Constato com pesar que Libra (ESTE SOU EU!) Está em último lugar ... Embora, de acordo com os dados, me pareça haver anomalias. De alguma forma, o pequeno Libra!
Parte 1. Análise e obtenção de dados iniciais
Wikipedia Lista de listas de listas
na saída você precisa de uma base com nome completo + data de nascimento + (se houver quaisquer outros sinais - por exemplo, m / f, país, etc.) há uma API .
Conseguimos raspar este site (coletando / obtendo / extraindo (extraindo) / coletando dados obtidos de recursos da web) usando a biblioteca Python Scrapy.
Instruções detalhadas
primeiro obtêm links (folhas com pessoas da Wikipedia e, em seguida, dados).
Em outros casos, eles analisado com êxito como este .
Resultado: arquivo BD wiki.zip
Parte 2. Sobre o pré-processamento (por Stanislav Kostenkov - contatos abaixo)
Muitas pessoas enfrentam a complexidade do processamento de dados de entrada. Portanto, nessa tarefa foi necessário retirar dados de nascimento de mais de 42 mil artigos e, se possível, determinar o país de nascimento. Por um lado, trata-se de uma tarefa algorítmica simples, por outro lado, as ferramentas dos sistemas Excel e BI não permitem que seja feita "de frente".
Nesse momento, as linguagens de programação (Python, R) vêm em socorro, cujo lançamento é fornecido na maioria dos sistemas de BI. Vale ressaltar que, por exemplo, no Power BI existe um limite de 30 minutos para a execução de um script (programa) em Python. Portanto, muitos processamentos "pesados" são feitos antes do lançamento de sistemas de BI, por exemplo, em um data lake.
Como o problema foi resolvido
A primeira coisa que fiz depois de carregar e verificar os valores inválidos foi transformar cada artigo em uma lista de palavras.
Nessa tarefa, tive sorte com o idioma inglês. Essa linguagem é caracterizada por uma forma rígida de construção da frase, o que facilitou muito a busca pela data de nascimento. A palavra-chave aqui é "nascer", então ela olha e analisa o que vem depois.
Por outro lado, todos os artigos foram retirados de uma fonte, o que também facilitou a tarefa. Todos os artigos tiveram aproximadamente a mesma estrutura e velocidade.
Além disso, todos os anos tinham 4 caracteres, todas as datas tinham 1–2 caracteres e os meses eram textuais. Havia apenas 3-4 variações possíveis na grafia da data de nascimento, o que foi resolvido por uma lógica simples. Também pode ser analisado por meio de expressões regulares.
O código real não está otimizado (tal tarefa não foi definida, talvez haja falhas nos nomes das variáveis).
Conforme previsto pelo país, tive a sorte de encontrar uma tabela de correspondências de países e nacionalidades. Normalmente, os artigos não descrevem o país, mas sim pertencer a ele. Por exemplo, a Rússia - russo. Portanto, buscamos ocorrências de nacionalidades, mas como poderia haver mais de 5 nacionalidades diferentes em um artigo, fiz a hipótese de que a palavra desejada seria o mais próximo possível da palavra-chave "queimar". Assim, o critério foi - o índice mínimo de distância entre as palavras necessárias no artigo. Em seguida, em uma linha foi renomeado de nacionalidade para país.
O que não foi feito
Nos artigos, muitas palavras continham lixo, ou seja, algum fragmento do código foi conectado à palavra, ou duas palavras foram mescladas. Portanto, não foi verificada a probabilidade de se encontrar os valores desejados em tais palavras. Você pode limpar essas palavras usando algoritmos de similaridade.
As entidades às quais pertence a palavra-chave "queimar" não foram analisadas. Houve vários exemplos em que a palavra-chave estava relacionada ao nascimento de parentes. Esses exemplos foram insignificantes. Esses exemplos podem ser rastreados até o fato de que a palavra-chave está longe do início do artigo. Você pode calcular os percentis de localização de uma palavra-chave e determinar o critério de recorte.
