- Sobre o que exatamente vamos conversar? Não sobre seleções e junções primitivas - acho que a maioria de vocês já sabe sobre elas.
Falaremos sobre o uso real de bancos de dados, quais dificuldades você pode enfrentar e o que você precisa saber como desenvolvedor de backend. Haverá muita informação, aqui está o conteúdo. Você não precisa conhecer diretamente os detalhes de cada um desses pontos, mas precisa saber que esse ponto existe.

E você precisa saber como quais problemas são resolvidos para que, quando tiver a tarefa de construir uma estrutura, salvar dados, saiba qual modelo de dados escolher e como salvá-lo. Ou suponha que você tenha um problema, veja que o banco de dados está inativo, lento ou há problemas de dados, inconsistência. Então você tem que entender onde cavar. Ou seja, você precisa saber quais conceitos existem e de que lado abordar os problemas.

Primeiro, vamos falar sobre dados. Afinal, o que é isso? Existem muitos fatos ao nosso redor, muitas informações, mas até que sejam coletados de alguma forma, são inúteis para nós. Nós os recolhemos, estruturamos e armazenamos. E é essa estruturação armazenada que é chamada de dados, e o que os armazena é chamado de banco de dados. Mas, embora esses dados sejam coletados em algum lugar, eles também são basicamente inúteis para nós. Portanto, existe uma camada acima dos bancos de dados - o DBMS. É isso que nos permite recuperar dados, armazená-los e analisá-los. Assim, transformamos os dados que recebemos em informações que já podemos mostrar ao usuário. O usuário adquire conhecimento e o aplica.

Discutiremos como estruturar informações e fatos, armazená-los, em que forma de dados, em que modelo. E como obtê-los para que muitos usuários possam acessar simultaneamente os dados e obter o resultado correto, para que nosso conhecimento final que aplicaremos seja verdadeiro e correto.

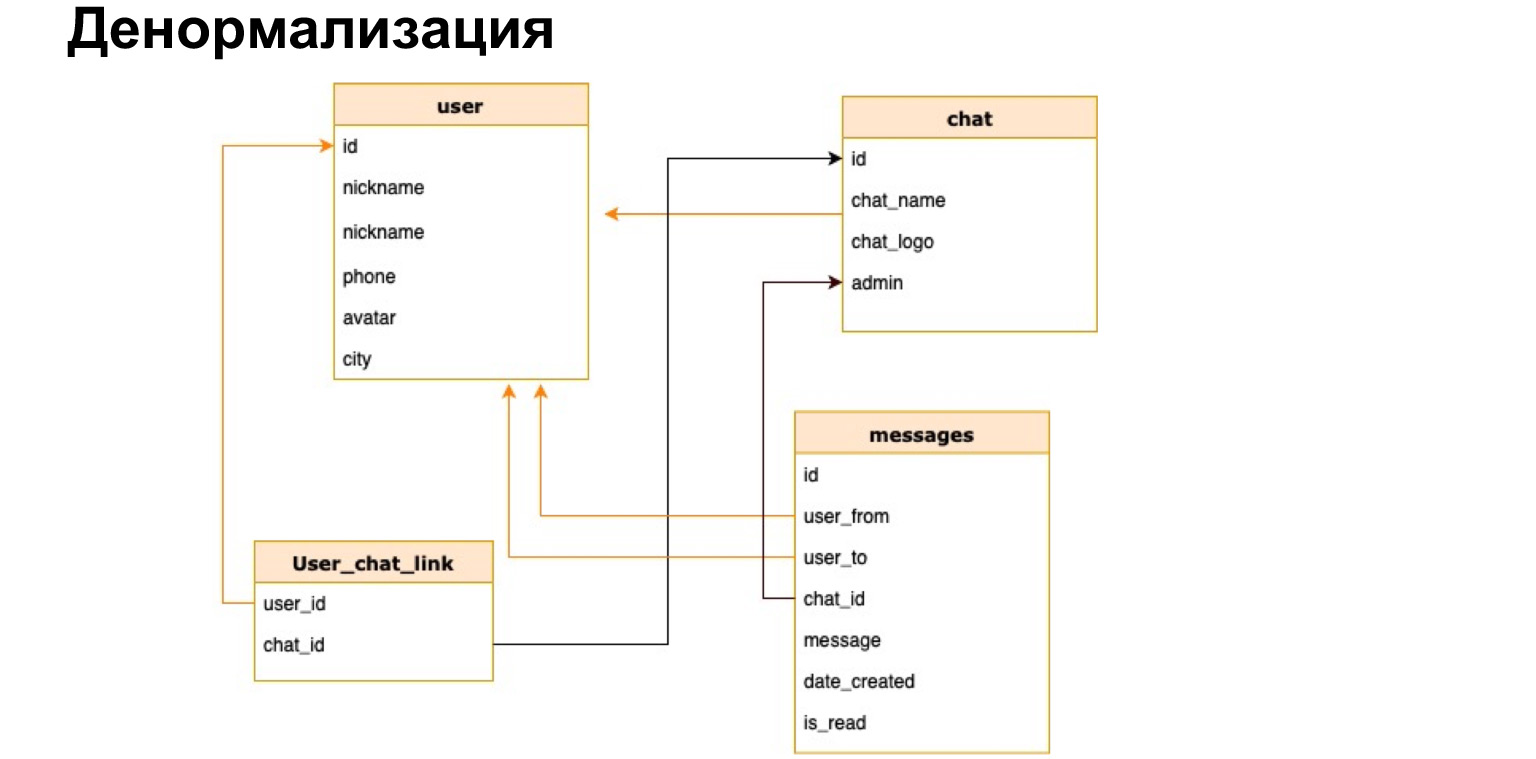
Primeiro, falaremos sobre bancos de dados relacionais. Acho que o modelo relacional é familiar para muitos de vocês. É um modelo do tipo de tabelas e relações entre as tabelas. Imagine que temos um mensageiro no qual gravamos dados e mensagens entre os usuários. Podemos escrevê-los todos em uma mesa tão grande e volumosa, ampla, onde teremos muitos dados repetitivos - de quem, quem, para quem, em qual conversa. E podemos escrever tudo isso em várias tabelas, ou seja, normalizar nossos dados, trazê-los para a terceira forma normal.
Existem notas e referências nos slides. Não vamos nos aprofundar em todos os conceitos agora. Tentarei não falar sobre conceitos técnicos que podem não ser familiares para você. Mas tudo o que eu digo você encontrará nas notas do slide. Incluindo a normalização, também haverá uma referência, você pode lê-la se não estiver familiarizado com este conceito.

Em termos gerais, a normalização é a divisão dos dados em tabelas com o objetivo de torná-los mais estruturados. Por exemplo, agora existe uma tabela de usuário, chat do messenger e mensagens. Essa estrutura garante que as mensagens exatamente dos usuários que conhecemos e dos chats que conhecemos serão gravadas aqui. Ou seja, garantimos a integridade dos dados. Garantimos o fato de que sempre podemos coletar a imagem completa. Mas, ao mesmo tempo, armazenamos, por exemplo, na tabela de mensagens apenas IDs, apenas identificadores. Assim, reduzimos o tamanho geral do banco de dados, tornando-o menor. Conseqüentemente, tornamos mais fácil gravar neste banco de dados. Não precisamos escrever constantemente para muitas tabelas. Acabamos de escrever na mesma tabela com o especialista em ID.

Se falamos de normalização, geralmente simplifica muito a visão do sistema, porque é muito gráfico, e imediatamente se torna claro para nós quais relações temos entre quais tabelas.
Reduzimos o número de erros na gravação de dados, pois se escrevermos uma mensagem no messenger e ainda não tivermos tal usuário, teremos que criar um. Mas o quadro final, os dados gerais, permanecerão completos.
Já falei sobre como reduzir o tamanho do banco de dados. Não precisamos escrever todos os dados sobre o usuário na tabela de mensagens todas as vezes. Para visualizar o perfil, podemos simplesmente ir para a tabela de usuários.
Também alertei sobre a dependência inconsistente. Estes são apenas links para IDs de outras tabelas, identificadores são valores únicos em uma tabela. De outra forma, elas são chamadas de chaves primárias e, quando temos um link para essas chaves primárias, o próprio link em outra tabela é chamado de chave estrangeira.
Essa estrutura também protege nossos dados contra exclusão acidental. Não podemos excluir um usuário porque, por exemplo, ele tem uma mensagem. Esta é uma rede tão pequena, mas segura.
Parece que fizemos uma excelente estrutura, tudo é claro, tudo é dependente, tudo é integral. O que mais você precisa para trabalhar?

