
Implementamos e comparamos 4 otimizadores de treinamento de rede neural populares: otimizador de impulso, propagação de rms, descida gradiente de minilote e estimativa de torque adaptativo. O repositório, muito código Python e sua saída, visualizações e fórmulas estão todos sob controle.
Introdução
Um modelo é o resultado de um algoritmo de aprendizado de máquina executado em alguns dados. O modelo representa o que foi aprendido pelo algoritmo. Essa é a "coisa" que persiste após a execução do algoritmo nos dados de treinamento e representa as regras, números e quaisquer outras estruturas de dados específicas do algoritmo e necessárias para a previsão.
O que é um otimizador?
Antes de prosseguirmos, precisamos saber o que é uma função de perda. A função de perda é uma medida de quão bem o seu modelo de previsão prevê o resultado esperado (ou valor). A função de perda também é chamada de função de custo (mais informações aqui ).
Durante o treinamento, tentamos minimizar a perda de função e atualizar os parâmetros para melhorar a precisão. Os parâmetros da rede neural são geralmente os pesos do link. Neste caso, os parâmetros são estudados na fase de treinamento. Portanto, o próprio algoritmo (e os dados de entrada) ajusta esses parâmetros. Mais informações podem ser encontradas aqui .
Assim, o otimizador é um método para obter melhores resultados, ajudando a acelerar o aprendizado. Em outras palavras, é um algoritmo usado para fazer pequenos ajustes em parâmetros como pesos e taxas de aprendizado para manter o modelo funcionando de forma correta e rápida. Aqui está uma visão geral básica dos vários otimizadores usados no aprendizado profundo e um modelo simples para entender a implementação desse modelo. Eu recomendo fortemente clonar este repositório e fazer alterações observando os padrões de comportamento.
Alguns termos comumente usados:
- Propagação de volta
Os objetivos da retropropagação são simples: ajustar cada peso na rede de acordo com o quanto ele contribui para o erro geral. Se você reduzir iterativamente o erro de cada peso, acabará com uma série de pesos que fornecem boas previsões. Encontramos a inclinação de cada parâmetro para a função de perda e atualizamos os parâmetros subtraindo a inclinação (mais informações aqui ).

- Gradiente descendente
A descida gradiente é um algoritmo de otimização usado para minimizar uma função movendo-se iterativamente em direção à descida mais íngreme, definida por um valor de gradiente negativo. No aprendizado profundo, usamos gradiente descendente para atualizar os parâmetros do modelo (mais informações aqui ).
- Hiperparâmetros
Um hiperparâmetro de modelo é uma configuração externa ao modelo, cujo valor não pode ser estimado a partir dos dados. Por exemplo, o número de neurônios ocultos, a taxa de aprendizado, etc. Não podemos estimar a taxa de aprendizado a partir dos dados (mais informações aqui ).
- Taxa de Aprendizagem
A taxa de aprendizagem (α) é um parâmetro de ajuste no algoritmo de otimização que determina o tamanho do passo em cada iteração enquanto se move em direção ao mínimo da função de perda (mais informações aqui).
Otimizadores populares

Abaixo estão alguns dos SEOs mais populares:
- Descida em gradiente estocástico (SGD).
- Otimizador de impulso.
- Propagação quadrada média (RMSProp).
- Estimativa de torque adaptativo (Adam).
Vamos considerar cada um deles em detalhes.
1. Descida gradiente estocástica (especialmente minilote)
Usamos um exemplo por vez ao treinar o modelo (em SGD puro) e atualizar o parâmetro. Mas temos que usar outro para o loop. Isso levará muito tempo. Portanto, usamos mini-lote SGD.
A descida gradiente do minibote busca equilibrar a robustez da descida gradiente estocástica e a eficiência da descida gradiente do lote. Esta é a implementação mais comum de gradiente descendente usada no aprendizado profundo. No minilote SGD, ao treinar o modelo, tomamos um grupo de exemplos (por exemplo, 32, 64 exemplos, etc.). Essa abordagem funciona melhor porque leva apenas um único loop para os minilotes, não todos os exemplos. Mini-pacotes são selecionados aleatoriamente para cada iteração, mas por quê? Quando os mini-pacotes são escolhidos aleatoriamente, quando presos nos mínimos locais, alguns passos ruidosos podem levar à saída desses mínimos. Por que precisamos deste otimizador?
- A taxa de atualização do parâmetro é maior do que na descida gradiente de lote simples, o que permite uma convergência mais confiável evitando mínimos locais.
- As atualizações em lote fornecem um processo computacionalmente mais eficiente do que a descida gradiente estocástica.
- Se você tiver pouca RAM, os mini-pacotes são a melhor opção. O batching é eficiente devido à falta de todos os dados de treinamento na memória e nas implementações de algoritmo.
