Modelos baseados em transformador têm alcançado excelentes resultados em uma grande variedade de disciplinas, incluindo conversação AI , linguagem natural de processamento , imagem de processamento , e até mesmo música . O principal componente de qualquer arquitetura é o módulo de atenção Transformers ( módulo de atenção), que calcula a similaridade para todos os pares na sequência de entrada. No entanto, ele não se ajusta bem com o aumento no comprimento da sequência de entrada, exigindo um aumento quadrático no tempo computacional para obter todas as estimativas de similaridade, bem como um aumento quadrático na quantidade de memória usada para construir uma matriz para armazenar essas estimativas.
Para aplicações que requerem atenção estendida, vários proxies mais rápidos e compactos foram propostos, como técnicas de cache de memória , mas a solução mais comum é usar atenção esparsa . A atenção esparsa reduz o tempo computacional e os requisitos de memória para o mecanismo de atenção, calculando apenas um número limitado de pontuações de similaridade de uma sequência em vez de todos os pares possíveis, resultando em uma matriz esparsa em vez de completa. Essas ocorrências esparsas podem ser sugeridas manualmente, encontradas usando técnicas de otimização, aprendidas ou mesmo randomizadas, conforme demonstrado por técnicas como Sparse Transformers , Longformers, Routing Transformers , Reformers and Big Bird . Uma vez que matrizes esparsas também podem ser representadas por grafos e arestas , métodos esparsos também são motivados pela literatura sobre redes neurais de grafos , especialmente no que diz respeito ao mecanismo de atenção delineado em Redes de Atenção de Grafos. Essas arquiteturas esparsas normalmente requerem camadas adicionais para criar implicitamente um mecanismo de atenção total.
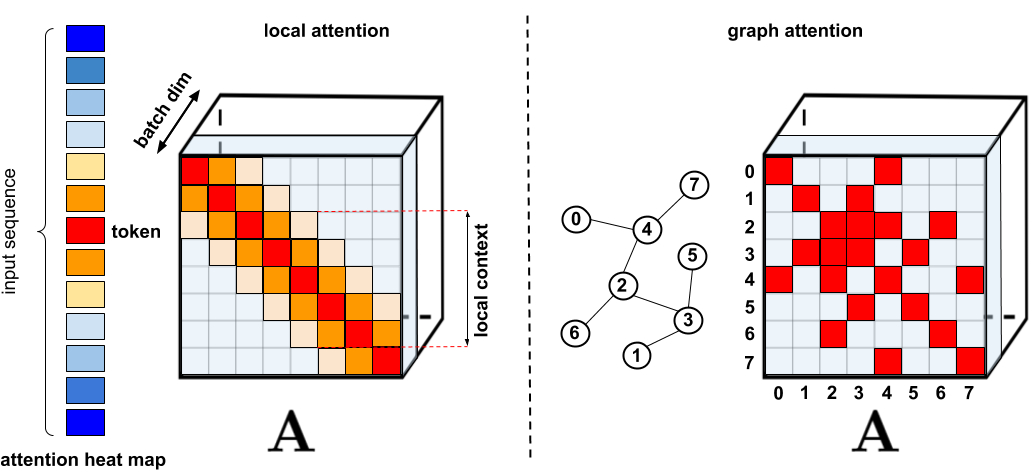
. : , . : Graph Attention Networks, , , . . « : » .
, . (1) , ; (2) ; (3) , , ; (4) , , . , , , Pointer Networks. , , , (softmax), .
, Performer, , . , , , ImageNet64, , PG-19. Performer () , , () . (Fast Attention Via Positive Orthogonal Random Features, FAVOR+), . ( , -). , .
, , , . , - . , , .
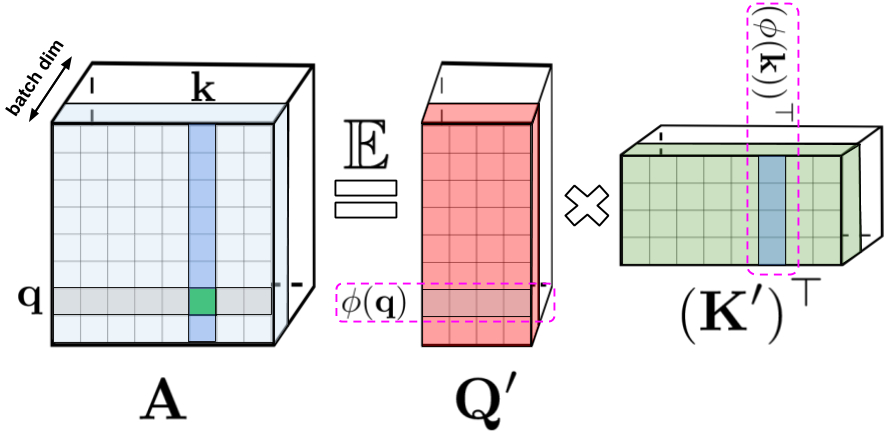
: , , , q k. : Q' K' , /. - , .
