
A equipe investe muito trabalho, esforço e recursos em cada mudança no jogo: às vezes, o desenvolvimento de uma nova funcionalidade ou nível leva vários meses. A tarefa do analista é minimizar os riscos da introdução de tais mudanças e ajudar a equipe a tomar a decisão certa sobre o desenvolvimento posterior do projeto.
Ao analisar decisões, é importante ser guiado por dados estatisticamente significativos que correspondam às preferências do público, em vez de suposições intuitivas. O teste A / B ajuda a obter esses dados e avaliá-los.
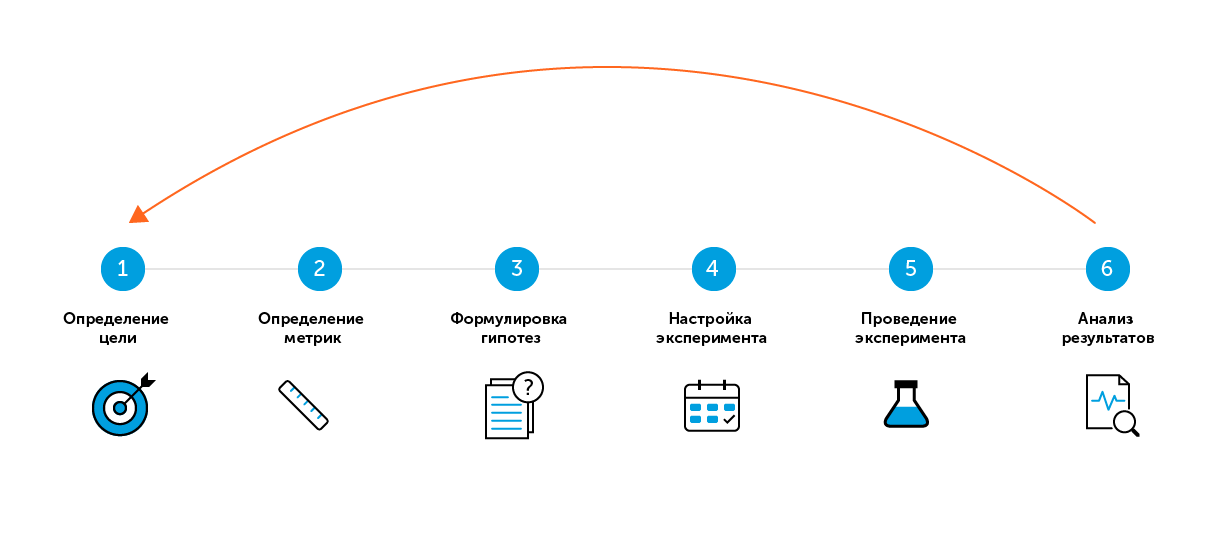
6 etapas "fáceis" de teste A / B
Para o termo de pesquisa "teste A / B" ou "teste de divisão", a maioria das fontes oferece algumas etapas "simples" para um teste bem-sucedido. Existem seis etapas em minha estratégia.
À primeira vista, tudo é simples:
- há grupo A, controle, sem mudanças no jogo;
- existe o grupo B, teste, com alterações. Por exemplo, uma nova funcionalidade foi adicionada, a dificuldade dos níveis foi aumentada, o tutorial foi alterado;
- execute o teste e veja qual variante tem melhor desempenho.
Na prática, é mais difícil. Para que a equipe implemente a melhor solução, eu, como analista, preciso responder o quão confiante estou nos resultados dos testes. Vamos lidar com as dificuldades passo a passo.
Etapa 1. Determine a meta
Por um lado, podemos testar tudo o que vem à mente de cada membro da equipe - desde a cor do botão até os níveis de dificuldade do jogo. A capacidade técnica de conduzir testes de divisão é incorporada aos nossos produtos na fase de design.
Por outro lado, é importante priorizar todas as sugestões para melhorar o jogo de acordo com o nível do efeito na métrica alvo. Portanto, primeiro traçamos um plano para lançar o teste de divisão da hipótese de maior prioridade para a menor.
Tentamos não executar vários testes A / B em paralelo para entender exatamente quais das novas funcionalidades afetaram a métrica alvo. Parece que com esta estratégia levará mais tempo para testar todas as hipóteses. Mas a priorização ajuda a eliminar hipóteses pouco promissoras no estágio de planejamento.
