Prolog
Vamos começar com a programação lógica e a linguagem Prolog. O conhecimento sobre a área temática é nele apresentado como um conjunto de fatos e regras. Os fatos descrevem o conhecimento imediato. Os fatos sobre clientes (ID, nome e endereço de e-mail) e faturas (ID da conta, cliente, data, valor devido e valor pago) do exemplo da postagem anterior seriam semelhantes a este
client(1, "John", "john@somewhere.net").
bill(1, 1,"2020-01", 100, 50).As regras descrevem o conhecimento abstrato que pode ser derivado de outras regras e fatos. A regra consiste em uma cabeça e um corpo. No cabeçalho da regra, você precisa especificar seu nome e uma lista de argumentos. O corpo de uma regra é uma lista de predicados conectados por operações lógicas AND (especificado por uma vírgula) e OR (especificado por um ponto e vírgula). Os predicados podem ser fatos, regras ou predicados embutidos, como operações de comparação, operações aritméticas, etc. A relação entre os argumentos da cabeça da regra e os argumentos dos predicados em seu corpo é definida usando variáveis booleanas - se a mesma variável estiver nas posições de dois argumentos diferentes, Isso significa que esses argumentos são idênticos. Uma regra é considerada verdadeira quando a expressão lógica do corpo da regra é verdadeira. O modelo de domínio pode ser definido como um conjunto de regras de referência:
unpaidBill(BillId, ClientId, Date, AmoutToPay, AmountPaid) :- bill(BillId, ClientId, Date, AmoutToPay, AmountPaid), AmoutToPay < AmountPaid.
debtor(ClientId, Name, Email) :- client(ClientId, Name, Email), unpaidBill(BillId, ClientId, _, _, _).Estabelecemos duas regras. Na primeira, afirmamos que todas as faturas com valor inferior ao devido são faturas não pagas. Na segunda, o devedor é um cliente que possui pelo menos uma fatura não paga.
A sintaxe do Prolog é muito simples: o elemento principal do programa é a regra, os principais elementos da regra são predicados, operações lógicas e variáveis. Na regra, a atenção está voltada para as variáveis - elas desempenham o papel de um objeto do mundo modelado e os predicados descrevem suas propriedades e relacionamentos entre elas. Na definição da regra do devedor, afirmamos que se os objetos ClientId, Nome e Email forem relacionados por um cliente e uma relação de fatura não paga, eles também serão relacionados por uma relação de devedor. Prolog é útil quando um problema é formulado como um conjunto de regras, declarações ou declarações lógicas. Por exemplo, ao trabalhar com gramática de linguagem natural, compiladores, em sistemas especialistas, ao analisar sistemas complexos como computadores, redes de computadores, objetos de infraestrutura. Complexo,sistemas de regras complicados são melhor descritos explicitamente e deixados para o tempo de execução do Prolog para lidar com eles automaticamente.
Prolog é baseado na lógica de primeira ordem (com alguns elementos de lógica de ordem superior incluídos). A inferência é feita através de um procedimento denominado resolução SLD (resolução seletiva linear definida de cláusula). Simplificado, seu algoritmo é uma travessia em árvore de todas as soluções possíveis. O procedimento de inferência encontra todas as soluções para o primeiro predicado do corpo da regra. Se o predicado atual na base de conhecimento é representado apenas por fatos, as soluções são aquelas que correspondem às ligações atuais de variáveis a valores. Se por regras, a verificação recursiva de seus predicados aninhados é necessária. Se nenhuma solução for encontrada, o ramo de pesquisa atual falhará. Uma nova ramificação é então criada para cada solução parcial encontrada. Em cada ramo, o procedimento de inferência vincula os valores encontrados a variáveis,incluído no predicado atual e procura recursivamente por uma solução para a lista restante de predicados. O trabalho termina quando o fim da lista de predicados é alcançado. A busca por uma solução pode entrar em um loop infinito no caso de definição recursiva de regras. O resultado do procedimento de pesquisa é uma lista de todas as ligações possíveis de valores para variáveis booleanas.