, , . , , , , -.
FAVOR+:
, . , . , , . , FAVOR+.
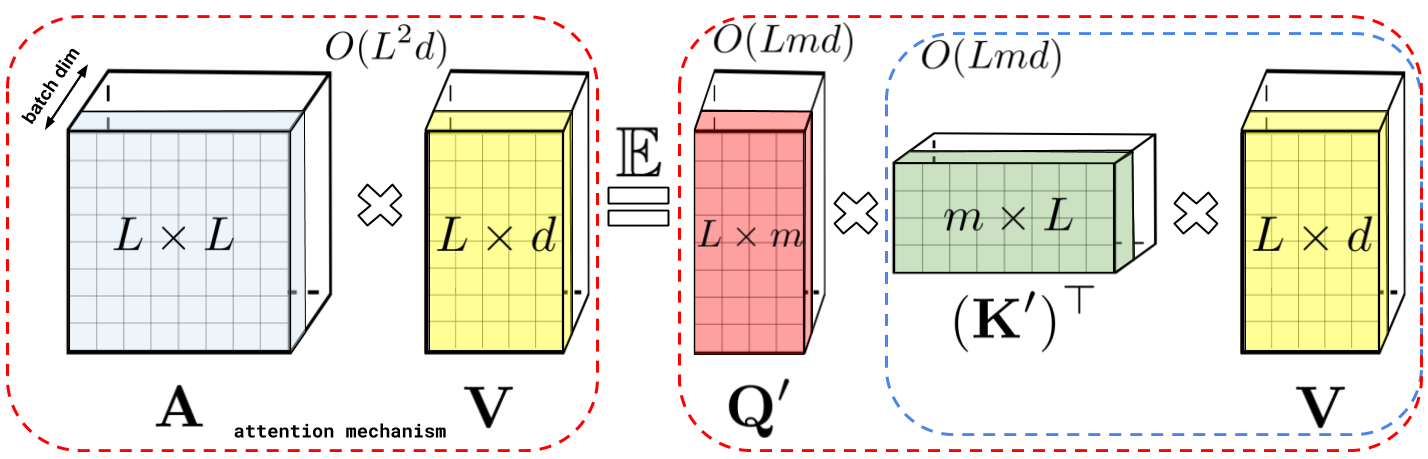
: , A V. : Q' K', A , , , , A .
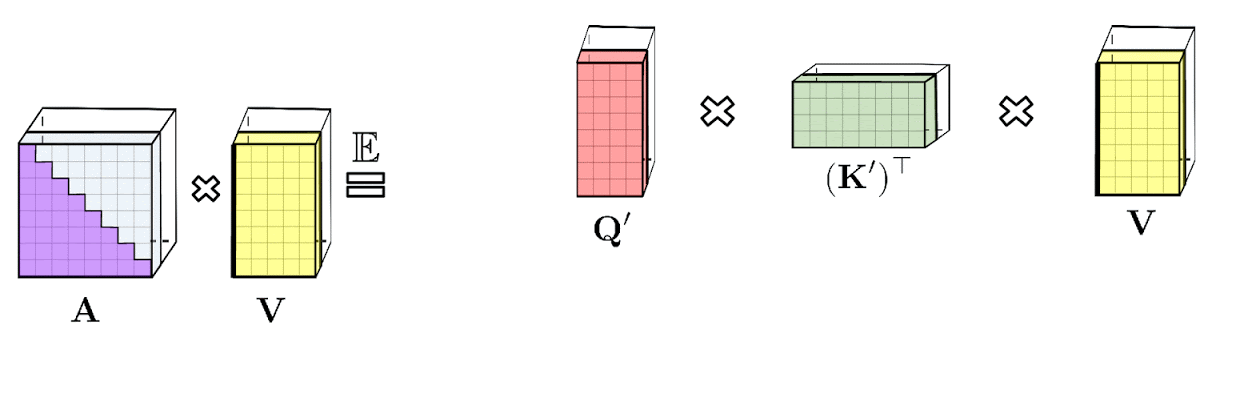