Obtemos dados que refletem melhor o efeito de mudanças específicas e não perdemos tempo configurando testes com efeitos questionáveis.
Definitivamente, discutimos o plano de lançamento com a equipe, uma vez que o foco de interesse muda em diferentes estágios do ciclo de vida do produto. No início do projeto, geralmente é Retenção D1 - a porcentagem de jogadores que voltaram ao jogo no dia seguinte após sua instalação. Em estágios posteriores, podem ser métricas de retenção ou monetização: conversão, ARPU e outros.
Exemplo.As métricas de retenção requerem atenção especial depois que um projeto é lançado no soft launch. Nesta fase, vamos destacar um dos possíveis problemas: A retenção D1 não atinge o nível dos benchmarks da empresa para um determinado gênero de jogo. É necessário analisar o funil de passagem dos primeiros níveis. Digamos que você notou uma grande queda de jogadores entre o início e a conclusão do terceiro nível - uma baixa taxa de conclusão do terceiro nível.
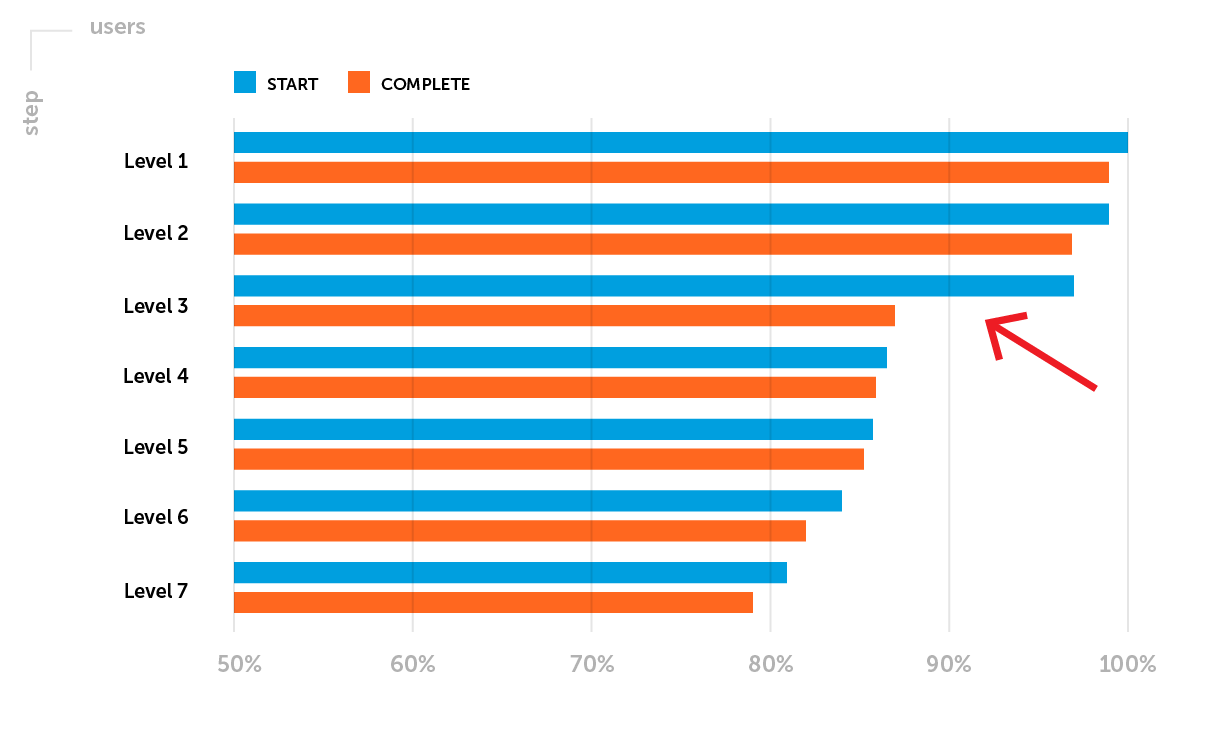
O objetivo do teste A / B planejado : aumentar a Retenção D1 aumentando a proporção de jogadores que concluíram o Nível 3 com sucesso.
