Continuamos uma série de artigos sobre moderação de conteúdo nos sites do Financial Technologies Development Centre do Russian Agricultural Bank. No último artigo, falamos sobre como resolvemos o problema de moderação de texto para um dos sites do ecossistema para agricultores "Agricultura Própria" . Você pode ler um pouco sobre o próprio site e qual o resultado que obtivemos aqui .
Resumindo, usamos um ensemble de um classificador ingênuo (filtro por dicionário) e BERT. Os textos que passaram pelo filtro do dicionário foram autorizados a entrar no BERT, onde também foram verificados.
E nós, juntamente com o Laboratório MIPT, continuamos a melhorar o nosso site, colocando-nos uma tarefa mais difícil de pré-moderação da informação gráfica. Esta tarefa se mostrou mais difícil que a anterior, pois ao processar uma linguagem natural, pode-se dispensar o uso de modelos de redes neurais. Com imagens, tudo é mais complicado - a maioria das tarefas são resolvidas usando redes neurais e a seleção de sua arquitetura correta. Mas nesta tarefa, ao que parece, temos lidado bem! E o que obtivemos com isso, continue lendo.

O que nós queremos?
Então vamos! Vamos definir imediatamente o que deve ser uma ferramenta de moderação de imagens. Por analogia com a ferramenta de moderação de texto, esta deve ser uma espécie de "caixa preta". Ao enviar uma imagem enviada ao site por vendedores de mercadorias como entrada, gostaríamos de entender como essa imagem é aceitável para publicação no site. Assim, ficamos com a tarefa: determinar se a imagem é adequada para publicação no site ou não.
A tarefa de pré-moderação de imagens é comum, mas a solução muitas vezes difere de site para site. Portanto, imagens de órgãos internos podem ser aceitáveis para fóruns médicos, mas não adequadas para mídia social. Ou, por exemplo, imagens de carcaças de animais cortadas são aceitáveis em um site onde são vendidas, mas dificilmente serão apreciadas por crianças que vão online para assistir Smesharikov. Quanto ao nosso site, imagens de produtos agrícolas (vegetais / frutas, ração animal, fertilizantes, etc.) seriam aceitáveis para ele. Por outro lado, é óbvio que o tema do nosso marketplace não implica a presença de imagens com conteúdos obscenos ou ofensivos diversos.
Para começar, decidimos conhecer as soluções já conhecidas para o problema e tentar adaptá-las ao nosso site. Como regra, muitas tarefas de moderação de conteúdo gráfico são reduzidas à resolução de problemas da classe NSFW , para a qual existe um conjunto de dados disponível publicamente.
Para resolver tarefas NSFW, via de regra, são utilizados classificadores baseados em ResNet, que apresentam acurácia de qualidade> 93%.
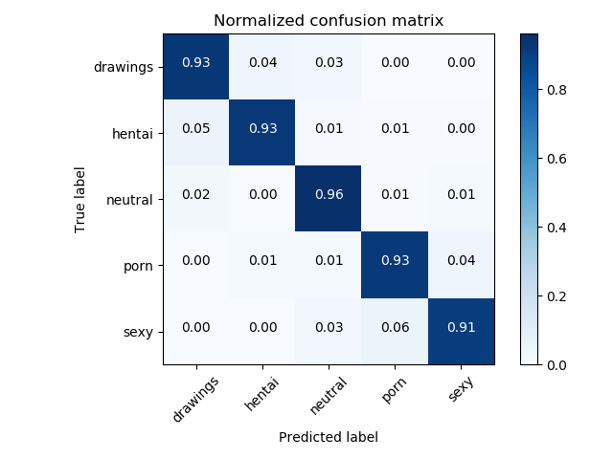
Matriz de erro do classificador NSFW original
Ok, digamos que temos um bom modelo e um conjunto de dados pronto para NSFW, mas isso será o suficiente para determinar a aceitabilidade da imagem para o site? Descobriu-se que não. Depois de discutir essa abordagem inicial com o modelo NSFW com os proprietários de nossos sites, percebemos que precisamos definir um pouco mais de categorias, a saber:
- ( , )
- ( , , , . )
- ( )
Ou seja, ainda tínhamos que compor nosso próprio conjunto de dados e pensar sobre o que outros modelos poderiam ser úteis.
É aqui que encontramos um problema comum de aprendizado de máquina: falta de dados. É devido ao fato de nosso site ter sido criado há pouco tempo, e não haver exemplos negativos nele, ou seja, marcado como inaceitável. Para resolvê-lo, o método de aprendizagem de poucas tentativas vem em nosso auxílio . A essência desse método é que podemos treinar novamente, por exemplo, ResNet em pequenos conjuntos de dados que montamos e obter uma precisão maior do que se fizéssemos um classificador do zero e usando apenas nosso pequeno conjunto de dados.
Como você fez isso?
Abaixo está um esquema geral de nossa solução, começando com a imagem de entrada e terminando com o resultado da detecção de várias categorias, se uma imagem de maçã for alimentada para a entrada.

