Atualmente, uma das tendências no estudo de redes neurais de grafos é a análise do funcionamento de tais arquiteturas, comparação com métodos nucleares, avaliação da complexidade e capacidade de generalização. Tudo isso ajuda a entender os pontos fracos dos modelos existentes e cria espaço para novos.
O trabalho tem como objetivo investigar dois problemas relacionados a redes neurais de grafos. Primeiro, os autores dão exemplos de gráficos que são diferentes em estrutura, mas indistinguíveis para GNNs simples e mais poderosos . Em segundo lugar, eles limitaram o erro de generalização para redes neurais de grafos com mais precisão do que os limites VC.
Introdução
Redes neurais de grafos são modelos que trabalham diretamente com gráficos. Eles permitem que você leve em consideração informações sobre a estrutura. Um GNN típico inclui um pequeno número de camadas que são aplicadas sequencialmente, atualizando as representações de vértices em cada iteração. Exemplos de arquiteturas populares: GCN , GraphSAGE , GAT , GIN .
O processo de atualização de embeddings de vértice para qualquer arquitetura GNN pode ser resumido por duas fórmulas:

onde AGG é geralmente uma função invariante a permutações ( soma , média , max etc.), COMBINE é uma função que combina a representação de um vértice e seus vizinhos.

Arquiteturas mais avançadas podem considerar informações adicionais, como recursos de borda, ângulos de borda, etc.
O artigo discute a classe GNN para o problema de classificação de grafos. Esses modelos são estruturados assim:
Primeiro, os vértices são embeddings usando L etapas das convoluções do gráfico
(, sum, mean, max)
GNN:
(LU-GNN). GCN, GraphSAGE, GAT, GIN
CPNGNN, , 1 d, d - ( port numbering)
DimeNet, 3D-,
LU-GNN
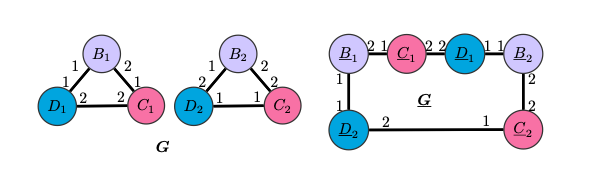
G G LU-GNN, , , readout-, . CPNGNN G G, .
CPNGNN

, “” , CPNGNN .
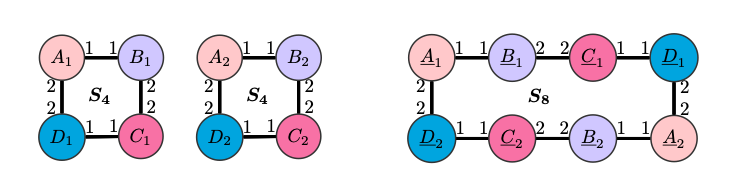
S8 S4 , , ( ), , , CPNGNN readout-, , . , .
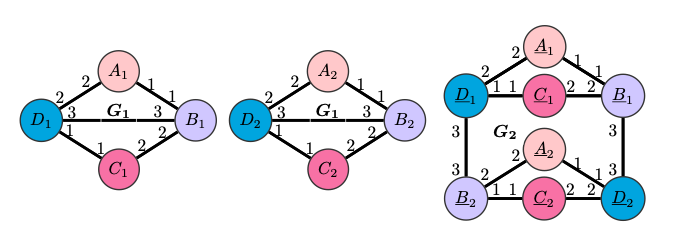
CPNGNN G2 G1. , DimeNet , , , , 
 .
.
DimeNet

DimeNet G4 , G3, . , . , G4 G3 S4 S8, , , DimeNet S4 S8 .
GNN
. , , .
GNN, :
DimeNet
message-



 , c - i- v, t - .
, c - i- v, t - .
:

readout-
.
: LU-GNN,

 - ,
- ,  - v, ,
- v, ,  . ,
. , 
 ,
,  .
.  GNN.
GNN.
. 
 .
.
 - GNN
- GNN  ,
,  - ,
- ,  .
.
,  ,
, - :
![loss_{\gamma}\left( a \right ) = \mathbb{I}\left[ a > 0\right ] + (1 + \frac{a}{\gamma})\mathbb{I}\left[ a \in \left[ \gamma, 0 \right ] \right].](https://habrastorage.org/getpro/habr/upload_files/10f/f87/63c/10ff8763ced82f8bcc4a3f1514442cd6.svg)
GNN 
 :
:

, , , , GNN . , (GNN, ), , , .
, :
,
( )

 - “ ”:
- “ ”:  , r - , d - , m - , L - ,
, r - , d - , m - , L - ,  - ,
- ,

( ), . , , , , , , .
Provas e informações mais detalhadas podem ser encontradas lendo o artigo original ou assistindo a um relatório de um dos autores.