Etapa 2. Definindo métricas
Antes de iniciar o teste A / B, determinamos o parâmetro monitorado - selecionamos a métrica, mudanças nas quais mostrarão se a nova funcionalidade do jogo é mais bem-sucedida do que a original.
Existem dois tipos de métricas:
- quantitativo - a duração média da sessão, o tamanho da verificação média, o tempo que leva para completar o nível, a quantidade de experiência e assim por diante
- qualidade - Retenção, Taxa de Conversão e outros.
O tipo de métrica afeta a escolha do método e das ferramentas para avaliar a significância dos resultados.
É provável que a funcionalidade testada afete não um alvo, mas várias métricas. Portanto, observamos as mudanças em geral, mas não tentamos encontrar "nada" quando não há significância estatística na avaliação da métrica alvo.
De acordo com a meta da primeira etapa, para o próximo teste A / B avaliaremos a Taxa de Conclusão do 3º nível - uma métrica qualitativa.
Etapa 3. Formule uma hipótese
Cada teste A / B testa uma hipótese geral, que é formulada antes do lançamento. Respondemos à pergunta: que mudanças esperamos no grupo de teste? O texto geralmente se parece com isto:
"Esperamos que (impacto) cause (mudança)" Os
métodos estatísticos funcionam da maneira oposta - não podemos usá-los para provar que a hipótese está correta. Portanto, após formular uma hipótese geral, duas estatísticas são determinadas. Eles ajudam a entender que a diferença observada entre o grupo de controle A e o grupo de teste B é um acidente ou o resultado de mudanças.
Em nosso exemplo:
- Hipótese nula ( H0 ): Reduzir a dificuldade do Nível 3 não afetará a proporção de usuários que concluem o Nível 3 com sucesso. A taxa de conclusão de nível 3 para os grupos A e B não é realmente diferente e as diferenças observadas são aleatórias.
- Hipótese alternativa ( H1 ): Reduzir a dificuldade do nível 3 aumentará a proporção de usuários que concluem o nível 3 com sucesso. A taxa de conclusão de nível 3 é mais alta no Grupo B do que no Grupo A, e essas diferenças são o resultado de mudanças.
Nesta fase, além de formular uma hipótese, é necessário avaliar o efeito esperado.
Hipótese: "Esperamos que uma diminuição na dificuldade do Nível 3 cause um aumento na Taxa de Conclusão do Nível 3 de 85% para 95%, ou seja, em mais de 11%."
(95% -85%) / 85% = 0,117 => 11,7%
Neste exemplo, ao determinar a Taxa de Conclusão esperada do Nível 3, pretendemos aproximá-la da Taxa de Conclusão média dos níveis iniciais.
Etapa 4. Configurando o experimento
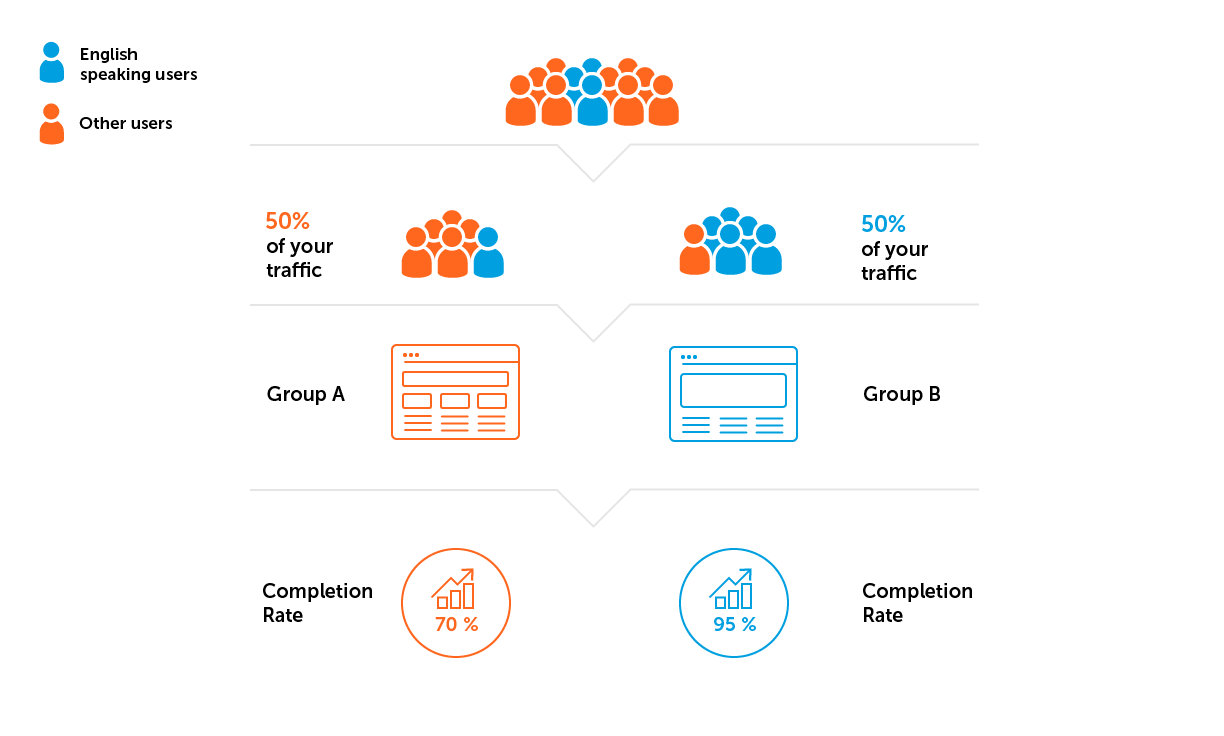
1. Defina os parâmetros para os grupos A / B antes de iniciar o experimento: para qual público lançamos o teste, para qual proporção de jogadores, quais configurações definimos em cada grupo.