Vamos imaginar que realmente o colocamos em operação, temos muitos usuários e, portanto, muitas mensagens. Eles se comunicam constantemente entre si. O que está acontecendo em nossa tabela de mensagens? Está crescendo constantemente. E para fazer buscas em não dados, precisamos passar constantemente por absolutamente todas as mensagens, verificar se são deste usuário ou não, neste chat ou não, e só então exibi-las.
Naturalmente, quanto mais usuários, mais mensagens, mais tempo demoram as solicitações de pesquisa. Precisamos de uma solução que nos permita pesquisar rapidamente as mensagens na tabela.
Nesse caso, os índices são usados para acelerar a pesquisa. A associação mais simples com índices é o conteúdo de um livro. Se precisar encontrar informações em um livro, você pode simplesmente folheá-lo ou pode ir para o índice. Os índices são uma espécie de sumário.
Também há um bom exemplo com uma lista telefônica. Você pode clicar em uma carta em seu telefone, e você será imediatamente consultado por sobrenomes começando com esta carta. Os índices de banco de dados funcionam de maneira muito semelhante. Vamos ver nossa tabela com as mensagens e como obteremos esses dados.

Preste atenção em como trabalharemos com os dados. Não com as linhas que temos na tabela, mas em geral. Os índices são construídos com base nas consultas que você faz.
Imaginemos que fazemos pedidos principalmente por chat, ou seja, descobrimos quais mensagens estão neste chat. Vamos construir o índice exatamente na coluna do chat. Os índices de banco de dados são uma estrutura separada. A mesa é independente dela. Ou seja, você pode excluir e reconstruir o índice a qualquer momento, e a tabela não sofrerá com isso.
Aqui você pode ver que selecionamos, colocamos um índice na coluna, e temos uma estrutura separada, que já reduziu um pouco o número de entradas, pois já existem várias mensagens no chat 11. O DBMS fornece uma pesquisa rápida nesta pequena mesa de bate-papo. Como isso é feito? Naturalmente, a busca não é uma busca simples. Existem muitos algoritmos de busca rápida, vamos dar uma olhada em um dos algoritmos mais populares que são usados por padrão na maioria dos bancos de dados. É uma árvore equilibrada.

