Damos continuidade ao tema segurança da informação e publicamos a tradução do artigo de Coussement Bruno.
Adicionar ruído aos dados existentes, adicionar ruído apenas aos resultados da manipulação de dados ou gerar dados sintéticos? Vamos confiar em nossa intuição?

As empresas estão crescendo e suas regulamentações de segurança cibernética estão se tornando mais rígidas, os arquitetos seniores estão adotando tendências ... Tudo isso leva ao fato de que a necessidade (ou obrigação) de reduzir os riscos associados à privacidade e ao vazamento de informações só se intensifica para os titulares dos dados.
Nesse caso, métodos de anonimização ou tokenização de dados são amplamente utilizados, embora também permitam a possibilidade de divulgação de informações privadas (veja este artigo para entender por que isso acontece).
Gerando dados sintéticos
Os dados sintéticos têm uma diferença fundamental. O objetivo é criar um gerador de dados que mostre as mesmas estatísticas globais dos dados originais. Distinguir o original do resultado deve ser difícil para um modelo ou pessoa.
Vamos ilustrar o acima gerando dados sintéticos no conjunto de dados Covertype usando o modelo TGAN .

Após treinar o modelo nesta tabela, gerei 5000 linhas e plotei um histograma da coluna Elevation do conjunto original e gerado. Parece que ambas as linhas coincidem visualmente.
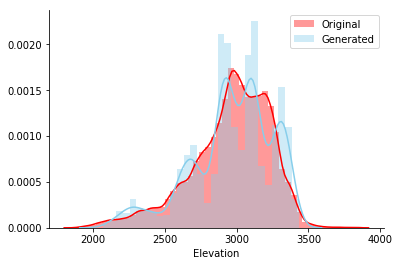
Para testar a relação entre pares de barras, um gráfico emparelhado de todas as barras contínuas é mostrado. A forma que os pontos azuis esverdeados formam (gerados) deve corresponder visualmente à forma dos pontos vermelhos (original). E assim aconteceu, legal!

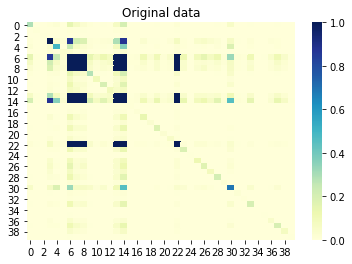
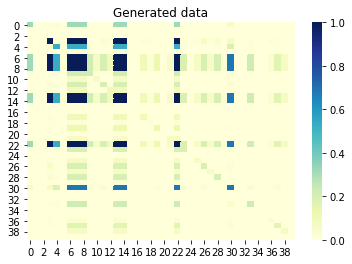
Se examinarmos agora as informações mútuas (também conhecidas como correlação sem sinal) entre as colunas, as colunas que estão correlacionadas entre si também devem estar correlacionadas no conjunto gerado. Por outro lado, colunas não correlacionadas no conjunto original não devem ser correlacionadas no conjunto gerado. Um valor próximo a 0 significa nenhuma correlação e um valor próximo a 1 significa correlação perfeita. Ótimo, é mesmo!
Informações mútuas entre as colunas do conjunto original:
Informações mútuas entre as colunas do conjunto gerado:
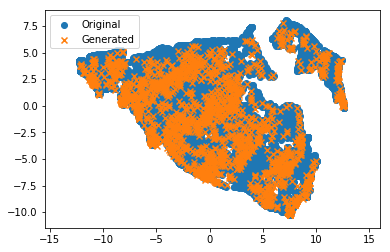
Como um teste final, eu queria treinar o método de redução de dimensionalidade não linear ( UMAP ) no conjunto original e projetar os pontos de origem no espaço 2D. Eu insiro o conjunto gerado no mesmo projetor. As cruzes laranja (geradas) devem estar nas nuvens de pontos azuis do conjunto de dados original. E aqui está! Excelente!
OK, experimentar dados é divertido!
Para casos mais graves, existem 2 abordagens principais:
- Modelos generativos profundos: podem ser usados para estudar a distribuição estatística da qual os dados reais foram supostamente retirados. Se você tiver uma aproximação dessa distribuição, poderá amostrar aleatoriamente um conjunto de dados sintético de tamanho arbitrário a partir dele. Isso é o que todos os caras legais estão fazendo agora.
Vale a pena prestar atenção a iniciativas como Cofre de dados sintéticos , Gretel.AI , Mostly.ai , MDClone , Hazy .