No exemplo acima para a regra do devedor, a regra de resolução primeiro encontrará uma solução para o predicado do cliente e a vinculará aos booleanos: ClientId = 1, Name = "John", Email = "john@somewhere.net". Então, para esta variante de valores variáveis, uma solução será executada para o próximo predicado unpaidBill. Para fazer isso, primeiro você precisa encontrar soluções para o predicado bill, desde que ClientId = 1. O resultado serão ligações para as variáveis BillId = 1, Date = "2020-01", AmoutToPay = 100, AmountPaid = 50. No final, AmoutToPay <AmountPaid será verificado no predicado de comparação embutido.
Redes semânticas
As redes semânticas são uma das formas mais populares de representar o conhecimento. A Web Semântica é um modelo de informação de uma área temática na forma de um gráfico direcionado. Os vértices do gráfico correspondem aos conceitos do domínio, e os arcos definem as relações entre eles.
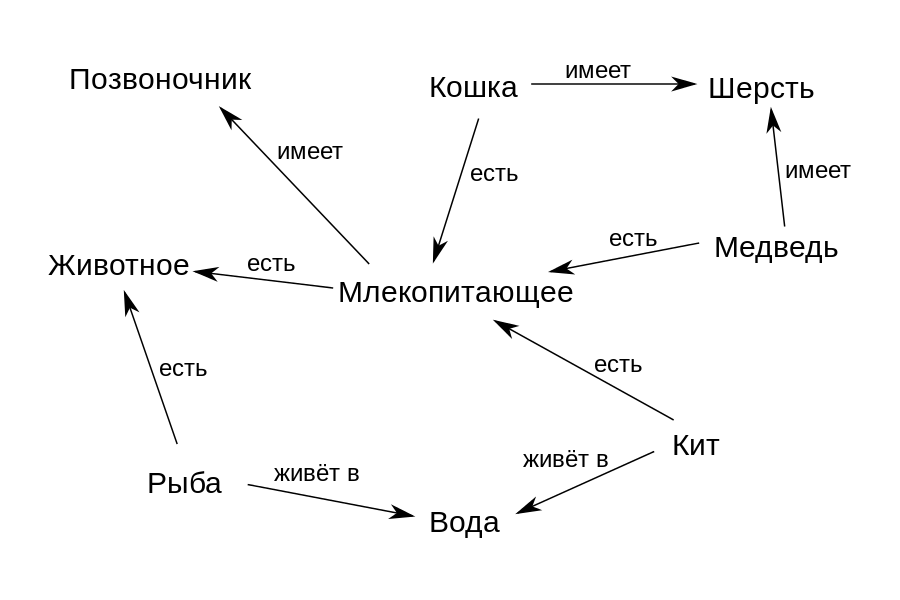
Por exemplo, de acordo com o gráfico da figura acima, o conceito de "Baleia" está associado à relação "é" ("é") com o conceito de "Mamífero" e "vive em" com o conceito de "Água". Assim, podemos definir formalmente a estrutura da área disciplinar - quais conceitos ela inclui e como eles se relacionam entre si. E então esse gráfico pode ser usado para encontrar respostas para perguntas e derivar novos conhecimentos a partir dele. Por exemplo, podemos deduzir o conhecimento de que "Baleia" "tem" "Espinha" se decidirmos que a relação "é" denota uma relação classe-subclasse, e a subclasse "Baleia" deve herdar todas as propriedades de sua classe "Mamífero".
RDF
A web semântica é uma tentativa de construir uma rede semântica global baseada nos recursos da World Wide Web, padronizando a apresentação de informações em uma forma adequada para processamento por máquina. Para isso, a informação é adicionalmente incorporada em páginas HTML na forma de atributos especiais de tags HTML, o que permite descrever o significado de seu conteúdo na forma de uma ontologia - um conjunto de fatos, conceitos abstratos e relações entre eles.
A abordagem padrão para descrever o modelo semântico de recursos da WEB é RDF (Resource Description Framework ou Resource Description Framework). De acordo com ele, todas as declarações devem ter a forma de um trio "sujeito - predicado - objeto". Por exemplo, o conhecimento sobre o conceito de “Baleia” será apresentado da seguinte forma: “Baleia” é um sujeito, “vive em” - um predicado, “Água” - um objeto. Todo o conjunto de tais declarações pode ser descrito usando um gráfico direcionado, sujeitos e objetos são seus vértices, e predicados são arcos, arcos de predicados são direcionados de objetos a sujeitos. Por exemplo, a ontologia do exemplo animal pode ser descrita da seguinte forma:
@prefix : <...some URL...>
@prefix rdf: <http://www.w3.org/1999/02/rdf-schema#>
@prefix rdfs: <http://www.w3.org/2000/01/22-rdf-syntax-ns#>
:Whale rdf:type :Mammal;
:livesIn :Water.