Como gerar mini-pacotes aleatórios?
def RandomMiniBatches(X, Y, MiniBatchSize):
m = X.shape[0]
miniBatches = []
permutation = list(np.random.permutation(m))
shuffled_X = X[permutation, :]
shuffled_Y = Y[permutation, :].reshape((m,1)) #sure for uptpur shape
num_minibatches = m // MiniBatchSize
for k in range(0, num_minibatches):
miniBatch_X = shuffled_X[k * MiniBatchSize:(k + 1) * MiniBatchSize,:]
miniBatch_Y = shuffled_Y[k * MiniBatchSize:(k + 1) * MiniBatchSize,:]
miniBatch = (miniBatch_X, miniBatch_Y)
miniBatches.append(miniBatch)
#handeling last batch
if m % MiniBatchSize != 0:
# end = m - MiniBatchSize * m // MiniBatchSize
miniBatch_X = shuffled_X[num_minibatches * MiniBatchSize:, :]
miniBatch_Y = shuffled_Y[num_minibatches * MiniBatchSize:, :]
miniBatch = (miniBatch_X, miniBatch_Y)
miniBatches.append(miniBatch)
return miniBatches
Qual será o formato do modelo?
Estou apresentando uma visão geral do modelo, caso você seja novo no aprendizado profundo. É mais ou menos assim:
def model(X,Y,learning_rate,num_iter,hidden_size,keep_prob,optimizer):
L = len(hidden_size)
params = initilization(X.shape[1], hidden_size)
for i in range(1,num_iter):
MiniBatches = RandomMiniBatches(X, Y, 64) # GET RAMDOMLY MINIBATCHES
p , q = MiniBatches[2]
for MiniBatch in MiniBatches: #LOOP FOR MINIBATCHES
(MiniBatch_X, MiniBatch_Y) = MiniBatch
cache, A = model_forward(MiniBatch_X, params, L,keep_prob) #FORWARD PROPOGATIONS
cost = cost_f(A, MiniBatch_Y) #COST FUNCTION
grad = backward(MiniBatch_X, MiniBatch_Y, params, cache, L,keep_prob) #BACKWARD PROPAGATION
params = update_params(params, grad, beta=0.9,learning_rate=learning_rate)
return params
Na figura a seguir, você pode ver que há grandes oscilações no SGD. O movimento vertical não é necessário: queremos apenas o movimento horizontal. Se você diminuir o movimento vertical e aumentar o movimento horizontal, o modelo aprenderá mais rápido, não concorda?

Como minimizar vibrações indesejadas? Os otimizadores a seguir os minimizam e ajudam a acelerar o aprendizado.
2. Otimizador de impulso
Há muita hesitação no SGD ou na descida gradiente. Você precisa seguir em frente, não para cima e para baixo. Precisamos aumentar a taxa de aprendizado do modelo na direção certa e faremos isso com o otimizador de momentum.

Como você pode ver na imagem acima, a Linha Verde do Pulse Optimizer é mais rápida do que as outras. A importância de aprender rapidamente pode ser vista quando você tem grandes conjuntos de dados e muitas iterações. Como implementar este otimizador?

O valor normal para β é cerca de 0,9.Você
pode ver que criamos dois parâmetros - vdW e vdb - a partir dos parâmetros de retropropagação . Considere o valor β = 0,9, então a equação assume a forma:
vdw= 0.9 * vdw + 0.1 * dw
vdb = 0.9 * vdb + 0.1 * dbComo você pode ver, vdw depende mais do valor anterior de vdw do que de dw. Quando a renderização é um gráfico, você pode ver que o Momentum Optimizer leva em consideração os gradientes anteriores para suavizar a atualização. É por isso que é possível minimizar as flutuações. Quando usamos SGD, o caminho percorrido pela descida gradiente do minilote oscilou em direção à convergência. O Momentum Optimizer ajuda a reduzir essas flutuações.
def update_params_with_momentum(params, grads, v, beta, learning_rate):
# grads has the dw and db parameters from backprop
# params has the W and b parameters which we have to update
for l in range(len(params) // 2 ):
# HERE WE COMPUTING THE VELOCITIES
v["dW" + str(l + 1)] = beta * v["dW" + str(l + 1)] + (1 - beta) * grads['dW' + str(l + 1)]
v["db" + str(l + 1)] = beta * v["db" + str(l + 1)] + (1 - beta) * grads['db' + str(l + 1)]
#updating parameters W and b
params["W" + str(l + 1)] = params["W" + str(l + 1)] - learning_rate * v["dW" + str(l + 1)]
params["b" + str(l + 1)] = params["b" + str(l + 1)] - learning_rate * v["db" + str(l + 1)]
return params
O repositório está aqui
3. Distribuição quadrada média da raiz
Root root mean square (RMSprop) é uma média de decadência exponencial. A propriedade essencial do RMSprop é que você não está limitado apenas à soma dos gradientes anteriores, mas está mais limitado aos gradientes das últimas etapas de tempo. RMSprop contribui para a média exponencialmente decadente de "gradientes de lei quadrada" anteriores. No RMSProp estamos tentando reduzir o movimento vertical usando a média, porque eles somam cerca de 0, tomando a média. RMSprop fornece a média para a atualização.

