
Fonte da imagem
Duas revoluções no processamento de linguagem natural
A primeira revolução na PNL foi associada ao sucesso de modelos baseados em representações vetoriais da semântica de uma língua, obtidos por meio de métodos de aprendizagem não supervisionados. O florescimento desses modelos começou com a publicação dos resultados de Tomáš Mikolov , estudante de doutorado Yoshua Bengio (um dos fundadores da aprendizagem profunda moderna, laureado com o Prêmio Turing) e o surgimento da popular ferramenta word2vec. A segunda revolução começou com o desenvolvimento de mecanismos de atenção em redes neurais recorrentes, o que resultou no entendimento de que o mecanismo de atenção é autossuficiente e poderia muito bem ser usado sem a própria rede recorrente. O modelo de rede neural resultante é chamado de "transformador". Ele foi apresentado à comunidade científica em 2017 em um artigo intitulado “Attention Is All You Need ”, escrito por um grupo de pesquisadores do Google Brain e Google Research. O rápido desenvolvimento de redes baseadas em transformadores resultou em modelos de linguagem gigantes como o Generative Pre- Training Transformer 3 (GPT-3) da OpenAIcapaz de resolver muitos problemas de PNL com eficiência.
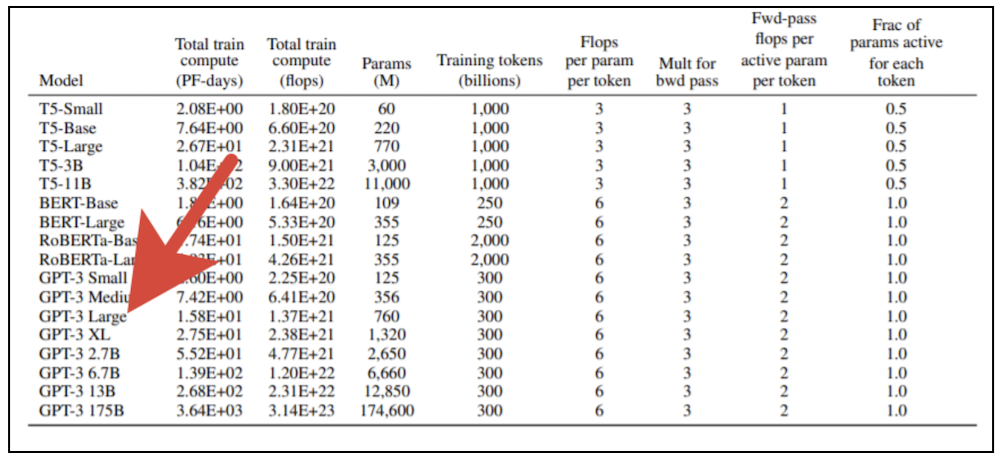
O treinamento de modelos de transformadores gigantes requer recursos computacionais significativos. Você não pode simplesmente pegar uma placa gráfica moderna e treinar tal modelo em seu computador doméstico. A publicação original da OpenAI apresenta 8 variantes do modelo, e se você pegar a menor delas (GPT-3 Small) com 125 milhões de parâmetros e tentar treiná-la usando uma placa de vídeo profissional NVidia V100 equipada com poderosos núcleos tensores, levará cerca de seis meses. Se pegarmos a maior versão do modelo com 175 bilhões de parâmetros, o resultado terá que esperar quase 500 anos. O custo de treinar a maior versão do modelo com as taxas de serviços em nuvem que fornecem dispositivos de computação modernos para aluguel,excede um bilhão de rublos (e isso ainda está sujeito à escala de desempenho linear com um aumento no número de processadores envolvidos, o que é em princípio inatingível).
Vida longa aos supercomputadores!
É claro que tais experimentos estão disponíveis apenas para empresas com recursos computacionais significativos. Para resolver tais problemas, em 2019 o Sberbank colocou em operação o supercomputador Christophari , que ocupou o primeiro lugar em termos de desempenho entre os supercomputadores disponíveis em nosso país. 75 nós de computação DGX-2 (cada um com 16 placas NVidia V100 ) conectados por um barramento ultrarrápido baseado na tecnologia Infinibandpermitem que você treine GPT-3 Small em apenas algumas horas. Porém, mesmo para tal máquina, a tarefa de treinar versões maiores do modelo não é trivial. Em primeiro lugar, parte da máquina está ocupada com o treinamento de outros modelos projetados para resolver problemas no campo da visão computacional, reconhecimento e síntese de voz e muitas outras áreas de interesse para várias empresas do ecossistema Sberbank. Em segundo lugar, o próprio processo de aprendizagem, que usa simultaneamente muitos nós computacionais em uma situação em que os pesos do modelo não cabem na memória de um cartão, é bastante fora do padrão.