:Fish rdf:type :Animal;
:livesIn :Water.Essa notação é chamada de tartaruga e deve ser legível por humanos. Mas o mesmo pode ser escrito nos formatos XML, JSON ou usando tags e atributos de um documento HTML. Embora na notação de tartaruga predicados e objetos possam ser agrupados por assunto para facilitar a leitura, no nível semântico cada trinca é independente.
RDF é útil nos casos em que o modelo de dados é complexo e contém um grande número de tipos de objetos e relacionamentos entre eles. Por exemplo, a Wikipedia fornece acesso ao conteúdo de seus artigos em formato RDF. Os fatos descritos nos artigos são estruturados, suas propriedades e relações são descritas, incluindo fatos de outros artigos.
RDFS
Um modelo RDF é um gráfico; por padrão, nenhuma semântica adicional é incluída nele. Todos podem interpretar os links no gráfico como acharem adequado. Você pode adicionar alguns links padrão a ele usando o RDF Schema - um conjunto de classes e propriedades para construir ontologias em cima do RDF. O RDFS permite que você descreva relacionamentos padrão entre conceitos, como a pertença de um recurso a uma determinada classe, a hierarquia entre classes, a hierarquia de propriedades e restringir os possíveis tipos de assunto e objeto.
Por exemplo, a declaração
:Mammal rdfs:subClassOf :Animal.especifica que "Mamífero" é uma subclasse do conceito "Animal" e herda todas as suas propriedades. Nesse sentido, o conceito de “Baleia” também pode ser atribuído à classe “Animal”. Mas para isso é necessário apontar que os conceitos "Mamífero" e "Animal" são classes:
:Animal rdf:type rdfs:Class.
:Mammal rdf:type rdfs:Class.Além disso, o predicado pode ser definido como restrições aos valores possíveis de seu sujeito e objeto.
Declaração
:livesIn rdfs:range :Environment.indica que o objeto da relação "vive em" deve ser sempre um recurso pertencente à classe "Ambiente". Portanto, devemos acrescentar uma afirmação de que o conceito de "Água" é uma subclasse do conceito de "Ambiente":
:Water rdf:type :Environment.
:Environment rdf:type rdfs:ClassO RDFS permite que você descreva o esquema de dados - para enumerar classes, propriedades, definir sua hierarquia e restrições sobre seus valores. E RDF é preencher esse esquema com fatos concretos e definir a relação entre eles. Agora podemos fazer uma pergunta sobre este gráfico. Isso pode ser feito em uma linguagem de consulta especial SPARQL, que se assemelha a SQL:
SELECT ?creature
WHERE {
?creature rdf:type :Animal;
:livesIn :Water.
} Esta consulta nos retornará 2 valores: "Baleia" e "Peixe".
Um exemplo de publicações anteriores com contas e clientes pode ser implementado aproximadamente como segue. Com RDF, você pode descrever um esquema de dados e preenchê-lo com valores:
:Client1 :name "John";
:email "john@somewhere.net".
:Client2 :name "Mary";
:email "mary@somewhere.net".
:Bill_1 :client :Client1;
:date "2020-01";
:amountToPay 100;
:amountPaid 50.
:Bill_2 :client :Client2;
:date "2020-01";
:amountToPay 80;
:amountPaid 80.Mas conceitos abstratos como "Devedor" e "Contas não pagas" do primeiro artigo desta série incluem operações aritméticas e comparação. Eles não se encaixam na estrutura estática da rede semântica de conceitos. Esses conceitos podem ser expressos usando consultas SPARQL:
SELECT ?clientName ?clientEmail ?billDate ?amountToPay ?amountPaid
WHERE {
?client :name ?clientName;
:email ?clientEmail.
?bill :client ?client;
:date ?billDate;
:amountToPay ?amountToPay;
:amountPaid ?amountPaid.
FILTER(?amountToPay > ?amountPaid).