Uma fonte

Dê uma olhada no código abaixo. Isso lhe dará uma compreensão básica de como implementar esse otimizador. Tudo é igual ao SGD, temos que mudar a função de atualização.
def initilization_RMS(params):
s = {}
for i in range(len(params)//2 ):
s["dW" + str(i)] = np.zeros(params["W" + str(i)].shape)
s["db" + str(i)] = np.zeros(params["b" + str(i)].shape)
return s
def update_params_with_RMS(params, grads,s, beta, learning_rate):
# grads has the dw and db parameters from backprop
# params has the W and b parameters which we have to update
for l in range(len(params) // 2 ):
# HERE WE COMPUTING THE VELOCITIES
s["dW" + str(l)]= beta * s["dW" + str(l)] + (1 - beta) * np.square(grads['dW' + str(l)])
s["db" + str(l)] = beta * s["db" + str(l)] + (1 - beta) * np.square(grads['db' + str(l)])
#updating parameters W and b
params["W" + str(l)] = params["W" + str(l)] - learning_rate * grads['dW' + str(l)] / (np.sqrt( s["dW" + str(l)] )+ pow(10,-4))
params["b" + str(l)] = params["b" + str(l)] - learning_rate * grads['db' + str(l)] / (np.sqrt( s["db" + str(l)]) + pow(10,-4))
return params
4. Adam Optimizer
Adam é um dos algoritmos de otimização mais eficientes no treinamento de redes neurais. Ele combina as idéias de RMSProp e Pulse Optimizer. Em vez de adaptar a taxa de aprendizado dos parâmetros com base na média do primeiro momento (média), como no RMSProp, Adam também usa a média dos segundos momentos dos gradientes. Especificamente, o algoritmo calcula a média móvel exponencial do gradiente e o gradiente quadrático, e os parâmetros
beta1e beta2controla a taxa de decaimento dessas médias móveis. Como?
def initilization_Adam(params):
s = {}
v = {}
for i in range(len(params)//2 ):
v["dW" + str(i)] = np.zeros(params["W" + str(i)].shape)
v["db" + str(i)] = np.zeros(params["b" + str(i)].shape)
s["dW" + str(i)] = np.zeros(params["W" + str(i)].shape)
s["db" + str(i)] = np.zeros(params["b" + str(i)].shape)
return v, s
def update_params_with_Adam(params, grads,v, s, beta1,beta2, learning_rate,t):
epsilon = pow(10,-8)
v_corrected = {}
s_corrected = {}
# grads has the dw and db parameters from backprop
# params has the W and b parameters which we have to update
for l in range(len(params) // 2 ):
# HERE WE COMPUTING THE VELOCITIES
v["dW" + str(l)] = beta1 * v["dW" + str(l)] + (1 - beta1) * grads['dW' + str(l)]
v["db" + str(l)] = beta1 * v["db" + str(l)] + (1 - beta1) * grads['db' + str(l)]
v_corrected["dW" + str(l)] = v["dW" + str(l)] / (1 - np.power(beta1, t))
v_corrected["db" + str(l)] = v["db" + str(l)] / (1 - np.power(beta1, t))
s["dW" + str(l)] = beta2 * s["dW" + str(l)] + (1 - beta2) * np.power(grads['dW' + str(l)], 2)
s["db" + str(l)] = beta2 * s["db" + str(l)] + (1 - beta2) * np.power(grads['db' + str(l)], 2)
s_corrected["dW" + str(l)] = s["dW" + str(l)] / (1 - np.power(beta2, t))
s_corrected["db" + str(l)] = s["db" + str(l)] / (1 - np.power(beta2, t))
params["W" + str(l)] = params["W" + str(l)] - learning_rate * v_corrected["dW" + str(l)] / np.sqrt(s_corrected["dW" + str(l)] + epsilon)
params["b" + str(l)] = params["b" + str(l)] - learning_rate * v_corrected["db" + str(l)] / np.sqrt(s_corrected["db" + str(l)] + epsilon)
return params
Hiperparâmetros
- β1 (beta1) valor quase 0,9
- β2 (beta2) - quase 0,999
- ε - evita a divisão por zero (10 ^ -8) (não afeta muito a aprendizagem)
Por que esse otimizador?
Suas vantagens:
- Implementação simples.
- Eficiência computacional.
- Requisitos de memória baixos.
- Escala invariante para diagonal de gradientes.
- Bem adequado para grandes tarefas em termos de dados e parâmetros.
- Adequado para fins não estacionários.
- Adequado para tarefas com gradientes muito barulhentos ou esparsos.
- Os hiperparâmetros são diretos e geralmente exigem poucos ajustes.
Vamos construir um modelo e ver como os hiperparâmetros aceleram o aprendizado
Vamos fazer uma demonstração prática de como acelerar o aprendizado. Neste artigo não iremos explicar as outras coisas (inicialização, rastreios,
forward_prop, back_prop, gradiente descendente, e assim por diante. D.). As funções necessárias para o treinamento já estão incorporadas ao NumPy. Se você quiser dar uma olhada, aqui está o link !
Vamos começar!
Estou criando uma função de modelo genérico que funciona para todos os otimizadores discutidos aqui.
