Você pode confiar na sua opinião, formada a partir de diferentes fontes de informação, por exemplo, publicações em sites ou experiência. Você pode perguntar a colegas e conhecidos. Outra opção é olhar para os tópicos da conferência: o comitê do programa é composto por representantes ativos da indústria, por isso confiamos neles na escolha dos tópicos relevantes. Uma área separada é a pesquisa e relatórios. Mas há um problema. Pesquisas sobre o estado do DevOps são realizadas anualmente no mundo, relatórios são publicados por empresas estrangeiras e quase não há informações sobre o DevOps russo.
Mas chegou o dia em que tal estudo foi realizado, e hoje vamos falar sobre os resultados obtidos. O estado de DevOps na Rússia foi investigado em conjunto pela Express 42 e Ontiko" O Express 42 ajuda empresas de tecnologia a implementar e desenvolver práticas e ferramentas DevOps e foi um dos primeiros a falar sobre DevOps na Rússia. Os autores do estudo, Igor Kurochkin e Vitaly Khabarov, atuam na área de análise e consultoria na Express 42, possuindo formação técnica de operação e experiência de trabalho em diferentes empresas. Nos últimos 8 anos, os colegas examinaram dezenas de empresas e projetos - de startups a empresas - com diferentes problemas, bem como diferentes maturidade cultural e de engenharia.
Em seu relatório, Igor e Vitaly contaram quais problemas existiam no processo de pesquisa, como eles os resolveram, bem como como a pesquisa de DevOps é conduzida em princípio e por que o Express 42 decidiu conduzir a sua própria. Seu relatório pode ser visto aqui .

DevOps Research
Igor Kurochkin iniciou a conversa.
Regularmente, fazemos uma pergunta ao público em conferências DevOps: "Você leu o relatório de status do DevOps deste ano?" Apenas alguns levantam a mão, e nosso estudo mostrou que apenas um terço os estuda. Se você nunca viu esses relatórios, digamos imediatamente que são todos muito semelhantes. Na maioria das vezes, existem frases como: "Comparado ao ano passado ..."
Aqui temos o primeiro problema, e depois dele mais dois:
- Não temos dados do ano passado. O estado do DevOps na Rússia não interessa a ninguém;
- Metodologia. Não está claro como testar hipóteses, como construir perguntas, como realizar análises, comparar resultados, encontrar conexões;
- Terminologia. Todos os relatórios estão em inglês, a tradução é necessária, uma estrutura de DevOps comum ainda não foi inventada e todos vêm com a sua própria.
Vamos dar uma olhada em como as análises do estado do DevOps em todo o mundo foram conduzidas em geral.
Referência histórica
A pesquisa DevOps é conduzida desde 2011. O primeiro foi realizado pela Puppet, desenvolvedora de sistemas de gerenciamento de configuração. Naquela época, era uma das principais ferramentas para descrever a infraestrutura na forma de código. Até 2013, esses estudos eram simplesmente na forma de pesquisas fechadas e sem relatórios públicos.
Em 2013, nasceu a IT Revolution, editora de todos os principais livros de DevOps. Juntamente com a Puppet, eles prepararam a primeira publicação "State of DevOps", onde 4 métricas principais apareceram pela primeira vez. No ano seguinte, a ThoughtWorks, uma empresa de consultoria conhecida por seus radares de tecnologia regulares em práticas e ferramentas da indústria, juntou-se a nós. E em 2015, uma seção de metodologia foi adicionada, e ficou claro como eles realizam a análise.
Em 2016, os autores do estudo, tendo criado sua empresa DORA (DevOps Research and Assessment), publicaram um relatório anual. No ano seguinte, DORA e Puppet divulgaram um relatório conjunto pela última vez.
E então o interessante começou:

