Hoje temos uma conversa física e técnica com Mikhail Burtsev , chefe do laboratório de redes neurais do MIPT. Seus interesses de pesquisa incluem modelos de aprendizagem de redes neurais, sistemas neurocognitivos e neuro-híbridos, evolução de sistemas adaptativos e algoritmos evolutivos, neurocontroladores e robótica. Tudo isso será discutido.

- Como começou a história do Laboratório de Redes Neurais e Deep Learning da Phystech?
- Em 2015, participei de uma iniciativa da Agência de Iniciativas Estratégicas (ASI) denominada "Frota Foresight" - esta é uma plataforma de vários dias para discussão no âmbito da Iniciativa Técnica Nacional. O tema principal dizia respeito às tecnologias que precisam ser desenvolvidas para que empresas apareçam na Rússia com potencial para assumir posições de liderança nos mercados globais. A mensagem principal era que é extremamente difícil entrar nos mercados formados, mas as tecnologias abrem novos territórios e novos mercados, e é precisamente neles que temos de entrar.
E então navegamos em um navio a motor ao longo do Volga e discutimos quais tecnologias poderiam ajudar a criar esses mercados e quebrar as barreiras tecnológicas atuais. E nessa discussão sobre o futuro, o tema dos assistentes pessoais cresceu. É claro que já começamos a usá-los - Alexa, Alice, Siri ... e era óbvio que existem barreiras técnicas no entendimento entre humanos e computadores. Por outro lado, muitos desenvolvimentos de pesquisa têm se acumulado, por exemplo, no campo da aprendizagem por reforço, no processamento de linguagem natural. E ficou claro: muitas tarefas difíceis estão sendo cada vez melhores e mais bem resolvidas com a ajuda das redes neurais.
E eu estava fazendo pesquisas sobre algoritmos de rede neural. Com base nos resultados das discussões da frota de previsão, formulamos o conceito de um projeto de desenvolvimento de tecnologia para um futuro próximo, que posteriormente foi transformado no projeto iPavlov. Este foi o início da minha interação com a Phystech.
Com mais detalhes, formulamos três tarefas. Infraestrutura - criação de uma biblioteca aberta para a condução de diálogos com o usuário. A segunda é conduzir pesquisas em processamento de linguagem natural. Além da solução de problemas específicos de negócios .
O Sberbank atuou como parceiro e o próprio projeto foi formado sob a asa da Iniciativa Técnica Nacional.
, 2015 -: deephack.me — , , - , . Open Data Science.
No início de 2018, publicamos o primeiro repositório de nossa biblioteca aberta DeepPavlov e , nos últimos dois anos, vimos um aumento constante de seus usuários (é focado em russo e inglês): temos cerca de 50% das instalações nos EUA, 20-30% na Rússia. No geral, acabou sendo um projeto de código aberto bastante bem-sucedido.
Não estamos apenas desenvolvendo, mas também tentando contribuir para a agenda global de pesquisa em IA conversacional. Percebendo a necessidade de competição acadêmica nesta área, lançamos a série Conversational AI Challenges como parte da NeuIPS, a conferência líder em aprendizado de máquina.
Além disso, não apenas organizamos competições, mas também participamos. Assim, a equipe do nosso laboratório no ano passado participou de um concurso da Amazon chamado Alexa Prize - criando um bot de bate-papo com o qual uma pessoa estaria interessada em conversar por 20 minutos.
A próxima competição terá início em novembro.
Trata-se de uma competição universitária, e o núcleo de participantes deveria ser formado por alunos e funcionários da universidade. Foram 350 equipes no total, sete são selecionadas para o topo e três são convidadas com base nos resultados do ano passado - nós chegamos ao topo.
Nosso sistema de diálogo conduziu cerca de 100 mil diálogos com usuários nos Estados Unidos e no final teve uma avaliação de cerca de 3,35-3,4 em 5, o que é muito bom. Isso sugere que conseguimos formar uma equipe de classe mundial no MIPT em um tempo bastante curto.
Agora o laboratório desenvolve projetos com diversas empresas, entre as grandes estão Huawei e Sberbank. Projetos em diferentes direções: AutoML, teoria das redes neurais e, claro, nossa direção principal - PNL.
- Sobre as tarefas que costumavam ser difíceis para o aprendizado de máquina: por que o aprendizado profundo decolou na solução desses problemas?
