Neste artigo, irei abordar um tópico um pouco mais complexo e interessante (pelo menos para mim, o desenvolvedor da equipe de pesquisa): pesquisa de texto completo. Adicionaremos um nó Elasticsearch à nossa região de contêiner, aprenderemos como construir um índice e pesquisar conteúdo, tendo descrições de cinco mil filmes do TMDB 5000 Movie Dataset como dados de teste... Também aprenderemos como fazer filtros de pesquisa e nos aprofundaremos na classificação.
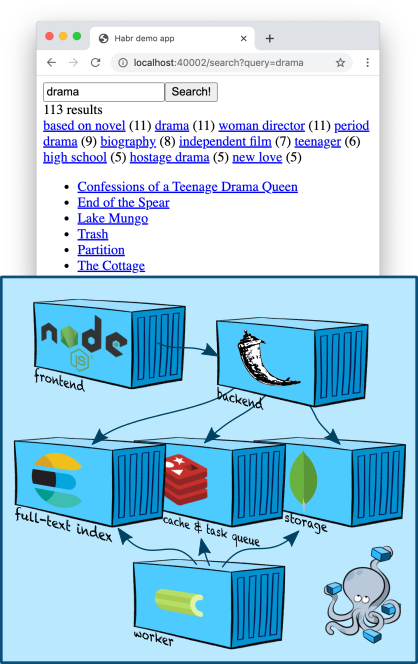
Infraestrutura: Elasticsearch
Elasticsearch é um armazenamento de documentos popular que pode construir índices de texto completo e, como regra, é usado especificamente como um mecanismo de pesquisa. Elasticsearch adiciona ao mecanismo Apache Lucene no qual é baseado, fragmentação, replicação, uma conveniente API JSON e um milhão de detalhes que o tornaram uma das soluções de pesquisa de texto completo mais populares.
Vamos adicionar um nó Elasticsearch ao nosso
docker-compose.yml:
services:
...
elasticsearch:
image: "elasticsearch:7.5.1"
environment:
- discovery.type=single-node
ports:
- "9200:9200"
...
A variável de ambiente
discovery.type=single-nodediz ao Elasticsearch para se preparar para trabalhar sozinho, em vez de procurar outros nós e mesclá-los em um cluster (esse é o comportamento padrão).
Observe que estamos publicando a porta 9200 para fora, embora nosso aplicativo esteja navegando dentro da rede criada por docker-compose. Isso é puramente para depuração: dessa forma, podemos acessar o Elasticsearch diretamente do terminal (até que possamos encontrar uma forma mais inteligente - mais sobre isso abaixo).
Adicionar o cliente Elasticsearch em nossa fiação não é difícil - o bom, o Elastic fornece um cliente Python minimalista .
Indexando
No último artigo, colocamos nossas entidades principais - "cartões" em uma coleção do MongoDB. Podemos recuperar rapidamente seu conteúdo de uma coleção por identificador, porque o MongoDB construiu um índice direto para nós - ele usa árvores B para isso .
Agora nos deparamos com a tarefa inversa - pelo conteúdo (ou seus fragmentos) para obter os identificadores das cartas. Portanto, precisamos de um índice reverso . É aqui que o Elasticsearch se torna útil!
O esquema geral para construir um índice geralmente se parece com este.
- Crie um novo índice vazio com um nome exclusivo e configure-o conforme necessário.
- Passamos por todas as nossas entidades no banco de dados e as colocamos em um novo índice.
- Mudamos a produção para que todas as consultas comecem a ir para o novo índice.
- Removendo o índice antigo. Aqui à vontade - você pode querer armazenar os últimos índices, para que, por exemplo, seja mais conveniente depurar alguns problemas.
Vamos criar o esqueleto do indexador e, em seguida, entrar em mais detalhes com cada etapa.
import datetime
from elasticsearch import Elasticsearch, NotFoundError
from backend.storage.card import Card, CardDAO
class Indexer(object):
def __init__(self, elasticsearch_client: Elasticsearch, card_dao: CardDAO, cards_index_alias: str):
self.elasticsearch_client = elasticsearch_client
self.card_dao = card_dao
self.cards_index_alias = cards_index_alias
def build_new_cards_index(self) -> str:
# .
# .
index_name = "cards-" + datetime.datetime.now().strftime("%Y-%m-%d-%H-%M-%S")
# .
# .
self.create_empty_cards_index(index_name)
# .
#
# .
for card in self.card_dao.get_all():
self.put_card_into_index(card, index_name)
return index_name
def create_empty_cards_index(self, index_name):
...
def put_card_into_index(self, card: Card, index_name: str):
...
def switch_current_cards_index(self, new_index_name: str):
...
Indexação: criando um índice
Um índice no Elasticsearch é criado por uma simples solicitação PUT
/-ou, no caso de usar um cliente Python (em nosso caso), chamando
elasticsearch_client.indices.create(index_name, {
...
})
O corpo da solicitação pode conter três campos.
- Descrição dos aliases (
"aliases": ...). O sistema de alias permite que você mantenha o conhecimento de qual índice está atualmente atualizado no lado do Elasticsearch; vamos falar sobre isso abaixo. - Configurações (
"settings": ...). Quando somos grandes caras com produção real, seremos capazes de configurar a replicação, fragmentação e outras alegrias SRE aqui. - Esquema de dados (
"mappings": ...). Aqui podemos especificar quais tipos de campos nos documentos que indexaremos, para quais desses campos precisamos de índices inversos, para quais agregações devem ser suportadas e assim por diante.
