 Há algum tempo, a plataforma Apache Ignite apareceu no horizonte e começou a ganhar popularidade. A computação in-memory é velocidade, o que significa que a velocidade deve ser garantida em todas as etapas do trabalho, especialmente ao carregar dados.
Há algum tempo, a plataforma Apache Ignite apareceu no horizonte e começou a ganhar popularidade. A computação in-memory é velocidade, o que significa que a velocidade deve ser garantida em todas as etapas do trabalho, especialmente ao carregar dados.
Abaixo do corte está uma descrição de uma maneira de carregar rapidamente os dados de uma tabela relacional em um cluster distribuído do Apache Ignite. O pré-processamento do conjunto de resultados da consulta SQL no nó cliente do cluster e a distribuição de dados no cluster usando a tarefa de redução de mapa são descritos. Descreve os caches e as tabelas relacionais relacionadas, mostra como criar um objeto personalizado a partir de uma linha da tabela e como usar o ComputeTaskAdapter para colocar rapidamente os objetos criados. Todo o código pode ser visto integralmente no repositório FastDataLoad .
História do problema
Este texto é uma tradução para o russo de minha postagem no In-Memory Computing Blog no site GridGain.
Portanto, uma determinada empresa decide acelerar um aplicativo lento, movendo a computação para um cluster na memória. Os dados iniciais para cálculos estão em MS SQL; o resultado dos cálculos deve ser colocado lá. O cluster é distribuído, pois já há muitos dados, o desempenho da aplicação está no limite e o volume de dados está crescendo. Limites de tempo difíceis são definidos.
Antes de escrever código rápido para processar dados, os dados precisam ser carregados rapidamente. Uma busca frenética na web revela uma falta distinta de exemplos de código que podem escalar para tabelas de dezenas ou centenas de milhões de linhas. Exemplos que você pode baixar, compilar e percorrer as etapas de depuração. Isso é por um lado.
, Apache Ignite / GridGain, . , . " ?", — , .
, .
(World Database)
, data collocation, . world.sql Apache Ignite.
CSV , — SQL :
- countryCache — country.csv;
- cityCache — city.csv;
- countryLanguageCache — countryLanguage.csv.
countryCache country.csv. countryCache — code, — String, — Country, (name, continent, region).

, — , . Country , . org.h2.tools.Csv, CSV java.sql.ResultSet. Apache Ignite , SQL H2.
// define countryCache
IgniteCache<String,Country> cache = ignite.cache("countryCache");
try (ResultSet rs = new Csv().read(csvFileName, null, null)) {
while (rs.next()) {
String code = rs.getString("Code");
String name = rs.getString("Name");
String continent = rs.getString("Continent");
Country country = new Country(code,name,continent);
cache.put(code,country);
}
}. , , . - .
, . , .
Apache Ignite — -. , PARTITIONED - (partition) . ; , . -, affinity function, , .

, :
- HashMap partition_number -> key -> Value
Map<Integer, Map<String, Country>> result = new HashMap<>(); - affinity function partition_number. cache.put() - HashMap partition_number
try (ResultSet rs = new Csv().read(csvFileName, null, null)) { while (rs.next()) { String code = rs.getString("Code"); String name = rs.getString("Name"); String continent = rs.getString("Continent"); Country country = new Country(code,name,continent); result.computeIfAbsent(affinity.partition(key), k -> new HashMap<>()).put(code,country); } }
ComputeTaskAdapter ComputeJobAdapter. ComputeJobAdapter 1024. , .
ComputeJobAdapter . , .
Compute Task,
, "ComputeTaskAdapter initiates the simplified, in-memory, map-reduce process". ComputeJobAdapter map — , . reduce — .
(RenewLocalCacheJob)
targetCache.putAll(addend);RenewLocalCacheJob partition_number .
(AbstractLoadTask)
( loader) — AbstractLoadTask. . ( ), AbstractLoadTask TargetCacheKeyType. HashMap
Map<Integer, Map<TargetCacheKeyType, BinaryObject>> result;countryCache String. . AbstractLoadTask TargetCacheKeyType, BinaryObject. , — .
BinaryObject
— . , JVM, - . class definition , JAR- . Country
IgniteCache<String, Country> countryCache;, , classpath ClassNotFound.
. — classpath, :
- JAR- ;
- classpath ;
- ;
- .
— BinaryObject () . :
-
IgniteCache<String, BinaryObject> countryCache; - Country BinaryObject (. LoadCountries.java)
Country country = new Country(code, name, .. ); BinaryObject binCountry = node.binary().toBinary(country); - HashMap, BinaryObject
Map<Integer, Map<String, BinaryObject>> result
, . , , ClassNotFoundException .
. .
Apache Ignite : .
default-config.xml — . :
- GridGain CE Installing Using ZIP Archive. 8.7.10, FastDataLoad , ;
- {gridgain}\config default-config.xml
<bean id="grid.cfg" class="org.apache.ignite.configuration.IgniteConfiguration"> <property name="peerClassLoadingEnabled" value="true"/> </bean> - , {gridgain}\bin ignite.bat. ; ;
- , . ,
[08:40:04] Topology snapshot [ver=2, locNode=d52b1db3, servers=2, clients=0, state=ACTIVE, CPUs=8, offheap=3.2GB, heap=2.0GB]
. , 8.7.25, pom.xml
<gridgain.version>8.7.25</gridgain.version>
class org.apache.ignite.spi.IgniteSpiException: Local node and remote node have different version numbers (node will not join, Ignite does not support rolling updates, so versions must be exactly the same) [locBuildVer=8.7.25, rmtBuildVer=8.7.10] , , map-reduce. — JAR-, compute task . Windows, Linux.
:
- FastDataLoad;
- ;
mvn clean package - , .
java -jar .\target\fastDataLoad.jar
main() LoadApp LoaderAgrument . map-reduce LoadCountries.
LoadCountries RenewLocalCacheJob , ( ).
#1

#2

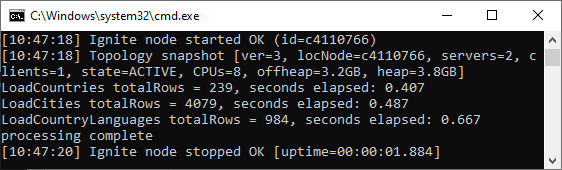
country.csv , CountryCode . cityCache countryLanguageCache; , .
.
.
:
- (SQL Server Management Studio):
- — 44 686 837;
- — 1.071 GB;
- — 0H:1M:35S;
- RenewLocalCacheJob reduce — 0H:0M:9S.
Leva menos tempo para distribuir dados em um cluster do que para executar uma consulta SQL.