- Difícil dizer. Descreverei agora minha intuição de uma forma ligeiramente simplificada. A questão é que, se o modelo tiver muitos parâmetros, ele surpreendentemente pode generalizar bem os resultados para novos dados. No sentido de que o número de parâmetros pode ser compatível com o número de exemplos. Pela mesma razão, o ML clássico resistiu por muito tempo à pressão das redes neurais - parece que nada de bom deveria resultar disso nesta situação.
O surgimento de parâmetros em modelos de aprendizado profundo ( fonte )
Surpreendentemente, esse não é o caso. Ivan Skorokhodov, de nosso laboratório, mostrou ( .pdf ) que quase qualquer padrão bidimensional pode ser encontrado no espaço da função de perda da rede neural.
Você pode escolher um plano de forma que cada ponto neste plano corresponda a um conjunto de parâmetros da rede neural. E a perda deles corresponderá a um padrão arbitrário e, portanto, você pode captar essas redes neurais que eles cairão diretamente nesta imagem.
Um resultado muito engraçado. Isso sugere que, mesmo com essas restrições absurdas, a rede neural pode aprender a tarefa atribuída a ela. Esse é o tipo de intuição aqui, sim.

Exemplos de padrões do artigo de Ivan Skorokhodov
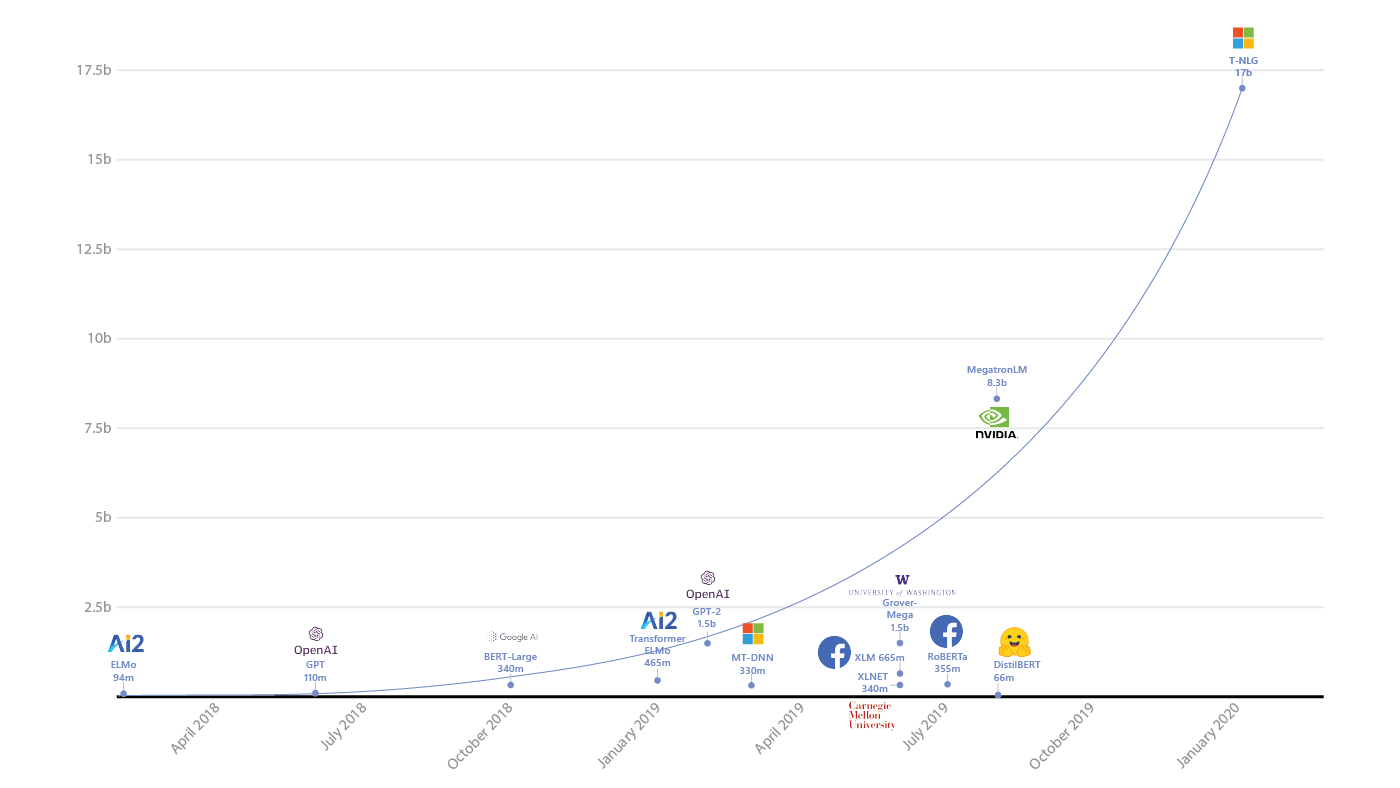
- Nos últimos anos, notáveis avanços têm sido notados no campo da aprendizagem profunda, mas já é visível o horizonte onde nos enterraremos no limite dos indicadores?

