Qual foi o objetivo deste estudo? Eu queria saber:
- Em quais aplicativos o Python é usado
- Quais conhecimentos são necessários: bancos de dados, bibliotecas, estruturas
- Quantos especialistas em cada área são solicitados
- Que salários são oferecidos

Carregando dados
Jobs baixado do site hh.ru , usando a API: dev.hh.ru . A pedido da "Python", foram carregadas as vagas de 1994 (região de Moscou), que foram divididas em suítes de treinamento e teste, na proporção de 80% e 20% . O tamanho do conjunto de treinamento é 1595 , o tamanho do conjunto de teste é 399 . O conjunto de testes será usado apenas nas seções de habilidades Top / Antitop e Classificação de Cargos.
Sinais
Com base no texto das vagas carregadas, foram formados dois grupos dos n-gramas mais comuns de palavras:
- 2 gramas em cirílico e latim
- 1 grama em latim
Nas vagas de TI, as principais habilidades e tecnologias são geralmente escritas em inglês, portanto, o segundo grupo incluiu palavras apenas em latim.
Após a seleção de n-gramas, o primeiro grupo continha 81 gramas de 2 e o segundo 98 gramas de 1:
| Não. | n | n-grama | Peso | Vagas |
| 1 | 2 | em python | oito | 258 |
| 2 | 2 | ci cd | oito | 230 |
| 3 | 2 | compreensão dos princípios | oito | 221 |
| 4 | 2 | conhecimento de sql | oito | 178 |
| cinco | 2 | Desenvolvimento e | nove | 174 |
| ... | ... | ... | ... | ... |
| 82 | 1 | sql | cinco | 490 |
| 83 | 1 | linux | 6 | 462 |
| 84 | 1 | postgresql | cinco | 362 |
| 85 | 1 | docker | 7 | 358 |
| 86 | 1 | Java | nove | 297 |
| ... | ... | ... | ... | ... |
Decidiu-se dividir as vagas em clusters de acordo com os seguintes critérios em ordem de prioridade:
| Uma prioridade | Critério | Peso |
| 1 | Campo (direção aplicada), cargo, experiência de
n-gram: "aprendizado de máquina", "administração Linux", "conhecimento excelente" |
7-9 |
| 2 | Ferramentas, tecnologias, software.
n-gramas: "sql", "linux os", "pytest" |
4-6 |
| 3 | Outras habilidades de
n-gram: "educação técnica", "Inglês", "tarefas interessantes" |
1-3 |
A determinação de qual grupo de critérios o n-grama pertence, e que peso atribuir a ele, ocorreu em um nível intuitivo. Aqui estão alguns exemplos:
- À primeira vista, "Docker" pode ser atribuído ao segundo grupo de critérios com um peso de 4 a 6. Mas a menção de "Docker" na vaga provavelmente significa que a vaga será para o cargo de "engenheiro DevOps". Portanto, "Docker" caiu no primeiro grupo e recebeu um peso de 7.
- «Java» , .. «Java» Java- « Python». «-». , , , «Java» 9.
n- — .
Para os cálculos, cada vaga foi transformada em um vetor com dimensão de 179 (o número de recursos selecionados) de números inteiros de 0 a 9, onde 0 significa que o i-ésimo n-grama está ausente na vaga e os números de 1 a 9 significam a presença do i-ésimo n - gramas e seu peso. Mais adiante no texto, um ponto é entendido como uma vaga representada por tal vetor.
Exemplo:
digamos que uma lista de n-gramas contenha apenas três valores:
Não. n n-grama Peso Vagas 1 2 em python oito 258 2 2 compreensão dos princípios oito 221 3 1 sql cinco 490
Depois, para uma vaga com texto.
Requisitos:
- Mais de 3 anos de experiência em desenvolvimento python .
- Bons conhecimentos de sql
o vetor é igual a [8, 0, 5].
Métricas
Para trabalhar com dados, você precisa entendê-los. No nosso caso, gostaria de ver se há algum agrupamento de pontos, que consideraremos como agrupamento. Para fazer isso, usei o algoritmo t-SNE para traduzir todos os vetores no espaço 2D.
A essência do método é reduzir a dimensão dos dados, mantendo ao máximo as proporções das distâncias entre os pontos do conjunto. É muito difícil entender como o t-SNE funciona a partir das fórmulas. Mas gostei de um exemplo encontrado em algum lugar da Internet: digamos que temos bolas no espaço tridimensional. Conectamos cada bola com todas as outras bolas por molas invisíveis que não se cruzam de forma alguma e não interferem uma com a outra durante o cruzamento. As molas atuam em duas direções, ou seja, eles resistem tanto à distância quanto à aproximação das bolas entre si. O sistema está em um estado estável, as bolas estão paradas. Se pegarmos uma das bolas, puxá-la de volta e depois soltá-la, ela voltará ao seu estado original devido à força das molas. Em seguida, pegamos dois pratos grandes e esprememos as bolas em uma camada fina,embora não interfira com as bolas para se mover no plano entre as duas placas. As forças das molas começam a agir, as bolas se movem e eventualmente param quando as forças de todas as molas se equilibram. As molas agirão de forma que as esferas que estavam próximas uma da outra permaneçam relativamente próximas e planas. Também com bolas removidas - elas serão removidas umas das outras. Com o auxílio de molas e placas, convertemos o espaço tridimensional em bidimensional, preservando de alguma forma a distância entre os pontos!Também com bolas removidas - elas serão removidas umas das outras. Com a ajuda de molas e placas, convertemos o espaço tridimensional em bidimensional, preservando de alguma forma a distância entre os pontos!Também com bolas removidas - elas serão removidas umas das outras. Com a ajuda de molas e placas, convertemos o espaço tridimensional em bidimensional, preservando de alguma forma a distância entre os pontos!