}A cláusula WHERE é uma lista de padrões triplos e condições de filtro. As variáveis booleanas podem ser substituídas em tercinas, cujo nome começa com "?" A tarefa do executor da consulta é encontrar todos os valores possíveis das variáveis para as quais todos os padrões triplos estariam contidos no gráfico e as condições de filtragem seriam satisfeitas.
Ao contrário do Prolog, onde as regras podem ser usadas para construir outras regras, no RDF uma consulta não faz parte da Web Semântica. Uma solicitação não pode ser referenciada como uma fonte de dados para outra solicitação. É verdade que o SPARQL tem a capacidade de representar os resultados da consulta como um gráfico. Portanto, você pode tentar combinar os resultados da consulta com o gráfico original e executar a nova consulta no gráfico combinado. Mas tal decisão iria claramente além da ideologia do RDF.
CORUJA
Um componente importante das tecnologias da Web Semântica é o OWL (Web Ontology Language) - uma linguagem para descrever ontologias. Com o vocabulário RDFS, você pode expressar apenas os relacionamentos mais básicos entre conceitos - a hierarquia de classes e relacionamentos. OWL oferece um vocabulário muito mais rico. Por exemplo, você pode especificar que duas classes (ou duas entidades) são equivalentes (ou diferentes). Essa tarefa é freqüentemente encontrada ao combinar ontologias.
Você pode criar classes compostas com base na interseção, união ou adição de outras classes:
- Quando interceptadas, todas as instâncias de uma classe composta devem se aplicar a todas as classes de origem também. Por exemplo, "Mamífero marinho" deve ser "Mamífero" e "Morador marinho" ao mesmo tempo.
- . , , «» «», «» «». «».
- , . , «» «».
- . , .
- — , .
Essas expressões que permitem vincular conceitos são chamadas de construtores.
O OWL também permite que você defina muitas propriedades de relacionamento importantes:
- Transitividade. Se as relações P (x, y) e P (y, z) se mantêm, então a relação P (x, z) também é satisfeita. Exemplos de tais relacionamentos são "Mais" - "Menos", "Pai" - "Filho", etc.
- Simetria. Se a relação P (x, y) for satisfeita, então a relação P (y, x) também será satisfeita. Por exemplo, um relacionamento relativo.
- Dependência funcional. Se as relações P (x, y) e P (x, z) forem mantidas, os valores de y e z devem ser idênticos. Um exemplo é o relacionamento com o Pai - uma pessoa não pode ter dois pais diferentes.
- Inversão de relações. Você pode especificar que se a relação P1 (x, y) for satisfeita, então mais uma relação P2 (y, x) deve ser satisfeita. Um exemplo de tal relacionamento é o relacionamento pai-filho.
- Cadeias de relacionamentos. Você pode especificar que se A está associado a alguma propriedade com B e B - com C, então A (ou C) pertence a uma determinada classe. Por exemplo, se A tem um pai para B, e o pai B tem seu pai C, então A é o neto de C..
Você também pode definir restrições sobre os valores dos argumentos das relações. Por exemplo, especifique que os argumentos devem sempre pertencer a uma classe específica, ou que uma classe deve ter pelo menos um relacionamento de um determinado tipo, ou limitar o número de relacionamentos desse tipo para ela. Ou você pode especificar que todas as instâncias relacionadas por um determinado relacionamento a um determinado valor pertencem a uma classe específica.
OWL é agora a ferramenta padrão de fato para construir ontologias. Essa linguagem é mais adequada para construir ontologias grandes e complexas do que RDFS. A sintaxe OWL permite expressar mais propriedades diferentes de conceitos e as relações entre eles. Mas também introduz uma série de restrições adicionais, por exemplo, o mesmo conceito não pode ser declarado simultaneamente como uma classe e como uma instância de outra classe. Ontologias OWL são mais rígidas, mais padronizadas e, portanto, mais legíveis. Se RDFS são apenas algumas classes adicionais no topo de um gráfico RDF, então OWL tem uma base matemática diferente - lógica de descrição. Assim, procedimentos formais de inferência tornam-se disponíveis que permitem extrair novas informações de ontologias OWL, verificar sua consistência e responder perguntas.