Agora, estamos apenas interessados no esquema e o temos muito simples:
{
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "english"
},
"text": {
"type": "text",
"analyzer": "english"
},
"tags": {
"type": "keyword",
"fields": {
"text": {
"type": "text",
"analyzer": "english"
}
}
}
}
}
}
Marcamos o campo
name, e textcomo o texto em inglês. Um analisador é uma entidade no Elasticsearch que processa texto antes de armazená-lo em um índice. No caso do englishanalisador, o texto será dividido em tokens ao longo dos limites das palavras ( detalhes ), após o que tokens individuais serão lematizados de acordo com as regras do idioma inglês (por exemplo, a palavra treesserá simplificada para tree), lemas muito gerais (mais ou menos the) serão excluídos e os lemas restantes serão colocados no índice reverso.
O campo é um
tagspouco mais complicado. Um tipokeywordassume que os valores deste campo são algumas constantes de string que não precisam ser processadas pelo analisador; o índice inverso será construído com base em seus valores "brutos" - sem tokenização e lematização. Mas o Elasticsearch criará estruturas de dados especiais para que as agregações possam ser lidas pelos valores deste campo (por exemplo, para que, simultaneamente com a pesquisa, você possa descobrir quais tags foram encontradas em documentos que atendem à consulta de pesquisa, e em que quantidade). Isso é ótimo para campos que são essencialmente enum; vamos usar esse recurso para fazer alguns filtros de pesquisa interessantes.
Mas para que o texto das tags também possa ser pesquisado por pesquisa de texto, adicionamos um subcampo
"text", configurado por analogia com nameetextacima - em essência, isso significa que Elasticsearch criará outro campo "virtual" sob o nome em todos os documentos que receber tags.text, no qual copiará o conteúdo tags, mas o indexará de acordo com regras diferentes.
Indexação: preenchendo o índice
Para indexar um documento, basta fazer uma solicitação PUT
/-/_create/id-ou, ao usar um cliente Python, apenas chamar o método requerido. Nossa implementação será semelhante a esta:
def put_card_into_index(self, card: Card, index_name: str):
self.elasticsearch_client.create(index_name, card.id, {
"name": card.name,
"text": card.markdown,
"tags": card.tags,
})
Preste atenção ao campo
tags. Embora o tenhamos descrito como contendo uma palavra-chave, não estamos enviando uma única string, mas uma lista de strings. Elasticsearch apóia isso; nosso documento estará localizado em qualquer um dos valores.
Indexação: trocando o índice
Para implementar uma pesquisa, precisamos saber o nome do índice totalmente construído mais recente. O mecanismo de alias nos permite manter essas informações no lado do Elasticsearch.
Um alias é um ponteiro para zero ou mais índices. A API Elasticsearch permite que você use um nome de alias em vez de um nome de índice ao pesquisar (POST em
/-/_searchvez de POST /-/_search); neste caso, o Elasticsearch pesquisará todos os índices apontados pelo alias.
Vamos criar um alias chamado
cards, que sempre apontará para o índice atual. Assim, a mudança para o índice real após a conclusão da construção ficará assim:
def switch_current_cards_index(self, new_index_name: str):
try:
# , .
remove_actions = [
{
"remove": {
"index": index_name,
"alias": self.cards_index_alias,
}
}
for index_name in self.elasticsearch_client.indices.get_alias(name=self.cards_index_alias)
]
except NotFoundError:
# , - .
# , .
remove_actions = []
#
# .
self.elasticsearch_client.indices.update_aliases({
"actions": remove_actions + [{
"add": {
"index": new_index_name,
"alias": self.cards_index_alias,
}
}]
})
Não vou entrar em mais detalhes sobre a API do alias; todos os detalhes podem ser encontrados na documentação .
Aqui é necessário fazer uma observação que em um serviço real altamente carregado, tal mudança pode ser bastante dolorosa e pode fazer sentido fazer um aquecimento preliminar - carregar o novo índice com algum tipo de pool de consultas salvas do usuário.
Todo o código que implementa a indexação pode ser encontrado neste commit .
Indexação: adicionando conteúdo
Para a demonstração neste artigo, estou usando dados do TMDB 5000 Movie Dataset . Para evitar problemas de direitos autorais, forneço apenas o código do utilitário que os importa de um arquivo CSV, que sugiro que você faça o download no site do Kaggle. Após o download, basta executar o comando
docker-compose exec -T backend python -m tools.add_movies < ~/Downloads/tmdb-movie-metadata/tmdb_5000_movies.csv
para criar cinco mil cartões de cinema e uma equipe
docker-compose exec backend python -m tools.build_index
para construir um índice. Observe que o último comando não cria realmente o índice, mas apenas coloca a tarefa na fila de tarefas, após o que ela será executada no trabalhador - descrevi essa abordagem com mais detalhes no último artigo .
docker-compose logs workermostrar como o trabalhador tentou!
Antes de entrarmos na pesquisa real, queremos ver com nossos próprios olhos se algo foi escrito no Elasticsearch e, em caso afirmativo, como fica!