Em geral, nos encontramos em uma situação em que a tocha. Distribuída, conhecida por muitos, não era adequada para nossos propósitos. Não tínhamos tantas opções, como resultado optamos pela implementação "nativa" para NVidia Megatron-LMe a nova ideia da Microsoft - DeepSpeed , que exigia a criação de contêineres docker personalizados no Christophari, com o qual nossos colegas da SberCloud nos ajudaram prontamente . DeepSpeed, em primeiro lugar, nos deu ferramentas convenientes para o treinamento paralelo de modelos, ou seja, espalhar um modelo em várias GPUs e fragmentar o otimizador entre as GPUs. Isso permite que você use lotes maiores, bem como modelos de trem com mais de 1,5 bilhão de pesos sem uma montanha de código adicional.
Surpreendentemente, a tecnologia do último meio século em seu desenvolvimento descreveu a próxima rodada da espiral - parece que a era dos mainframes (computadores poderosos com acesso de terminal) está voltando. Já estamos acostumados com o fato de que as principais ferramentas de desenvolvimento são um computador pessoal alocado para uso exclusivo do desenvolvedor. No final dos anos 1960 e início dos 1970, uma hora de operação do mainframe custava quase o mesmo que o salário de um mês inteiro para um operador de computador! Parecia que esses tempos haviam acabado para sempre e o "ferro" ficou para sempre mais barato do que o tempo de trabalho. No entanto, parece que o hardware fez um retorno impressionante. A vida cotidiana de um especialista em aprendizado de máquina moderno mais uma vez se assemelha à vida cotidiana de Sasha Privalov da história dos irmãos Strugatsky "Segunda-feira começa no sábado", com a única diferença de que o lugar de "Aldan" em nosso caso é ocupado por "Christofari", e o papel da magia e feitiçaria é realizado por métodos de aprendizado profundo.
Da experiência SberDevices
Muitas vezes, no passado, tivemos que aprender outros modelos baseados em transformadores - esses são vários herdeiros de BERT e modelos de codificador-decodificador, como o T5 do Google . Assistentes virtuais criados por SberDevices para várias superfícies, começando com o SberBox e SberPortal mais recentese terminando com o conhecido aplicativo Sberbank Online, eles usam vários modelos semelhantes em seu trabalho para resolver vários problemas durante a comunicação com o usuário. Por exemplo, o assistente virtual Joy usa o modelo GPT-2 Medium no modo de bate-papo, treinado em um grande corpus da literatura russa, treinado em um conjunto de dados de diálogo especial e equipado com um mecanismo de classificação especial projetado para selecionar as respostas mais interessantes. Tais modelos são capazes de conduzir uma conversa com o usuário, não escolhendo pistas de uma biblioteca de respostas pré-preparada, mas fazendo suas próprias frases “na hora”, o que torna a comunicação com ele mais variada e divertida.
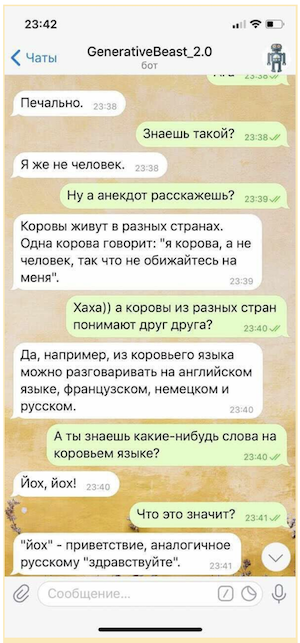

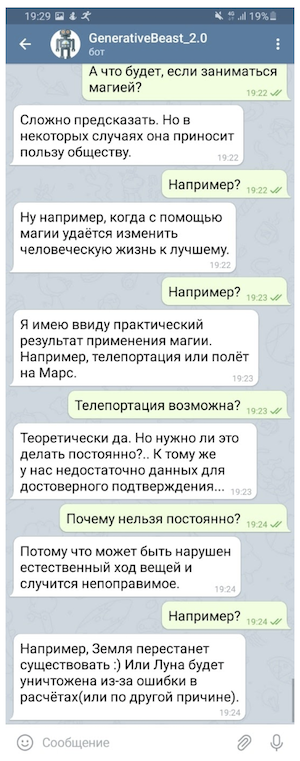
Claro, tal "tagarelice" não pode ser usado sem algum seguro na forma de um sistema de microintentes (regras criadas para fornecer respostas controladas a algumas das questões mais sensíveis) e um modelo separado projetado para evitar questões provocativas, mas mesmo de forma limitada A "tagarelice" "generativa" é capaz de elevar significativamente o humor de seu interlocutor.