Como funciona? Temos um número de chat, que é um valor inteiro, e a árvore é construída de acordo com o seguinte princípio: o que está menos à esquerda do nó, mais valores à direita do nó. O que essa estrutura nos dá? Se você olhar as folhas de resumo desta árvore, todos os valores na parte inferior estão ordenados. Esta é uma grande vantagem em ganhos de produtividade. Agora vou mostrar o porquê.
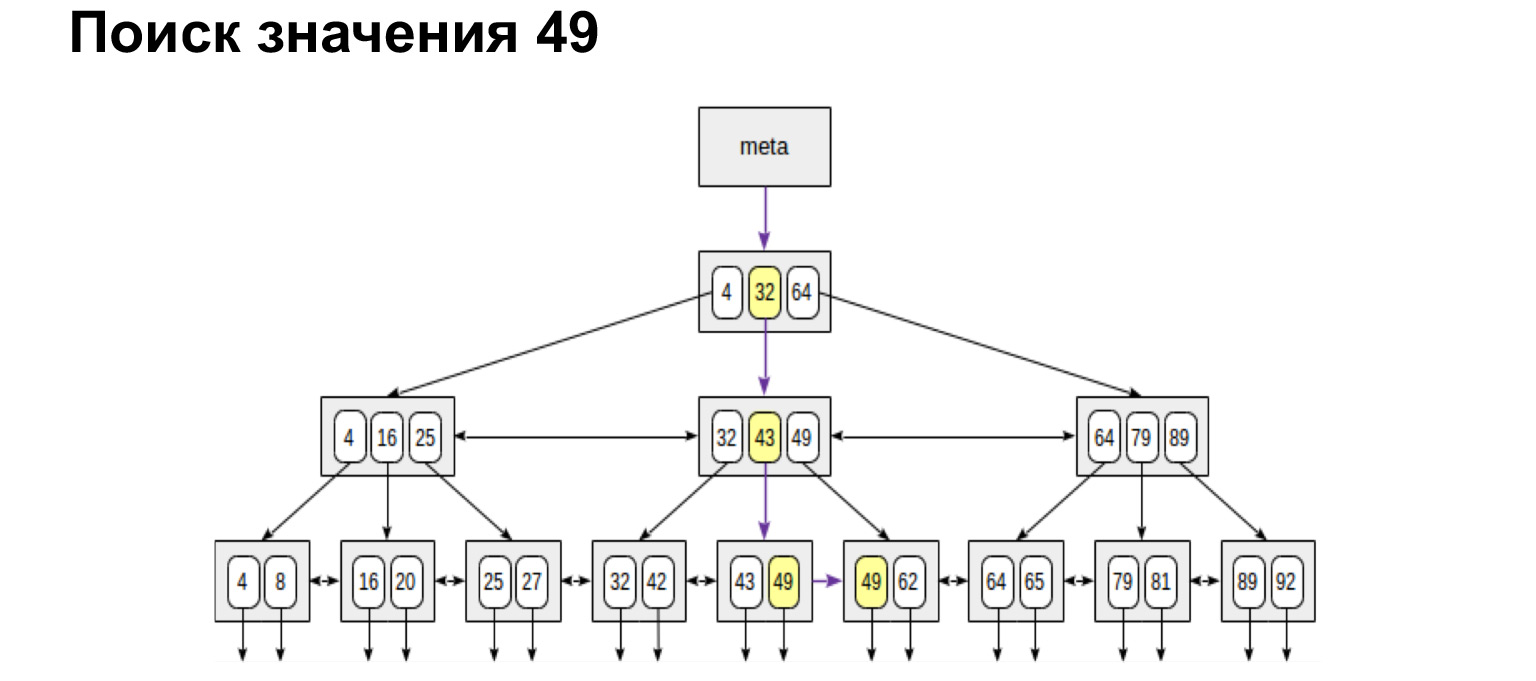
Por exemplo, estamos procurando um valor. É muito fácil procurar um significado. Descemos na árvore ou para a esquerda, para a direita - dependendo se esse valor é maior ou menor.
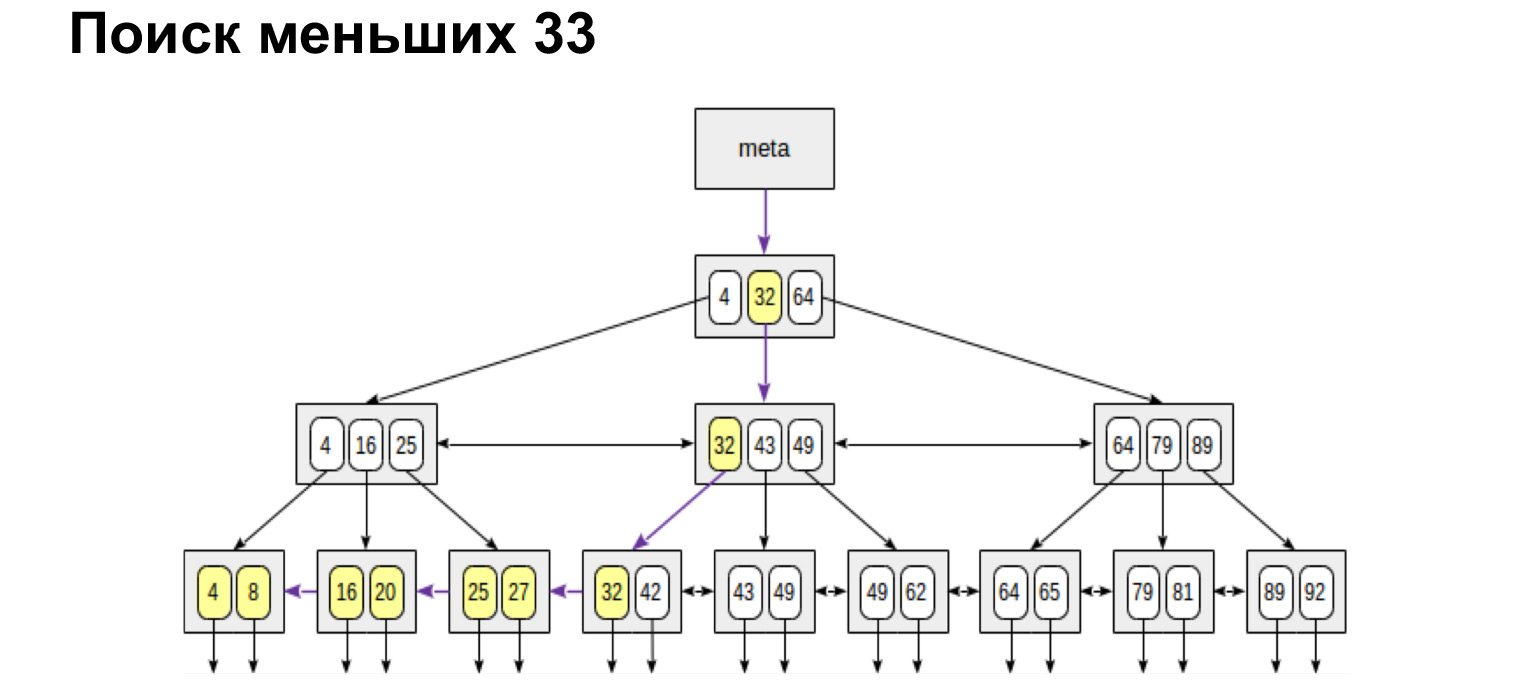
E se quisermos encontrar, por exemplo, um intervalo, veja como é simples e rápido. Chegamos ao valor e depois seguimos os links nas folhas já junto aos valores ordenados, basta ir até o final.
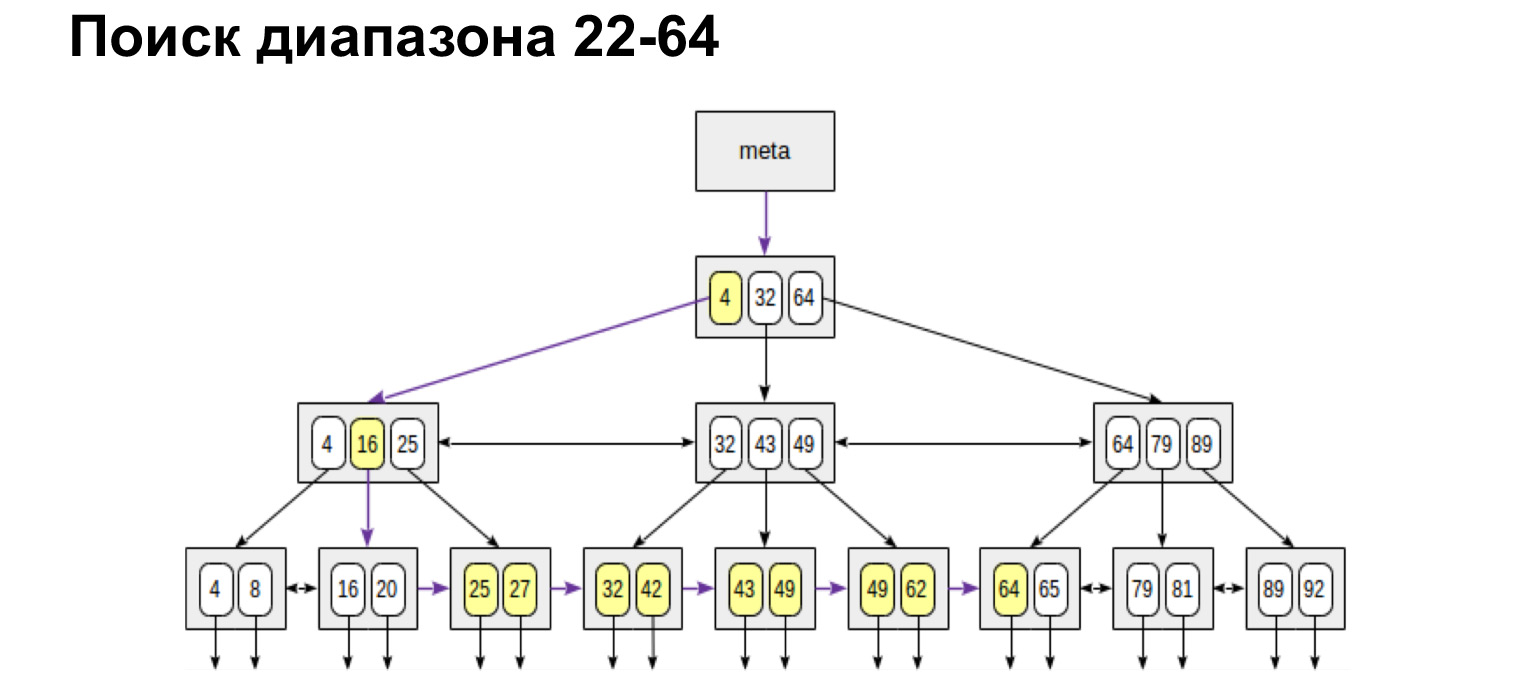
Se precisarmos de um intervalo definido de e para, fazemos exatamente o mesmo. Encontre o valor inicial e siga os links de folha até o valor máximo. Caminhamos na árvore apenas uma vez. É muito conveniente, muito rápido.
Da mesma forma, buscaremos os valores máximos e mínimos. Ande completamente para a esquerda, completamente para a direita. Também receberemos uma lista ordenada. Ou seja, se apenas precisamos obter todos os chats de forma ordenada, chegamos ao primeiro e percorremos as folhas até o valor mais à direita, obtemos uma lista ordenada. É por esse princípio que o banco de dados pesquisa muito rapidamente na tabela de índice as linhas que precisamos selecionar e as retorna.
O que é importante saber aqui? Pareceria uma estrutura legal - agora iremos construir para cada coluna de acordo com essa árvore e pesquisaremos. Por que você acha que não vai funcionar? Por que não teremos um aumento de velocidade se construirmos uma árvore para cada coluna? (...)
Nossas seleções vão realmente acelerar. Sempre que precisamos passar por algum valor, vamos ao índice, encontramos ali um link para os próprios valores. Os índices geralmente contêm exatamente as referências às strings, não as próprias strings. E para selecionar funciona perfeitamente. Mas assim que quisermos definir os dados da tabela, atualizar ou excluir dados, todas essas árvores terão que ser reconstruídas.
Na verdade, a exclusão não reconstruirá, mas simplesmente fragmentará essa árvore, e terminaremos com muitos valores vazios. Haverá uma enorme árvore com valores vazios. Mas é com update e com create que essas árvores serão reconstruídas todas as vezes. Como resultado, teremos uma grande sobrecarga sobre toda essa estrutura. E, em vez de buscar dados rapidamente e acelerar o banco de dados, diminuiremos a velocidade de nossas consultas.
O que mais é importante saber? Quando você trabalha com um banco de dados, veja, leia quais índices existem nele, porque cada banco de dados tem suas próprias implementações, seus próprios índices diferentes. Existem índices para acelerar, existem índices para garantir a integridade. Uma das mais simples é apenas a chave primária. Este também é um índice exclusivo. E em relação ao seu banco de dados, veja como funciona, como trabalhar com ele, porque esse é o tipo de conhecimento que o ajudará a escrever as consultas mais ideais.
Discutimos o que devemos ter em mente sobre a sobrecarga de manter índices ao inserir dados. Esqueci de dizer que, quando você constrói um índice, ele deve ser altamente seletivo. O que isso significa?
Vamos dar uma olhada nesta árvore. Entendemos que se o índice for definido como verdadeiro falso, obteremos apenas dois pedaços enormes de madeira à esquerda e à direita. E examinamos 50% da tabela, na melhor das hipóteses, o que na verdade não é muito eficiente. É melhor indexar exatamente as colunas com os valores mais diferentes. Isso irá acelerar nossas seleções.
Eu disse sobre a fragmentação; ao excluir dados, você precisa ter isso em mente. Se costumamos ter exclusões nos dados contidos no índice, pode ser necessário desfragmentá-los, e isso também precisa ser monitorado. Também é importante entender que você está construindo um índice não com base nas colunas que possui, mas em como você usa esses dados. E as consultas que incluem índices precisam ser escritas com muito cuidado. O que significa legal? Quando você escreve uma consulta, a envia para o banco de dados, ela não é enviada diretamente para o banco de dados, mas para uma certa camada de software chamada de planejador de consulta.
O planejador tem uma certa tabela de correspondência de quanto custa a operação e quão caro é. No exemplo do PostgreSQL, existem tabelas técnicas especiais que coletam informações sobre seus dados, sobre suas tabelas. O planejador verifica qual consulta você tem, quais dados estão armazenados na tabela pg_stat. Esta é exatamente a tabela que armazena informações gerais sobre quantos dados você tem e quais colunas estão em sua tabela, quais índices estão nela. Com base nisso, ele analisa os planos de execução da sua consulta, calcula quanto tempo de acordo com qual plano levará para a consulta e escolhe o mais ideal.