1. Inicialização:
inicializamos os parâmetros usando uma função de inicialização que recebe entradas como
features_size (em nosso caso 12288) e uma matriz oculta de tamanhos (usamos [100,1]) e esta saída como parâmetros de inicialização. Existe outro método de inicialização. Eu encorajo você a ler este artigo.
def initilization(input_size,layer_size):
params = {}
np.random.seed(0)
params['W' + str(0)] = np.random.randn(layer_size[0], input_size) * np.sqrt(2 / input_size)
params['b' + str(0)] = np.zeros((layer_size[0], 1))
for l in range(1,len(layer_size)):
params['W' + str(l)] = np.random.randn(layer_size[l],layer_size[l-1]) * np.sqrt(2/layer_size[l])
params['b' + str(l)] = np.zeros((layer_size[l],1))
return params
2. Propagação direta:
Nesta função, a entrada é X, assim como os parâmetros, a extensão das camadas ocultas e o dropout, que são usados na técnica de dropout.
Defino o valor em 1 para que nenhum efeito seja visto no exercício. Se o seu modelo for super ajustado, você poderá definir um valor diferente. Eu apenas aplico o dropout nas camadas pares .
Calculamos o valor de ativação para cada camada usando uma função
forward_activation.
#activations-----------------------------------------------
def forward_activation(A_prev, w, b, activation):
z = np.dot(A_prev, w.T) + b.T
if activation == 'relu':
A = np.maximum(0, z)
elif activation == 'sigmoid':
A = 1/(1+np.exp(-z))
else:
A = np.tanh(z)
return A
#________model forward ____________________________________________________________________________________________________________
def model_forward(X,params, L,keep_prob):
cache = {}
A =X
for l in range(L-1):
w = params['W' + str(l)]
b = params['b' + str(l)]
A = forward_activation(A, w, b, 'relu')
if l%2 == 0:
cache['D' + str(l)] = np.random.randn(A.shape[0],A.shape[1]) < keep_prob
A = A * cache['D' + str(l)] / keep_prob
cache['A' + str(l)] = A
w = params['W' + str(L-1)]
b = params['b' + str(L-1)]
A = forward_activation(A, w, b, 'sigmoid')
cache['A' + str(L-1)] = A
return cache, A
3. Retropropagação:
aqui escrevemos a função de retropropagação. Ele retornará grad ( inclinação ). Usamos
gradao atualizar os parâmetros (se você não souber sobre isso). Eu recomendo a leitura deste artigo.
def backward(X, Y, params, cach,L,keep_prob):
grad ={}
m = Y.shape[0]
cach['A' + str(-1)] = X
grad['dz' + str(L-1)] = cach['A' + str(L-1)] - Y
cach['D' + str(- 1)] = 0
for l in reversed(range(L)):
grad['dW' + str(l)] = (1 / m) * np.dot(grad['dz' + str(l)].T, cach['A' + str(l-1)])
grad['db' + str(l)] = 1 / m * np.sum(grad['dz' + str(l)].T, axis=1, keepdims=True)
if l%2 != 0:
grad['dz' + str(l-1)] = ((np.dot(grad['dz' + str(l)], params['W' + str(l)]) * cach['D' + str(l-1)] / keep_prob) *
np.int64(cach['A' + str(l-1)] > 0))
else :
grad['dz' + str(l - 1)] = (np.dot(grad['dz' + str(l)], params['W' + str(l)]) *
np.int64(cach['A' + str(l - 1)] > 0))
return grad
Já vimos o recurso de atualização do otimizador, então vamos usá-lo aqui. Vamos fazer algumas pequenas alterações na função de modelo da discussão SGD.