2. Verificamos a representatividade da amostra como um todo e a homogeneidade das amostras nos grupos. Você pode executar previamente um teste A / A para avaliar esses parâmetros - um teste no qual os grupos de teste e controle têm a mesma funcionalidade. O teste A / A ajuda a garantir que não haja diferenças estatisticamente significativas nas métricas de destino em ambos os grupos. Se houver diferenças, um teste A / B com essas configurações - tamanho da amostra e nível de confiança - não pode ser executado.
A amostra não será perfeitamente representativa, mas sempre prestamos atenção à estrutura dos usuários em função de suas características - usuário novo / antigo, nível de jogo, país. Tudo está vinculado ao objetivo do teste A / B e é negociado com antecedência. É importante que a estrutura dos usuários em cada grupo seja condicionalmente a mesma.
Existem duas armadilhas potencialmente perigosas aqui:
- Altas métricas em grupos durante o experimento podem ser uma consequência de atrair um bom tráfego. O tráfego é bom se as taxas de engajamento forem altas. Tráfego ruim é a causa mais comum de queda nas métricas.
- Heterogeneidade da amostra. Digamos que o projeto do nosso exemplo esteja sendo desenvolvido para um público que fala inglês. Isso significa que precisamos evitar uma situação em que mais usuários de países onde o inglês não é predominante caiam em um dos grupos.
3. Calcule o tamanho da amostra e a duração do experimento.
Parece que o momento é transparente, dado o enorme conjunto de calculadoras online.
No entanto, seu uso requer a entrada de informações iniciais específicas. Para escolher a opção apropriada para uma calculadora online, pense nos tipos de dados e entenda os termos a seguir.
- População em geral - todos os usuários para os quais as conclusões do teste A / B serão distribuídas no futuro.
- Amostra - usuários que realmente são testados. Com base nos resultados da análise da amostra, são tiradas conclusões sobre o comportamento de toda a população em geral.
- , . — , , , .
- , . .
- (α) — , (0), .
- (1-α) — , , .
- (1-β) — , , .
A combinação desses parâmetros permite calcular o tamanho da amostra necessária em cada grupo e a duração do teste.
Em uma calculadora online, você pode brincar com os dados de entrada para entender a natureza de seu relacionamento.
Um exemplo . Vamos usar a calculadora Optimizely para calcular o tamanho da amostra para uma taxa de conversão de 1%. Considere que o tamanho do efeito esperado é de 5% a um nível de confiança de 95% (o indicador é calculado como 1-α). Observe que na interface desta calculadora, o termo Significância estatística é usado para significar “Nível de confiança” a um nível de significância de 5%.