Algumas palavras sobre a utilidade do pré-processamento ao limpar dados
Existem casos comuns em que podemos adivinhar exatamente o que deve ser colocado no lugar das lacunas. Mas há casos, por exemplo, em que há omissões com base no sexo do comprador de uma loja e há dados sobre suas compras. Não existem técnicas padronizadas para resolver este problema em sistemas de BI, mas ao mesmo tempo, no nível de pré-processamento, você pode criar um modelo "leve" e ver várias opções para preencher as lacunas. Existem opções de preenchimento baseadas em algoritmos simples de aprendizado de máquina. E vale a pena usar. Não é difícil.
O código-fonte (Python) está disponível no link
Resultado: arquivo out_data_fin.xls
Stanislav Kostenkov / CBS Consulting (Izhevsk, Rússia) staskostenkov@gmail.com
Parte 3. Aplicativo Qlik Sense
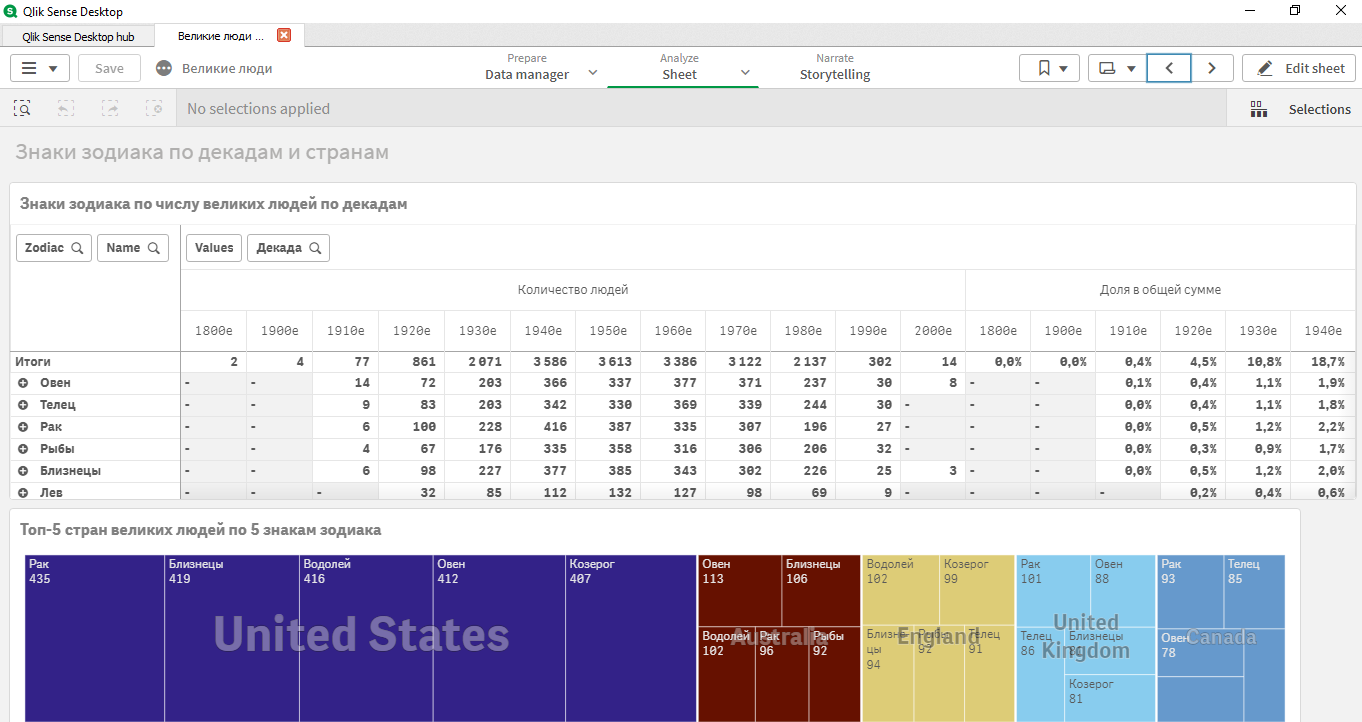
Em seguida, um aplicativo clássico foi feito, onde algumas anomalias com o conjunto de dados foram reveladas:
- fazia sentido escolher apenas décadas de 1920-1980;
- em diferentes países, havia diferentes líderes de acordo com os signos do horóscopo;
- signos superiores: Câncer, Áries, Gêmeos, Touro, Capricórnio.
Todos os dados (conjunto de dados, dados brutos, recebidos pelo aplicativo Qlik Sense para análise de dados) são localizados por referência .