Se você deseja ver o tempo de execução previsto para sua consulta, você pode usar a operação Explain. Se quiser a execução real, você pode usar a análise Explain. Qual é a diferença? Como eu disse, o escalonador calcula inicialmente o tempo de execução com base no tempo estimado para cada operação. Portanto, o tempo real pode variar dependendo da máquina e da natureza dos seus dados. Portanto, se você deseja a execução real, é claro que é melhor usar a análise Explain.
Você pode ver um exemplo neste slide. Mostra que às vezes as consultas baseadas em sua coluna que possuem índices podem não usar o índice de varredura, mas apenas a varredura completa em toda a tabela. Isso acontece se tivermos baixa seletividade de índice e se o planejador achar que uma consulta de varredura completa na tabela será mais lucrativa.
Vamos imaginar que temos nosso messenger e queremos na lista do chat, por exemplo, mostrar o nome do chat ou a quantidade de mensagens não lidas. Se cada vez que abrirmos um chat, recalcularmos todos os dados de todos os chats, isso não será lucrativo.
Existe tal coisa - desnormalização. Esta é uma cópia dos dados mais quentes usados ou um pré-cálculo dos dados necessários e salvá-los em uma tabela.
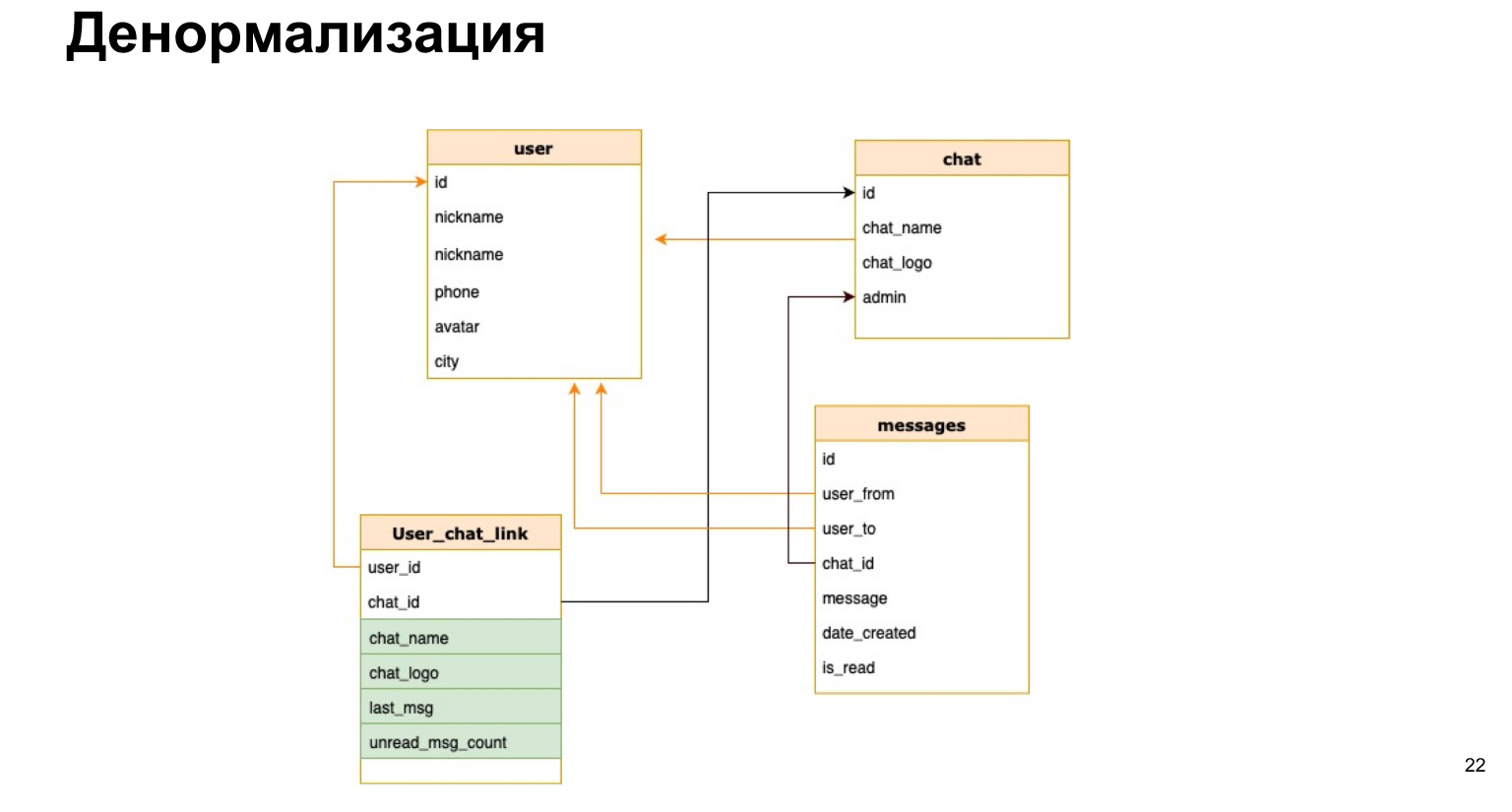
É assim que a relação entre o usuário e o chat pode ser. Ou seja, além do ID do usuário e do chat, salvaremos brevemente o nome do chat, o log do chat e o número de mensagens não lidas. Assim, toda vez não precisaremos carregar todas as nossas tabelas, fazer seleções e recalcular tudo isso.

Qual é a vantagem da desnormalização? Nós aceleramos o processo de amostragem de dados. Ou seja, nossas seleções passam o mais rápido possível, damos uma resposta aos usuários o mais rápido possível.
A dificuldade é que cada vez que adicionamos novos dados, precisamos recalcular todas essas colunas e a probabilidade de erro é muito alta. Ou seja, se nossos selects ficarem muito mais simples e não precisarmos entrar o tempo todo, então nosso update e create tornam-se muito incômodos, pois precisamos travar os triggers ali, recalcular e não esquecer de nada.
Portanto, você só deve usar a desnormalização quando realmente precisar dela. E como agora seguimos toda essa lógica, primeiro você precisa normalizar os dados, ver como vai usá-los, ajustar os índices. Se você acha que as consultas não estão funcionando bem, dê uma olhada em Explicar antes de desnormalizar. Descubra como eles são realmente executados, como o planejador os executa. E só então, quando você já tiver chegado à conclusão de que a desnormalização ainda é necessária, você poderá fazê-lo. Mas existe essa prática, e a desnormalização de dados costuma ser usada em projetos reais.
Vamos mais longe. Mesmo que você estruture bem os dados, escolha um modelo de dados, colete-o, desnormalize tudo, crie índices, ainda assim, muito no mundo da TI pode dar errado.
O software pode falhar, a energia pode cair, o hardware ou a rede podem falhar. Existe uma segunda classe de problemas: nossos bancos de dados são usados por muitos usuários simultaneamente. Eles podem atualizar os mesmos dados ao mesmo tempo. Devemos ser capazes de resolver todos esses problemas.
Vamos dar uma olhada em exemplos específicos do que se trata.