A maneira mais direta e rápida de fazer isso é usar a API Elasticsearch HTTP. Primeiro, vamos verificar para onde o alias aponta:
$ curl -s localhost:9200/_cat/aliases
cards cards-2020-09-20-16-14-18 - - - -
Ótimo, o índice existe! Vamos olhar de perto:
$ curl -s localhost:9200/cards-2020-09-20-16-14-18 | jq
{
"cards-2020-09-20-16-14-18": {
"aliases": {
"cards": {}
},
"mappings": {
...
},
"settings": {
"index": {
"creation_date": "1600618458522",
"number_of_shards": "1",
"number_of_replicas": "1",
"uuid": "iLX7A8WZQuCkRSOd7mjgMg",
"version": {
"created": "7050199"
},
"provided_name": "cards-2020-09-20-16-14-18"
}
}
}
}
Finalmente, vamos dar uma olhada em seu conteúdo:
$ curl -s localhost:9200/cards-2020-09-20-16-14-18/_search | jq
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4704,
"relation": "eq"
},
"max_score": 1,
"hits": [
...
]
}
}
No total, nosso índice é de 4704 documentos, e no campo
hits(que ignorei porque é muito grande) você pode até ver o conteúdo de alguns deles. Sucesso!
Uma maneira mais conveniente de navegar pelo conteúdo do índice e, geralmente, todos os tipos de mimos com o Elasticsearch seria usar Kibana . Vamos adicionar o contêiner a
docker-compose.yml:
services:
...
kibana:
image: "kibana:7.5.1"
ports:
- "5601:5601"
depends_on:
- elasticsearch
...
Depois de uma segunda vez,
docker-compose uppodemos ir para Kibana no endereço localhost:5601(atenção, o servidor pode não iniciar rapidamente) e, após uma breve configuração, visualizar o conteúdo de nossos índices em uma interface web agradável.
Eu recomendo fortemente a guia Dev Tools - durante o desenvolvimento, você frequentemente precisará fazer certas consultas no Elasticsearch, e é muito mais conveniente no modo interativo com preenchimento e formatação automáticos.
Pesquisa
Depois de todos os preparativos incrivelmente entediantes, é hora de adicionarmos a funcionalidade de pesquisa ao nosso aplicativo da web!
Vamos dividir essa tarefa não trivial em três estágios e discutir cada um separadamente.
- Adicione um componente
Searcherresponsável pela lógica de pesquisa ao back-end . Ele formará uma consulta ao Elasticsearch e converterá os resultados em mais digeríveis para nosso back-end. - Adicione um endpoint à API (manipular / rotear / como você chama na sua empresa?) Que
/cards/searchrealiza a pesquisa. Ele chamará o método do componenteSearcher, processará os resultados e os retornará ao cliente. - Vamos implementar a interface de pesquisa no front-end. Ele entrará em contato
/cards/searchquando o usuário decidir o que deseja pesquisar e exibirá os resultados (e, possivelmente, alguns controles adicionais).
Pesquisa: nós implementamos
Não é tão difícil escrever um gerente de pesquisa quanto projetar um. Vamos descrever o resultado da pesquisa e a interface do gerenciador e discutir por que isso é diferente.
# backend/backend/search/searcher.py
import abc
from dataclasses import dataclass
from typing import Iterable, Optional
@dataclass
class CardSearchResult:
total_count: int
card_ids: Iterable[str]
next_card_offset: Optional[int]
class Searcher(metaclass=abc.ABCMeta):
@abc.abstractmethod
def search_cards(self, query: str = "",
count: int = 20, offset: int = 0) -> CardSearchResult:
pass
Algumas coisas são óbvias. Por exemplo, paginação. Somos uma startup ambiciosa e
Alguns são menos óbvios. Por exemplo, uma lista de IDs, não cartões como resultado. O Elasticsearch armazena todos os nossos documentos por padrão e os retorna nos resultados da pesquisa. Esse comportamento pode ser desativado para economizar no tamanho do índice de pesquisa, mas para nós esta é claramente uma otimização prematura. Então, por que não devolver os cartões imediatamente? Resposta: isso violaria o princípio da responsabilidade única. Talvez um dia acabemos com uma lógica complexa no gerenciador de cartões que traduz os cartões para outros idiomas, dependendo das configurações do usuário. Exatamente neste momento, os dados da página do cartão e os dados dos resultados da pesquisa ficarão dispersos, pois esqueceremos de adicionar a mesma lógica ao gestor de pesquisa. E assim por diante.
A implementação dessa interface é tão simples que tive preguiça de escrever esta seção :-(
# backend/backend/search/searcher_impl.py
from typing import Any
from elasticsearch import Elasticsearch
from backend.search.searcher import CardSearchResult, Searcher
ElasticsearchQuery = Any #
class ElasticsearchSearcher(Searcher):
def __init__(self, elasticsearch_client: Elasticsearch, cards_index_name: str):
self.elasticsearch_client = elasticsearch_client
self.cards_index_name = cards_index_name
def search_cards(self, query: str = "", count: int = 20, offset: int = 0) -> CardSearchResult:
result = self.elasticsearch_client.search(index=self.cards_index_name, body={
"size": count,
"from": offset,
"query": self._make_text_query(query) if query else self._match_all_query
})
total_count = result["hits"]["total"]["value"]
return CardSearchResult(
total_count=total_count,
card_ids=[hit["_id"] for hit in result["hits"]["hits"]],
next_card_offset=offset + count if offset + count < total_count else None,
)
def _make_text_query(self, query: str) -> ElasticsearchQuery:
return {
# Multi-match query
# ( match
# query, ).
"multi_match": {
"query": query,
# ^ – .
# , .
"fields": ["name^3", "tags.text", "text"],
}
}
_match_all_query: ElasticsearchQuery = {"match_all": {}}
Na verdade, vamos apenas para a API Elasticsearch e extraímos cuidadosamente os IDs dos cartões encontrados do resultado.