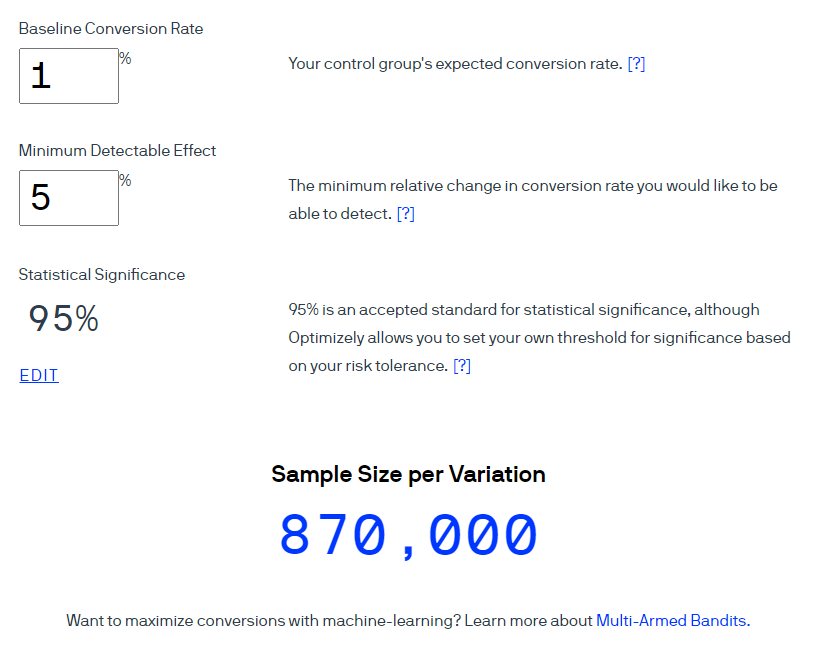
Optimizely afirma que 870.000 usuários devem ser incluídos em cada grupo.
Converter o tamanho da amostra para uma duração aproximada do teste - dois cálculos simples.
Cálculo No. 1. Tamanho da amostra × número de grupos no experimento = número total de usuários necessários
Cálculo No. 2. Número total de usuários necessários ÷ número médio de usuários por dia = número aproximado de dias do experimento
Se o primeiro grupo requer 870.000 usuários, então para o teste de duas opções, o total o número de usuários será de 1.740.000. Considerando o tráfego de 1.000 jogadores por dia, o teste deve durar 1.740 dias. Esta duração não se justifica. Nesse estágio, geralmente revisamos a hipótese, os dados de base e a adequação do teste.
Em nosso exemplo com uma melhoria de Nível 3, a conversão é a proporção daqueles que concluíram o Nível 3 com sucesso. Ou seja, a taxa de conversão é de 85%, queremos aumentar esse indicador em pelo menos 11%. Com um nível de confiança de 95%, temos 130 usuários por grupo.

Com o mesmo volume de tráfego de 1000 usuários, o teste, grosso modo, pode ser concluído em menos de um dia. Essa conclusão está fundamentalmente errada, pois não leva em consideração a sazonalidade semanal. O comportamento do usuário difere em dias diferentes da semana, por exemplo, pode mudar nos feriados. E em alguns projetos esta influência é muito forte, em outros é quase imperceptível. Esta não é uma condição necessária em todos os projetos e nem em todos os testes, mas nos projetos com os quais já trabalhei, a sazonalidade semanal nos KPI sempre foi observada.
Portanto, arredondamos a duração do teste para semanas para levar em consideração a sazonalidade. Mais frequentemente, nosso ciclo de teste é de uma a duas semanas, dependendo do tipo de teste A / B.
Etapa 5. Conduzindo um experimento
Depois de iniciar um teste A / B, você deseja imediatamente examinar os resultados, mas a maioria das fontes proíbe estritamente fazer isso para excluir o problema de visualização. Para explicar a essência do problema em palavras simples, na minha opinião, ninguém conseguiu até agora. Os autores de tais artigos baseiam suas provas na avaliação de probabilidades, vários resultados da modelagem matemática, que levam os leitores à zona das "fórmulas matemáticas complexas". Sua principal conclusão é um fato quase indiscutível: não olhe para os dados até que a amostra exigida tenha sido digitada e decorrido o número exigido de dias após o início do teste. Como resultado, muitas pessoas interpretam mal o problema de "espiar" e seguem as recomendações literalmente.
