
Esta é uma tradução do segundo artigo de uma série sobre privacidade diferencial.
Na semana passada, no primeiro artigo desta série - " Privacidade diferencial - analisando dados enquanto mantém a confidencialidade (introdução à série) " - examinamos os conceitos básicos e os usos da privacidade diferencial. Hoje vamos considerar as opções possíveis para construir sistemas, dependendo do modelo de ameaça esperado.
A implantação de um sistema que atenda aos princípios de privacidade diferencial não é uma tarefa trivial. Como exemplo, em nossa próxima postagem, veremos um programa Python simples que implementa a adição de ruído Laplace diretamente em uma função que processa dados confidenciais. Mas para que isso funcione, precisamos coletar todos os dados necessários em um servidor.
E se o servidor for hackeado? Nesse caso, a privacidade diferencial não nos ajudará, pois só protege os dados obtidos com o trabalho do programa!
Ao implantar sistemas com base nos princípios de privacidade diferencial, é importante considerar o modelo de ameaça: de quais oponentes queremos proteger o sistema. Se esse modelo inclui invasores capazes de comprometer completamente um servidor com dados confidenciais, então precisamos mudar o sistema para que ele possa resistir a tais ataques.
Ou seja, as arquiteturas de sistemas que respeitam a privacidade diferencial devem considerar tanto a privacidade quanto a segurança . A privacidade controla o que pode ser recuperado dos dados retornados pelo sistema. E a segurança pode ser considerada a tarefa oposta: é o controle do acesso a parte dos dados, mas não dá nenhuma garantia quanto ao seu conteúdo.
Modelo de privacidade central diferencial
O modelo de ameaça mais comumente usado no trabalho de privacidade diferencial é o modelo de privacidade diferencial central (ou simplesmente "privacidade diferencial central").
O principal componente - o armazenamento de dados confiáveis (curador de dados confiáveis) . Cada fonte envia a ele seus dados confidenciais e os coleta em um único lugar (por exemplo, em um servidor). Um repositório é confiável se presumirmos que ele processa nossos dados confidenciais por conta própria, não os transfere para ninguém e não pode ser comprometido por ninguém. Em outras palavras, acreditamos que um servidor com dados confidenciais não pode ser comprometido.
Como parte do modelo central, geralmente adicionamos ruído às respostas às consultas (veremos a implementação de Laplace no próximo artigo). A vantagem deste modelo é a capacidade de adicionar o menor valor de ruído possível, mantendo assim a precisão máxima permitida pelos princípios de privacidade diferencial. Abaixo está um diagrama do processo. Colocamos uma barreira de privacidade entre o armazenamento de dados confiável e o analista para que apenas os resultados que atendam aos critérios de privacidade diferencial especificados possam sair. Assim, o analista não precisa ser confiável.
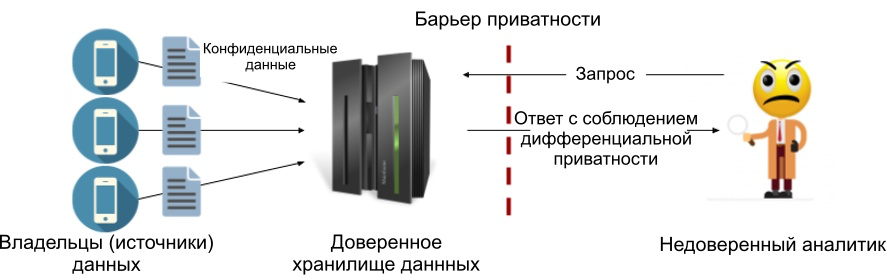
Figura 1: O modelo central de privacidade diferencial.
A desvantagem do modelo central é que ele requer um armazenamento confiável, e muitos deles não. Na verdade, a falta de confiança no consumidor dos dados costuma ser o principal motivo para o uso de princípios de privacidade diferenciados.
Modelo de privacidade diferencial local
O modelo de privacidade diferencial local permite que você se livre do armazenamento de dados confiável: cada fonte de dados (ou proprietário dos dados) adiciona ruído aos seus dados antes de transferi-los para o armazenamento. Isso significa que o armazenamento nunca conterá informações confidenciais, o que significa que não há necessidade de sua procuração. A figura abaixo mostra o dispositivo do modelo local: nele, uma barreira de privacidade está entre cada proprietário dos dados e o armazenamento (que pode ou não ser confiável).
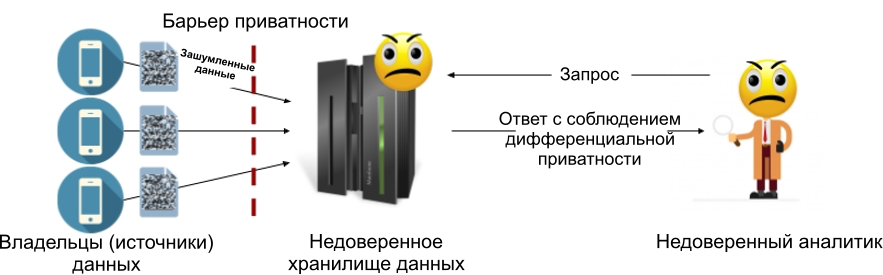
Figura 2: Modelo de privacidade diferencial local.