O algoritmo t-SNE foi usado por mim apenas para visualizar um conjunto de pontos. Ele ajudou a escolher uma métrica, bem como selecionar os pesos dos recursos.
Se usarmos a métrica euclidiana que usamos em nossa vida diária, então a localização das vagas ficará assim:

A figura mostra que a maioria dos pontos estão concentrados no centro, e há pequenos ramos nas laterais. Com essa abordagem, algoritmos de agrupamento que usam as distâncias entre os pontos não produzirão nada de bom.
Existem muitas métricas (maneiras de determinar a distância entre dois pontos) que funcionarão bem com os dados que você está explorando. Escolhi a distância de Jaccard como medida , levando em consideração os pesos de n-gramas. A medida de Jaccard é fácil de entender, mas funciona bem para resolver o problema em consideração.
:
1 n-: « python», «sql», «docker»
2 n-: « python», «sql», «php»
:
« python» — 8
«sql» — 5
«docker» — 7
«php» — 9
(n- 1- 2- ): « python», «sql» = 8 + 5 = 13
( n- 1- 2- ): « python», «sql», «docker», «php» = 8 + 5 + 7 + 9 = 29
=1 — ( / ) = 1 — (13 / 29) = 0.55
A matriz de distâncias entre todos os pares de pontos foi calculada, o tamanho da matriz é 1595 x 1595. No total, 1.271.215 distâncias entre pares únicos. A distância média acabou sendo 0,96, entre 619 659 a distância é 1 (ou seja, não há nenhuma semelhança). O gráfico a seguir mostra que, em geral, há pouca semelhança entre os empregos:
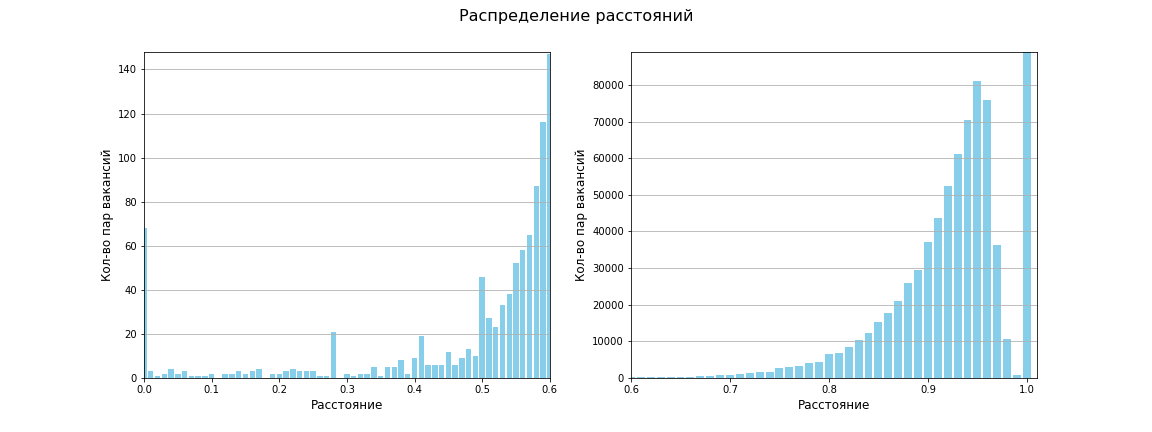
Usando a métrica Jaccard, nosso espaço agora se parece com isto:

Apareceram quatro áreas de densidade distintas e dois pequenos aglomerados de baixa densidade. Pelo menos é assim que meus olhos veem!
Clustering
O Gaussian Mixture Model (GMM) foi escolhido como o algoritmo de agrupamento . O algoritmo recebe dados como vetores como entrada, e o parâmetro n_components é o número de clusters em que o conjunto deve ser dividido. Você pode ver como o algoritmo funciona aqui (em inglês). Usei uma implementação GMM pronta da biblioteca scikit -learn: sklearn.mixture.GaussianMixture .
Observe que o GMM não usa uma métrica, mas separa os dados apenas por um conjunto de recursos e seus pesos. No artigo, a distância de Jaccard é usada para visualizar dados, calcular a compactação dos clusters (tomei a distância média entre os pontos do cluster para compactação) e determinaro ponto central do cluster (vacância típica) - o ponto com a menor distância média aos demais pontos do cluster. Muitos algoritmos de agrupamento usam exatamente a distância entre os pontos. A seção Outros métodos falará sobre outros tipos de agrupamento que são baseados em métricas e também fornecem bons resultados.
