Processar até mesmo alguns gigabytes de dados em um laptop só pode se tornar uma tarefa assustadora se ele não tiver muita RAM e um bom poder de processamento.
Apesar disso, os cientistas de dados ainda precisam encontrar soluções alternativas para esse problema. Existem opções para configurar o Pandas para lidar com grandes conjuntos de dados, comprar GPUs ou adquirir poder de computação em nuvem. Neste artigo, veremos como usar o Dask para grandes conjuntos de dados em sua máquina local.
Dask e Python
Dask é uma biblioteca de computação paralela Python flexível. Funciona bem com outros projetos de código aberto, como NumPy, Pandas e scikit-learn. Dask tem uma estrutura de array que é equivalente a arrays NumPy, dataframes Dask são semelhantes a dataframes Pandas e Dask-ML é scikit- learn.
Essas semelhanças facilitam a integração do Dask em seu trabalho. A vantagem de usar o Dask é que você pode dimensionar a computação para vários núcleos em seu computador. Assim, você tem a oportunidade de trabalhar com grandes quantidades de dados que não cabem na memória. Você também pode acelerar os cálculos que geralmente ocupam muito espaço.
Fonte
Dask DataFrame
Ao carregar uma grande quantidade de dados, o Dask geralmente lê uma amostra dos dados para reconhecer os tipos de dados. Na maioria das vezes, isso leva a erros, pois pode haver diferentes tipos de dados na mesma coluna. É recomendável que você declare os tipos com antecedência para evitar erros. Dask pode baixar arquivos enormes dividindo-os em blocos definidos pelo parâmetro
blocksize.
data_types ={'column1': str,'column2': float}
df = dd.read_csv(“data,csv”,dtype = data_types,blocksize=64000000 )
Os
comandos de origem no Dask DataFrame são semelhantes aos comandos do Pandas. Por exemplo, obter
headetail dataframe é semelhante:
df.head()
df.tail()As funções no DataFrame são lentas. Ou seja, eles não são avaliados até que a função seja chamada
compute.
df.isnull().sum().compute()Como os dados são carregados em blocos, algumas funções do Pandas, como
sort_values()falharão. Mas você pode usar a funçãonlargest().
Clusters em Dask
A computação paralela é a chave do Dask porque permite que você leia em vários núcleos ao mesmo tempo. Dask fornece
machine schedulerque funciona em uma única máquina. Não escala. Também existe um distributed schedulerque permite dimensionar para várias máquinas.
O uso
dask.distributedrequer configuração do cliente. Esta é a primeira coisa que você faz se planeja usá-lo dask.distributed em sua análise. Ele fornece baixa latência, localidade de dados, comunicação trabalhador a trabalhador e é fácil de configurar.
from dask.distributed import Client
client = Client()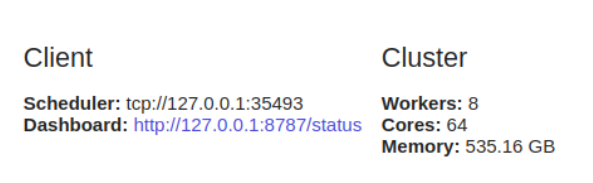
É
dask.distributedvantajoso usar mesmo em uma única máquina, pois oferece funções de diagnóstico por meio de um painel.
Se você não configurar
Client, então, por padrão, você usará o agendador de máquina para uma máquina. Ele fornecerá simultaneidade em um único computador usando processos e threads.
Dask ML
Dask também permite o treinamento e previsão de modelos paralelos. O objetivo
dask-mlé oferecer aprendizado de máquina escalonável. Ao declarar n_jobs = -1 scikit-learn, você pode executar cálculos em paralelo. Dask usa esse recurso para permitir que você faça cálculos em um cluster. Você pode fazer isso com o pacote joblib , que ativa o paralelismo e o pipelining em Python. Com o Dask ML, você pode usar modelos do scikit-learn e outras bibliotecas como o XGboost.
Uma implementação simples seria assim.
Primeiro, importe
train_test_splitpara dividir seus dados em casos de treinamento e teste.
from dask_ml.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)Em seguida, importe o modelo que deseja usar e instancie-o.
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(verbose=1)Então você precisa importar
joblibpara habilitar a computação paralela.
import joblibEm seguida, comece a treinar e prever com o back-end paralelo.
from sklearn.externals.joblib import parallel_backend
with parallel_backend(‘dask’):
model.fit(X_train,y_train)
predictions = model.predict(X_test)Limites e uso de memória
Tarefas individuais no Dask não podem ser executadas em paralelo. Trabalhadores são processos Python que herdam as vantagens e desvantagens da computação Python. Além disso, ao trabalhar em um ambiente distribuído, deve-se ter cuidado para garantir a segurança e a privacidade de seus dados.
Dask tem um agendador central que monitora dados em nós de trabalho e no cluster. Ele também gerencia a liberação de dados do cluster. Quando a tarefa for concluída, ele o removerá imediatamente da memória para liberar espaço para outras tarefas. Mas se algo for necessário para um determinado cliente, ou for importante para os cálculos atuais, será armazenado na memória.
Outra limitação do Dask é que ele não implementa todas as funcionalidades do Pandas. A interface do Pandas é muito grande, então Dask não a cobre completamente. Ou seja, realizar algumas dessas operações no Dask pode ser desafiador. Além disso, as operações lentas do Pandas também serão lentas em Dask.
Quando você não precisa de um Dask DataFrame
Nas seguintes situações, Dask pode não ser a opção certa para você:
- Quando o Pandas tem funções de que você precisa, mas Dask não as implementou.
- Quando seus dados se encaixam perfeitamente na memória do seu computador.
- Quando seus dados não são apresentados em forma de tabela. Nesse caso, tente dask.bag ou disk.array .
Pensamentos finais
Neste artigo, vimos como você pode usar o Dask para trabalhar de forma distribuída com grandes conjuntos de dados em seu computador local. Vimos que podemos usar o Dask, pois sua sintaxe já nos é familiar. Além disso, o Dask pode ser dimensionado para milhares de núcleos.
Também vimos que podemos usá-lo no aprendizado de máquina para previsão e treinamento. Se quiser saber mais, verifique esses materiais na documentação .
