
Portanto, considere um gráfico ponderado direcionado. Deixe o gráfico ter n vértices. Cada par de vértices corresponde a algum peso (probabilidade de transição).

Deve-se notar que os gráficos da web típicos são uma cadeia de Markov discreta homogênea para a qual a condição de indecomponibilidade e a condição de aperiodicidade são satisfeitas.
Vamos escrever a equação de Kolmogorov-Chapman:
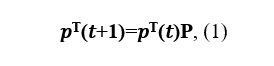
onde P é a matriz de transição.
Suponha que haja um limite.O
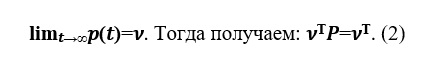
vetor v é chamado de distribuição de probabilidade estacionária.
Foi a partir da relação (2) que se propôs a busca do vetor de ranking de páginas web no modelo Brin-Page.
Como v é o limite,

a distribuição estacionária pode ser calculada pelo método de iterações simples (MPI).
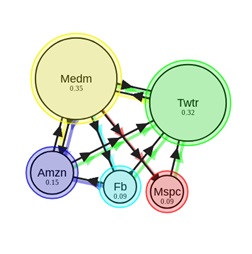
Para ir de uma página à outra, o usuário deve, com certa probabilidade, escolher o link que deseja acessar. Se o documento tiver vários links de saída, assumiremos que o usuário clica em cada um deles com a mesma probabilidade. E por último, existe também o coeficiente de teletransporte, que nos mostra que com alguma probabilidade o usuário pode passar do documento atual para outra página, não necessariamente relacionada diretamente com a página em que se encontra no momento. Deixe o usuário se teletransportar com probabilidade δ, então a equação (1) assumirá a forma

Para 0 <δ <1, a equação tem garantia de ter uma solução única. Na prática, uma equação com δ = 0,15 é geralmente usada para calcular o PageRank.
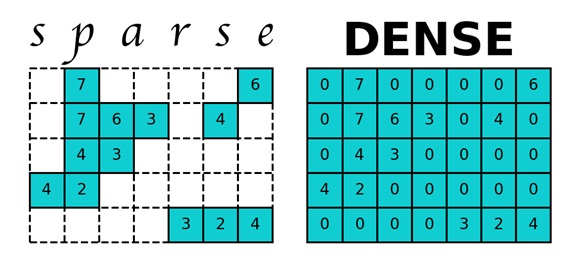
Considere um gráfico da web do Google de um site - link. Este gráfico da web contém 875713 vértices, o que significa que para uma matriz bidimensional P, você precisa alocar 714 Gb de memória. A RAM dos computadores modernos é uma ordem de magnitude menor, então o computador começa a usar a memória do disco rígido, cujo acesso torna muito mais lento o trabalho do programa de cálculo do PageRank. Mas a matriz P é uma matriz esparsa - uma matriz com predominantemente zero elementos. Para trabalhar com matrizes esparsas em Python, o módulo esparso da biblioteca scipy é usado, o que ajuda a matriz P a ocupar muito menos memória.
Vamos aplicar esse algoritmo a esses dados. Nós são páginas da web e as bordas direcionadas são hiperlinks entre eles.
Primeiro, vamos importar as bibliotecas de que precisamos:
import cvxpy as cp
import numpy as np
import pandas as pd
import time
import numpy.linalg as ln
from scipy.sparse import csr_matrix
Agora, vamos passar para a implementação em si:
#
data = pd.read_csv("web-Google.txt", names = ['i','j'], sep="\t", header=None)
NODES = 916428
EDGES = 5105039
#
NEW = csr_matrix((np.ones(len(data['i'])),(data['i'],data['j'])),shape=(NODES,NODES))
b = NEW.sum(axis=1)
NEW = NEW.transpose()
#
p0 = np.ones((NODES,1))/NODES
eps = 10**-5
delta = 0.15
ERROR = True
k = 0
#
while (ERROR == True):
with np.errstate(divide='ignore'):
z = p0 / b
p1 = (1-delta) * NEW.dot(csr_matrix(z)) + delta * np.ones((NODES,1))/NODES
if (ln.norm(p1-p0) < eps):
ERROR = False
k = k + 1
# PageRank
p0 = p1
Nos gráficos, podemos ver como o vetor p chega a um estado estacionário v :