def model(X,Y,learning_rate,num_iter,hidden_size,keep_prob,optimizer):
L = len(hidden_size)
params = initilization(X.shape[1], hidden_size)
costs = []
itr = []
if optimizer == 'momentum':
v = initilization_moment(params)
elif optimizer == 'rmsprop':
s = initilization_RMS(params)
elif optimizer == 'adam' :
v,s = initilization_Adam(params)
for i in range(1,num_iter):
MiniBatches = RandomMiniBatches(X, Y, 32) # GET RAMDOMLY MINIBATCHES
p , q = MiniBatches[2]
for MiniBatch in MiniBatches: #LOOP FOR MINIBATCHES
(MiniBatch_X, MiniBatch_Y) = MiniBatch
cache, A = model_forward(MiniBatch_X, params, L,keep_prob) #FORWARD PROPOGATIONS
cost = cost_f(A, MiniBatch_Y) #COST FUNCTION
grad = backward(MiniBatch_X, MiniBatch_Y, params, cache, L,keep_prob) #BACKWARD PROPAGATION
if optimizer == 'momentum':
params = update_params_with_momentum(params, grad, v, beta=0.9,learning_rate=learning_rate)
elif optimizer == 'rmsprop':
params = update_params_with_RMS(params, grad, s, beta=0.9,learning_rate=learning_rate)
elif optimizer == 'adam' :
params = update_params_with_Adam(params, grad,v, s, beta1=0.9,beta2=0.999, learning_rate=learning_rate,t=i) #UPDATE PARAMETERS
elif optimizer == "minibatch":
params = update_params(params, grad,learning_rate=learning_rate)
if i%5 == 0:
costs.append(cost)
itr.append(i)
if i % 100 == 0 :
print('cost of iteration______{}______{}'.format(i,cost))
return params,costs,itr
Treino com mini packs