Montamos os processos para que a cada dia vejamos dados relevantes para o acompanhamento dos KPI dos projetos. Em painéis pré-preparados, monitoramos o progresso do experimento desde o início: verificamos se os grupos são recrutados uniformemente, se há algum problema crítico após o lançamento do teste que possa afetar os resultados, e assim por diante.
A regra principal é não tirar conclusões prematuras. Todas as conclusões são formuladas de acordo com o desenho estabelecido para o teste A / B e são resumidas em um relatório detalhado. Monitoramos a evolução do indicador desde o lançamento do teste A / B.
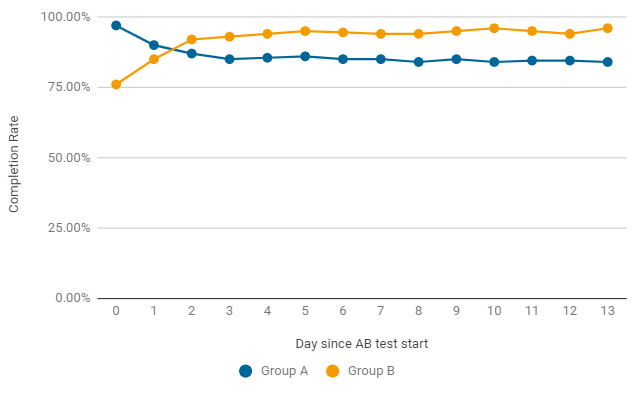
Um exemplo, como no teste A / B, a taxa de conclusão pode mudar por dia.Nos primeiros dois dias após o lançamento, a variante do jogo venceu sem alterações (grupo A), mas acabou por ser apenas um acidente. Já a partir do segundo dia, o indicador do grupo B adquire resultados consistentemente melhores. Para concluir o teste, é necessário não apenas significância estatística, mas também estabilidade, por isso estamos aguardando o final do teste.
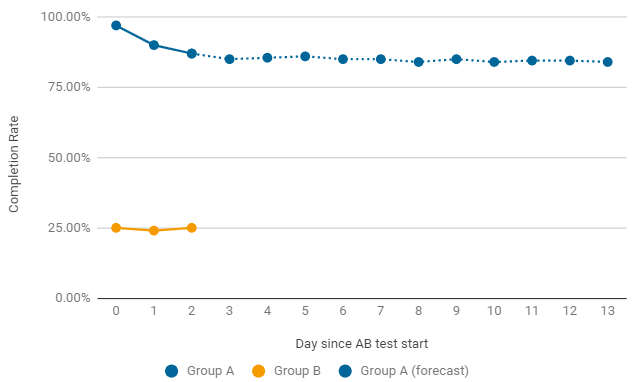
Um exemplo de quando vale a pena terminar um teste A / B prematuramente. Se, após o lançamento, um dos grupos apresentar taxas criticamente baixas, procuramos imediatamente os motivos dessa queda. Os erros mais comuns estão na configuração e nas configurações do nível do jogo. Nesse caso, o teste atual é encerrado prematuramente e um novo com correções é iniciado.
Etapa 6. Analisando os resultados
O cálculo das principais métricas não é particularmente difícil, mas avaliar a importância dos resultados obtidos é um problema separado.
Calculadoras online podem ser usadas para testar a significância estatística dos resultados ao avaliar as métricas de qualidade, como retenção e conversão.
Minhas três principais calculadoras online para tarefas como esta:
- As incríveis ferramentas A / B de Evan são uma das mais populares. Ele implementa vários métodos para avaliar a significância de um teste. Ao usá-lo, você precisa entender claramente a essência de cada parâmetro inserido, interpretar os resultados de forma independente e formular conclusões.
- , A/B Testguide. , . — , .
- A/B Testing Calculator Neilpatel. -, .