Esquema geral da solução
Vamos considerar cada parte do esquema com mais detalhes.
Estágio 1: detector de Graffiti
Esperamos que mercadorias com texto nas embalagens sejam carregadas em nosso site e, portanto, surge a tarefa de detectar inscrições e identificar seu significado.
No primeiro estágio, usamos a biblioteca OpenCV Text Detection para encontrar os rótulos dos pacotes.
OpenCV Text Detection é uma ferramenta de reconhecimento óptico de caracteres (OCR) para Python. Ou seja, ele reconhece e "lê" textos embutidos em imagens.

Exemplo de operação do detector EAST
Você pode ver um exemplo de detecção de inscrições na foto. Para identificar a caixa delimitadora, usamos o modelo EAST, mas aqui o leitor pode sentir uma pegadinha, já que esse modelo é treinado para reconhecer textos em inglês, e em nossas imagens os textos são em russo. Por isso, ainda, é utilizado um modelo de classificação binária (graffiti / não graffiti) baseado no ResNet, que foi treinado para a qualidade exigida em nossos dados. Escolhemos o ResNet-18, pois este modelo provou ser o melhor na escolha de uma arquitetura.
Em nossa tarefa, gostaríamos de distinguir fotos em que as inscrições são inscrições na embalagem de produtos de graffiti. Portanto, decidimos dividir todas as fotos com texto em duas classes: graffiti e não graffiti. A
precisão do modelo obtido foi de 95% em uma amostra pré-diferida:
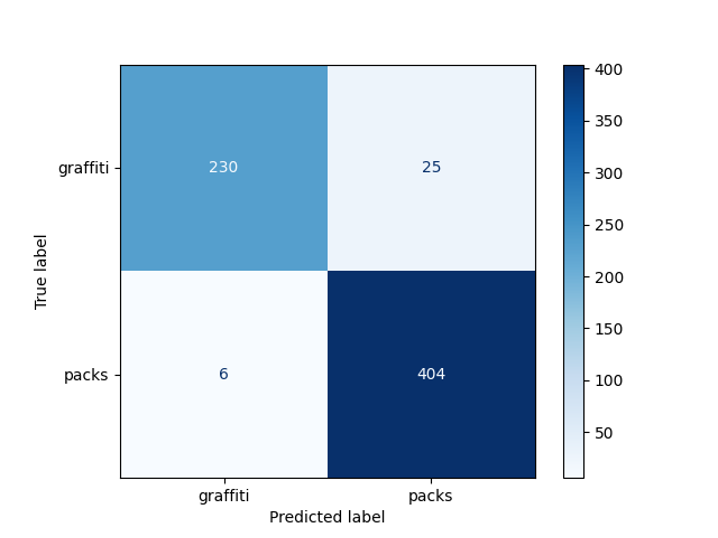
Graffiti Detector Bug Matrix
Nada mal! Agora podemos isolar o texto na foto e com boa probabilidade entender se é adequado para publicação. Mas e se não houver texto na foto?
Estágio 2: detector NSFW
Se não encontramos texto na imagem, isso não significa que seja inaceitável, portanto, queremos ainda avaliar como o conteúdo da imagem corresponde ao tema do site.
Nesta fase, a tarefa é atribuir a imagem a uma das categorias:
- drogas
- porn (porn)
- animais
- fotos que podem causar rejeição (incluindo desenhos) (gore / drawing_gore)
- hentai (hentai)
- imagens neutras (neutras)
É importante que o modelo retorne não apenas a categoria, mas também o grau de confiança dos algoritmos nela.
Um modelo baseado em NSFW foi usado para classificação. Ela é treinada de tal forma que divide a foto em 7 classes e apenas uma delas esperamos ver no site. Portanto, deixamos apenas fotos neutras.
O resultado de tal modelo é 97% (em termos de precisão) da