Hoje você pode escrever uma prova de conceito usando dados sintéticos para resolver um dos seguintes problemas comuns enfrentados pelas organizações de TI:
- Sem carga útil no ambiente de desenvolvimento
Digamos que você esteja trabalhando em um produto de dados (pode ser qualquer coisa) em que os dados nos quais está interessado estão em um ambiente de produção com uma política de acesso muito rígida. Infelizmente, você só tem acesso ao ambiente de desenvolvimento sem dados interessantes.
- God Mode - Direitos de acesso para engenheiros e cientistas de dados
Digamos que você seja um cientista de dados e, de repente, um oficial de segurança da informação tenha limitado seus privilégios tão necessários para acessar os dados de produção. Como você pode continuar a ter um bom desempenho em ambientes tão difíceis e limitados?
- Transferência de dados confidenciais para um parceiro externo não confiável
Você faz parte da Empresa X. A Organização Y gostaria de apresentar seu produto de dados bacana mais recente (pode ser qualquer coisa).
Eles pedem que você extraia dados para mostrar o produto a você.
Como os dados sintéticos se relacionam com a privacidade diferencial?
A principal propriedade da geração de dados sintéticos é que, independentemente do pós-processamento ou adição de informações de terceiros, ninguém jamais poderá saber se um objeto está contido no conjunto original, e também não poderá obter as propriedades desse objeto. Esta propriedade faz parte de um conceito mais amplo denominado "privacidade diferencial" (DP).
Privacidade diferencial global e local
DP é dividido em 2 tipos.
Muitas vezes, apenas o resultado de uma tarefa específica é de interesse (por exemplo, treinar um modelo com base em dados não divulgados de pacientes de diferentes hospitais, calculando o número médio de pessoas que já cometeram um crime, etc.), então deve-se prestar atenção à privacidade diferencial global.
Nesse caso, um usuário não confiável nunca verá dados confidenciais. Em vez disso, ele diz a um curador de confiança (com mecanismos globais de privacidade diferencial) que tem acesso a dados confidenciais quais operações executar.
Apenas o resultado é informado ao usuário não confiável. Eu recomendo Pysyft e OpenDPse você precisar de mais informações sobre ferramentas semelhantes.
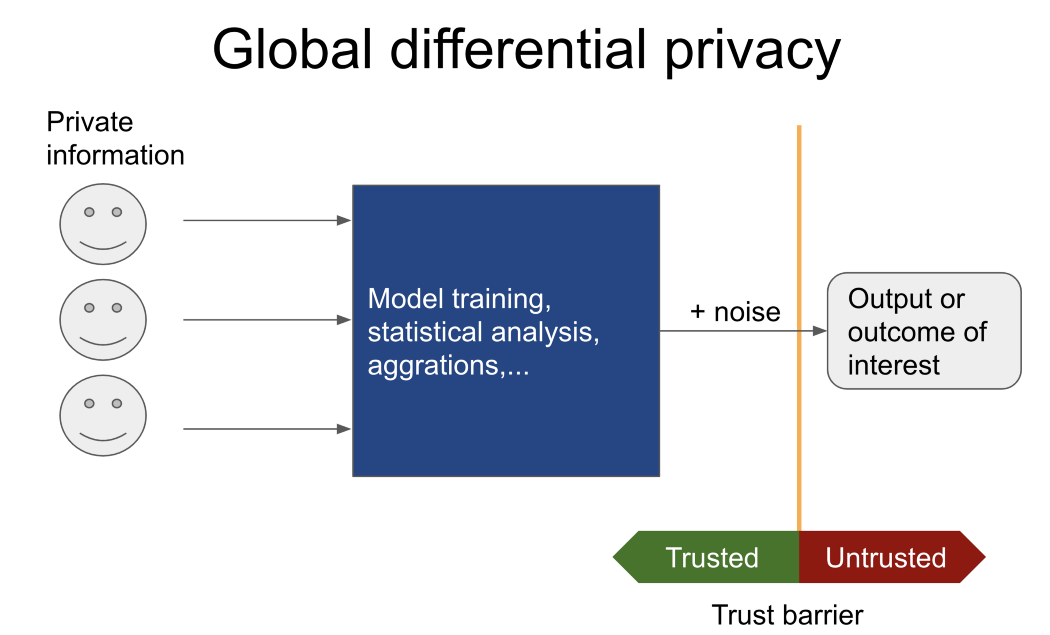
Em contraste, se os dados forem transferidos para uma parte não confiável, os princípios da confidencialidade local diferencial entram em jogo. Tradicionalmente, isso é feito adicionando ruído a cada linha em uma tabela ou banco de dados. A quantidade de ruído adicionado depende de:
- o nível necessário de confidencialidade (o famoso épsilon na literatura de DP),
- o tamanho do conjunto de dados (um conjunto de dados maior requer menos ruído para atingir o mesmo nível de privacidade),
- tipo de dados da coluna (quantitativo, categórico, ordinal).