A implementação do endpoint também é bastante trivial:
# backend/backend/server.py
...
def search_cards(self):
request = flask.request.json
search_result = self.wiring.searcher.search_cards(**request)
cards = self.wiring.card_dao.get_by_ids(search_result.card_ids)
return flask.jsonify({
"totalCount": search_result.total_count,
"cards": [
{
"id": card.id,
"slug": card.slug,
"name": card.name,
# ,
# ,
# .
} for card in cards
],
"nextCardOffset": search_result.next_card_offset,
})
...
A implementação do front-end usando este endpoint, embora volumosa, é geralmente bastante direta e não quero me concentrar nisso neste artigo. Todo o código pode ser visto neste commit .

Até aí tudo bem, vamos seguir em frente.
 Pesquisa: adicionando filtros
Pesquisa: adicionando filtros
A pesquisa de texto é legal, mas se você já pesquisou um recurso sério, provavelmente viu todos os tipos de coisas boas, como filtros.
Nossas descrições de filmes do banco de dados TMDB 5000 têm tags, além de títulos e descrições, então vamos implementar filtros por tags para treinamento. Nosso objetivo está na captura de tela: ao clicar em uma tag, apenas os filmes com essa tag devem permanecer nos resultados da pesquisa (seu número está indicado entre parênteses ao lado).

Para implementar filtros, precisamos resolver dois problemas.
- Aprenda a entender, mediante solicitação, qual conjunto de filtros está disponível. Não queremos mostrar todos os valores de filtro possíveis em todas as telas, porque existem muitos deles e a maioria deles levará a um resultado vazio; você precisa entender quais marcas os documentos encontrados por solicitação possuem e, de preferência, deixar o N mais popular.
- Aprender, de fato, a aplicar um filtro - a deixar nos resultados da pesquisa apenas documentos com marcas, o filtro pelo qual o usuário escolheu.
O segundo no Elasticsearch é simplesmente implementado por meio da API de consulta (consulte os termos de consulta ), o primeiro é por meio de um mecanismo de agregação um pouco menos trivial .
Portanto, precisamos saber quais tags são encontradas nos cartões encontrados e ser capazes de filtrar os cartões com as tags necessárias. Primeiro, vamos atualizar o design do gerenciador de pesquisa:
# backend/backend/search/searcher.py
import abc
from dataclasses import dataclass
from typing import Iterable, Optional
@dataclass
class TagStats:
tag: str
cards_count: int
@dataclass
class CardSearchResult:
total_count: int
card_ids: Iterable[str]
next_card_offset: Optional[int]
tag_stats: Iterable[TagStats]
class Searcher(metaclass=abc.ABCMeta):
@abc.abstractmethod
def search_cards(self, query: str = "",
count: int = 20, offset: int = 0,
tags: Optional[Iterable[str]] = None) -> CardSearchResult:
pass
Agora vamos prosseguir para a implementação. A primeira coisa que precisamos fazer é iniciar uma agregação pelo campo
tags:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -10,6 +10,8 @@ ElasticsearchQuery = Any
class ElasticsearchSearcher(Searcher):
+ TAGS_AGGREGATION_NAME = "tags_aggregation"
+
def __init__(self, elasticsearch_client: Elasticsearch, cards_index_name: str):
self.elasticsearch_client = elasticsearch_client
self.cards_index_name = cards_index_name
@@ -18,7 +20,12 @@ class ElasticsearchSearcher(Searcher):
result = self.elasticsearch_client.search(index=self.cards_index_name, body={
"size": count,
"from": offset,
"query": self._make_text_query(query) if query else self._match_all_query,
+ "aggregations": {
+ self.TAGS_AGGREGATION_NAME: {
+ "terms": {"field": "tags"}
+ }
+ }
})
Agora, no resultado da pesquisa do Elasticsearch, virá um campo
aggregationsdo qual, usando uma chave, TAGS_AGGREGATION_NAMEpodemos obter baldes contendo informações sobre quais valores estão no campo tagspara os documentos encontrados e com que frequência eles ocorrem. Vamos extrair esses dados e retorná-los conforme projetado acima:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -28,10 +28,15 @@ class ElasticsearchSearcher(Searcher):
total_count = result["hits"]["total"]["value"]
+ tag_stats = [
+ TagStats(tag=bucket["key"], cards_count=bucket["doc_count"])
+ for bucket in result["aggregations"][self.TAGS_AGGREGATION_NAME]["buckets"]
+ ]
return CardSearchResult(
total_count=total_count,
card_ids=[hit["_id"] for hit in result["hits"]["hits"]],
next_card_offset=offset + count if offset + count < total_count else None,
+ tag_stats=tag_stats,
)
Adicionar um aplicativo de filtro é a parte mais fácil:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -16,11 +16,17 @@ class ElasticsearchSearcher(Searcher):
self.elasticsearch_client = elasticsearch_client
self.cards_index_name = cards_index_name
- def search_cards(self, query: str = "", count: int = 20, offset: int = 0) -> CardSearchResult:
+ def search_cards(self, query: str = "", count: int = 20, offset: int = 0,
+ tags: Optional[Iterable[str]] = None) -> CardSearchResult:
result = self.elasticsearch_client.search(index=self.cards_index_name, body={
"size": count,
"from": offset,
- "query": self._make_text_query(query) if query else self._match_all_query,
+ "query": {
+ "bool": {
+ "must": self._make_text_queries(query),
+ "filter": self._make_filter_queries(tags),
+ }
+ },
"aggregations": {
As subconsultas incluídas na cláusula obrigatória são obrigatórias, mas também serão consideradas no cálculo da velocidade dos documentos e, consequentemente, da classificação; se alguma vez adicionarmos mais condições aos textos, é melhor adicioná-los aqui. As subconsultas na cláusula de filtro apenas filtram sem afetar a velocidade e a classificação.