matriz de erro do detector NSFW
Estágio 3: detector de pessoa
Mas mesmo depois de aprendermos como filtrar NSFW, o problema ainda não pode ser considerado resolvido. Por exemplo, a foto de uma pessoa não se enquadra na categoria NSFW nem na categoria foto com texto, mas também não gostaríamos de ver essas imagens no site. Em seguida, adicionamos à nossa arquitetura um modelo de detecção humana - Single Shot Detector (doravante denominado SSD).
Selecionar pessoas ou algum outro objeto conhecido anteriormente também é uma tarefa popular com uma ampla gama de aplicações. Usamos o modelo nvidia_ssd pronto da pytorch.

Um exemplo do algoritmo SSD
Os resultados do modelo são inferiores (precisão - 96%):

Matriz de erro do detector humano
resultados
Avaliamos a qualidade do nosso instrumento usando métricas ponderadas de F1, Precisão e Recall. Os resultados são apresentados na tabela:
| Métricas | Precisão obtida |
| F1 ponderado | 0,96 |
| Precisão Ponderada | 0,96 |
| Rechamada Ponderada | 0,96 |
E aqui estão alguns exemplos mais ilustrativos de seu trabalho:
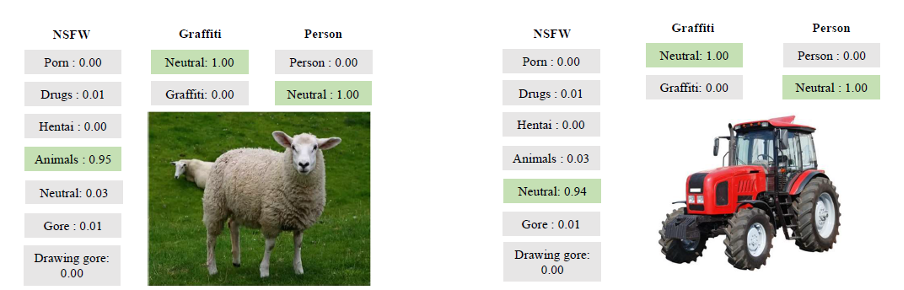
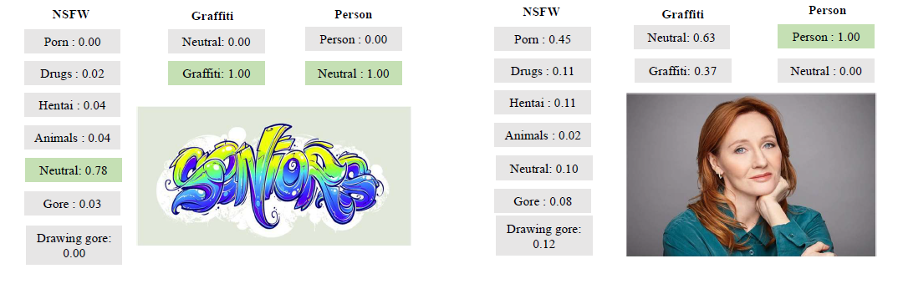
Exemplos da ferramenta
Conclusão
No processo de resolução, usamos todo um "zoológico" de modelos que costumam ser usados para tarefas de visão computacional. Aprendemos a “ler” texto de fotos, encontrar pessoas e distinguir conteúdo impróprio.
Por último, gostaria de observar que o problema considerado é útil do ponto de vista de ganhar experiência e usar modelos clássicos modificados. Aqui estão alguns dos insights que obtivemos:
- Você pode contornar o problema de escassez de dados usando o método de aprendizado de poucos instantes: modelos grandes podem ser treinados com a precisão necessária em seus próprios dados
- : ,
- , ,
- , , . , , ,
- Apesar de a tarefa de moderação de imagens ser bastante popular, a sua solução, como no caso dos textos, pode diferir de site para site, visto que cada um deles se destina a um público diferente. No nosso caso, por exemplo, nós, além de conteúdo impróprio, também detectamos animais e pessoas
Obrigado pela atenção e até o próximo artigo!