable e) {
System.exit(1);
}
System.exit(0);
}
.
java -jar features-stream-1.0.0.jar -c plain.properties
: Java 1.8.
: kafka 2.6.0, jsoup 1.13.1.
. .
Primeiro: permite que você construa rapidamente um tópico em união.
Segundo: permite que você inicie rapidamente a fusão em diferentes ambientes.
É importante notar que a solução impõe uma restrição na estrutura dos dados de entrada. Ou seja, tópico e deve ter uma estrutura tabular. Para superar essa limitação, você pode introduzir uma camada adicional que permitirá reduzir várias estruturas a tabulares.
Para a implementação industrial de funcionalidade completa, você deve prestar atenção a uma funcionalidade muito poderosa e, o mais importante, flexível: KSQL .
Links e recursos
Código-fonte ;
Conheça Michelangelo: a plataforma de aprendizado de máquina da Uber .