Resta implementar
_make_filter_queries():
def _make_filter_queries(self, tags: Optional[Iterable[str]] = None) -> List[ElasticsearchQuery]:
return [] if tags is None else [{
"term": {
"tags": {
"value": tag
}
}
} for tag in tags]
Novamente, não vou me alongar na parte do front-end; todo o código está neste commit .
Ranging
Assim, nossa busca procura por cartões, os filtra de acordo com uma determinada lista de tags e os exibe em alguma ordem. Mas qual deles? A ordem é muito importante para uma pesquisa prática, mas tudo o que fizemos durante nosso litígio em termos de ordem foi sugerido ao Elasticsearch que encontrar palavras no título do cartão é mais lucrativo do que na descrição ou nas tags, especificando a prioridade
^3na consulta de múltiplas correspondências.
Apesar do fato de que, por padrão, o Elasticsearch classifica os documentos com uma fórmula bastante complicada baseada em TF-IDF, para nossa startup ambiciosa imaginária, isso dificilmente é suficiente. Se nossos documentos forem mercadorias, precisamos ser capazes de prestar contas de suas vendas; se for conteúdo gerado pelo usuário, leve em consideração sua atualização e assim por diante. Mas não podemos simplesmente classificar pelo número de vendas / data de adição, porque assim não levaremos em consideração a relevância para a consulta de pesquisa.
A classificação é um domínio grande e confuso de tecnologia que não pode ser abordado em uma seção no final deste artigo. Portanto, aqui estou mudando para golpes grandes; Tentarei dizer em termos mais gerais como a classificação de grau industrial pode ser organizada na pesquisa e revelarei alguns detalhes técnicos de como ela pode ser implementada com o Elasticsearch.
A tarefa de classificação é muito complexa, por isso não é surpreendente que um dos principais métodos modernos de resolvê-la seja o aprendizado de máquina. A aplicação de tecnologias de aprendizado de máquina à classificação é chamada coletivamente de aprender a classificar .
Um processo típico se parece com isso.
Nós decidimos o que queremos classificar . Colocamos as entidades nas quais estamos interessados no índice, aprendemos como obter algum topo razoável (por exemplo, alguma classificação e corte simples) dessas entidades para uma determinada consulta de pesquisa e agora queremos aprender como classificá-la de uma forma mais inteligente.
Determinando como queremos classificar... Decidimos quais são as características que precisamos para classificar nossos resultados de acordo com os objetivos de negócios de nosso serviço. Por exemplo, se nossas entidades são produtos que vendemos, podemos classificá-los em ordem decrescente de probabilidade de compra; se memes - pela probabilidade de gostar ou compartilhar, e assim por diante. É claro que não sabemos como calcular essas probabilidades - na melhor das hipóteses podemos estimar, e mesmo assim apenas para entidades antigas para as quais temos estatísticas suficientes -, mas tentaremos ensinar o modelo a predizê-las com base em sinais indiretos.
Extraindo signos... Criamos um conjunto de recursos para nossas entidades que podem nos ajudar a avaliar a relevância das entidades para consultas de pesquisa. Além do mesmo TF-IDF, que já sabe calcular Elasticsearch para nós, um exemplo típico é a CTR (click-through rate): pegamos os logs do nosso serviço durante todo o tempo, para cada par de entidade + consulta de pesquisa contamos quantas vezes a entidade apareceu nos resultados da pesquisa para esta solicitação e quantas vezes ela foi clicada, dividimos uma pela outra, et voilà - a estimativa mais simples da probabilidade de clique condicional está pronta. Também podemos criar características específicas do usuário e características emparelhadas entre usuário e entidade para personalizar as classificações. Tendo surgido com os sinais, escrevemos um código que os calcula, os coloca em algum tipo de armazenamento e sabe como fornecê-los em tempo real para uma determinada consulta de pesquisa, usuário e um conjunto de entidades.
Reunir um conjunto de dados de treinamento . As opções são muitas, mas todas elas, via de regra, são formadas a partir dos registros de eventos "bons" (por exemplo, um clique e depois uma compra) e "ruins" (por exemplo, um clique e retorno à emissão) em nosso serviço. Quando montamos um conjunto de dados, seja uma lista de declarações "a avaliação da relevância do produto X para a consulta Q é aproximadamente igual a P", uma lista de pares "o produto X é mais relevante para o produto Y para a consulta Q" ou um conjunto de listas "para a consulta Q, produtos P 1 , P 2 , ... corretamente classificados como este -que ", ajustamos os sinais correspondentes a todas as linhas que aparecem nele.