Em suma, nossa experiência no ensino de grandes modelos de transformadores foi útil quando a administração do Sberbank decidiu alocar recursos de computação para um projeto de pesquisa para treinar o GPT-3. Esse projeto exigia combinar os esforços de várias unidades ao mesmo tempo. Por parte da SberDevices, o papel de liderança neste processo foi assumido pelo Departamento de Sistemas Experimentais de Aprendizagem de Máquina (com a participação de vários especialistas de outras equipas) e por parte da Sberbank.AI - pela equipa AGI PNL . Nossos colegas de SberCloud, que apóiam Christophari, também se juntaram ativamente ao projeto.
Juntamente com colegas da equipe AGI PNL, conseguimos montar a primeira versão do corpus de treinamento em língua russa com um volume total de mais de 600 GB. Inclui uma enorme coleção de literatura russa, instantâneos da Wikipedia em russo e inglês, uma coleção de instantâneos de sites de notícias e perguntas e respostas , seções públicas de Pikabu , uma coleção completa de materiais do popular portal de ciência 22century.ru e do portal bancário banki.ru , bem como o Omnia Russica corpus . Além disso, como queríamos experimentar a capacidade de manipular o código do programa, incluímos instantâneos do github e StackOverflow no corpus de treinamento.... A equipe de PNL da AGI fez muita limpeza e desduplicação de dados, bem como preparou os kits de validação e teste do modelo. Se no corpus original usado pelo OpenAI, a proporção de inglês para outras línguas é 93: 7, então, em nosso caso, a proporção de russo para outras línguas é de aproximadamente 9: 1.
Escolhemos as arquiteturas GPT-3 Medium (350 milhões de parâmetros) e GPT-3 Large (760 milhões de parâmetros) como base para os primeiros experimentos. Ao fazer isso, treinamos o modelo com blocos de transformador alternados com uma esparsae mecanismos e modelos de atenção densos nos quais todos os bloqueios de atenção foram concluídos. O fato é que o trabalho original da OpenAI fala sobre blocos de intercalação, mas não fornece sua sequência específica. Se todos os blocos de atenção no modelo estiverem completos, isso aumenta o custo computacional do treinamento, mas garante que o potencial preditivo do modelo seja totalmente explorado. Atualmente, a comunidade científica está estudando ativamente vários modelos de atenção, projetados para reduzir os custos computacionais de modelos de treinamento e aumentar a precisão. Em pouco tempo, os pesquisadores propuseram um transformador longo , um reformador , um transformador com capacidade de atenção adaptativa., Transformador de compressão [transformador compressivo] , transformador ENBLOCK [transformador blockwise ] , BigBird , transformador com complexidade linear [linformer] e vários outros modelos semelhantes. Também estamos engajados em pesquisas nessa área, enquanto modelos compostos apenas por blocos densos são uma espécie de benchmark que nos permite avaliar o grau de diminuição na precisão de várias versões "aceleradas" do modelo.
Competição "AI 4 Humanidades: ruGPT-3"
Este ano, no âmbito do AI Journey, a equipa Sberbank.AI organizou a competição AI 4 Humanities: ruGPT-3. Como parte do teste geral, os participantes são convidados a enviar protótipos de soluções para qualquer problema empresarial ou social criado usando o modelo pré-treinado ruGPT-3. Os participantes da nomeação especial "AIJ Junior" são convidados a criar uma solução para gerar ensaios significativos em quatro disciplinas humanitárias (idioma russo, história, literatura, estudos sociais) da 11ª série (USE) com base no ruGPT-3 com base no ruGPT-3 para um determinado tópico / texto da tarefa.
Especialmente para essas competições, treinamos três versões do modelo GPT-3: 1) GPT-3 Médio, 2) GPT-3 Grande com alternância de blocos esparsos e densos do transformador, 3) o mais "poderoso" GPT-3 Grande, composto por apenas blocos densos. Os conjuntos de dados de treinamento e tokenizers são idênticos para todos os modelos - o tokenizer BBPE e nosso conjunto de dados Large1 personalizado com um volume de 600 GB foram usados (sua composição é fornecida no texto acima).
Todos os três modelos estão disponíveis para download no repositório da competição.
Aqui estão alguns exemplos divertidos de como o terceiro modelo funciona:



Como modelos como o GPT-3 mudarão nosso mundo?