Na seção anterior, foi determinado a olho nu que provavelmente haverá seis clusters. É assim que os resultados do agrupamento são exibidos com n_components = 6:

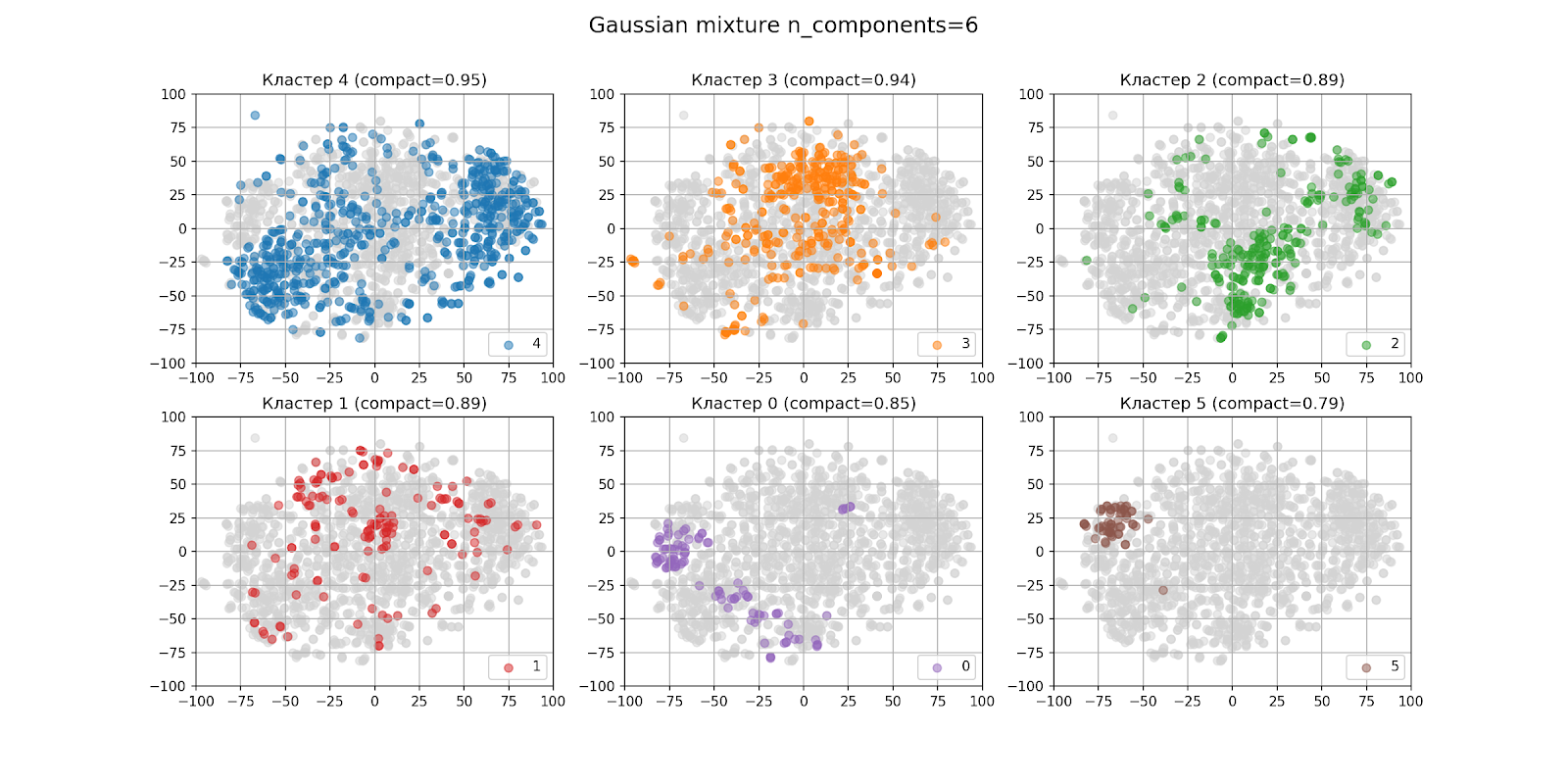
Na figura com a saída dos clusters separadamente, os clusters são organizados em ordem decrescente do número de pontos da esquerda para a direita, de cima para baixo: o cluster 4 é o maior, o cluster 5 é o menor. A compactação de cada cluster é indicada entre colchetes.
Aparentemente, o agrupamento acabou não sendo muito bom, mesmo se considerarmos que o algoritmo t-SNE não é perfeito. Ao analisar os clusters, o resultado também não foi animador.