Treinamos o modelo . Aqui estão todos os clássicos do ML: treinar / testar, hiperparâmetros, retreinamento,
Incorporamos o modelo . Resta-nos estragar de alguma forma o cálculo do modelo em tempo real para todo o topo, para que os resultados já classificados cheguem ao usuário. Existem muitas opções; para fins ilustrativos, irei (novamente) focar em um plug-in Elasticsearch simples, Learning to Rank .
Classificação: Elasticsearch Learning to Rank Plugin
Elasticsearch Learning to Rank é um plugin que adiciona ao Elasticsearch a habilidade de calcular o modelo ML no SERP e imediatamente classificar os resultados de acordo com as taxas de pontuação calculadas. Também nos ajudará a obter recursos idênticos aos usados em tempo real, ao mesmo tempo que reutiliza os recursos do Elasticsearch (TF-IDF e similares).
Primeiro, precisamos conectar o plugin em nosso contêiner com Elasticsearch. Precisamos de um Dockerfile simples
# elasticsearch/Dockerfile
FROM elasticsearch:7.5.1
RUN ./bin/elasticsearch-plugin install --batch http://es-learn-to-rank.labs.o19s.com/ltr-1.1.2-es7.5.1.zip
e alterações relacionadas a
docker-compose.yml:
--- a/docker-compose.yml
+++ b/docker-compose.yml
@@ -5,7 +5,8 @@ services:
elasticsearch:
- image: "elasticsearch:7.5.1"
+ build:
+ context: elasticsearch
environment:
- discovery.type=single-node
Também precisamos de suporte a plugins no cliente Python. Com espanto, descobri que o suporte para Python não chega completo com o plug-in, então, especialmente para este artigo, eu o limpei . Adicionar
elasticsearch_ltrpara requirements.txte atualizar o cliente na fiação:
--- a/backend/backend/wiring.py
+++ b/backend/backend/wiring.py
@@ -1,5 +1,6 @@
import os
+from elasticsearch_ltr import LTRClient
from celery import Celery
from elasticsearch import Elasticsearch
from pymongo import MongoClient
@@ -39,5 +40,6 @@ class Wiring(object):
self.task_manager = TaskManager(self.celery_app)
self.elasticsearch_client = Elasticsearch(hosts=self.settings.ELASTICSEARCH_HOSTS)
+ LTRClient.infect_client(self.elasticsearch_client)
self.indexer = Indexer(self.elasticsearch_client, self.card_dao, self.settings.CARDS_INDEX_ALIAS)
self.searcher: Searcher = ElasticsearchSearcher(self.elasticsearch_client, self.settings.CARDS_INDEX_ALIAS)
Classificação: placas de serrar
Cada solicitação no Elasticsearch retorna não apenas uma lista de IDs de documentos que foram encontrados, mas também alguns deles em breve (como você traduziria a palavra pontuação para o russo?). Portanto, se esta é uma consulta de correspondência ou multicamadas que estamos usando, rápido é o resultado do cálculo daquela fórmula muito complicada envolvendo TF-IDF; se a consulta bool é uma combinação de taxas de consulta aninhadas; se consulta de pontuação de função- o resultado do cálculo de uma determinada função (por exemplo, o valor de algum campo numérico em um documento) e assim por diante. O plug-in ELTR nos fornece a capacidade de usar a velocidade de qualquer solicitação como um sinal, permitindo-nos facilmente combinar dados sobre o quão bem o documento corresponde à solicitação (por meio de consulta de correspondência múltipla) e algumas estatísticas pré-calculadas que colocamos no documento com antecedência (por meio da consulta de pontuação de função) ...
Como temos um banco de dados TMDB 5000 em mãos, que contém descrições de filmes e, entre outras coisas, suas classificações, vamos tomar a classificação como um recurso pré-calculado exemplar.
No presente cometerEu adicionei alguma infraestrutura básica para armazenar recursos no back-end de nosso aplicativo da web e suporte para carregar a classificação do arquivo do filme. Para não forçá-lo a ler outro monte de código, descreverei o mais básico.
- Armazenaremos os recursos em uma coleção separada e os obteremos por um gerenciador separado. Despejar todos os dados em uma entidade é uma prática ruim.
- Entraremos em contato com este gerente na fase de indexação e colocaremos todos os sinais disponíveis nos documentos indexados.
- Para conhecer o esquema do índice, precisamos saber a lista de todos os recursos existentes antes de iniciar a construção do índice. Vamos codificar esta lista por enquanto.
- Como não vamos filtrar documentos por valores de atributos, mas apenas extraí-los de documentos já encontrados para cálculo do modelo, vamos desligar a construção de índices inversos por novos campos com uma opção
index: falseno esquema e economizar um pouco de espaço por conta disso.
Classificação: coleta do conjunto de dados
Como, em primeiro lugar, não temos produção e, em segundo lugar, as margens deste artigo são muito pequenas para falar sobre telemetria, Kafka, NiFi, Hadoop, Spark e processos de ETL de construção, irei apenas gerar visualizações aleatórias e cliques para nossos cartões e algum tipo de consulta de pesquisa. Depois disso, você precisará calcular as características dos pares de solicitação de cartão resultantes.