Em teoria, para um nível igual de confidencialidade, o mecanismo DP global (adicionando ruído ao resultado) fornecerá resultados mais precisos do que o mecanismo local (ruído de nível de linha).
Assim, os métodos de geração de dados sintéticos podem ser considerados uma forma de DP local.
Para mais informações sobre esses tópicos, aconselho a consulta às seguintes fontes:
- www.udacity.com/course/secure-and-private-ai--ud185
- medium.com/@arbidha1412/local-and-global-differential-privacy-249aaa3571
- www.openmined.org
Recomendação
Vejamos agora um exemplo mais específico. Você deseja compartilhar uma planilha contendo informações pessoais com uma parte não confiável.
Agora, você pode adicionar ruído às linhas de dados existentes (DP local), configurar e usar um sistema robusto (DP global) ou gerar dados sintéticos com base no original.
O ruído deve ser adicionado às linhas de dados existentes se
- você não sabe qual operação será realizada nos dados após a publicação,
- você precisa compartilhar periodicamente uma atualização dos dados originais (= ter este fluxo de trabalho como parte de um processo em lote estável),
- você e os proprietários dos dados confiam na pessoa / equipe / organização para adicionar ruído aos dados originais.
Aqui eu recomendo começar com as ferramentas OpenDP .
O caso mais famoso de privacidade diferencial está no Censo dos Estados Unidos (consulte databricks.com/session_na20/using-apache-spark-and-differential-privacy-for-protecting-the-privacy-of-the-2020-census-respondents ).
Esses dados são recalculados e atualizados a cada três anos. São principalmente dados numéricos agregados e publicados em vários níveis (município, estado, nível nacional).
Instale e use um sistema confiável se
- o sistema que você especificou suporta as tarefas e operações que serão realizadas nele,
- os dados básicos são armazenados em locais diferentes e não podem deixá-los (por exemplo, em hospitais diferentes),
- você e os proprietários dos dados realmente confiam no sistema atual e na pessoa / equipe / organização que o está configurando.
Como um usuário de dados confidenciais, você obterá resultados mais precisos do que a primeira abordagem.
Muitos frameworks não têm atualmente todos os recursos necessários para implantar essa besta de uma forma segura, escalável e auditável. Ainda há muito trabalho de engenharia necessário aqui.
Mas, à medida que sua adoção cresce, o DP pode ser uma boa alternativa para grandes organizações e negócios.
Eu recomendo começar aqui com OpenMined .
É possível gerar dados sintéticos se
- a tabela original é relativamente pequena (<1 milhão de linhas, <100 colunas),
- ad-hoc ( ),
- / / , .
Como no pequeno experimento descrito acima, os resultados são promissores. Também não requer excelente conhecimento de sistemas de DP. Você pode começar hoje, se precisar, deixá-lo treinar durante a noite e, por assim dizer, preparar o conjunto sintético compartilhado para amanhã de manhã.
A maior desvantagem é que esses modelos complexos podem se tornar caros para treinar e manter se a quantidade de dados aumentar. Cada mesa também requer seu próprio treinamento completo do modelo (o treinamento portátil não funcionará aqui). Você não será capaz de escalar para centenas de tabelas, mesmo com um orçamento computacional significativo.
Caso contrário, você está sem sorte.
Conclusão
Como a privacidade dos dados é mais importante do que nunca, temos métodos excelentes para gerar dados sintéticos ou adicionar ruído aos dados existentes. No entanto, todos eles ainda têm suas limitações. Com exceção de alguns casos de nicho, uma ferramenta escalonável e flexível de nível empresarial ainda não foi criada para permitir que dados contendo informações pessoais sejam transferidos para partes não confiáveis.
Os proprietários de dados ainda precisam confiar em métodos ou sistemas estabelecidos, o que exige muita confiança deles. Esse é o maior problema!
Enquanto isso, se você quiser fazer uma tentativa (prova de conceito, basta testar), abra qualquer um dos links acima.