params, cost_sgd,itr = model(X_train, Y_train, learning_rate = 0.01,
num_iter=500, hidden_size=[100, 1],keep_prob=1,optimizer='minibatch')
Y_train_pre = predict(X_train, params, 2)
print('train_accuracy------------', accuracy_score(Y_train_pre, Y_train))Conclusão ao abordar com mini-pacotes:
cost of iteration______100______0.35302967575683797
cost of iteration______200______0.472914548745098
cost of iteration______300______0.4884728238471557
cost of iteration______400______0.21551100063345618
train_accuracy------------ 0.8494208494208494
Treinamento do Pulse Optimizer
params,cost_momentum, itr = model(X_train, Y_train, learning_rate = 0.01,
num_iter=500, hidden_size=[100, 1],keep_prob=1,optimizer='momentum')
Y_train_pre = predict(X_train, params, 2)
print('train_accuracy------------', accuracy_score(Y_train_pre, Y_train))Saída do otimizador de pulso:
cost of iteration______100______0.36278494129038086
cost of iteration______200______0.4681552335189021
cost of iteration______300______0.382226159384529
cost of iteration______400______0.18219310793752702 train_accuracy------------ 0.8725868725868726Treinamento com RMSprop
params,cost_rms,itr = model(X_train, Y_train, learning_rate = 0.01,
num_iter=500, hidden_size=[100, 1],keep_prob=1,optimizer='rmsprop')
Y_train_pre = predict(X_train, params, 2)
print('train_accuracy------------', accuracy_score(Y_train_pre, Y_train))Saída RMSprop:
cost of iteration______100______0.2983858963793841
cost of iteration______200______0.004245700579927428
cost of iteration______300______0.2629426607580565
cost of iteration______400______0.31944824707807556 train_accuracy------------ 0.9613899613899614Treinando com Adam
params,cost_adam, itr = model(X_train, Y_train, learning_rate = 0.01,
num_iter=500, hidden_size=[100, 1],keep_prob=1,optimizer='adam')
Y_train_pre = predict(X_train, params, 2)
print('train_accuracy------------', accuracy_score(Y_train_pre, Y_train))Conclusão de Adam:
cost of iteration______100______0.3266223660473619
cost of iteration______200______0.08214547683157716
cost of iteration______300______0.0025645257286439583
cost of iteration______400______0.058015188756586206 train_accuracy------------ 0.9845559845559846Você viu a diferença de precisão entre os dois? Usamos os mesmos parâmetros de inicialização, a mesma taxa de aprendizado e o mesmo número de iterações; apenas o otimizador é diferente, mas olhe o resultado!
Mini-batch accuracy : 0.8494208494208494
momemtum accuracy : 0.8725868725868726
Rms accuracy : 0.9613899613899614
adam accuracy : 0.9845559845559846Visualização gráfica do modelo

Você pode verificar o repositório se tiver dúvidas sobre o código.
Resumo
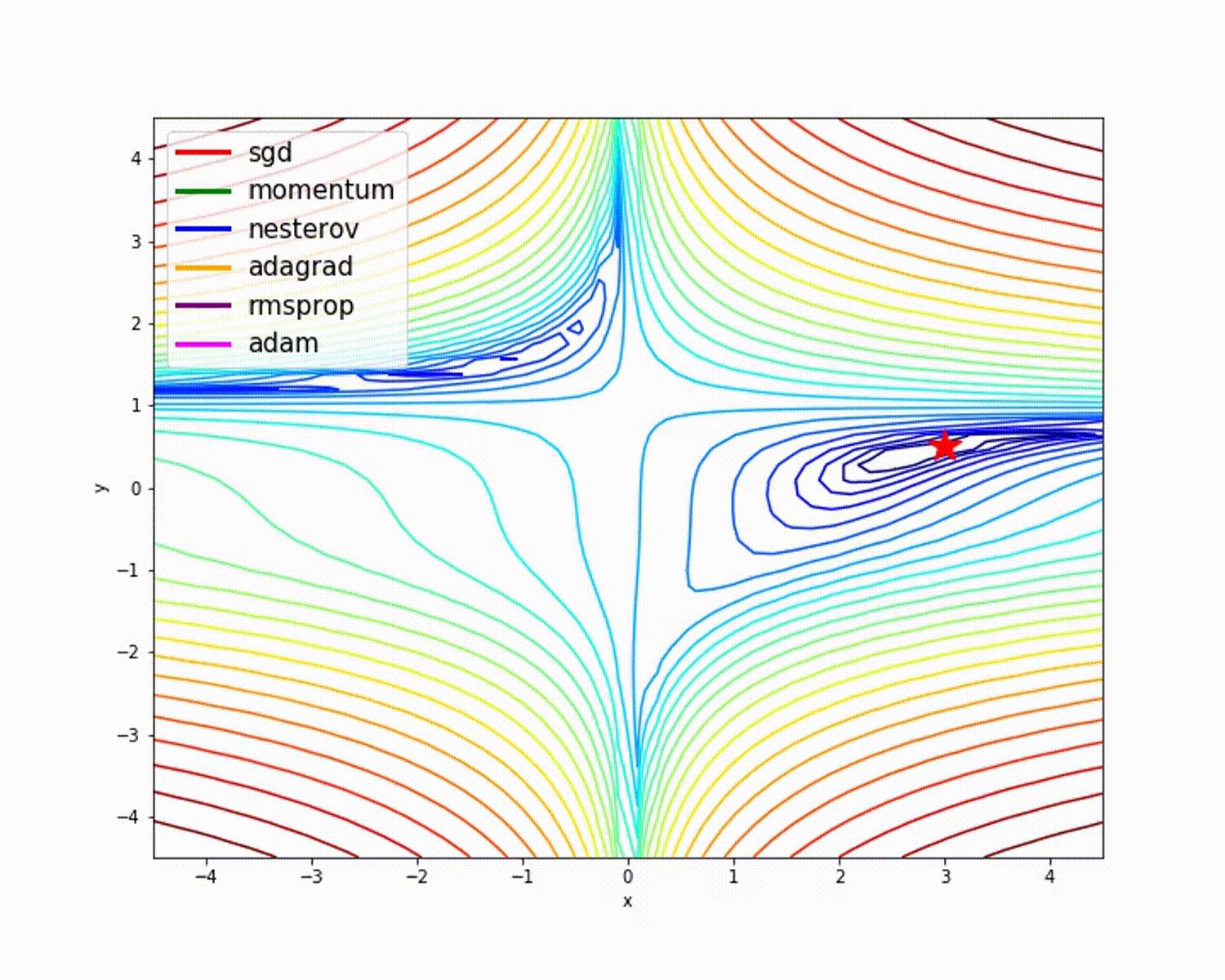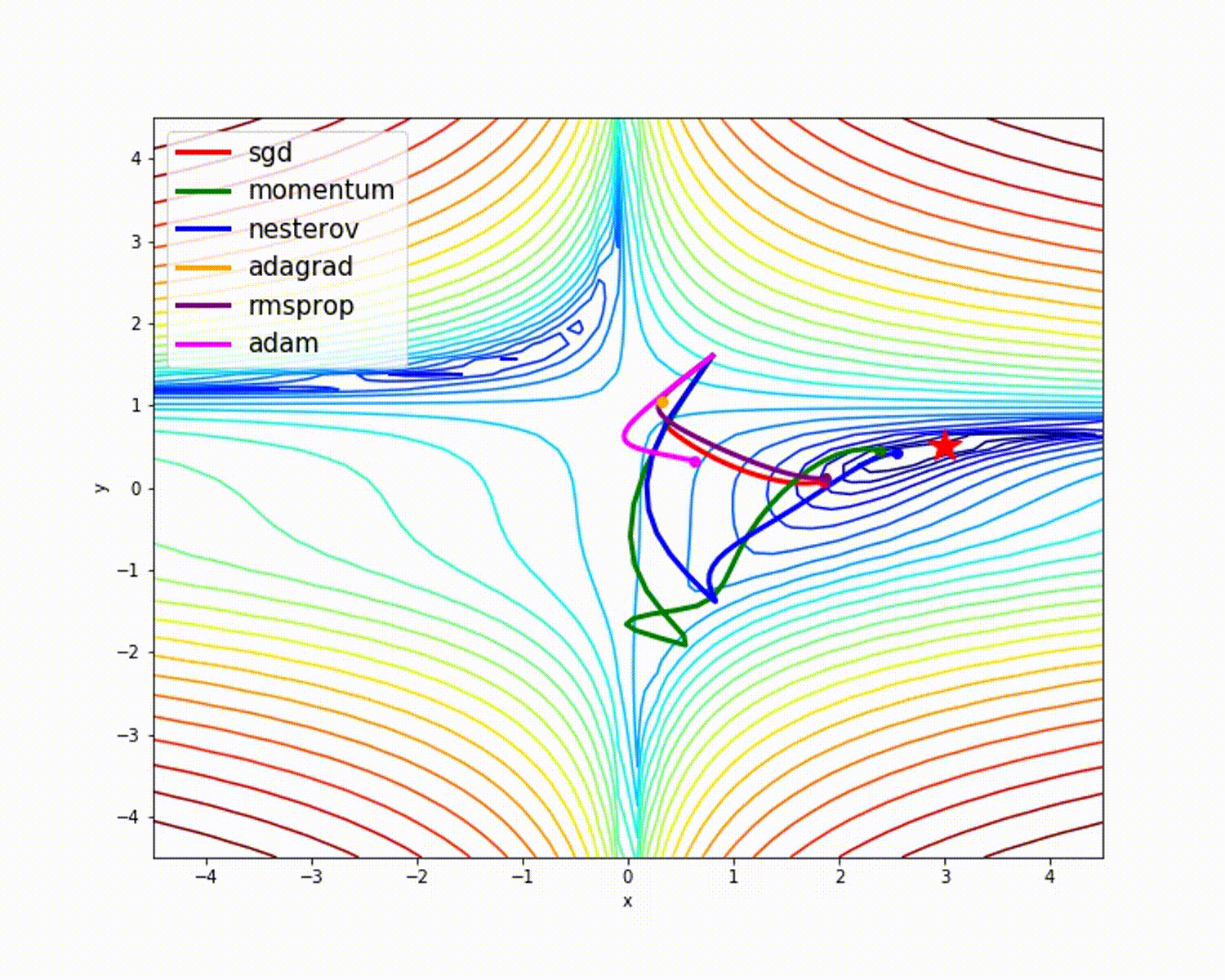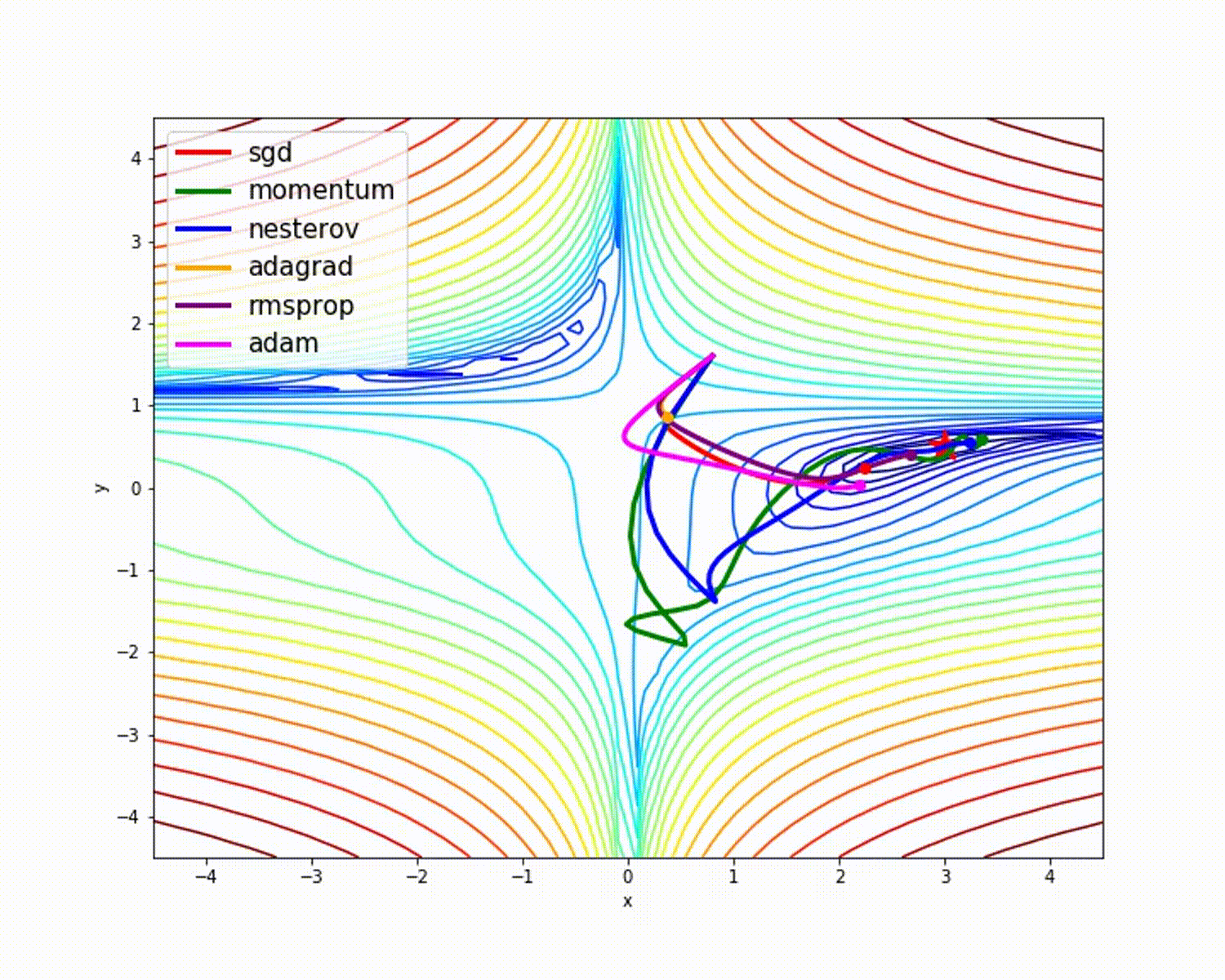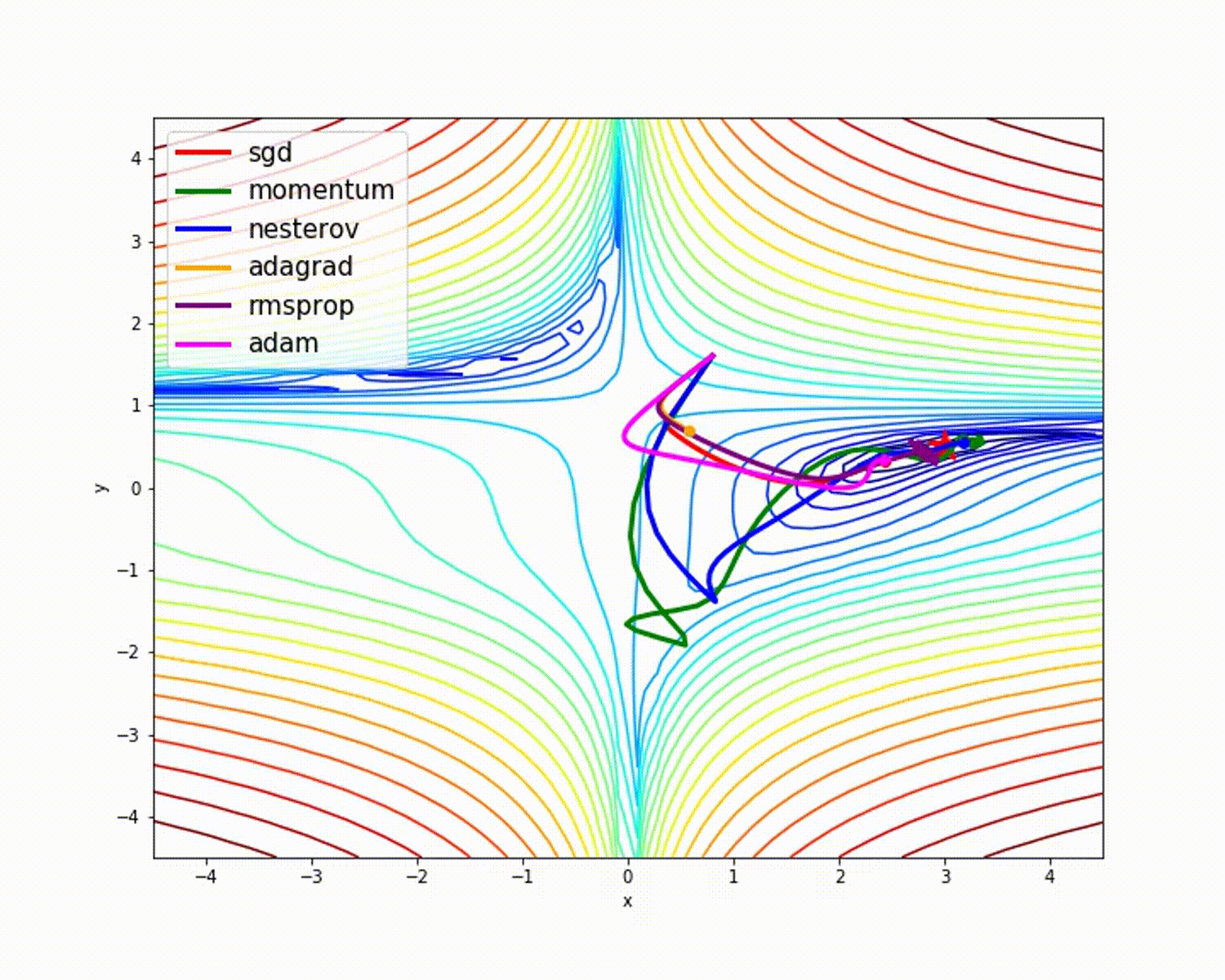
origem