É hora de se aprofundar na API do plugin ELTR. Para calcular os recursos, precisaremos criar uma entidade de armazenamento de recursos (até onde eu entendo, isso é na verdade apenas um índice no Elasticsearch no qual o plug-in armazena todos os seus dados) e, em seguida, criar um conjunto de recursos - uma lista de recursos com uma descrição de como calcular cada um deles. Depois disso, será o suficiente para irmos ao Elasticsearch com um pedido especial para obter um vetor de valores de recurso para cada entidade encontrada como resultado.
Vamos começar criando um conjunto de recursos:
# backend/backend/search/ranking.py
from typing import Iterable, List, Mapping
from elasticsearch import Elasticsearch
from elasticsearch_ltr import LTRClient
from backend.search.features import CardFeaturesManager
class SearchRankingManager:
DEFAULT_FEATURE_SET_NAME = "card_features"
def __init__(self, elasticsearch_client: Elasticsearch,
card_features_manager: CardFeaturesManager,
cards_index_name: str):
self.elasticsearch_client = elasticsearch_client
self.card_features_manager = card_features_manager
self.cards_index_name = cards_index_name
def initialize_ranking(self, feature_set_name=DEFAULT_FEATURE_SET_NAME):
ltr: LTRClient = self.elasticsearch_client.ltr
try:
# feature store ,
# ¯\_(ツ)_/¯
ltr.create_feature_store()
except Exception as exc:
if "resource_already_exists_exception" not in str(exc):
raise
# feature set !
ltr.create_feature_set(feature_set_name, {
"featureset": {
"features": [
#
# ,
# ,
# .
self._make_feature("name_tf_idf", ["query"], {
"match": {
# ELTR
# , .
# , ,
# ,
# match query.
"name": "{{query}}"
}
}),
# , .
self._make_feature("combined_tf_idf", ["query"], {
"multi_match": {
"query": "{{query}}",
"fields": ["name^3", "tags.text", "text"]
}
}),
*(
#
# function score.
# -
# , 0.
# (
# !)
self._make_feature(feature_name, [], {
"function_score": {
"field_value_factor": {
"field": feature_name,
"missing": 0
}
}
})
for feature_name in sorted(self.card_features_manager.get_all_feature_names_set())
)
]
}
})
@staticmethod
def _make_feature(name, params, query):
return {
"name": name,
"params": params,
"template_language": "mustache",
"template": query,
}
Now - uma função que calcula recursos para uma determinada consulta e cartões:
def compute_cards_features(self, query: str, card_ids: Iterable[str],
feature_set_name=DEFAULT_FEATURE_SET_NAME) -> Mapping[str, List[float]]:
card_ids = list(card_ids)
result = self.elasticsearch_client.search({
"query": {
"bool": {
# ,
# — ,
# .
# ID.
"filter": [
{
"terms": {
"_id": card_ids
}
},
# — ,
# SLTR.
#
# feature set.
# ( ,
# filter, .)
{
"sltr": {
"_name": "logged_featureset",
"featureset": feature_set_name,
"params": {
# .
# , ,
#
# {{query}}.
"query": query
}
}
}
]
}
},
#
# .
"ext": {
"ltr_log": {
"log_specs": {
"name": "log_entry1",
"named_query": "logged_featureset"
}
}
},
"size": len(card_ids),
})
# (
# ) .
# ( ,
# , Kibana.)
return {
hit["_id"]: [feature.get("value", float("nan")) for feature in hit["fields"]["_ltrlog"][0]["log_entry1"]]
for hit in result["hits"]["hits"]
}
Um script simples que aceita CSV com solicitações e cartões de identificação como entrada e produz CSV com os seguintes recursos:
# backend/tools/compute_movie_features.py
import csv
import itertools
import sys
import tqdm
from backend.wiring import Wiring
if __name__ == "__main__":
wiring = Wiring()
reader = iter(csv.reader(sys.stdin))
header = next(reader)
feature_names = wiring.search_ranking_manager.get_feature_names()
writer = csv.writer(sys.stdout)
writer.writerow(["query", "card_id"] + feature_names)
query_index = header.index("query")
card_id_index = header.index("card_id")
chunks = itertools.groupby(reader, lambda row: row[query_index])
for query, rows in tqdm.tqdm(chunks):
card_ids = [row[card_id_index] for row in rows]
features = wiring.search_ranking_manager.compute_cards_features(query, card_ids)
for card_id in card_ids:
writer.writerow((query, card_id, *features[card_id]))
Finalmente, você pode executar tudo!
# feature set
docker-compose exec backend python -m tools.initialize_search_ranking
#
docker-compose exec -T backend \
python -m tools.generate_movie_events \
< ~/Downloads/tmdb-movie-metadata/tmdb_5000_movies.csv \
> ~/Downloads/habr-app-demo-dataset-events.csv
#
docker-compose exec -T backend \
python -m tools.compute_features \
< ~/Downloads/habr-app-demo-dataset-events.csv \
> ~/Downloads/habr-app-demo-dataset-features.csv
Agora temos dois arquivos - com eventos e sinais - e podemos iniciar o treinamento.