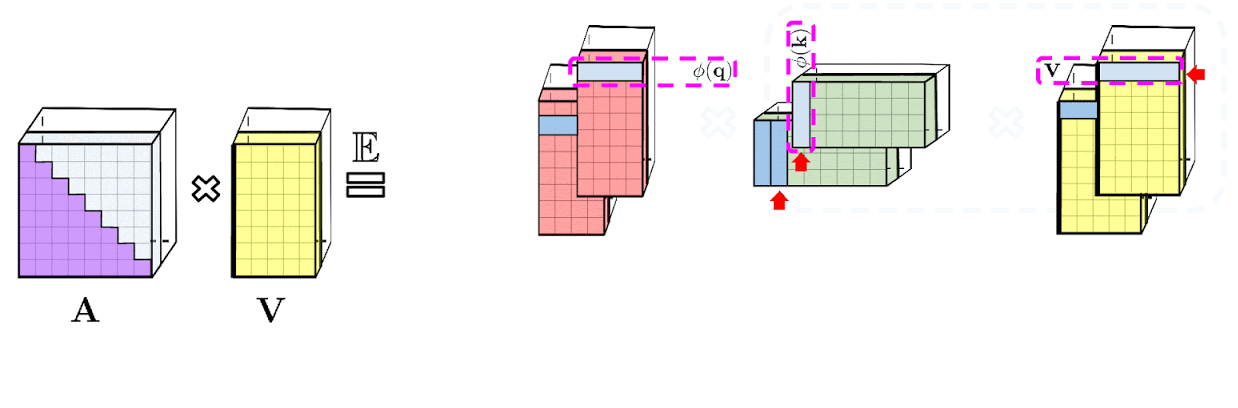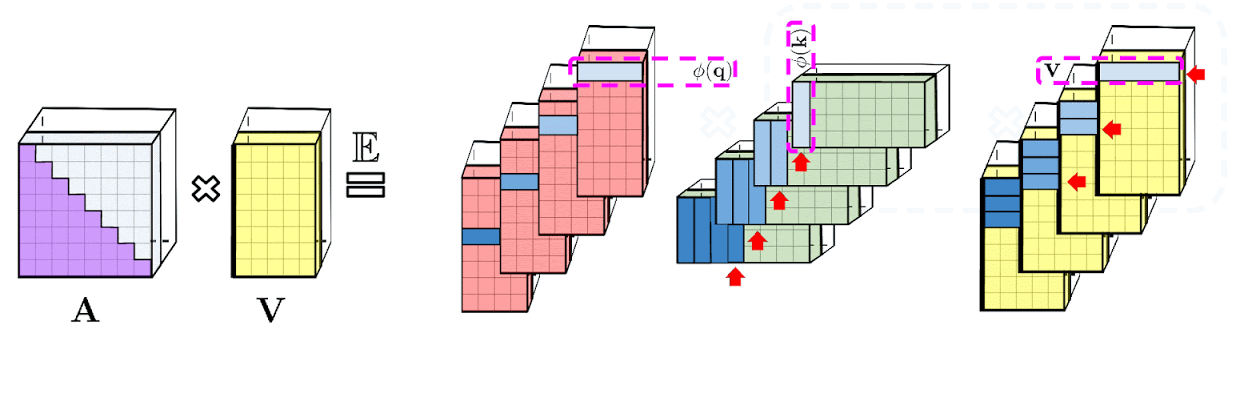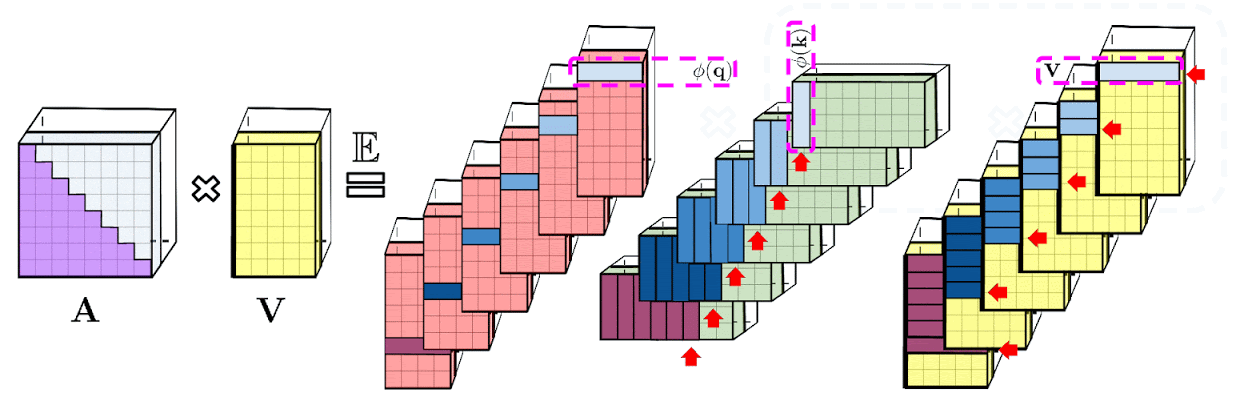
: , . : , .