Para encontrar o número ideal de clusters n_components, usaremos os critérios AIC e BIC, sobre os quais você pode ler aqui . O cálculo desses critérios é incorporado ao método sklearn.mixture.GaussianMixture . É assim que o gráfico de critérios se parece:

Quando n_components = 12, o critério BIC tem o menor (melhor) valor, o critério AIC também tem um valor próximo ao mínimo (mínimo quando n_components = 23). Vamos dividir as vagas em 12 clusters:


Os clusters são agora mais compactos, tanto em aparência quanto em termos numéricos. Durante a análise manual, as vagas foram divididas em grupos de características para a compreensão de uma pessoa. A figura mostra os nomes dos clusters. Os clusters numerados 11 e 4 são marcados como <Lixeira 2>:
- No cluster 11, todos os recursos têm aproximadamente os mesmos pesos totais.
- O cluster 4 é dedicado a Java. No entanto, existem poucas vagas para o cargo de Desenvolvedor Java no cluster, o conhecimento de Java é muitas vezes necessário, pois "será uma vantagem adicional."
Clusters
Depois de remover dois clusters não informativos numerados 11 e 4, o resultado é 10 clusters:
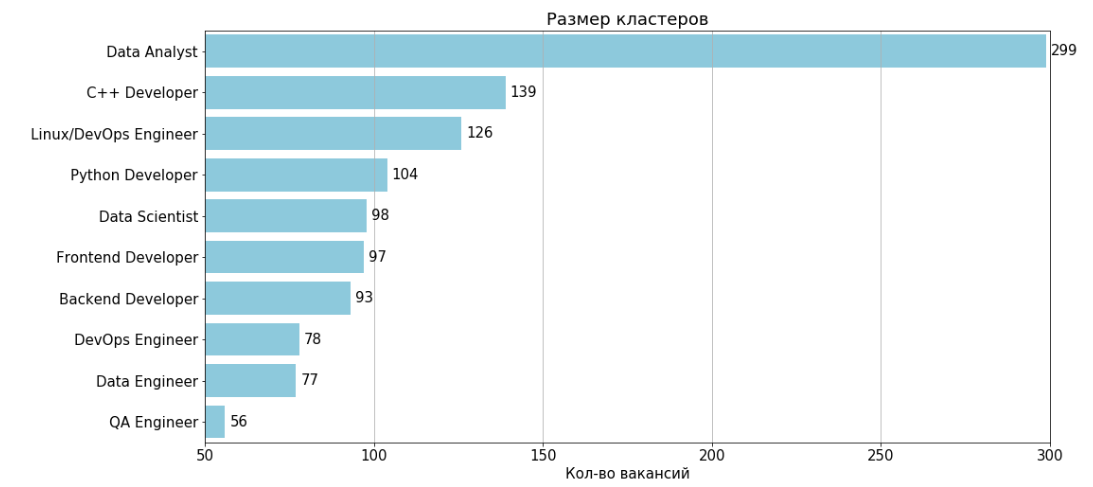
Para cada cluster, existe uma tabela de recursos e 2 gramas que são mais encontrados nas vagas do cluster.
Legenda:
S - proporção de vagas em que o traço é encontrado, multiplicado pelo peso do traço
% - porcentagem de vagas em que o traço / 2 grama é encontrado Vaga
típica do cluster - vaga, com a menor distância média para outros pontos do cluster
Analista de informações
Número de empregos: 299 Trabalho
típico: 35.805.914
| Não. | Assine com peso | S | Placa | % | 2 gramas | % |
| 1 | excel | 3,13 | sql | 64,55 | conhecimento de sql | 18,39 |
| 2 | r | 2,59 | excel | 34,78 | em desenvolvimento | 14.05 |
| 3 | sql | 2,44 | r | 28,76 | python r | 14.05 |
| 4 | conhecimento de sql | 1,47 | bi | 19,40 | com grande | 13,38 |
| cinco | análise de dados | 1,17 | quadro | 15,38 | Desenvolvimento e | 13,38 |
| 6 | quadro | 1.08 | 14,38 | análise de dados | 13,04 | |
| 7 | com grande | 1.07 | vba | 13,04 | conhecimento de python | 12,71 |
| oito | Desenvolvimento e | 1.07 | Ciência | 9,70 | armazém analítico | 11,71 |
| nove | vba | 1.04 | dwh | 6,35 | experiência de desenvolvimento | 11,71 |
| dez | conhecimento de python | 1.02 | oráculo | 6,35 | bases de dados | 11,37 |
Desenvolvedor C ++
Número de empregos: 139 Trabalho
típico: 39.955.360
| Não. | Assine com peso | S | Placa | % | 2 gramas | % |
| 1 | c ++ | 9,00 | c ++ | 100,00 | experiência de desenvolvimento | 44,60 |
| 2 | Java | 3,30 | linux | 44,60 | c c ++ | 27,34 |
| 3 | linux | 2,55 | Java | 36,69 | c ++ python | 17,99 |
| 4 | c # | 1,88 | sql | 23,02 | em c ++ | 16,55 |
| cinco | vai | 1,75 | c # | 20,86 | desenvolvimento em | 15,83 |
| 6 | desenvolvimento em | 1,27 | vai | 19,42 | estruturas de dados | 15,11 |
| 7 | bom conhecimento | 1,15 | unix | 12,23 | experiência de escrita | 14,39 |
| oito | estruturas de dados | 1.06 | tensorflow | 11,51 | programação em | 13,67 |
| nove | tensorflow | 1.04 | bash | 10,07 | em desenvolvimento | 13,67 |
| dez | experiência de programação | 0,98 | postgresql | 9,35 | linguagens de programação | 12,95 |
Engenheiro Linux / DevOps
Número de vagas de trabalho: 126 Trabalho
típico: 39.533.926
| Não. | Assine com peso | S | Placa | % | 2 gramas | % |