A lógica descritiva é uma parte da lógica de primeira ordem. Apenas predicados de um lugar (por exemplo, um conceito pertence a uma classe), predicados de dois lugares (um conceito tem uma propriedade e seu valor), bem como construtores de classe e propriedades de relacionamento, listados acima, são permitidos nele. Todas as outras expressões de lógica de primeira ordem na lógica descritiva foram eliminadas. Por exemplo, as afirmações de que o conceito de “Fatura não paga” pertence à classe “Fatura”, o conceito de “Fatura” possui as propriedades “Valor a pagar” e “Valor pago” serão aceitas. Mas fazer uma afirmação de que o conceito de “Fatura não paga” do imóvel “Valor a pagar” deve ser maior do que o imóvel “Valor pago” não funcionará. Isso requer uma regra que inclui um predicado para comparar essas propriedades. Infelizmente,Os construtores do OWL não permitem que você faça isso.
Assim, a expressividade da lógica descritiva é inferior à da lógica de primeira ordem. Mas, por outro lado, os algoritmos de inferência em lógica descritiva são muito mais rápidos. Além disso, possui a propriedade de decidibilidade - a solução pode ser encontrada garantida em um tempo finito. Acredita-se que na prática tal vocabulário seja suficiente para construir ontologias complexas e volumosas, e OWL é um bom compromisso entre expressividade e eficiência de inferência.
Também vale a pena mencionar o SWRL (Semantic Web Rule Language), que combina a capacidade de criar classes e propriedades em OWL com a escrita de regras em uma versão limitada da linguagem Datalog. O estilo dessas regras é o mesmo do Prolog. SWRL suporta predicados embutidos para comparação, matemática, string, data e manipulação de lista. Isso é exatamente o que faltou para implementar o conceito de "Nota fiscal não paga" com o auxílio de uma expressão simples.
Flora-2
Como alternativa às redes semânticas, considere uma tecnologia como os frames. Um quadro é uma estrutura que descreve um objeto complexo, uma imagem abstrata, um modelo de algo. Consiste em um nome, um conjunto de propriedades (características) e seus valores. O valor da propriedade pode ser outro quadro. Além disso, a propriedade pode ter um valor padrão. Uma função para calcular seu valor pode ser anexada a uma propriedade. Um quadro também pode incluir procedimentos de serviço, incluindo manipuladores para tais eventos, como criar, excluir um quadro, alterar o valor das propriedades, etc. Uma propriedade importante dos quadros é a capacidade de herdar. O quadro filho inclui todas as propriedades dos quadros pai.
O sistema de frames vinculados forma uma rede semântica muito semelhante a um gráfico RDF. Mas nas tarefas de criação de ontologias, os quadros foram suplantados pelo OWL, que agora é o padrão de fato. OWL é mais expressivo, tem uma base teórica mais avançada - lógica descritiva formal. Ao contrário de RDF e OWL, em que as propriedades dos conceitos são descritas independentemente umas das outras, no modelo de quadro, o conceito e suas propriedades são considerados como um único todo - o quadro. Se nos modelos RDF e OWL, os vértices do gráfico contêm os nomes dos conceitos e as arestas contêm suas propriedades, então, no modelo de quadro, os vértices do gráfico contêm conceitos com todas as suas propriedades e as arestas contêm conexões entre suas propriedades ou relações de herança entre conceitos.
Nesse sentido, o modelo de frame está muito próximo do modelo de programação orientada a objetos. Eles são praticamente os mesmos, mas têm um escopo diferente - os quadros visam modelar uma rede de conceitos e relacionamentos entre eles, e OOP - modelar o comportamento dos objetos, sua interação uns com os outros. Portanto, OOP fornece mecanismos adicionais para ocultar os detalhes de implementação de um componente de outros, restringindo o acesso aos métodos e campos de uma classe.
Linguagens de enquadramento modernas (como KL-ONE, PowerLoom, Flora-2) combinam os tipos de dados compostos do modelo de objeto com a lógica de primeira ordem. Nessas linguagens, você pode não apenas descrever a estrutura dos objetos, mas também operar com esses objetos em regras, criar regras que descrevam as condições para um objeto pertencer a uma determinada classe, etc. Os mecanismos de herança e composição de classes recebem uma interpretação lógica, que fica disponível para uso por procedimentos de inferência. Essas linguagens são mais expressivas do que OWL e não se limitam a predicados de dois lugares.