O modelo de privacidade diferencial local evita o principal problema do modelo central: se o data warehouse for comprometido, os hackers só terão acesso a dados ruidosos que já atendam aos requisitos de privacidade diferencial. Esta é a principal razão pela qual o modelo local foi escolhido para sistemas como o Google RAPPOR [1] e o sistema de coleta de dados da Apple [2].
Mas por outro lado? O modelo local é menos preciso do que o central. No modelo local, cada fonte adiciona ruído de forma independente para satisfazer suas próprias condições de privacidade diferencial, de forma que o ruído total de todos os participantes seja muito maior do que o ruído no modelo central.
Em última análise, essa abordagem só se justifica para consultas com uma tendência (sinal) muito persistente. A Apple, por exemplo, usa um modelo local para estimar a popularidade do emoji, mas o resultado só é útil para o emoji mais popular (onde a tendência é mais pronunciada). Normalmente, esse modelo não é usado para consultas mais complexas, como aquelas usadas pelo US Census Bureau [10] ou aprendizado de máquina.
Modelos híbridos
Os modelos central e local têm vantagens e desvantagens, e o principal esforço agora é tirar o melhor deles.
Por exemplo, você pode usar o modelo de embaralhamento implementado no sistema Prochlo [4]. Ele contém um armazenamento de dados não confiável, muitos proprietários de dados individuais e vários shufflers parcialmente confiáveis .... Cada fonte adiciona primeiro uma pequena quantidade de ruído aos seus dados e depois a envia para o agitador, que adiciona mais ruído antes de enviá-lo para o data warehouse. O resultado final é que é improvável que os agitadores "consigam" (ou sejam hackeados ao mesmo tempo) com o armazenamento de dados ou entre si, portanto, um pouco de ruído adicionado pelas fontes será suficiente para garantir a privacidade. Cada mixer pode lidar com várias fontes, assim como o modelo central, portanto, uma pequena quantidade de ruído garantirá a privacidade do conjunto de dados resultante.
O modelo do agitador é um compromisso entre os modelos local e central: adiciona menos ruído do que o local, mas mais do que central.
Você também pode combinar privacidade diferencial com criptografia, como na computação multipartidária segura (MPC) ou criptografia totalmente homomórfica (FHE). O FHE permite cálculos com dados criptografados sem primeiro descriptografá-los, e o MPC permite que um grupo de participantes execute consultas com segurança em fontes distribuídas sem revelar seus dados. Computando funções privadas diferenciaisusar a computação cripto-segura (ou apenas segura) é uma maneira promissora de atingir a precisão do modelo central com todos os benefícios do local. Além disso, neste caso, o uso de computação segura elimina a necessidade de um armazenamento confiável. Trabalhos recentes [5] demonstram resultados encorajadores da combinação de MPC e privacidade diferencial, absorvendo a maioria das vantagens de ambas as abordagens. É verdade que, na maioria dos casos, os cálculos seguros são várias ordens de magnitude mais lentos do que os realizados localmente, o que é especialmente importante para grandes conjuntos de dados ou consultas complexas. A computação segura está atualmente em fase de desenvolvimento ativa, portanto, seu desempenho está aumentando rapidamente.
Então?
No próximo artigo, daremos uma olhada em nossa primeira ferramenta de código aberto para colocar em prática conceitos diferenciais de privacidade. Vejamos outras ferramentas, disponíveis para iniciantes e aplicáveis a bancos de dados muito grandes, como o US Census Bureau. Tentaremos calcular os dados populacionais de acordo com os princípios da privacidade diferencial.
Assine nosso blog e não perca a tradução do próximo artigo. Muito em breve.
Fontes
[1] Erlingsson, Úlfar, Vasyl Pihur e Aleksandra Korolova. "Rappor: Resposta ordinal de preservação de privacidade agregável aleatória." Em Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security, pp. 1054-1067. 2014.
[2] Apple Inc. "Visão geral técnica da privacidade diferencial da Apple." Acessado em 31/07/2020. https://www.apple.com/privacy/docs/Differential_Privacy_Overview.pdf
[3] Garfinkel, Simson L., John M. Abowd e Sarah Powazek. "Problemas encontrados na implantação de privacidade diferencial." Em Proceedings of the 2018 Workshop on Privacy in the Electronic Society, pp. 133-137. 2018.
[4] Bittau, Andrea, Úlfar Erlingsson, Petros Maniatis, Ilya Mironov, Ananth Raghunathan, David Lie, Mitch Rudominer, Ushasree Kode, Julien Tinnes e Bernhard Seefeld. "Prochlo: forte privacidade para análises na multidão." Em Proceedings of the 26th Symposium on Operating Systems Principles, pp. 441-459. 2017.
[5] Roy Chowdhury, Amrita, Chenghong Wang, Xi He, Ashwin Machanavajjhala e Somesh Jha. "Cryptε: Crypto-Assisted Differential Privacy on Untrusted Servers." Em Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, pp. 603-619. 2020.