Performer , , , .
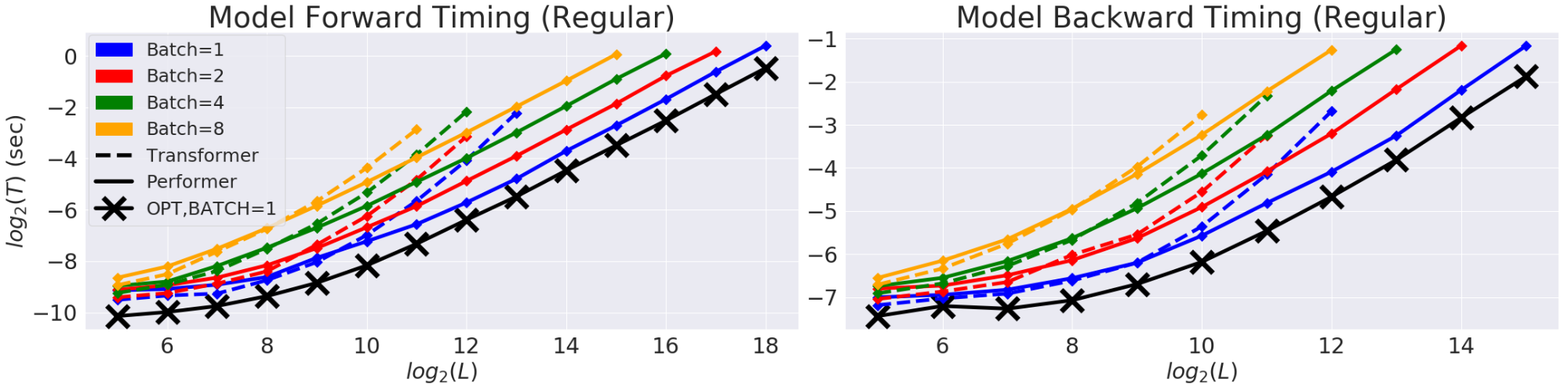
(T) (L). GPU. (X) «» , , , . Performer .
, Performer, -, , .
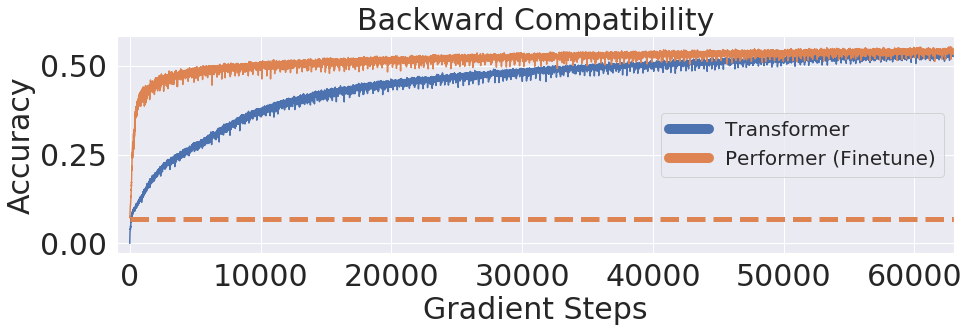
One Billion Word Benchmark (LM1B), Performer, 0.07 ( ). Performer .
:
— , . , , 20 . (, UniRef) , . Performer-ReLU ( ReLU, , ) , Performer-Softmax (accuracy) , .