Como exemplo, vamos tentar implementar nosso exemplo com devedores na linguagem Flora-2... Esta linguagem inclui 3 componentes: a lógica de quadro F-logic, que combina quadros e lógica de primeira ordem, a lógica de ordem superior HiLog, que fornece ferramentas para formar declarações sobre a estrutura de outras declarações e meta-programação, e a lógica de mudança da Lógica Transacional, que permite de forma lógica descreve as alterações de dados e os efeitos colaterais dos cálculos. Agora, estamos apenas interessados na lógica do quadro lógico-F . Para começar, vamos usá-lo para declarar a estrutura de frames que descrevem os conceitos (classes) de clientes e devedores:
client[|name => \string,
email => \string
|].
bill[|client => client,
date => \string,
amountToPay => \number,
amountPaid => \number,
amountPaid -> 0
|].Agora podemos declarar instâncias (objetos) destes conceitos:
client1 : client[name -> 'John', email -> 'john@somewhere.net'].
client2 : client[name -> 'Mary', email -> 'mary@somewhere.net'].
bill1 : bill[client -> client1,
date -> '2020-01',
amountToPay -> 100
].
bill2 : bill[client -> client2,
date -> '2020-01',
amountToPay -> 80,
amountPaid -> 80
].O símbolo '->' significa a associação de um atributo com um valor específico em um objeto e um valor padrão em uma declaração de classe. Em nosso exemplo, o campo amountPaid da classe bill tem um valor padrão de zero. O símbolo ':' significa a criação de uma entidade da classe: client1 e client2 são entidades da classe client.
Agora podemos declarar que os conceitos "Nota fiscal não paga" e "Devedor" são subclasses dos conceitos "Conta" e "Cliente":
unpaidBill :: bill.
debtor :: client.O símbolo '::' declara uma relação de herança entre as classes. A estrutura da classe é herdada, métodos e valores padrão para todos os seus campos. Resta declarar as regras que especificam a pertença às classes de fatura não paga e devedor:
?x : unpaidBill :- ?x : bill[amountToPay -> ?a, amountPaid -> ?b], ?a > ?b.
?x : debtor :- ?x : client, ?_ : unpaidBill[client -> ?x]. A primeira declaração afirma que uma variável
?é uma entidade unpaidBill se for uma entidade de cobrança e seu campo amountToPay for maior do que amountPaid. Na segunda, o que ?pertence à classe unpaidBill, se pertence à classe cliente e há pelo menos uma entidade da classe unpaidBill em que o valor do campo cliente é igual a uma variável ?. Essa entidade da classe unpaidBill será associada a uma variável anônima ?_, cujo valor não é mais usado.
Você pode obter uma lista de devedores usando a consulta:
?- ?x:debtor.Solicitamos que você encontre todos os valores relacionados à classe devedora. O resultado será uma lista de todos os valores possíveis para a variável
?x:
?x = client1A lógica do quadro combina a visibilidade de um modelo orientado a objetos com o poder da programação lógica. Será conveniente ao trabalhar com bancos de dados, modelar sistemas complexos, integrar dados díspares - nos casos em que você precisa se concentrar na estrutura de conceitos.
SQL
Finalmente, vamos dar uma olhada nos principais recursos da sintaxe SQL. Na última publicação, dissemos que o SQL tem uma base teórica lógica - cálculo relacional, e consideramos a implementação de um exemplo com devedores no LINQ. Em termos de semântica, o SQL está perto de linguagens de enquadramento e modelos OOP - em um modelo de dados relacional, o elemento principal é uma tabela, que é percebida como um todo, e não como um conjunto de propriedades separadas.
A sintaxe SQL se ajusta perfeitamente a esta orientação de tabela. A solicitação é dividida em seções. As entidades do modelo, que são representadas por tabelas, visualizações e consultas aninhadas, foram movidas para a seção FROM. Os links entre eles são especificados usando operações JOIN. Dependências entre campos e outras condições estão nas cláusulas WHERE e HAVING. Em vez de variáveis booleanas que vinculam argumentos de predicado, operamos nos campos da tabela diretamente na consulta. Esta sintaxe descreve a estrutura do modelo de domínio mais claramente do que a sintaxe Prolog “linear”.