Usando o vetor PageRank, você também pode determinar o vencedor nas eleições. Um pequeno subconjunto de colaboradores da Wikipedia são administradores, que são usuários com acesso a recursos técnicos adicionais para auxiliar na manutenção. Para que um usuário se torne administrador, uma solicitação de administrador é emitida e a comunidade da Wikipedia, por meio de comentários públicos ou votação, decide quem deve ser promovido à posição de administrador.
O problema do PageRank também pode ser reduzido a um problema de minimização e resolvido usando o método do gradiente condicional de Frank-Wolfe, que é o seguinte: selecione um dos vértices do simplex e faça um ponto de partida neste vértice. Implementação deste método em dados - o link é apresentado a seguir:
#
data = pd.read_csv("grad.txt", names = ['i','j'], sep="\t", header=None)
NODES = 6301
EDGES = 20777
#
NEW = csr_matrix((np.ones(len(data['i'])),(data['i'],data['j'])),shape=(NODES,NODES))
b = NEW.sum(axis=1)
NEW = NEW.transpose()
e = np.ones(NODES)
with np.errstate(divide='ignore'):
z = e / b
NEW = NEW.dot(csr_matrix(z))
#
eps = 0.05
k=0
a_0 = 1
y = np.zeros((NODES,1))
p0 = np.ones((NODES,1))/NODES
#
p0[0] = 0.1
y[np.argmin(df(p0))] = 1
p1 = (1-2/(1+k))*p0 + 2/(1+k)*y
#
while ((ln.norm(p1-p0) > eps)):
y = np.zeros((NODES,1))
k = k + 1
p0 = p1
y[np.argmin(df(p0))] = 1
p1 = (1-2/(1+k))*p0 + 2/(1+k)*y

Para o funcionamento eficaz de um motor de busca real, a velocidade de cálculo do vetor PageRank é mais importante do que a precisão do seu cálculo. MPI não permite que você sacrifique a precisão em prol da velocidade de computação. O algoritmo de Monte Carlo ajuda até certo ponto a lidar com esse problema. Lançamos um usuário virtual que vagueia pelas páginas dos sites. Ao coletar estatísticas de suas visitas às páginas do site, após um período bastante longo de tempo, obtemos para cada página quantas vezes o usuário a visitou. Normalizando este vetor, obtemos o vetor PageRank desejado. Vamos demonstrar como esse algoritmo funciona com dados já em uso .
#
def get_edges(m, i):
if (i == NODES):
return random.randint(0, NODES)
else:
if (len(m.indices[m.indptr[i] : m.indptr[i+1]]) != 0):
return np.random.choice(m.indices[m.indptr[i] : m.indptr[i+1]])
else:
return NODES
#
data = pd.read_csv("web-Google.txt", names = ['i','j'], sep="\t", header=None)
NODES = 916428
EDGES = 5105039
NEW = csr_matrix((np.ones(len(data['i'])),(data['i'],data['j'])),shape=(NODES,NODES))
#c , total –
for total in range(1000000,2000000,100000):
#
k = random.randint(0, NODES)
# PageRank
ans = np.zeros(NODES+1)
margin2 = np.zeros(NODES)
ans_prev = np.zeros(NODES)
for t in range(total):
j = get_edges(NEW, k)
ans[j] = ans[j]+1
k = j
#
ans = np.delete(ans, len(ans)-1)
ans = ans/sum(ans)
for number in range(len(ans)):
margin2[number] = ans[number] - ans_prev[number]
ans_prev = ans
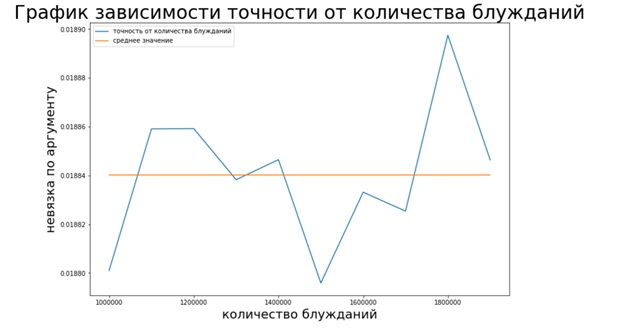
Como pode ser visto no gráfico, o método Monte Carlo, ao contrário dos dois métodos anteriores, não é estável (não há convergência), mas ajuda a estimar o vetor Page Rank sem exigir muito tempo.
Conclusão: Assim, consideramos os principais algoritmos para determinação do PageRank de gráficos da web. Antes de começar a projetar um site, você deve se certificar de que o PageRank não seja desperdiçado, prestando atenção ao seguinte:
- Os links internos mostram como o “poder do link” está se acumulando em seu site, então concentre-se nas informações importantes na página inicial do site, já que a “página inicial” do site tem o PageRank mais forte.
- Páginas órfãs que não possuem links de outras páginas do seu site. Tente evitar essas páginas.
- Vale a pena mencionar os links externos se forem úteis ao visitante do seu site.
- Links de entrada quebrados diluem o peso geral da página, então você precisa monitorá-los periodicamente e “corrigi-los”, se necessário.
No entanto, isso não significa que você deve se concentrar no PageRank. Mas vale lembrar que ao prestar atenção na estrutura do site na hora de construí-lo, nas funcionalidades dos links internos e externos, você está otimizando o site para o PageRank.