Classificação: treinar e implementar o modelo
Vamos pular os detalhes do carregamento de conjuntos de dados (você pode ver o script completo neste commit ) e ir direto ao ponto.
# backend/tools/train_model.py
...
if __name__ == "__main__":
args = parser.parse_args()
feature_names, features = read_features(args.features)
events = read_events(args.events)
# train test 4 1.
all_queries = set(events.keys())
train_queries = random.sample(all_queries, int(0.8 * len(all_queries)))
test_queries = all_queries - set(train_queries)
# DMatrix — , xgboost.
#
# . 1, ,
# 0, ( . ).
train_dmatrix = make_dmatrix(train_queries, events, feature_names, features)
test_dmatrix = make_dmatrix(test_queries, events, feature_names, features)
# !
#
# ML,
# XGBoost.
param = {
"max_depth": 2,
"eta": 0.3,
"objective": "binary:logistic",
"eval_metric": "auc",
}
num_round = 10
booster = xgboost.train(param, train_dmatrix, num_round, evals=((train_dmatrix, "train"), (test_dmatrix, "test")))
# .
booster.dump_model(args.output, dump_format="json")
# , :
# ROC-.
xgboost.plot_importance(booster)
plt.figure()
build_roc(test_dmatrix.get_label(), booster.predict(test_dmatrix))
plt.show()
Lançamento
python backend/tools/train_search_ranking_model.py \
--events ~/Downloads/habr-app-demo-dataset-events.csv \
--features ~/Downloads/habr-app-demo-dataset-features.csv \
-o ~/Downloads/habr-app-demo-model.xgb
Observe que, como exportamos todos os dados necessários com os scripts anteriores, este script não precisa mais ser executado dentro do docker - ele precisa ser executado em sua máquina, tendo instalado
xgbooste sklearn. Da mesma forma, na produção real, os scripts anteriores teriam que ser executados em algum lugar onde houvesse acesso ao ambiente de produção, mas este não é.
Se tudo for feito corretamente, o modelo vai treinar com sucesso e veremos duas lindas fotos. O primeiro é um gráfico da importância dos recursos:

embora os eventos tenham sido gerados aleatoriamente,
combined_tf_idfacabou sendo muito mais significativo do que outros - porque eu fiz um truque e diminuí artificialmente a probabilidade de um clique para cartas que são mais baixas na SERP, classificadas à nossa maneira antiga. O fato de a modelo perceber isso é um bom sinal e um sinal de que não cometemos erros totalmente estúpidos no processo de aprendizagem.
O segundo gráfico é a curva ROC : a

linha azul está acima da linha vermelha, o que significa que nosso modelo prevê rótulos um pouco melhor do que o cara ou coroa. (A curva do engenheiro de ML da amiga da mamãe deve quase tocar o canto superior esquerdo.)
A questão é muito pequena - adicionamos um script para preencher o modelo , o preenchemos e adicionamos um pequeno novo item à consulta de pesquisa - redefinindo:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -27,6 +30,19 @@ class ElasticsearchSearcher(Searcher):
"filter": list(self._make_filter_queries(tags, ids)),
}
},
+ "rescore": {
+ "window_size": 1000,
+ "query": {
+ "rescore_query": {
+ "sltr": {
+ "params": {
+ "query": query
+ },
+ "model": self.ranking_manager.get_current_model_name()
+ }
+ }
+ }
+ },
"aggregations": {
self.TAGS_AGGREGATION_NAME: {
"terms": {"field": "tags"}
Agora, depois que o Elasticsearch realizar a pesquisa de que precisamos e classificar os resultados com seu algoritmo (bastante rápido), pegaremos os 1000 resultados principais e os re-classificaremos usando nossa fórmula aprendida por máquina (relativamente lenta). Sucesso!
Conclusão
Pegamos nosso aplicativo da web minimalista e passamos de nenhum recurso de pesquisa per se a uma solução escalável com muitos recursos avançados. Isso não foi tão fácil de fazer. Mas também não é tão difícil! O aplicativo final encontra-se no repositório do Github em um branch com um nome modesto
feature/searche requer Docker e Python 3 com bibliotecas de aprendizado de máquina para ser executado.
Usei o Elasticsearch para mostrar como isso funciona em geral, quais problemas são encontrados e como podem ser resolvidos, mas essa certamente não é a única ferramenta para escolher. Solr , índices de texto completo PostgreSQL e outros mecanismos também merecem sua atenção ao escolher sobre o que construir sua
E, claro, esta solução não pretende estar completa e pronta para produção, mas é puramente uma ilustração de como tudo pode ser feito. Você pode melhorá-lo quase infinitamente!
- Indexação incremental. Ao modificar nossos cartões por meio
CardManager, seria bom atualizá-los imediatamente no índice. ParaCardManagernão sabermos que também temos uma busca no serviço, e para prescindir de dependências cíclicas, teremos que parafusar a inversão de dependências de uma forma ou de outra. - Para indexar em nosso caso específico, os pacotes do MongoDB com o Elasticsearch, você pode usar soluções prontas como o conector mongo .
- , — Elasticsearch .
- , , .
- , , . -, -, - … !
- ( , ), ( ). , .
- , , .
- Orquestrar um cluster de nós com fragmentação e replicação é um prazer totalmente separado.
Mas para manter o artigo legível em tamanho, vou parar por aí e deixá-lo sozinho com esses desafios. Obrigado pela atenção!