| 1 | ansible | 5,33 | linux | 84,92 | ci cd | 58,73 |
| 2 | docker | 4,78 | ansible | 76,19 | experiência de administração | 42,06 |
| 3 | bash | 4,78 | docker | 74,60 | bash python | 33,33 |
| 4 | ci cd | 4,70 | bash | 68,25 | tcp ip | 39,37 |
| cinco | linux | 4,43 | Prometeu | 58,73 | experiência de customização | 28,57 |
| 6 | Prometeu | 4,11 | zabbix | 54,76 | monitoramento e | 26,98 |
| 7 | nginx | 3,67 | nginx | 52,38 | prometheus grafana | 23,81 |
| oito | experiência de administração | 3,37 | grafana | 52,38 | sistemas de monitoramento | 22,22 |
| nove | zabbix | 3,29 | postgresql | 51,59 | com docker | 16,67 |
| dez | alce | 3,22 | Kubernetes | 51,59 | gerenciamento de configurações | 16,67 |
Desenvolvedor Python
Número de vagas de trabalho: 104 Trabalho
típico: 39.705.484
| Não. | Assine com peso | S | Placa | % | 2 gramas | % |
| 1 | em python | 6,00 | docker | 65,38 | em python | 75,00 |
| 2 | django | 5,62 | django | 62,50 | desenvolvimento em | 51,92 |
| 3 | frasco | 4,59 | postgresql | 58,65 | experiência de desenvolvimento | 43,27 |
| 4 | docker | 4,24 | frasco | 50,96 | frasco de django | 04,24 |
| cinco | desenvolvimento em | 4,15 | redis | 38,46 | api resto | 23,08 |
| 6 | postgresql | 2,93 | linux | 35,58 | python de | 21,15 |
| 7 | aiohttp | 1,99 | coelhomq | 33,65 | bases de dados | 18,27 |
| oito | redis | 1,92 | sql | 30,77 | experiência de escrita | 18,27 |
| nove | linux | 1,73 | Mongodb | 25,00 | com docker | 17,31 |
| dez | coelhomq | 1,68 | aiohttp | 22,12 | com postgresql | 16,35 |
Cientista de dados
Número de empregos: 98 Trabalho
típico: 38 071 218
| Não. | Assine com peso | S | Placa | % | 2 gramas | % |
| 1 | pandas | 7,35 | pandas | 81,63 | aprendizado de máquina | 63,27 |
| 2 | entorpecido | 6,04 | entorpecido | 75,51 | pandas entorpecidos | 43,88 |
| 3 | aprendizado de máquina | 5,69 | sql | 62,24 | análise de dados | 29,59 |
| 4 | pytorch | 3,77 | pytorch | 41,84 | ciência de dados | 26,53 |
| cinco | ml | 3,49 | ml | 38,78 | conhecimento de python | 25,51 |
| 6 | tensorflow | 3,31 | tensorflow | 36,73 | cigano entorpecido | 24,49 |
| 7 | análise de dados | 2,66 | faísca | 32,65 | python pandas | 23,47 |
| oito | scikitlearn | 2,57 | scikitlearn | 28,57 | em python | 21,43 |
| nove | ciência de dados | 2,39 | docker | 27,55 | estatística matemática | 20,41 |
| dez | faísca | 2,29 | hadoop | 27,55 | algoritmos de máquina | 20,41 |
Desenvolvedor Frontend
Número de empregos: 97 Trabalho
típico: 39.681.044
| Não. | Assine com peso | S | Placa | % | 2 gramas | % |
| 1 | javascript | 9,00 | javascript | 100 | html css | 27,84 |
| 2 | django | 2,60 | html | 42,27 | experiência de desenvolvimento | 25,77 |
| 3 | reagir | 2,32 | postgresql | 38,14 | em desenvolvimento | 17,53 |
| 4 | nodejs | 2,13 | docker | 37,11 | conhecimento de javascript | 15,46 |
| cinco | a parte dianteira | 2,13 | css | 37,11 | e suporte | 15,46 |
| 6 | docker | 2.09 | linux | 32,99 | python e | 14,43 |
| 7 | postgresql | 1,91 | sql | 31,96 | css javascript | 13,40 |
| oito | linux | 1,79 | django | 28,87 | bases de dados | 12,37 |
| nove | html css | 1,67 | reagir | 25,77 | em python | 12,37 |
| dez | php | 1,58 | nodejs | 23,71 | design e | 11,34 |
Desenvolvedor de back-end
Número de empregos: 93 Trabalho
típico: 40.226.808