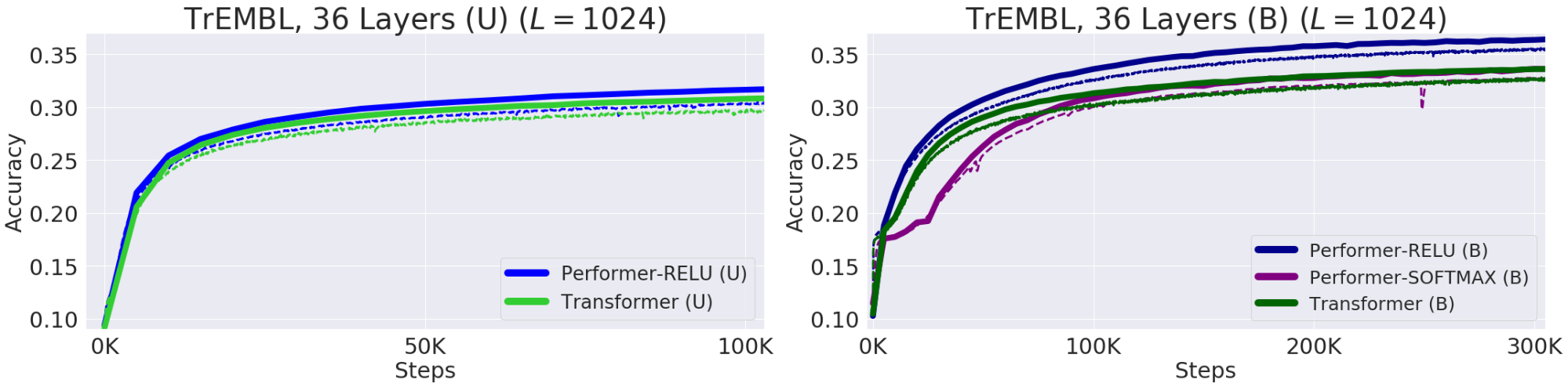
. (Train) — , (Validation) – , — (U), — (B). 36 ProGen (2019) , 16x16 TPU-v2. .
Protein Performer, ReLU. Performer , , . , , . Performer' . , , Performer - .
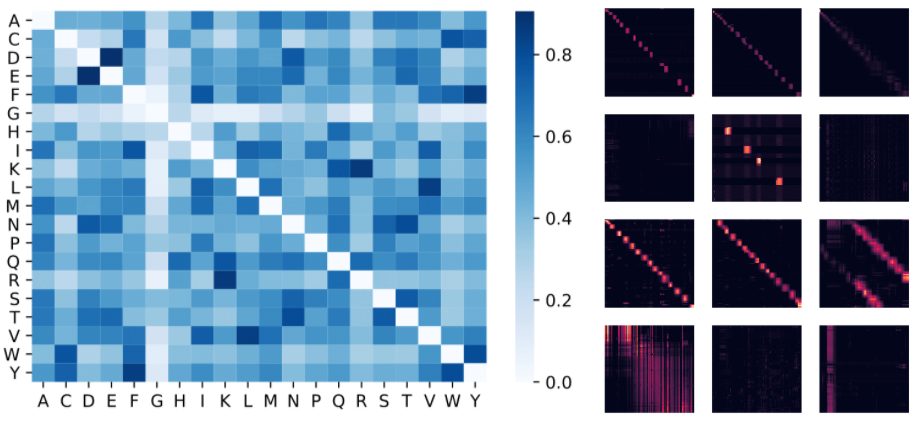
: , . , (D, E) (F, Y), . : 4 () 3 «» () BPT1_BOVIN, .
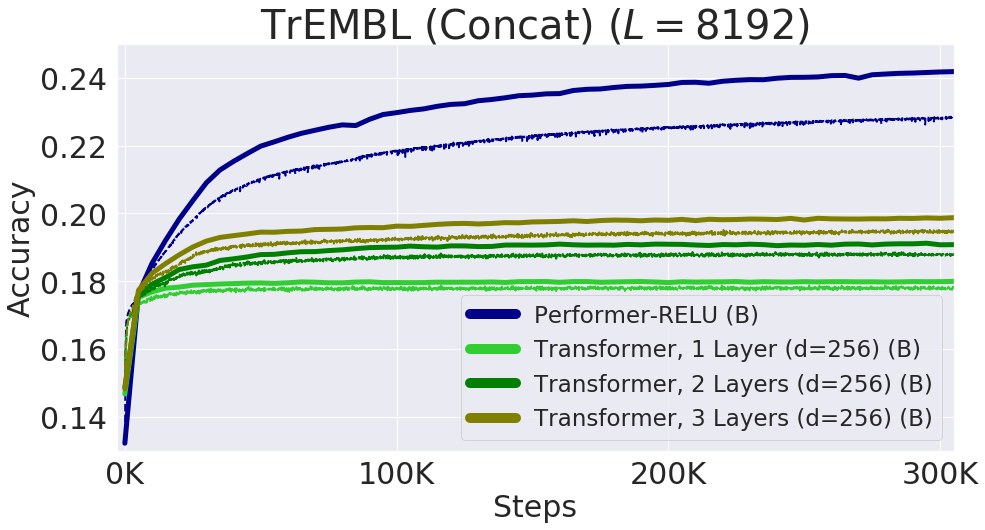
8192, . TPU, ( ) .
, . , , FAVOR Reformer. , Performer' . , , .
- — Krzysztof Choromanski, Lucy Colwell
- —
- Edição e layout - Sergey Shkarin