É importante entender que modelos como o GPT-1/2/3, na verdade, resolvem exatamente um problema - eles tentam prever o próximo token (geralmente uma palavra ou parte dele) na sequência dos anteriores. Essa abordagem possibilita o uso de dados “não rotulados” para treinamento, ou seja, dispensa o envolvimento de um “professor” e, por outro lado, permite solucionar uma gama bastante ampla de problemas da área de PNL. De fato, no texto de um diálogo, por exemplo, uma resposta-resposta é uma continuação da história da comunicação, em uma obra de ficção - o texto de cada parágrafo continua o texto anterior, e em uma sessão de perguntas e respostas o texto da resposta segue o texto da pergunta. Como resultado, os modelos de grande capacidade podem resolver muitos desses problemas sem treinamento adicional especial - eles só precisam de exemplos que se encaixem no "contexto do modelo"que o GPT-3 tem bastante impressionante - até 2.048 tokens.
GPT-3 é capaz não só de gerar textos (incluindo poemas, piadas e paródias literárias), mas também de corrigir erros gramaticais, conduzir diálogos e até mesmo (FORA DO ESTADO!) Escrever códigos de programas mais ou menos significativos. Muitos usos interessantes do GPT-3 podem ser encontrados no site do pesquisador independente Gwern Branwen. Branuen, desenvolvendo uma ideia expressa em um tweet de brincadeira de Andrej Karpathy, faz uma pergunta interessante: estamos testemunhando o surgimento de um novo paradigma de programação?
Aqui está o texto do tweet original de Karpaty:
“Adoro a ideia do Software 3.0. A programação vai da preparação de conjuntos de dados para a preparação de consultas que permitem ao sistema de meta-aprendizado "entender" a essência da tarefa que precisa executar. LOL "[Adorei a ideia para o Software 3.0. A programação passando de conjuntos de dados de curadoria para prompts de curadoria para fazer o meta-aluno "pegar" a tarefa que deveria estar fazendo. RI MUITO].
Desenvolvendo a ideia de Karpaty, Branuen escreve:
« GPT-3 [ ] , : , , , ( GPT-2); , , , [prompt], , , «» - , , . , , «» «», GPT-3 . « » , : , , , , , , , , , ».
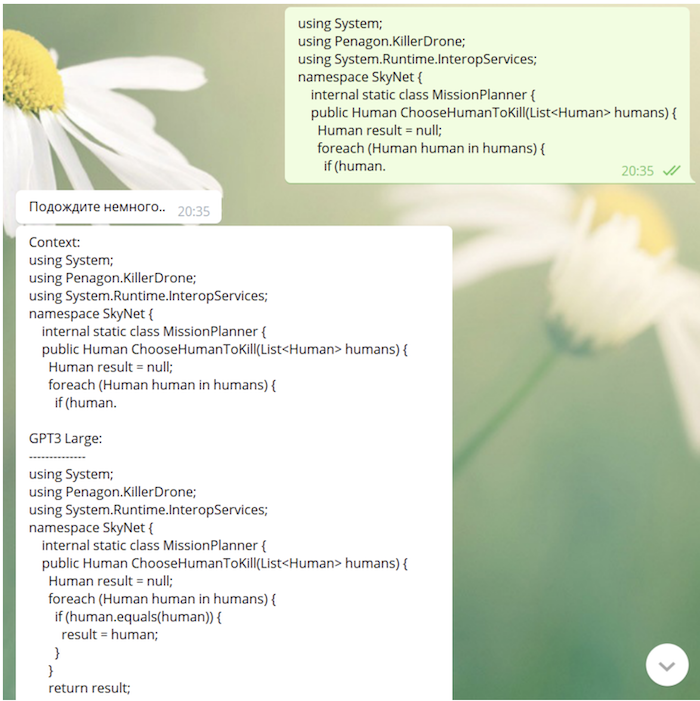
Como nosso modelo "viu" github e StackOverflow no processo de aprendizagem, ele é perfeitamente capaz de escrever código (às vezes não desprovido de um significado muito profundo):
Qual é o próximo
Este ano, continuaremos trabalhando em modelos de transformadores gigantes. Planos adicionais estão relacionados à expansão e limpeza de conjuntos de dados (eles, em particular, incluirão instantâneos do serviço de pré-impressão arxiv.org para publicações científicas e a biblioteca de pesquisa PubMed Central, conjuntos de dados de diálogo especializados e conjuntos de dados em lógica simbólica), aumentando o tamanho dos modelos treinados, bem como usando tokenizer aprimorado.
Esperamos que a publicação de modelos treinados estimule o trabalho de pesquisadores e desenvolvedores russos que precisam de modelos de linguagem superpoderosos, porque com base no ruGPT-3 você pode criar seus próprios produtos originais, resolver vários problemas científicos e de negócios. Experimente usar nossos modelos, experimente com eles e certifique-se de compartilhar todos os resultados que você obter. O progresso científico torna nosso mundo melhor e mais interessante, vamos melhorar o mundo juntos!