O crescimento no tamanho dos modelos de IA e os recursos que eles consomem (fonte: openai.com/blog/ai-and-compute/ )
- Na PNL, o limite ainda não é sentido, embora pareça que, por exemplo, na aprendizagem por reforço, algo já começou escorregar. Ou seja, não houve mudanças qualitativas nos últimos dois anos. Houve um grande boom de Atari para AlphaGo com a hibridização com Monte Carlo Tree Search, mas agora não há avanço direto.
Mas na PNL ocorre o contrário: redes recorrentes, redes convolucionais e, finalmente, a arquitetura do transformador e o próprio GPT ( um dos mais novos e interessantes modelos de transformador, frequentemente usado para gerar textos - nota do autor) Já é um desenvolvimento puramente extenso. E então parece que ainda há margem para conquistar algo novo. Portanto, na PNL, a barra de cima ainda não é visível. Embora, é claro, seja quase impossível prever qualquer coisa aqui.
- Se imaginarmos o desenvolvimento de linguagens e frameworks para aprendizado de máquina, passamos da escrita (condicionalmente) em puro numpy, scikit-learn, para tensorflow, keras - os níveis de abstração aumentaram. O que vem a seguir para nós?
— , : - . , , low level high level code: numpy . , , NLP : .
- Tensorflow / Pytorch — : .
- : NLP- — DeepPavlov.
- : — DeepPavlov Dream .
- Um sistema para alternar entre habilidades / pipelines, incluindo nosso Agente DeepPavlov.
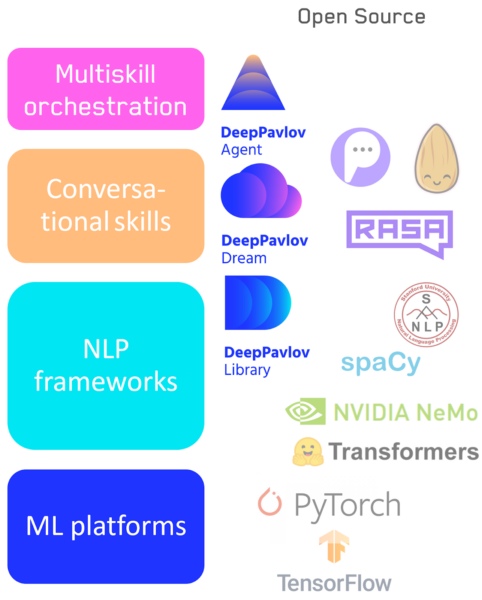
Pilha de tecnologia de IA de conversação
Diferentes aplicativos e tarefas exigem diferentes flexibilidade de ferramentas e, portanto, não acho que nenhum elemento dessa hierarquia irá desaparecer. Os sistemas de baixo e alto nível evoluirão conforme e quando necessário. Por exemplo, bibliotecas visuais que não estão disponíveis para programadores, mas também bibliotecas de baixo nível para desenvolvedores, não irão a lugar nenhum.
- Os experimentos sociais agora estão sendo realizados por analogia com o teste de Turing clássico, onde as pessoas devem entender se uma rede neural está à sua frente ou uma pessoa?
- Esses experimentos são realizados regularmente. No Alexa Challenge, uma pessoa tinha que avaliar a qualidade de uma conversa, mas não sabia com quem estava falando - um bot ou uma pessoa. Até agora, do ponto de vista de uma conversa ao vivo, a diferença entre uma máquina e uma pessoa é significativa, mas vem diminuindo a cada ano. A propósito, nosso artigo sobre isso acabou de sair na AI Magazine.
Fora da comunidade científica, isso é feito regularmente. Recentemente, alguém treinou um modelo GPT, configurou uma conta no Twitter para ela e começou a postar respostas. Muitas pessoas se inscreveram, a conta ganhou popularidade e ninguém sabia que era uma rede neural.
Um formato tão curto, como no Twitter, quando as formulações são gerais e "profundas", se adequa bem ao sistema de inferência de redes neurais.