Vamos imaginar que existem dois usuários que desejam reservar uma sala de reuniões. O usuário 1 vê que a sala de reunião está livre neste momento e começa a reservá-la. Sua janela se abre e ele pensa para qual dos meus colegas irei ligar. Enquanto está pensando, o usuário 2 também vê que a sala de reuniões está livre e abre uma janela de edição para si mesmo.
Como resultado, quando o usuário 1 salvou esses dados, ele saiu e acha que está tudo bem, a sala de reunião está reservada. Mas, neste momento, o usuário 2 sobrescreve seus dados, e acontece que a sala de chat é atribuída ao usuário 2. Isso é chamado de conflito de dados. E devemos ser capazes de mostrar esses conflitos às pessoas e, de alguma forma, resolvê-los. É neste local que teremos regravações.

Como fazer isso? Podemos simplesmente bloquear a sala de reunião por um tempo enquanto o usuário 1 está pensando. Se ele salvou os dados, não permitiremos que o usuário 2 faça isso. Se ele liberou os dados e não salvou, o usuário 2 poderá reservar uma sala de conferências. Você pode ver uma imagem semelhante ao comprar ingressos para o cinema. Você tem 15 minutos para pagar os ingressos, caso contrário, eles são fornecidos novamente a outras pessoas que também podem pegar e pagar por eles.
Aqui está outro exemplo que nos mostrará como é importante garantir que nossas operações sejam realizadas de forma completa. Digamos que eu queira transferir dinheiro da conta bancária 1 para a conta 2. No momento, tenho três operações. Eu verifico se tenho fundos suficientes, deduzo fundos da minha primeira conta e os deposito na segunda conta. É claro que se em algum desses momentos eu falhar, algo dará errado.
Por exemplo, se nesta fase ocorrer outra transação de leitura de dados, os fundos da minha conta não serão mais suficientes, não poderei realizar outras operações. Se ocorrer um problema no segundo momento, então, por exemplo, retiramos dinheiro de uma conta, mas não colocamos dinheiro na segunda. Acontece que, como resultado, minha conta bancária, todas as minhas contas, serão reduzidas em alguma quantia. Não há como recuperar esse dinheiro.
Para resolver esses problemas, existe o conceito de transação - uma execução atômica integral de todas as três operações simultaneamente.
Como o banco de dados faz isso? Ele grava todas essas alterações em um log específico e as aplica somente quando nossa transação é confirmada. Assim, garantimos que todas essas operações serão realizadas como um todo ou não serão realizadas de forma alguma.
Se em qualquer momento deste momento tivermos uma falha, o dinheiro não será debitado da primeira conta e, consequentemente, não o perderemos.
As transações têm quatro propriedades, quatro requisitos para elas. Estes são Atomicidade, Consistência, Isolamento e Durabilidade - atomicidade, consistência, isolamento e persistência dos dados. Quais são essas propriedades?
- Atomicidade ou atomicidade é uma garantia de que a operação que você está executando será totalmente executada, que não será executada parcialmente. Assim, garantimos que a consistência geral dos dados em nosso banco de dados será antes e depois da operação.
- Consistency — -, . (Integrity). - , , Integrity Error, : , . . — , .
, , , , . . .
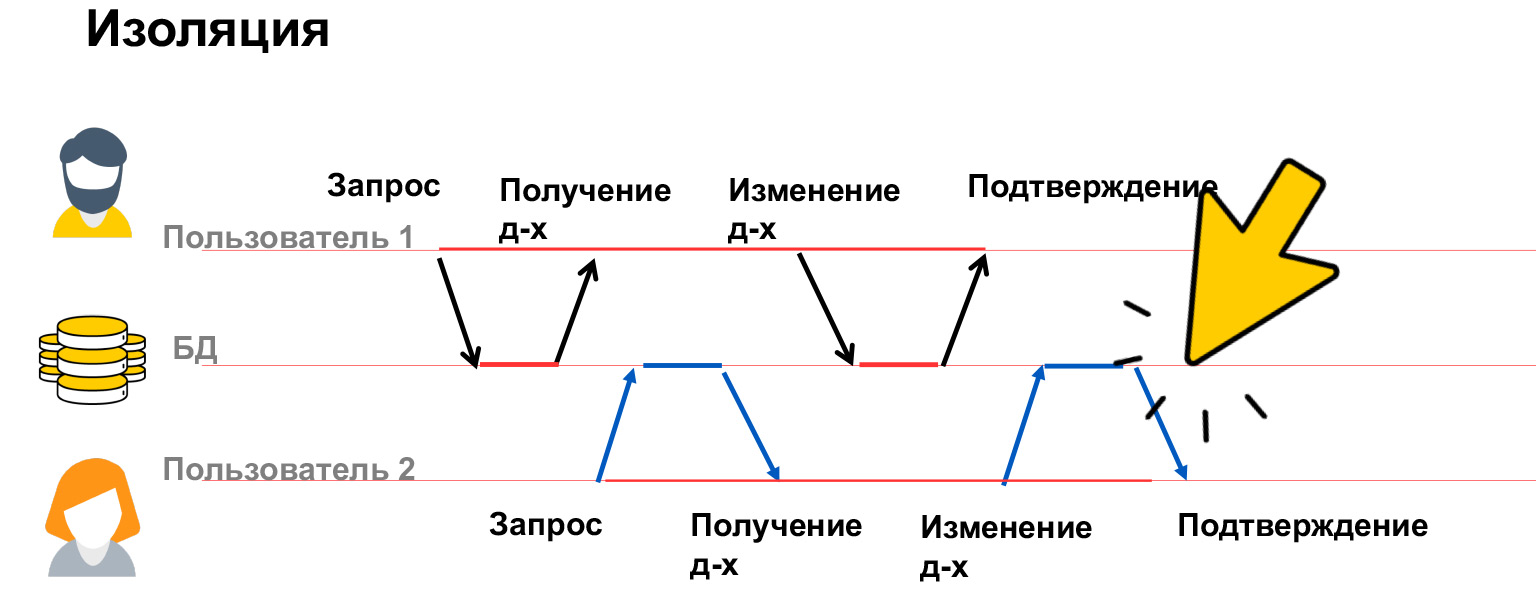
- Isolation — , . . , .
- Durability — , , , , .
Vamos conversar um pouco mais sobre isolamento. O isolamento de transações é uma propriedade muito cara, muitos recursos são gastos nele, por isso temos vários níveis de isolamento em nossos bancos de dados. Vamos ver o que podem ser os problemas e, a partir disso, já discutiremos como resolvê-los.
Existem quatro classes principais de problemas - atualização perdida, leitura suja, leitura não repetível e leitura fantasma. Vamos olhar mais de perto.
Uma atualização perdida é como no exemplo com salas de chat, quando o usuário 1 substituiu os dados e ele não sabe sobre isso. Ou seja, não bloqueamos os dados que este usuário está alterando e, consequentemente, recebemos sua substituição.
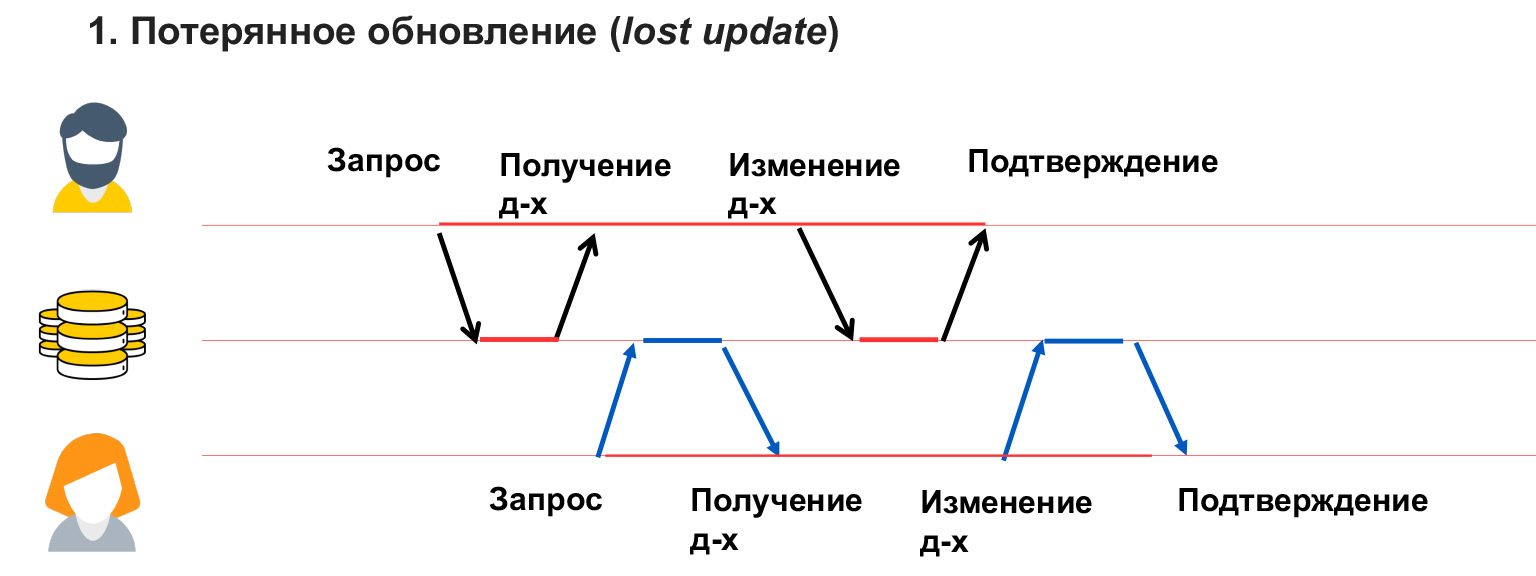
Um problema de leitura suja ocorre quando um usuário vê alterações temporárias feitas por outro usuário, que podem ser revertidas ou simplesmente feitas temporariamente.