| Não. | Assine com peso | S | Placa | % | 2 gramas | % |
| 1 | django | 5,90 | django | 65,59 | python django | 26,88 |
| 2 | js | 4,74 | js | 52,69 | experiência de desenvolvimento | 25,81 |
| 3 | reagir | 2,52 | postgresql | 40,86 | conhecimento de python | 20,43 |
| 4 | docker | 2,26 | docker | 35,48 | em desenvolvimento | 18,28 |
| cinco | postgresql | 2.04 | reagir | 27,96 | ci cd | 17,20 |
| 6 | compreensão dos princípios | 1,89 | linux | 27,96 | conhecimento confiante | 16,13 |
| 7 | conhecimento de python | 1,63 | Processo interno | 22,58 | api resto | 15.05 |
| oito | Processo interno | 1,58 | redis | 22,58 | html css | 13,98 |
| nove | ci cd | 1,38 | sql | 20,43 | habilidade de entender | 10,75 |
| dez | a parte dianteira | 1,35 | mysql | 19,35 | em um estranho | 10,75 |
DevOps Engineer
Número de empregos: 78 Trabalho
típico: 39634258
| Não. | Assine com peso | S | Placa | % | 2 gramas | % |
| 1 | devops | 8,54 | devops | 94,87 | ci cd | 51,28 |
| 2 | ansible | 5,38 | ansible | 76,92 | bash python | 30,77 |
| 3 | bash | 4,76 | linux | 74,36 | experiência de administração | 24,36 |
| 4 | Jenkins | 4,49 | bash | 67,95 | e suporte | 23,08 |
| cinco | ci cd | 4,10 | Jenkins | 64,10 | docker kubernetes | 20,51 |
| 6 | linux | 3,54 | docker | 50,00 | Desenvolvimento e | 17,95 |
| 7 | docker | 2,60 | Kubernetes | 41,03 | experiência de escrita | 17,95 |
| oito | Java | 2.08 | sql | 29,49 | e personalização | 17,95 |
| nove | experiência de administração | 1,95 | oráculo | 25,64 | Desenvolvimento e | 16,67 |
| dez | e suporte | 1,85 | abertura | 24,36 | script | 14,10 |
Engenheiro de dados
Número de empregos: 77 Trabalho
típico: 40.008.757
| Não. | Assine com peso | S | Placa | % | 2 gramas | % |
| 1 | faísca | 6,00 | hadoop | 89,61 | processamento de dados | 38,96 |
| 2 | hadoop | 5,38 | faísca | 85,71 | big data | 37,66 |
| 3 | Java | 4,68 | sql | 68,83 | experiência de desenvolvimento | 23,38 |
| 4 | colmeia | 4,27 | colmeia | 61,04 | conhecimento de sql | 22,08 |
| cinco | escala | 3,64 | Java | 51,95 | Desenvolvimento e | 19,48 |
| 6 | big data | 3,39 | escala | 51,95 | faísca hadoop | 19,48 |
| 7 | etl | 3,36 | etl | 48,05 | java scala | 19,48 |
| oito | sql | 2,79 | fluxo de ar | 44,16 | qualidade de dados | 18,18 |
| nove | processamento de dados | 2,73 | kafka | 42,86 | e processamento | 18,18 |
| dez | kafka | 2,57 | oráculo | 35,06 | colmeia hadoop | 18,18 |
Engenheiro de QA
Número de empregos: 56 Trabalho
típico: 39630489
| Não. | Assine com peso | S | Placa | % | 2 gramas | % |
| 1 | automação de teste | 5,46 | sql | 46,43 | automação de teste | 60,71 |
| 2 | experiência de teste | 4,29 | qa | 42,86 | experiência de teste | 53,57 |
| 3 | qa | 3,86 | linux | 35,71 | em python | 41,07 |
| 4 | em python | 3,29 | selênio | 32,14 | experiência de automação | 35,71 |
| cinco | Desenvolvimento e | 2,57 | rede | 32,14 | Desenvolvimento e | 32,14 |
| 6 | sql | 2.05 | docker | 30,36 | experiência de teste | 30,36 |
| 7 | linux | 2.04 | Jenkins | 26,79 | experiência de escrita | 28,57 |
| oito | selênio | 1,93 | Processo interno | 26,79 | testando em | 23,21 |
| nove | rede | 1,93 | bash | 21,43 | teste automatizado | 21,43 |
| dez | Processo interno | 1,88 | ui | 19,64 | ci cd | 21,43 |
Salários
Os salários são indicados apenas em 261 (22%) vagas de 1.167 nos clusters.