Como vejo o estilo de sintaxe da linguagem de modelagem
Usando o exemplo de fatura não paga, podemos comparar abordagens como programação lógica (Prolog), lógica de quadro (Flora-2), tecnologias de web semântica (RDFS, OWL e SWRL) e cálculo relacional (SQL). Resumi suas principais características em uma tabela:
| Língua | Base matemática | Orientação de estilo | Âmbito de aplicação |
|---|---|---|---|
| Prolog | Lógica de primeira ordem | Nas regras | Sistemas baseados em regras, correspondência de padrões. |
| RDFS | Gráfico | Conectado entre conceitos | Esquema de dados de recursos da WEB |
| CORUJA | Lógica descritiva | Conectado entre conceitos | Ontologias |
| SWRL | Uma versão simplificada da lógica de primeira ordem do Datalog | Regras sobre links entre conceitos | Ontologias |
| Flora-2 | Quadros + lógica de primeira ordem | Sobre regras no topo da estrutura do objeto | Bancos de dados, modelagem de sistemas complexos, integração de dados díspares |
| SQL | Cálculo relacional | Em estruturas de mesa | Base de dados |
Agora precisamos encontrar uma base matemática e um estilo de sintaxe para uma linguagem de modelagem projetada para trabalhar com dados semiestruturados e integração de dados de fontes distintas, que seriam combinados com linguagens de programação orientadas a objetos e funcionais de propósito geral.
As linguagens mais expressivas são Prolog e Flora-2 - elas são baseadas em lógica completa de primeira ordem com elementos de lógica de ordem superior. O resto das abordagens são subconjuntos dele. Exceto para RDFS - não tem nada a ver com lógica formal. Nesta fase, a lógica de primeira ordem desenvolvida parece-me a opção preferida. Para começar, pretendo me alongar sobre isso. Mas a opção limitada na forma de cálculo relacional ou lógica de banco de dados dedutiva também tem suas vantagens. Ele oferece ótimo desempenho ao trabalhar com grandes quantidades de dados. Deve ser considerado separadamente no futuro. A lógica descritiva parece muito limitada e incapaz de expressar relações dinâmicas entre conceitos.
Do meu ponto de vista, para trabalhar com dados semiestruturados e integrar fontes de dados díspares, a lógica de quadros é mais adequada do que o Prolog orientado por regras, ou OWL, que é focado em relacionamentos e classes de conceito. O modelo de quadro descreve explicitamente as estruturas dos objetos e concentra a atenção neles. No caso de objetos com muitas propriedades, a forma do quadro é muito mais legível do que regras ou trigêmeos sujeito-propriedade-objeto. A herança também é um mecanismo muito útil que pode reduzir drasticamente a quantidade de código repetitivo. Comparado ao modelo relacional, a lógica de quadro permite que você descreva estruturas de dados complexas, como árvores e gráficos, de uma forma mais natural. E o mais importante,a proximidade do modelo frame para descrição do conhecimento ao modelo OOP permitirá integrá-los em uma linguagem de forma natural.
Quero emprestar uma estrutura de consulta do SQL. A definição de um conceito pode ter uma forma complexa e não custa quebrá-lo em seções para enfatizar suas partes constituintes e facilitar a percepção. Além disso, para a maioria dos desenvolvedores, a sintaxe SQL é bastante familiar.
Portanto, quero tomar a lógica de quadros como a base da linguagem de modelagem. Mas como o objetivo é descrever estruturas de dados e integrar fontes de dados díspares, tentarei abandonar a sintaxe orientada a regras e substituí-la por uma versão estruturada emprestada do SQL. O principal elemento do modelo de domínio será um "conceito" (conceito). Em sua definição, quero incluir todas as informações necessárias para extrair suas entidades dos dados de origem:
- o nome do conceito;
- um conjunto de seus atributos;
- () , ;
- , ;
- , .
A definição do conceito será semelhante a uma consulta SQL. E todo o modelo de domínio estará na forma de conceitos inter-relacionados.
Pretendo mostrar a sintaxe resultante da linguagem de modelagem na próxima publicação. Para quem deseja se familiarizar com ele agora, existe um texto completo em estilo científico em inglês, disponível aqui:
Hybrid Ontology-Oriented Programming for Semi-Structured Data Processing
Links para publicações anteriores:
Projetando uma linguagem de programação multiparadigma. Parte 1 - Para que serve?
Nós projetamos uma linguagem de programação multiparadigma. Parte 2 - Comparação da construção de modelo em PL / SQL, LINQ e GraphQL