Nesse caso, o usuário 1 escreveu algo no banco de dados. O usuário 2, neste momento, estava calculando algo a partir daí e construindo análises sobre esses dados. E o usuário 1 encontrou um erro, inconsistência e está revertendo esses dados. Assim, a análise que o usuário 2 anotou será falsa, incorreta, porque os dados a partir dos quais ele calculou não estão mais lá. Você também precisa ser capaz de resolver esse problema.
Uma leitura não repetível é quando temos um usuário com 1 transação longa. Ele busca dados do banco de dados e, neste momento, o usuário 2 altera parte dos mesmos dados.
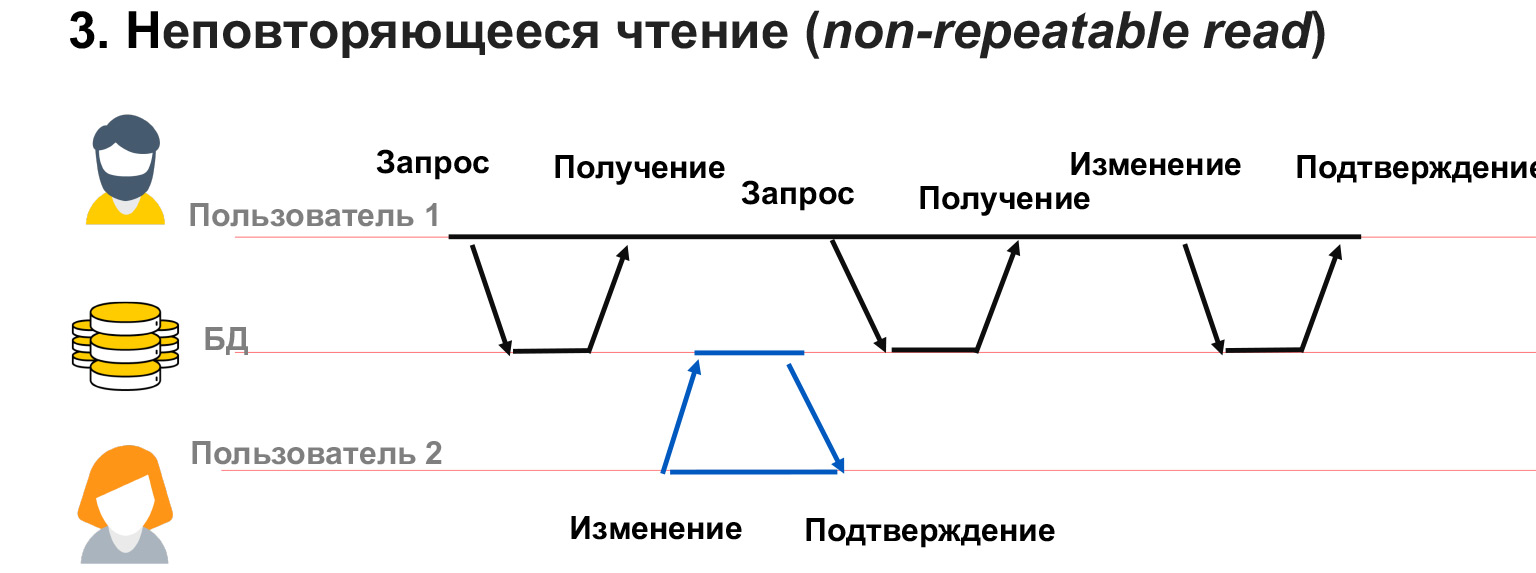
Nesse caso, verifica-se que o usuário 1 não bloqueou as alterações nos dados que ele possui. E apesar do fato de ele mesmo ter obtido um instantâneo dos dados, quando ele é solicitado pelo mesmo select novamente, ele pode obter valores diferentes nessas linhas. Assim, haverá um conflito, uma incompatibilidade nos dados que grava.

Um problema semelhante pode ocorrer se o usuário 2 tiver adicionado ou excluído dados. Ou seja, o usuário 1 fez uma solicitação e, em seguida, após uma segunda solicitação dos mesmos dados, ele tinha ou desapareceu linhas. Nesse caso, no contexto de uma transação, é muito difícil entender o que fazer com eles, como processá-los.

Para resolver esses problemas, existem quatro níveis de isolamento. O primeiro e o nível mais baixo são Leitura não confirmada. Isso é o que o PostgreSQL descreve como Sem bloqueio. Quando lemos ou gravamos dados, não impedimos que outros usuários leiam ou gravem esses dados. Acontece que não estamos bloqueando nenhuma mudança. Todos os quatro desses problemas ainda podem ocorrer. Mas contra o que esse nível de isolamento protege? Ele garante que todas as transações que chegam ao banco de dados sejam executadas. Se dois usuários iniciarem simultaneamente a execução de consultas com os mesmos dados, ambas as transações serão executadas sequencialmente.
Para que isso é útil? Este nível de isolamento é muito raramente usado na prática, mas pode ser útil, por exemplo, quando há uma grande consulta analítica e você deseja ler na segunda consulta e ver em que estágio seu analista está, quais dados já foram registrados e quais não estão. E então a segunda solicitação - que é para depuração, depuração, verificação - você executa apenas neste nível de isolamento. E ele vê todas as alterações em sua primeira consulta analítica, que podem eventualmente ser revertidas. Ou não revertido, mas no momento atual você pode ver o estado do sistema.

Leia os dados confirmados, leia os dados confirmados. Este nível de isolamento é usado por padrão na maioria dos bancos de dados relacionais, incluindo PostgreSQL e Oracle. Isso garante que você nunca leia dados sujos. Ou seja, outra transação nunca vê os estágios intermediários da primeira transação. A vantagem é que funciona muito bem para consultas pequenas e curtas. Garantimos que nunca teremos uma situação em que vejamos algumas partes dos dados, dados incompletos. Por exemplo, aumentamos o salário de um departamento inteiro e não vemos quando apenas uma parte das pessoas recebeu aumento e a segunda parte está sentada com um salário não indexado. Porque se tivermos tal situação, é lógico que nosso analista "vá" imediatamente.
Contra o que esse nível de isolamento não protege? Ele não protege contra o fato de que os dados que você selecionou podem ser alterados. Para consultas pequenas, esse nível de isolamento é suficiente, mas para consultas grandes e longas, análises complexas, é claro, você pode usar níveis mais complexos que bloqueiam suas tabelas.
O nível de isolamento de leitura repetida protege contra os três primeiros problemas que discutimos com você. Esta e a atualização perdida quando regravamos nossa sala de bate-papo; Leitura suja - leitura de dados não confirmados; e estes dados de leitura - leitura não repetíveis atualizados por outras transações.