Ao calcular salários:
- Se o intervalo "de ... a ..." foi especificado, o valor médio foi usado
- Se apenas "de ..." ou apenas "para ..." foi indicado, então este valor foi tomado
- Os cálculos usaram (ou foram dados) salário após impostos (NET)
No gráfico:
- Os clusters são classificados em ordem decrescente do salário médio
- Barra vertical na caixa - mediana
- Box - intervalo [Q1, Q3], onde Q1 (25%) e Q3 (75%) são percentis. Essa. 50% dos salários caem na caixa
- O "bigode" inclui salários na faixa [Q1 - 1,5 * IQR, Q3 + 1,5 * IQR], onde IQR = Q3 - Q1 - intervalo interquartil
- Os pontos individuais são anomalias que não caíram no bigode. (Existem anomalias não incluídas no diagrama)

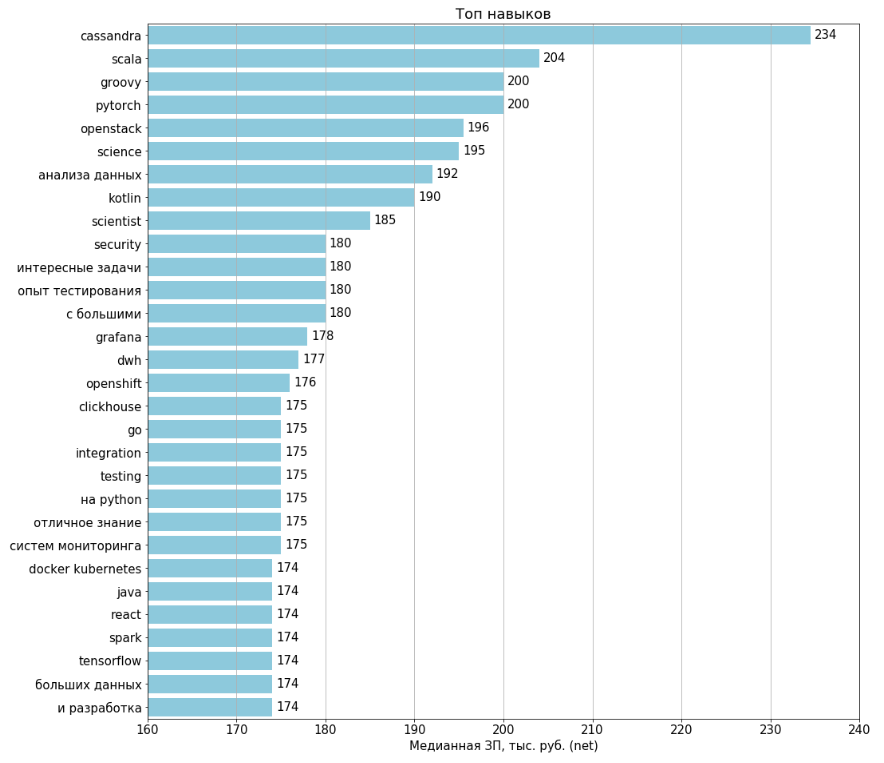
Habilidades superiores / antitop
Os gráficos foram construídos para todas as vagas de 1994 carregadas. Os salários são indicados em 443 (22%) vagas. Para o cálculo de cada recurso, foram selecionadas as vagas em que esse recurso está presente e com base nelas foi calculado o salário médio.

Classificação do trabalho
O agrupamento poderia ser muito mais fácil sem recorrer a modelos matemáticos complexos: compilar os principais cargos e dividi-los em grupos. Em seguida, analise cada grupo quanto aos melhores n-gramas e salários médios. Não há necessidade de destacar recursos e atribuir pesos a eles.
Essa abordagem funcionaria bem (até certo ponto) para uma consulta "Python". Mas para o pedido "Programador 1C" esta abordagem não funcionará, porque para programadores 1C, configurações 1C ou áreas aplicadas raramente são indicadas nos nomes das vagas. E há muitas áreas onde 1C é usado: contabilidade, cálculo de salários, cálculo de impostos, cálculo de custos em empresas industriais, contabilidade de depósito, orçamento, sistemas ERP, varejo, contabilidade gerencial, etc.
Para mim, vejo duas tarefas para a análise de vagas:
- Entenda onde uma linguagem de programação sobre a qual conheço pouco é usada (como neste artigo).
- Filtrar novos empregos publicados.
O agrupamento é adequado para resolver o primeiro problema, para resolver o segundo - vários classificadores, florestas aleatórias, árvores de decisão, redes neurais. No entanto, eu queria avaliar a adequação do modelo escolhido para o problema de classificação de cargos.
Se você usar o método predict () embutido no sklearn.mixture.GaussianMixture , então nada de bom acontecerá. Ele atribui a maioria das vagas a grandes clusters, e dois dos três primeiros clusters não são informativos. Usei uma abordagem diferente:
- Aproveitamos a vaga que queremos classificar. Nós o vetorizamos e obtemos um ponto em nosso espaço.
- Calculamos a distância deste ponto a todos os clusters. Abaixo da distância entre um ponto e um cluster, tomei a distância média deste ponto para todos os pontos no cluster.
- O cluster com a menor distância é a turma prevista para a vaga selecionada. A distância até o cluster indica a confiabilidade de tal previsão.