Um exemplo . Para a análise de tais testes A / B, temos um painel que exibe todas as informações necessárias para tirar conclusões e destaca automaticamente o resultado com uma mudança significativa no alvo.

Vamos ver como tirar conclusões sobre este teste A / B usando calculadoras.
Dados iniciais:
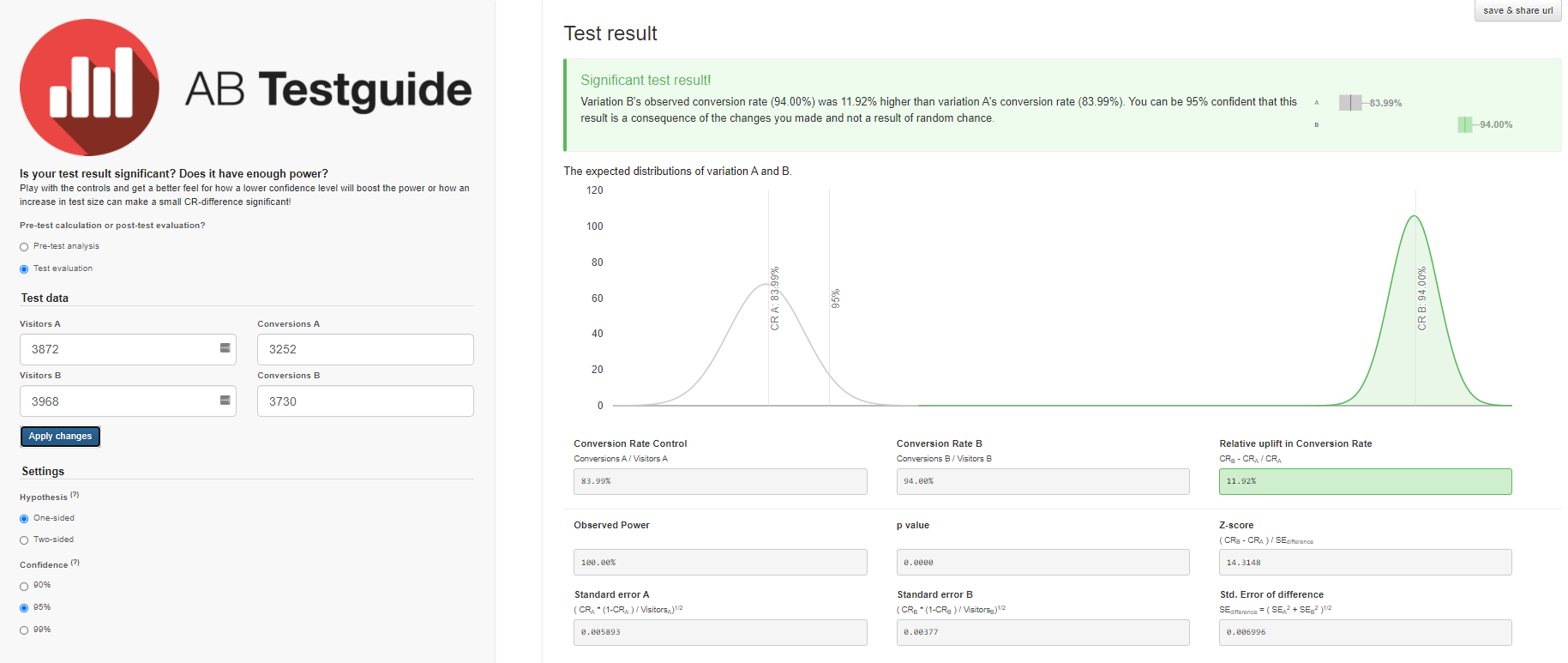
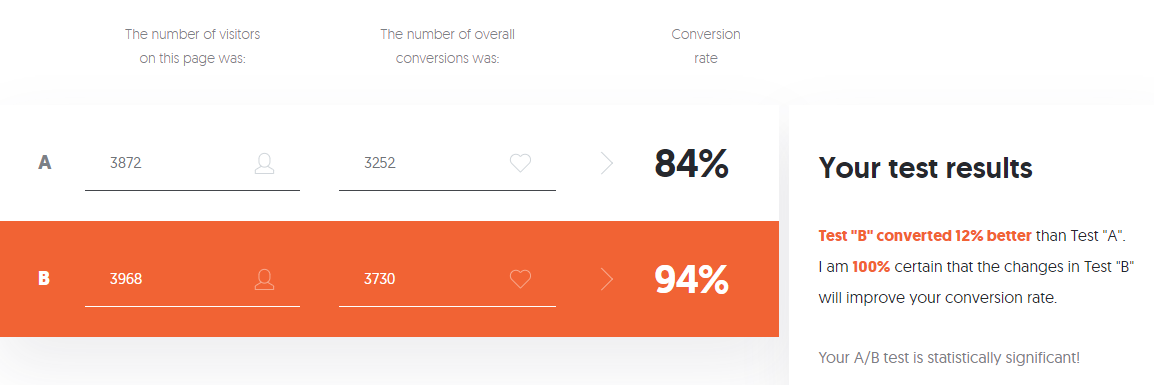
- No grupo A, de 3870 usuários que iniciaram o nível 3, apenas 3.252 usuários o passaram com sucesso - 84%.