Como é fornecido? Bloqueando a mesa, ou seja, bloqueando nosso select. Quando colocamos o select em nossa transação, parece um instantâneo dos dados. E neste momento não vemos as mudanças dos outros usuários, o tempo todo trabalhamos com esse instantâneo de dados. A desvantagem é que bloqueamos os dados e, portanto, temos menos solicitações paralelas que podem funcionar com os dados. Este é um aspecto muito importante. E, em geral, por que existem tantos desses níveis de isolamento?
Quanto mais alto o nível, mais blocos e menos usuários podem trabalhar com o banco de dados em paralelo. Cada transação vê um instantâneo específico dos dados que não podem ser alterados. Mas novos dados podem aparecer. Portanto, esse nível de isolamento não nos salva do surgimento de novos dados adequados para seleção.
Existe mais um nível de isolamento - serialização. Isso geralmente é chamado de pedido. Este é um bloqueio de dados completo na mesa. Ele salva da leitura fantasma, ou seja, da leitura apenas dos dados que adicionamos ou deletamos, porque travamos a tabela, não permitimos a escrita nela. E atendemos nossas solicitações de forma holística.

Isso é muito útil para consultas analíticas grandes e complexas, onde a precisão e a integridade dos dados são críticas. Não vai acontecer que em algum momento lemos os dados do usuário, e então novas estatísticas apareceram em outra tabela e acabou por estar fora de sincronia.
Este é o nível de isolamento mais alto. Ele possui o maior número de bloqueios e a menor paralelização possível de consultas.
O que você precisa saber sobre transações? Que nos facilitam a vida, pois são implementados a nível de DBMS e só precisamos fazer corretamente nossas consultas, formá-las corretamente, para que os dados eventualmente sejam consistentes. E para bloquear exatamente os dados com os quais nossos usuários trabalham. É preciso ter em mente que é ruim bloquear tudo, em qualquer lugar. Dependendo de qual sistema você tem e de quem lê / escreve quanto, você terá um nível diferente de isolamento. Se você quiser o sistema mais rápido possível que cometa alguns erros, você pode escolher o nível de isolamento mínimo. Se você tem um sistema bancário que deve garantir a consistência dos dados, tudo é feito e nada é perdido - então, é claro, você precisa escolher o nível de isolamento máximo.
Já fizemos um bom progresso no entendimento de como estruturar o banco de dados e o que pode acontecer. Vamos mais longe.
É seguro armazenar um banco de dados. Certamente não é seguro. Se algo acontecer com ela, perdemos todos os dados. Se houver um backup, podemos rolar, mas haverá tempo de inatividade do sistema. Se nossa rede quebrar ou o nó ficar indisponível, o sistema também ficará ocioso por algum tempo, em tempo de inatividade.
Como isso pode ser resolvido? Existe esse conceito - replicação. Esta é a duplicação do banco de dados para outros nós e servidores.

Esta é exatamente uma duplicação completa, uma cópia do banco de dados. Como podemos usar esse mecanismo?
Primeiro, se algo acontecer ao banco de dados, podemos redirecionar as solicitações para outra cópia do banco de dados, o que é lógico em princípio. Este é o aplicativo principal. De que outra forma podemos usar isso?
Vamos imaginar que o usuário está longe do servidor. Podemos distribuir servidores de forma a abranger o número máximo de usuários e fornecer solicitações o mais rápido possível. Cada um desses servidores terá a mesma cópia dos outros, mas as solicitações retornarão aos usuários mais rapidamente.

Outro uso muito popular é o balanceamento de carga. Como temos cópias idênticas dos dados, podemos ler não de nossa cabeça, nem de um banco de dados, mas de outros. Assim, descarregamos nosso servidor.