- Para aumentar a precisão do modelo, escolhi 0,87 como a distância limite, ou seja, se a distância até o cluster mais próximo for maior que 0,87, o modelo não classifica a vaga.
Para avaliar o modelo, 30 vagas foram selecionadas aleatoriamente do conjunto de testes. Na coluna de veredicto:
N / a: o modelo não classificou o trabalho (distância> 0,87)
+: classificação correta
-: classificação incorreta
| Vaga de emprego | Cluster mais próximo | Distância | Veredito |
| 37637989 | Engenheiro Linux / DevOps | 0,9464 | N / D |
| 37833719 | Desenvolvedor C ++ | 0,8772 | N / D |
| 38324558 | Engenheiro de dados | 0,8056 | + |
| 38517047 | Desenvolvedor C ++ | 0,8652 | + |
| 39053305 | Lixo | 0,9914 | N / D |
| 39210270 | Engenheiro de dados | 0,8530 | + |
| 39349530 | Desenvolvedor Frontend | 0,8593 | + |
| 39402677 | Engenheiro de dados | 0,8396 | + |
| 39415267 | Desenvolvedor C ++ | 0,8701 | N / D |
| 39734664 | Engenheiro de dados | 0,8492 | + |
| 39770444 | Desenvolvedor de back-end | 0,8960 | N / D |
| 39770752 | Cientista de dados | 0,7826 | + |
| 39795880 | Analista de informações | 0,9202 | N / D |
| 39947735 | Desenvolvedor Python | 0,8657 | + |
| 39954279 | Engenheiro Linux / DevOps | 0,8398 | - |
| 40008770 | DevOps Engineer | 0,8634 | - |
| 40015219 | Desenvolvedor C ++ | 0,8405 | + |
| 40031023 | Desenvolvedor Python | 0,7794 | + |
| 40072052 | Analista de informações | 0,9302 | N / D |
| 40112637 | Engenheiro Linux / DevOps | 0,8285 | + |
| 40164815 | Engenheiro de dados | 0,8019 | + |
| 40186145 | Desenvolvedor Python | 0,7865 | + |
| 40201231 | Cientista de dados | 0,7589 | + |
| 40211477 | DevOps Engineer | 0,8680 | + |
| 40224552 | Cientista de dados | 0,9473 | N / D |
| 40230011 | Engenheiro Linux / DevOps | 0,9298 | N / D |
| 40241704 | Lixo 2 | 0,9093 | N / D |
| 40245997 | Analista de informações | 0,9800 | N / D |
| 40246898 | Cientista de dados | 0,9584 | N / D |
| 40267920 | Desenvolvedor Frontend | 0,8664 | + |
Total: 12 vagas sem resultado, 2 vagas - classificação errada, 16 vagas - classificação correta. Completude do modelo - 60%, precisão do modelo - 89%.
Lados fracos
O primeiro problema - vamos pegar duas vagas:
Vaga 1 -
Requisitos para " Programador C ++ Líder" ":
- 5+ anos de experiência em desenvolvimento C ++.
- Conhecimento de Python será uma vantagem adicional. "
Vaga 2 -Do ponto de vista do modelo, essas vagas são idênticas. Tentei ajustar os pesos dos recursos pela ordem de sua ocorrência no texto. Isso não levou a nada de bom.
Requisitos para " Programador Python Líder" ":
- Mais de 5 anos de experiência em desenvolvimento Python.
- Conhecimento de C ++ será uma vantagem adicional "
O segundo problema é que o GMM agrupa todos os pontos de um conjunto, como muitos algoritmos de agrupamento. Os clusters não informativos não são um problema por si só. Mas os clusters informativos também contêm outliers. No entanto, isso pode ser facilmente resolvido limpando os clusters, por exemplo, removendo os pontos mais atípicos que têm a maior distância média para o resto dos pontos do cluster.
Outros métodos
A página de comparação de cluster demonstra bem os vários algoritmos de cluster. GMM é o único que deu bons resultados.
O resto dos algoritmos não funcionou ou deu resultados muito modestos.
Daqueles implementados por mim, os bons resultados foram em dois casos:
- Pontos com alta densidade foram selecionados em uma determinada vizinhança, localizados a uma distância distante uns dos outros. Os pontos tornaram-se os centros dos aglomerados. Então, a partir dos centros, iniciou-se o processo de formação dos agrupamentos - a junção de pontos vizinhos.
- O agrupamento aglomerativo é uma fusão iterativa de pontos e clusters. A biblioteca scikit-learn apresenta esse tipo de agrupamento, mas não funciona bem. Em minha implementação, alterei a matriz de junção após cada iteração da mesclagem. O processo parou quando alguns parâmetros de limite foram alcançados - na verdade, os dendrogramas não ajudam a entender o processo de fusão se 1.500 elementos estão agrupados.
Conclusão
A pesquisa que fiz me deu as respostas para todas as perguntas no início do artigo. Tive experiência prática com clustering enquanto implementava variações de algoritmos conhecidos. Eu realmente espero que o artigo motive o leitor a realizar sua pesquisa analítica e, de alguma forma, ajude nesta lição emocionante.