Em 2018, as empresas se separaram e foram lançados dois relatórios independentes: um da Puppet e outro da DORA em conjunto com o Google. A DORA continuou a usar sua metodologia com as principais métricas, perfis de desempenho e práticas de engenharia que afetam as principais métricas e o desempenho de toda a empresa. E a Puppet ofereceu sua própria abordagem, descrevendo o processo e a evolução do DevOps. Mas a história não pegou, em 2019 a Puppet abandonou essa metodologia e lançou uma nova versão dos relatórios, nos quais listava as principais práticas e como elas afetam o DevOps do seu ponto de vista. Então outra coisa aconteceu: o Google comprou a DORA, e juntos eles divulgaram outro relatório. Você pode tê-lo visto.
As coisas complicaram-se este ano. A Puppet é conhecida por ter lançado sua própria votação. Eles fizeram isso uma semana antes de nós, e já terminou. Participamos e vimos em que temas estão interessados. A Puppet está atualmente realizando sua análise e se preparando para publicar o relatório.
Mas ainda não há anúncio da DORA e do Google. Em maio, quando a pesquisa costumava começar, chegou a informação de que Nicole Forsgren, uma das fundadoras da DORA, havia se mudado para outra empresa. Portanto, presumimos que não haverá pesquisa e nenhum relatório da DORA este ano.
Como estão as coisas na Rússia?
Não fizemos nenhuma pesquisa DevOps. Falamos em conferências, recontando as conclusões de outras pessoas e o Raiffeisenbank traduziu "State of DevOps" para 2019 (você pode encontrar o anúncio deles em Habré), muito obrigado a eles. E é tudo.
Portanto, conduzimos nossa própria pesquisa na Rússia usando metodologias e descobertas DORA. Usamos o relatório de colegas do Raiffeisenbank para nossa pesquisa, inclusive para a sincronização de terminologia e tradução. E as perguntas específicas do setor vêm dos relatórios da DORA e da pesquisa Puppet deste ano.
Processo de pesquisa
O relatório é apenas a parte final. Todo o processo de pesquisa consiste em quatro grandes etapas:
Durante a fase de preparação, entrevistamos especialistas do setor e preparamos uma lista de hipóteses. Com base neles, foram elaboradas perguntas e lançado um inquérito para todo o mês de agosto. Em seguida, analisamos e preparamos o próprio relatório. Para DORA, esse processo leva 6 meses. Nos reunimos há 3 meses e agora entendemos que mal tivemos tempo: só fazendo a análise você entende quais perguntas precisam ser feitas.
Participantes
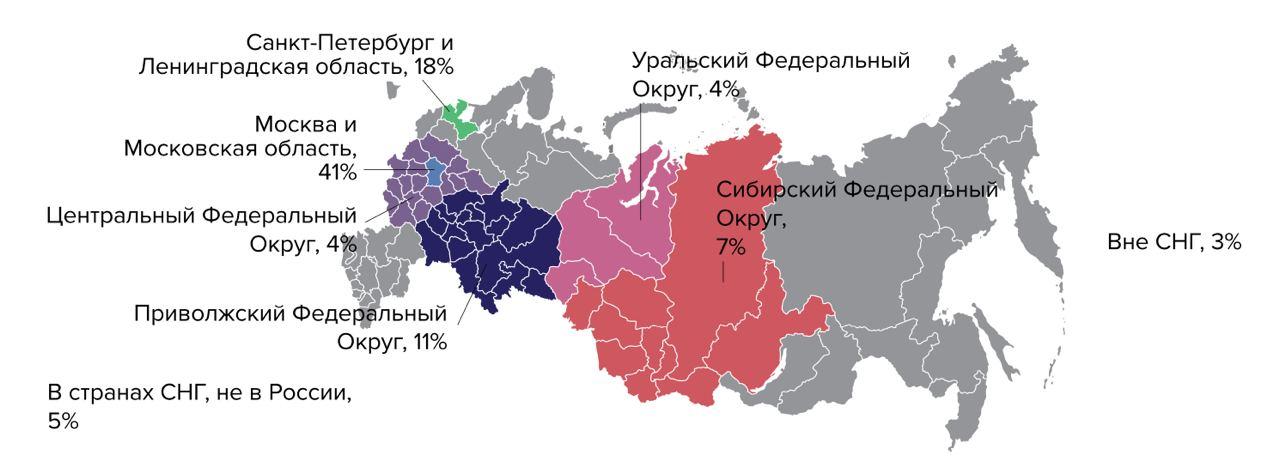
Todos os relatórios estrangeiros começam com um retrato dos participantes, e a maioria deles não é da Rússia. A porcentagem de entrevistados russos oscila de 5 a 1% de ano para ano, e isso não permite que nenhuma conclusão seja tirada.
Mapa do relatório Accelerate State of DevOps 2019:

Em nosso estudo, conseguimos entrevistar 889 pessoas - isso é bastante (DORA faz pesquisas com cerca de mil pessoas em seus relatórios anualmente) e aqui alcançamos a meta:
Verdade, nem todos os nossos participantes chegaram ao fim: porcentagem o enchimento acabou sendo um pouco menos da metade. Mas mesmo isso foi o suficiente para obter uma amostra representativa e conduzir uma análise. O DORA não divulga o percentual de preenchimento em seus relatórios, portanto não pode ser comparado aqui.
Indústrias e posições
Nossos entrevistados representam uma dúzia de setores. Metade deles trabalha com tecnologia da informação. Seguem-se os serviços financeiros, comércio, telecomunicações e outros. Entre os cargos estão especialistas (desenvolvedor, testador, engenheiro de operação) e gerentes (líderes de equipe, equipes, direções, diretores): A

cada segundo trabalha em uma empresa de médio porte. Uma terceira pessoa trabalha em grandes empresas. A maioria trabalha em equipes de até 9 pessoas. Separadamente, perguntamos sobre as principais atividades, e a maioria está de uma forma ou de outra relacionada à operação, e cerca de 40% se dedica ao desenvolvimento:

Assim coletamos informações para comparar e analisar representantes de diferentes setores, empresas, equipes. Meu colega Vitaly Khabarov falará sobre a análise.
Análise e comparação
Vitaly Khabarov: Muito obrigado a todos os participantes que responderam a nossa pesquisa, preencheram os questionários e nos forneceram dados para análises e testes posteriores de nossas hipóteses. E graças aos nossos clientes e clientes, temos uma vasta experiência que ajudou a identificar questões de interesse para a indústria e formular as hipóteses que testamos em nossa pesquisa.
Infelizmente, você não pode simplesmente pegar uma lista de perguntas de um lado e dados do outro, de alguma forma compará-los, dizer: “Sim, tudo funciona assim, tínhamos razão” e se dispersar. Não, precisamos de metodologia e métodos estatísticos para ter certeza de que não estamos enganados e de que nossas conclusões são confiáveis. Então podemos construir nosso trabalho posterior com base nestes dados:

Principais métricas
Tomamos como base a metodologia DORA, que eles descreveram em detalhes no livro "Accelerate State of DevOps". Verificamos se as principais métricas são adequadas para o mercado russo. Elas podem ser usadas da mesma maneira que a DORA usa para responder à pergunta: "Como a indústria na Rússia corresponde à indústria estrangeira?"
Principais métricas:
- Frequência de implantação. Com que frequência uma nova versão de um aplicativo é implantada no ambiente de produção (mudanças planejadas, excluindo hot fixes e resposta a incidentes)?
- Tempo de entrega. Quanto tempo é o tempo médio entre a confirmação de uma mudança (escrever a funcionalidade como código) e a implantação da mudança no ambiente do produto?
- . , , ?
- . ( , )?
A DORA encontrou uma relação entre essas métricas e o desempenho organizacional em suas pesquisas. Também verificamos em nossa pesquisa.
Mas para ter certeza de que as quatro métricas principais podem influenciar algo, você precisa entender - elas estão de alguma forma relacionadas umas às outras? A DORA respondeu afirmativamente com uma advertência: a relação entre a Taxa de falha de mudança e as outras três métricas é ligeiramente mais fraca. Temos quase a mesma foto. Se o tempo de entrega, a frequência de implantação e o tempo de recuperação se correlacionam (encontramos essa correlação por meio da correlação de Pearson e da escala de Chaddock), então não há uma correlação forte com mudanças malsucedidas.
Em princípio, a maioria dos entrevistados tende a responder que há um número bastante pequeno de incidentes ocorrendo na produção. Embora no futuro veremos que ainda existe uma diferença significativa entre os grupos de respondentes em termos de taxa de alterações sem sucesso, para esta divisão ainda não podemos usar esta métrica.
Associamos isso ao fato de que (como ficou claro durante a análise e comunicação com alguns de nossos clientes) existe uma ligeira diferença na percepção do que é considerado um incidente. Se conseguirmos restaurar a operacionalidade do nosso serviço durante a janela técnica, isso pode ser considerado um incidente? Provavelmente não, porque consertamos tudo, estamos ótimos. Pode ser considerado um incidente se tivermos que relançar nosso aplicativo 10 vezes em um modo normal, usual para nós? Parece que não. Portanto, a questão da relação das mudanças malsucedidas com outras métricas permanece em aberto. Vamos refiná-lo ainda mais.
É importante aqui que encontramos uma correlação significativa entre os tempos de entrega, os tempos de recuperação e a frequência de implantação. Portanto, pegamos essas três métricas para dividir ainda mais os respondentes em grupos de desempenho.
Quanto pesar em gramas?
Usamos análise de cluster hierárquica:
- Distribuímos respondentes em um espaço n-dimensional, onde a coordenada de cada respondente são suas respostas às perguntas.
- Declaramos cada entrevistado como um pequeno grupo.
- Combinamos os dois clusters que estão mais próximos um do outro em um cluster maior.
- Encontre o próximo par de clusters e combine-os em um cluster maior.
É assim que agrupamos todos os nossos respondentes no número necessário de clusters. Com a ajuda de um dendrograma (uma árvore de conexões entre clusters), vemos a distância entre dois clusters vizinhos. Tudo o que nos resta é definir um certo limite de distância entre esses grupos e dizer: "Esses dois grupos são bastante distintos um do outro porque a distância entre eles é enorme."
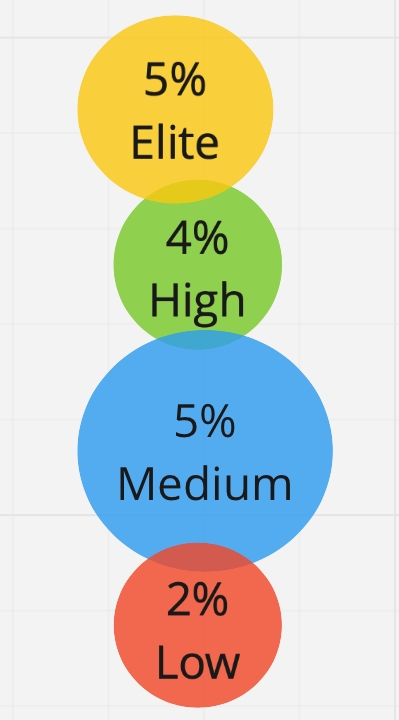
Mas há um problema oculto aqui: não temos restrições quanto ao número de clusters - podemos obter 2, 3, 4, 10 clusters. E a primeira ideia era - por que não dividir todos os nossos entrevistados em 4 grupos, como a DORA faz. Mas descobrimos que as diferenças entre esses grupos se tornam insignificantes, e não podemos ter certeza de que o respondente realmente pertence ao seu próprio grupo e não ao vizinho. Ainda não podemos dividir o mercado russo em quatro grupos. Portanto, paramos em exatamente três perfis, entre os quais há uma diferença estatisticamente significativa:

Em seguida, determinamos o perfil por clusters: pegamos as medianas de cada métrica para cada grupo e fizemos uma tabela de perfis de desempenho. Na verdade, obtivemos os perfis de desempenho da média dos participantes em cada grupo. Identificamos três perfis de eficiência: Baixa, Média, Alta:

Aqui, confirmamos nossa hipótese de que as 4 principais métricas são adequadas para determinar o perfil de desempenho e funcionam tanto no mercado ocidental quanto no russo. Existe uma diferença entre os grupos e é estatisticamente significativa. Gostaria de enfatizar que existe uma diferença significativa na média entre os perfis de desempenho de acordo com a métrica de mudanças malsucedidas, embora inicialmente não tenhamos dividido os respondentes por esse parâmetro.
Então surge a pergunta: como usar tudo isso?
Como usar
Se você pegar qualquer equipe, 4 métricas principais e aplicá-las à tabela, então em 85% dos casos não obteremos uma correspondência completa - este é apenas um participante médio, e não o que é na realidade. Somos todos (e cada equipe) um pouco diferente.
Nós verificamos: pegamos nossos entrevistados e o perfil de desempenho da DORA, e vimos quantos entrevistados se encaixam em um determinado perfil. Descobrimos que apenas 16% dos entrevistados acertaram com precisão um dos perfis. Todos os outros estão espalhados em algum lugar entre:
Isso significa que o perfil de desempenho tem um escopo limitado. Para entender onde você está em uma primeira aproximação, você pode usar esta tabela: "Oh, parece que estamos mais próximos de Médio ou Alto!" Se você entender para onde ir em seguida, isso pode ser o suficiente. Mas se sua meta é a melhoria constante e contínua, e você deseja saber mais precisamente onde desenvolver e o que fazer, fundos adicionais são necessários. Nós os chamamos de calculadoras:
- Calculadora DORA
- Calculator Express 42 * (em desenvolvimento)
- Desenvolvimento próprio (você pode criar sua própria calculadora interna).
Para que eles são necessários? Para entender:
- A equipe de nossa organização atende aos nossos padrões?
- Se não, podemos ajudá-la - acelerá-la dentro da estrutura da experiência que nossa empresa possui?
- Se sim, podemos fazer ainda melhor?
Você também pode usá-los para coletar estatísticas dentro da empresa:
- Que equipes temos;
- Divida as equipes em perfis;
- Veja: Ah, essas equipes estão com baixo desempenho (não puxam um pouco), e essas são legais: implantam todos os dias, sem erros, têm menos de uma hora de lead time.
E aí você poderá descobrir que dentro da nossa empresa existe o know-how e as ferramentas necessárias para aquelas equipes que ainda não resistiram.
Ou, se você entende que dentro da empresa você se sente ótimo, você é melhor do que muitos, então pode dar uma olhada mais ampla. Esta é exatamente a indústria russa: podemos obter a experiência necessária na indústria russa para nos acelerar? Calculator Express 42 vai ajudar aqui (está em desenvolvimento). Se você superou o mercado russo, então olhe para a calculadora DORA e o mercado global.
OK. E se você estiver no grupo Elit da calculadora DORA, o que fazer? Não existe uma boa solução aqui. Muito provavelmente você está na vanguarda da indústria, e maior aceleração e melhoria da confiabilidade são possíveis devido ao P&D interno e ao gasto de mais recursos.
Vamos passar para o mais doce - comparação.
Comparação
Inicialmente, queríamos comparar a indústria russa com a ocidental. Se compararmos diretamente, vemos que temos menos perfis e eles estão um pouco mais misturados uns com os outros, os limites são um pouco mais confusos:

Nossos artistas de elite estão escondidos entre os de alto desempenho, mas eles existem - eles são a elite, unicórnios que alcançaram alturas significativas. Na Rússia, a diferença entre o perfil Elite e o perfil Alto ainda não é significativa o suficiente. Acreditamos que no futuro essa separação ocorrerá em conexão com o aprimoramento da cultura da engenharia, a qualidade da implementação das práticas de engenharia e a expertise dentro das empresas.
Se passarmos para uma comparação direta dentro da indústria russa, veremos que as equipes de alto perfil são melhores em todos os aspectos. Também confirmamos nossa hipótese de que existe uma relação entre essas métricas e o desempenho organizacional: equipes de alto perfil têm muito mais probabilidade de não apenas atingir as metas, mas também de superá-las.
Vamos nos tornar equipes de alto perfil e não parar por aí:
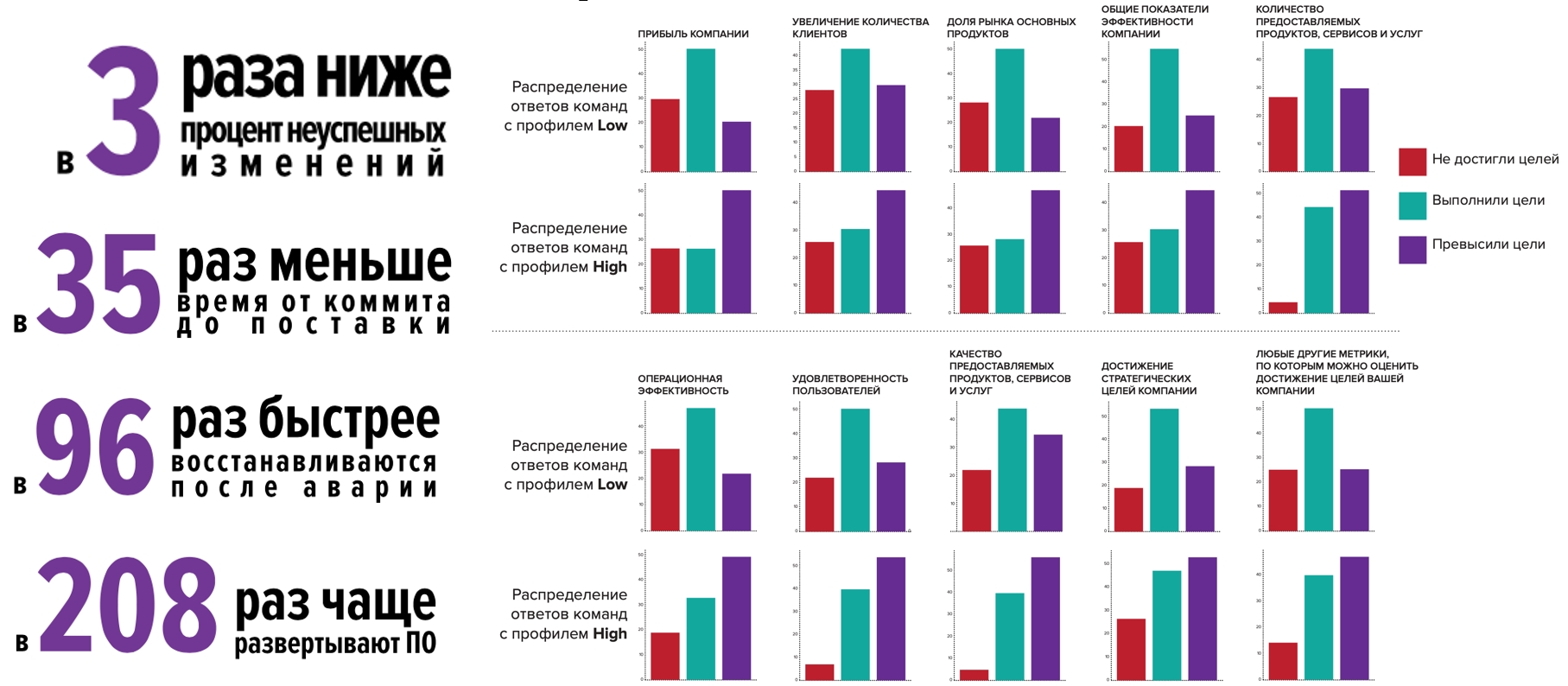
Mas este ano é especial, e decidimos verificar como as empresas vivem em uma pandemia: Equipes de alto perfil se saem muito melhor e se sentem melhor do que a média do setor:
- Novos produtos foram lançados 1,5 a 2 vezes com mais frequência
- 2x mais probabilidade de melhorar a confiabilidade e / ou desempenho da infraestrutura do aplicativo.
Ou seja, as competências que já possuíam os ajudaram a se desenvolver mais rápido, lançar novos produtos, modificar produtos existentes, conquistando assim novos mercados e novos usuários:

O que mais ajudou nossas equipes?
Práticas de engenharia

Vou lhe contar sobre as descobertas significativas de cada prática que verificamos. Talvez algo mais tenha ajudado as equipes, mas estamos falando sobre DevOps. E dentro do DevOps, vemos uma diferença entre equipes de perfis diferentes.
Plataforma como serviço
Não encontramos nenhuma conexão significativa entre a idade da plataforma e o perfil da equipe: as plataformas apareceram quase ao mesmo tempo para as equipes Low e High. Já para este último, a plataforma oferece, em média, mais serviços e mais interfaces de programação para controle por meio de código de programa. E as equipes de plataforma são mais propensas a ajudar seus desenvolvedores e equipes a usar a plataforma, com mais frequência para resolver seus problemas e incidentes relacionados à plataforma e para educar outras equipes.

Infraestrutura como código
Tudo é bastante normal aqui. Encontramos uma relação entre a automação do código de infraestrutura e quanta informação é armazenada dentro do repositório de infraestrutura. Comandos de alto perfil armazenam mais informações em repositórios: configuração de infraestrutura, pipeline de CI / CD, configurações de ambiente e parâmetros de construção. Eles armazenam essas informações com mais frequência, funcionam melhor com código de infraestrutura e automatizam mais processos e tarefas para trabalhar com código de infraestrutura.
Curiosamente, não vimos nenhuma diferença significativa nos testes de infraestrutura. Eu associo isso ao fato de que os comandos de perfil alto geralmente têm mais automação de teste. Talvez eles não devam ser distraídos separadamente por testes de infraestrutura, mas os testes que eles usam para verificar os aplicativos são suficientes e, graças a eles, eles já podem ver o que e onde eles quebraram.
Integração e entrega
A seção mais entediante porque confirmamos que quanto mais automação você tiver, melhor trabalhará com o código, maior será a probabilidade de obter as melhores métricas.
Arquitetura
Queríamos ver como os microsserviços afetam o desempenho. Na verdade, não, uma vez que a utilização de microsserviços não está associada ao aumento dos indicadores de desempenho. Os microsserviços são usados tanto pelos comandos de perfil alto quanto pelos comandos de perfil baixo.
Mas o que é significativo é que, para as equipes de alto nível, a transição para uma arquitetura de microsserviço permite que desenvolvam e implementem seus serviços de forma independente. Se a arquitetura permite que os desenvolvedores atuem de forma autônoma, sem esperar por alguém externo à equipe, então essa é uma competência chave para aumentar a velocidade. É aqui que os microsserviços ajudam. E apenas sua implementação não desempenha um grande papel.
Como encontramos tudo isso?
Tínhamos um plano ambicioso para replicar totalmente a metodologia DORA, mas faltavam recursos. Se a DORA usa muito patrocínio e a pesquisa leva meio ano, fizemos nossa pesquisa em pouco tempo. Queríamos construir um modelo DevOps como o DORA faz e faremos isso no futuro. Até agora, nos limitamos a mapas de calor:

examinamos a distribuição das práticas de engenharia entre as equipes de cada perfil e descobrimos que as equipes do perfil Alto, em média, usam as práticas de engenharia com mais frequência. Você pode ler mais sobre tudo isso em nosso relatório .
Para variar, vamos mudar de estatísticas complexas para estatísticas simples.
O que mais encontramos?
Ferramentas
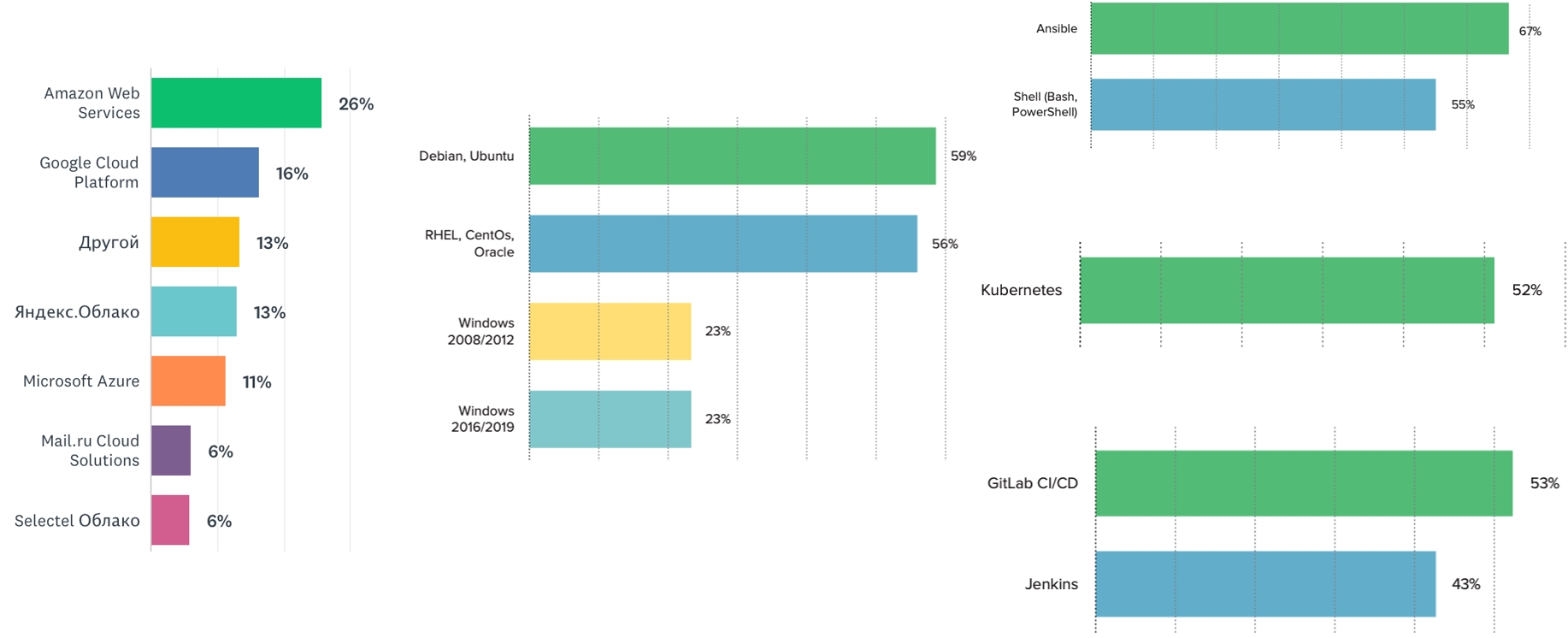
Observamos que grande parte das equipes utiliza o sistema operacional Linux. Mas o Windows ainda está em alta - pelo menos um quarto dos entrevistados observou o uso de uma ou outra versão dele. O mercado parece ter essa necessidade. Portanto, você pode desenvolver essas competências e fazer apresentações em conferências.
O Kubernetes é o líder entre os orquestradores (52%). O próximo orquestrador da fila é o Docker Swarm (cerca de 12%). Os sistemas de CI mais populares são Jenkins e GitLab. O sistema de gerenciamento de configuração mais popular é o Ansible, seguido por nosso amado Shell.
Entre a hospedagem em nuvem, a Amazon ainda está na liderança. A participação das nuvens russas está aumentando gradualmente. No ano que vem, será interessante ver como os provedores de nuvem russos se sentirão, se sua participação no mercado aumentar. São, você pode usar, e é bom:
passo a palavra para o Igor, que vai passar mais algumas estatísticas.
Disseminação de práticas
Igor Kurochkin: Separadamente, pedimos aos respondentes que indicassem como as práticas de engenharia consideradas são disseminadas na empresa. A maioria das empresas tem uma abordagem mista com um conjunto diferente de padrões, e os projetos-piloto são muito populares. Também vimos uma ligeira diferença entre os perfis. Representantes de alto perfil usam mais frequentemente o padrão “Iniciativa de baixo para cima”, quando pequenas equipes de especialistas mudam processos de trabalho, ferramentas e compartilham desenvolvimentos bem-sucedidos com outras equipes. No Medium, esta é uma iniciativa de cima para baixo que afeta toda a empresa, criando comunidades e centros de excelência:

Agile e DevOps
O relacionamento entre o Agile e o DevOps é um tópico importante na indústria. Essa questão também é levantada no Relatório do Estado do Agile de 2019/2020, então decidimos comparar como as atividades Agile e DevOps estão relacionadas nas empresas. Descobrimos que DevOps não Agile é raro. Para metade dos entrevistados, a disseminação do Agile começou muito antes, e cerca de 20% observaram um início simultâneo, e um dos sinais de baixo perfil será a ausência de práticas Agile e DevOps:

Topologias de comando
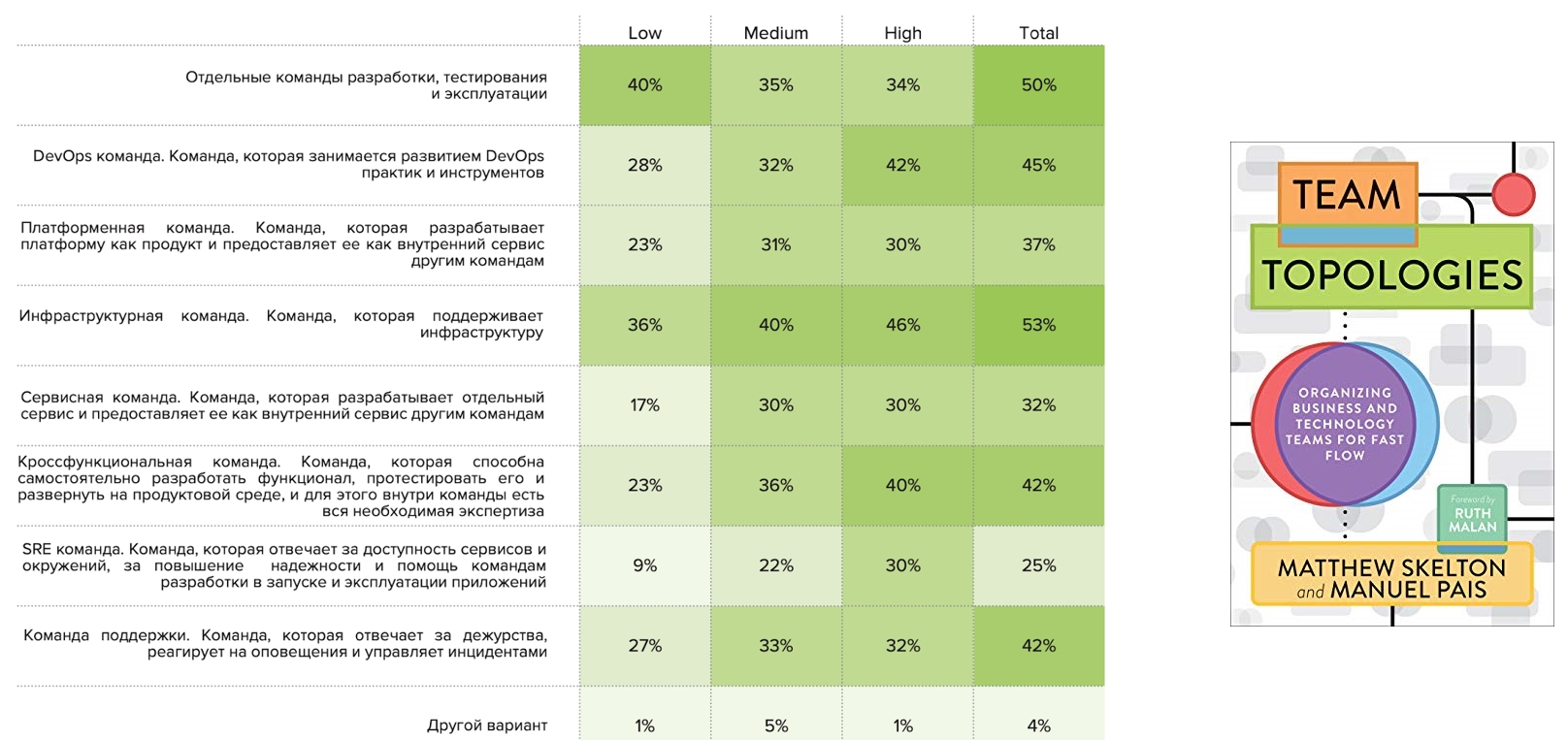
No final do ano passado, foi publicado o livro " Topologias de equipes ", que propunha um framework para a descrição de topologias de equipes. Ficamos imaginando se isso seria aplicável a empresas russas. E fizemos a pergunta: "Que padrões você encontra?"
As equipes de infraestrutura são observadas por metade dos entrevistados, bem como equipes separadas de desenvolvimento, teste e operação. As equipes individuais de DevOps foram observadas por 45%, entre as quais os representantes altos são mais comuns. Isso é seguido por equipes multifuncionais, que também são mais comuns para High. Comandos SRE separados aparecem nos perfis Alto e Médio e raramente aparecem no perfil Baixo:
Razão DevQaOps
Vimos essa pergunta no Facebook do líder da equipe da plataforma Skyeng - ele estava interessado na proporção de desenvolvedores, testadores e administradores nas empresas. Perguntamos e analisamos as respostas com base em perfis: os representantes do perfil Alto têm menos engenheiros de teste e operações por desenvolvedor:
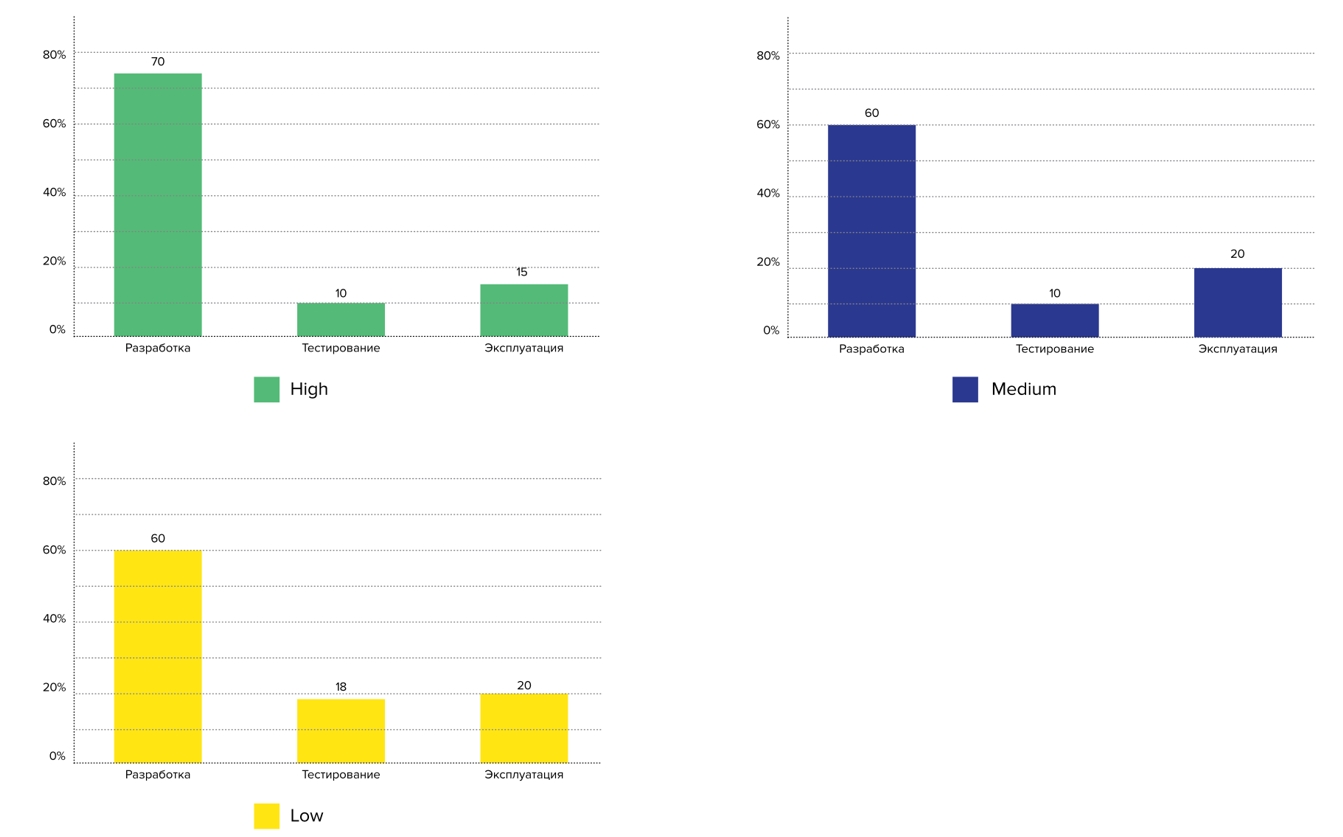
Planos para 2021
Em seus planos para o próximo ano, os entrevistados observaram as seguintes atividades:

Aqui você pode ver a interseção com a conferência DevOps Live 2020. Revisamos cuidadosamente o programa:
- Infraestrutura como produto
- Transformação DevOps
- Divulgando as práticas DevOps
- DevSecOps
- Clubes de casos e discussões
Mas nosso discurso não será tempo suficiente para considerar todos os tópicos. Deixados nos bastidores:
- Plataforma como serviço e como produto;
- Infraestrutura como código, ambientes e nuvens;
- Integração e entrega contínuas;
- Arquitetura;
- Padrões DevSecOps;
- Plataformas e equipes multifuncionais.
Nosso relatório acabou sendo volumoso, com 50 páginas, e você pode vê-lo em mais detalhes.
Resumindo
Esperamos que nossa pesquisa e relatório o inspirem a experimentar novas abordagens de desenvolvimento, teste e operações, além de ajudá-lo a navegar, comparar-se com outros participantes da pesquisa e identificar áreas onde você pode melhorar suas próprias abordagens.
Resultados da primeira pesquisa sobre o estado do DevOps na Rússia:
- Principais métricas. Descobrimos que as principais métricas (tempo de espera, frequência de implantação, tempo de recuperação e mudanças malsucedidas) são apropriadas para analisar a eficácia do desenvolvimento, teste e operações.
- High, Medium, Low. High, Medium, Low , , . High , Low. .
- , 2021 . , . High , , .
- Práticas de DevOps, ferramentas e seu desenvolvimento. Os principais planos das empresas para o próximo ano incluem o desenvolvimento de práticas e ferramentas DevOps, a introdução de práticas DevSecOps e uma mudança na estrutura organizacional. E a efetiva implantação e desenvolvimento das práticas de DevOps se dá por meio de projetos pilotos, formação de comunidades e centros de excelência, iniciativas nos níveis superior e inferior da empresa.
Teremos o maior prazer em ouvir seus comentários, histórias, comentários. Obrigado a todos que participaram do estudo e esperamos sua participação no próximo ano.