
Um caminho espinhoso e difícil de quem encontrou o FSIS USRN Rosreestr. Ele está esperando uma espera sem fim para o navegador carregar, chaves, captchas, intervalos entre solicitações de 5 minutos. Por que ele sofreria tanto? Ele já havia contribuído com seu próprio dinheiro quando decidiu trabalhar com este sistema e solicitar seus extratos. Mas não - conseguir um extrato da USRN é como tirar a cebola. A última etapa que espera o sofredor - o extrato baixado e cobiçado é representado por um arquivo zip, no qual, um, outro arquivo e um arquivo sig. E já dentro está o próprio arquivo de instrução. Mas também não é fácil de ler - está em xml. E para que tudo cresça junto, acaba sendo necessário baixar este xml junto com a assinatura de uma página especial do Rosreestr. E lá, ainda há um captcha esperando. E assim com cada afirmação! Vamos superar essa última dor hoje usando python.
Tarefa:
- descompacte todo o zip na pasta,
- download por especificação. link para Rosreestr,
- finalmente baixe!, uma visão legível da declaração.
Portanto, inicialmente na pasta, são baixados os arquivos zip dos extratos:
Após importar os módulos Python:
import os
import zipfile
import webbrowser,time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
Vamos descompactar todos os arquivos zip e excluí-los para que não se confundam com o conteúdo:
zipFiles = []
sigFiles = []
for filename in os.listdir('.'):
if filename.endswith('.zip'):
zipfile.ZipFile(filename, 'r').extractall()
os.remove(filename)
Temos arquivos zip e arquivos sig para eles, que serão carregados no site da Rosreestr:
Vá para o loop principal do programa para todos os arquivos do diretório (no meu caso, "C: / 2"):
for filename in zipFiles:
act = browser.find_element_by_id('sig_file')
act.send_keys('C:\\2\\'+str(filename)+'.sig')
act = browser.find_element_by_id('xml_file')
# zip
zip_ref = zipfile.ZipFile(filename, 'r').extractall()
# xml
for f in os.listdir('.'):
if f.endswith('.xml'):
print(f)
# xml
act.send_keys('C:\\2\\'+str(f))
act = browser.find_element_by_css_selector('input.brdg1111')
act.click()
i = str(input(" : "))
for b in i:
act.send_keys(b)
time.sleep (0.1)
#act.submit()
act = browser.find_element_by_css_selector('.terminal-button-bright')
act.click()
time.sleep (5)
try:
act = browser.find_element_by_link_text(' ')
act.click()
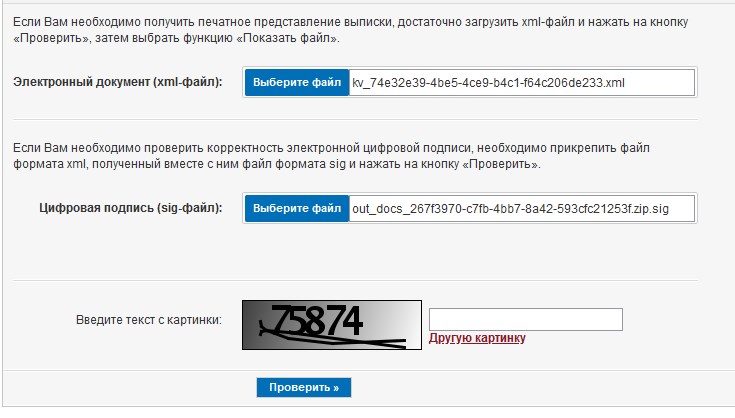
Após o carregamento bem-sucedido da página do portal Rosreestr , rosreestr.gov.ru/wps/portal/cc_vizualisation , o programa encontrará o arquivo zip no diretório, obterá o arquivo de instrução xml de lá e inserirá no campo obrigatório no site. O programa fará o mesmo com o arquivo sig anexado ao xml:
Em seguida, o programa aguardará a entrada do captcha:
Após o usuário inserir o captcha, ele o enviará ao site e clicará no link de download do já "normal" extrato do USRN:
Será aberta uma janela na qual o extrair, que pode ser salvo em html ou pressionando CTRL + P no Chrome - em pdf.
Resta adicionar captcha de solução automática e download automático de extratos legíveis por humanos. Mas essa é a coisa mais simples aqui, não é?
O código do programa está aqui .