Como vimos, o otimizador Adam oferece boa precisão em comparação com outros otimizadores. A imagem acima mostra como o modelo aprende por meio de iterações. Momentum fornece a velocidade SGD e RMSProp fornece a média exponencial dos pesos para os parâmetros atualizados. Usamos menos dados no modelo acima, mas veremos mais benefícios dos otimizadores ao trabalhar com grandes conjuntos de dados e muitas iterações. Discutimos a ideia básica dos otimizadores e espero que isso lhe dê alguma motivação para aprender mais sobre otimizadores e usá-los!
Recursos
As perspectivas para redes neurais e aprendizado de máquina profundo são enormes e, pelas estimativas mais conservadoras, seu impacto no mundo será quase o mesmo que o impacto da eletricidade na indústria no século XIX. Os especialistas que avaliarão essas perspectivas antes de qualquer outra pessoa terão todas as chances de se tornar o chefe do progresso. Para essas pessoas, fizemos um código promocional HABR , que dá um adicional de 10% ao desconto de treinamento indicado no banner.

- Curso de Aprendizado de Máquina
- Curso "Matemática e Aprendizado de Máquina para Ciência de Dados"
- Curso avançado "Machine Learning Pro + Deep Learning"
- Bootcamp online para ciência de dados
- Treinar a profissão de Analista de Dados do zero
- Data Analytics Online Bootcamp
- Ensinar a profissão de Ciência de Dados do zero
- Curso de Python para Desenvolvimento Web