- Quais áreas você considera mais promissoras, onde esperar um salto?
- ( risos ) Poderia dizer que é na unificação de todas as minhas direções favoritas que haverá um salto. Tentarei descrever com mais detalhes no quadro da problematização. Temos os atuais modelos GPT baseados em transformadores - eles não têm propósito na vida, apenas geram texto semelhante ao humano, completamente sem objetivo. E eles não podem vinculá-lo à situação e aos objetivos no contexto do próprio mundo.
E uma das maneiras é criar uma vinculação de uma visão lógica do mundo ao GPT, que leu muito, muito texto, e nele, de fato, já existem muitas conexões lógicas. Por exemplo, através da hibridização com "Wikidata" (este é um gráfico que descreve o conhecimento sobre o mundo, cujos vértices estão os artigos da Wikipedia).
Se pudéssemos conectar os dois para que a GPT possa usar a base de conhecimento, isso seria um salto em frente.
A segunda abordagem para o problema da falta de objetivo dos modelos da PNL é baseada na integração da compreensão dos objetivos humanos neles. Se tivermos um modelo que pode conduzir um modelo de linguagem generativo vinculado a um gráfico de conhecimento, poderíamos treiná-lo para ajudar uma pessoa a atingir seus objetivos. E tal assistente deve compreender a pessoa através da PNL, e seus objetivos, e a situação - então ele precisa planejar ações. E no planejamento, o aprendizado por reforço funciona melhor.
Como combinar e otimizar tudo isso é uma questão em aberto.
E a última é a busca por arquiteturas de rede neural. Quando, por exemplo, usando abordagens evolutivas, estamos procurando no espaço de arquiteturas que são ótimas para uma dada tarefa. Mas tudo isso não será decidido hoje - há muito espaço para pesquisar.
Das boas notícias: o hardware está evoluindo muito rapidamente e, talvez, isso nos permitirá em 5-10 anos combinar modelos de linguagem de rede neural, gráficos de conhecimento e aprendizado por reforço. E então teremos um salto quântico na compreensão do homem pela máquina.
Com a ajuda de tal assistente, será possível lançar a solução de outras tarefas: análise de imagens, análise de prontuários médicos ou da situação econômica, seleção de mercadorias.
Portanto, eu diria que, do ponto de vista científico, nos próximos cinco anos veremos um rápido desenvolvimento no campo da hibridização - há muitas tarefas interessantes.
Pessoal, o déficit de pessoal será enorme, e há uma grande chance de obter resultados novos e interessantes, e também de influenciar o desenvolvimento do setor. Conecte-se - você precisa aproveitar o momento!( O autor apóia ativamente essa resposta, uma vez que ele lida apenas com esses sistemas. )
- Como começar a mergulhar no aprendizado profundo?
- A maneira mais fácil, me parece, é fazer um curso em deep learning school : inicialmente era destinado a alunos do ensino médio, mas será bastante adequado para alunos. No geral, esse é um grande empreendimento, ajudei no agendamento e dei palestras introdutórias lá.
Também recomendo assistir a cursos introdutórios de universidades, fazer tarefas - há apenas um monte de coisas na Internet. A melhor de todas as ferramentas para "brincar" é o Colab do Google, existem milhões de exemplos de tarefas, você pode descobrir e executar as soluções mais modernas - sem instalar nenhum software em seu computador.
Outra forma é competir no Kaggle. E também participe da Open Data Science - uma comunidade de língua russa para Data Science, onde existem vários canais de aprendizagem profunda. Sempre há pessoas prontas para ajudar com conselhos e códigos.
Estas são as formas principais.
Leader-ID : friends, para a seleção agora lançada do acelerador para a promoção de projetos de IA, pensamos em uma opção de login para desenvolvedores indie. Não, isso não altera as condições básicas sob as quais apenas as equipes participam do intensivo. Mas temos muitas perguntas de indivíduos que não têm seu próprio projeto agora, mas querem participar (e estes não são apenas programadores, designers têm um grande interesse em projetos de IA). E encontramos uma solução: ajudaremos a reunir uma equipe e pessoas afins por meio de um hackathon online gratuito . Começará em 10 de outubro às 12h00 e terminará exatamente um dia depois. Nele, o bot irá distribuí-los em equipes, e então, sob sua orientação, você percorrerá as principais etapas de desenvolvimento do projeto e o enviará para o Arquipélago 20.35. Todos os dados estão em sua conta pessoal, você só precisa se cadastrar a tempo.