- No grupo B, de 3.968 usuários, 3.730 passaram de nível com sucesso - 94%.
A calculadora Awesome A / B Tools de Evan calculou o intervalo de confiança para cada opção, levando em consideração o tamanho da amostra e o nível de significância selecionado.
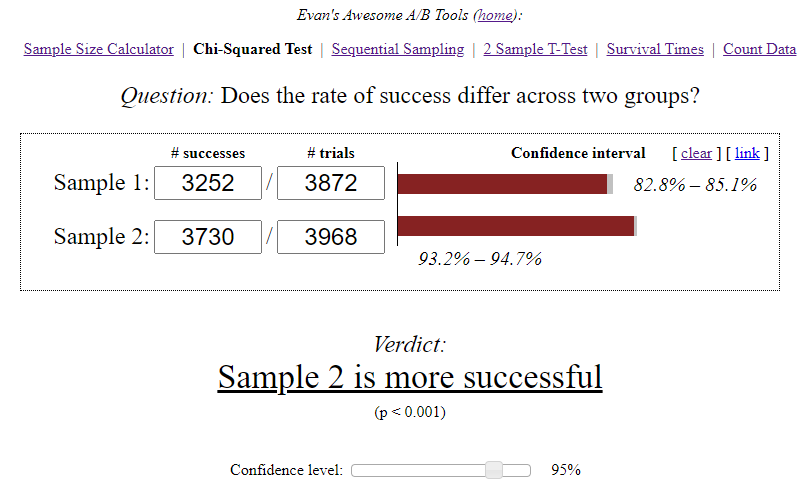
Conclusões independentes:
- A — 84,00%, 82,8%—85,1%. B — 94,00%, 93,2%—94,7%. (94%-84%)/84% = 0,119 => 12%
- 12% , A. — , . 95%.
- .
Obteremos resultados semelhantes com a calculadora A / B Testguide . Mas aqui você já pode brincar com as configurações, obter um resultado gráfico e conclusões formuladas.
Se você tem medo de tantas configurações, não há desejo ou necessidade de lidar com a variedade de dados calculados pela calculadora, você pode usar a Calculadora de Testes A / B da Neilpatel .
Cada calculadora online possui seus próprios critérios e algoritmos, que podem não levar em consideração todas as características do experimento. Como resultado, surgem questões e dúvidas na interpretação dos resultados. Além disso, se a métrica alvo for quantitativa - verificação média ou duração média da primeira sessão - as calculadoras online listadas não são mais aplicáveis e métodos de avaliação mais avançados são necessários.
Elaboro um relatório detalhado sobre cada teste A / B, portanto selecionei e implementei métodos e critérios adequados para minhas tarefas para avaliar a significância estatística dos resultados.
Conclusão
O teste A / B é uma ferramenta que não dá uma resposta inequívoca à pergunta "Qual opção é melhor?", Mas apenas permite reduzir a incerteza no caminho para encontrar as soluções ideais. Ao conduzi-la, os detalhes são importantes em todas as etapas da preparação, cada imprecisão custa recursos e pode afetar negativamente a confiabilidade dos resultados. Espero que este artigo tenha sido útil para você e o ajude a evitar erros nos testes A / B.