Também temos o conceito de consultas OLTP e consultas OLAP. O que é isso? OLTP - consultas transacionais curtas. OLAP é uma análise de longo prazo. É quando pegamos um grande join, um grande select, mesclamos tudo e é muito importante para nós que neste momento todos os dados estejam bloqueados, para que não haja alterações e o banco de dados esteja completo.
Para tais situações, você pode fazer análises em uma cópia separada do banco de dados. Portanto, não iremos afetar nossos usuários, eles também podem fazer entradas no banco de dados, só então essas entradas virão para nossa cópia.
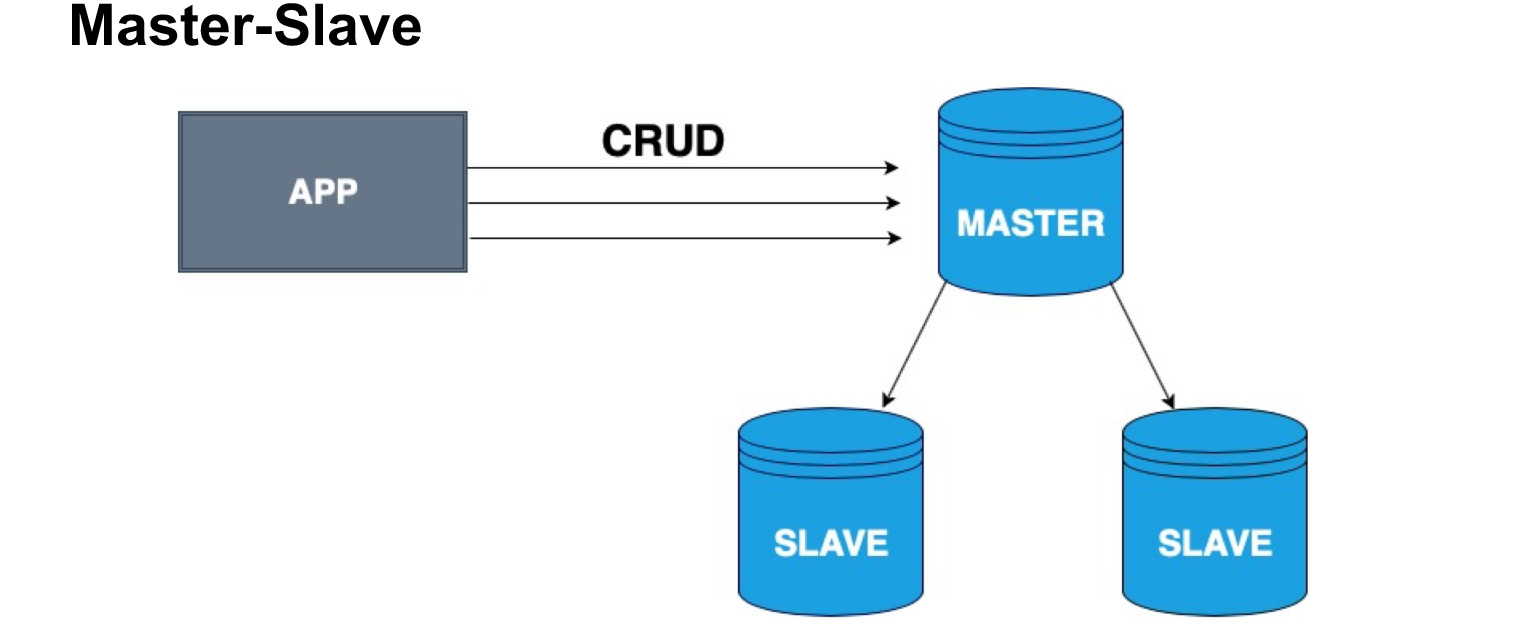
Para distribuir corretamente as cópias dos bancos de dados, o conceito de um nó mestre e um nó escravo, Mestre e Escravo, é introduzido. O escravo é freqüentemente chamado de réplica ou seguidor. Mestre - o nó no qual nosso usuário, nosso aplicativo grava. O Master aplica todas as mudanças, mantém um registro das mudanças e envia este registro para o Slave. O Slave não aceita alterações de usuários, mas apenas aplica alterações no log do Mestre. Observe que o Master não envia uma cópia todas as vezes, mas envia alterações. O escravo passa por cima dessas mudanças e recebe a mesma cópia dos dados que no Mestre.
Um parâmetro muito importante do sistema replicado é que as solicitações sejam executadas de forma síncrona ou assíncrona. O que é uma solicitação síncrona? É quando o Master envia um pedido para uma réplica síncrona, para um Slave síncrono, espera que o Slave diga "Sim, aceitei" e devolve a confirmação ao Master. Só então o Mestre retornará a resposta ao usuário. Se a réplica for assíncrona, o mestre enviará uma solicitação à réplica, mas imediatamente informará ao usuário que "É isso, eu anotei." Vamos ver como isso funciona.
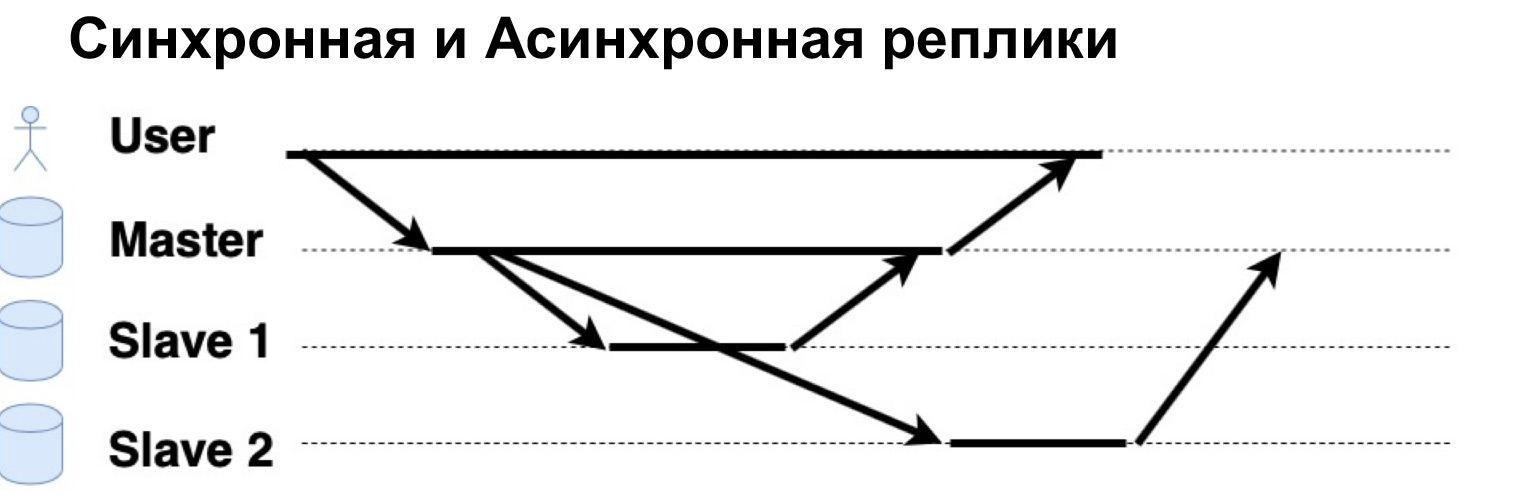
Há um usuário que gravou dados no Mestre. O Mestre os enviou para duas réplicas, esperou por uma resposta de uma réplica síncrona e imediatamente deu uma resposta ao usuário. Uma réplica assíncrona gravou e disse ao Mestre: "Sim, está tudo bem, os dados estão gravados."
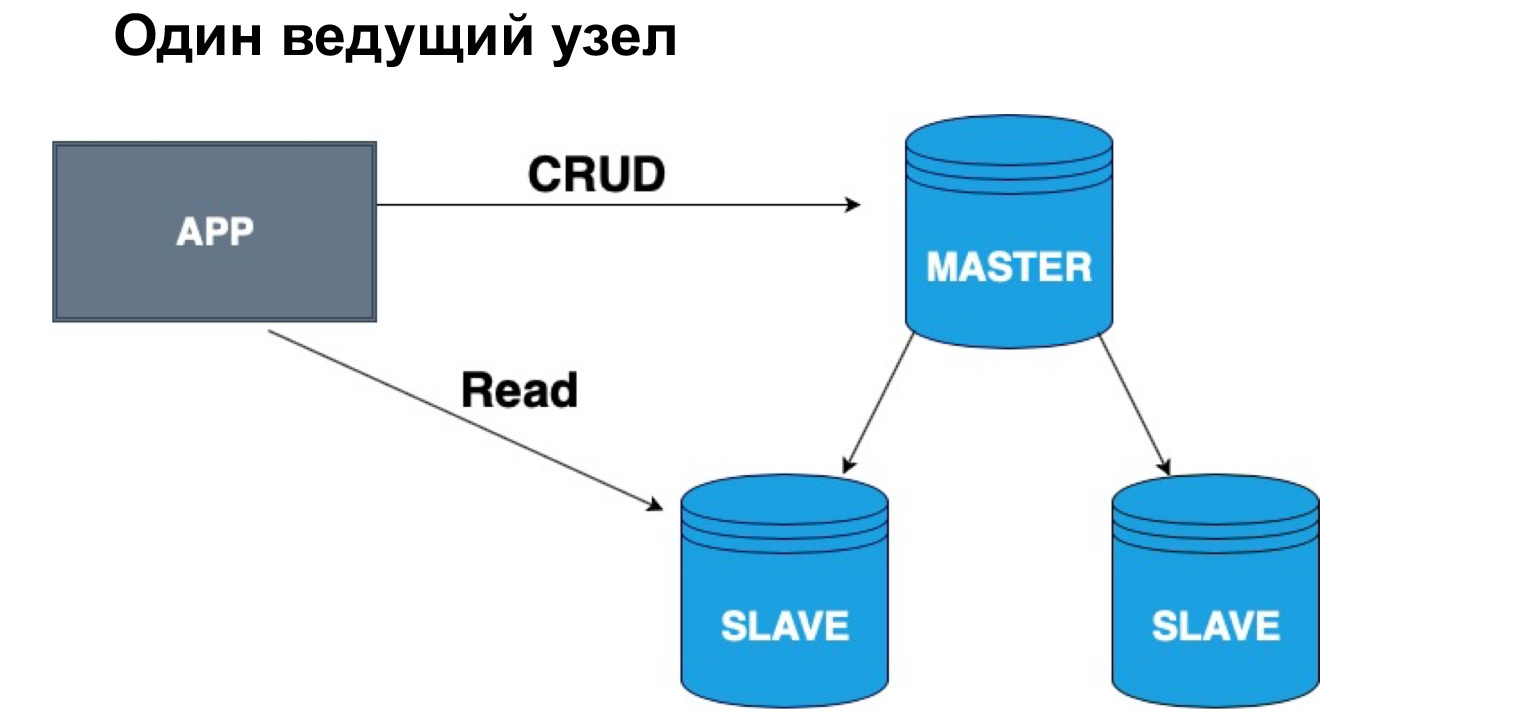
Em termos de tal hierarquia, Mestre e Escravo, podemos ter uma ou várias cabeças. Se tivermos um nó mestre, é muito conveniente gravar nele, mas você pode ler de uma réplica síncrona. Por que exatamente do síncrono? Porque uma réplica síncrona garante que os dados sejam atualizados com a máxima precisão.
Quando uma consulta é aplicada aos dados, uma operação do log, também leva tempo. Portanto, se a precisão de cem por cento dos dados que deseja receber é importante para você, deve ir para a leitura, para uma seleção no Master. Se você não acredita que os dados podem chegar com um pequeno atraso, você pode ler o Slave síncrono. Se você não for absolutamente crítico quanto à relevância dos dados, poderá ler, inclusive da réplica assíncrona, descarregando, assim, o mestre e a réplica síncrona das solicitações.
A replicação também pode ter vários mestres. Aplicativos diferentes podem gravar em cabeçotes diferentes, e esses Master resolvem conflitos entre si.
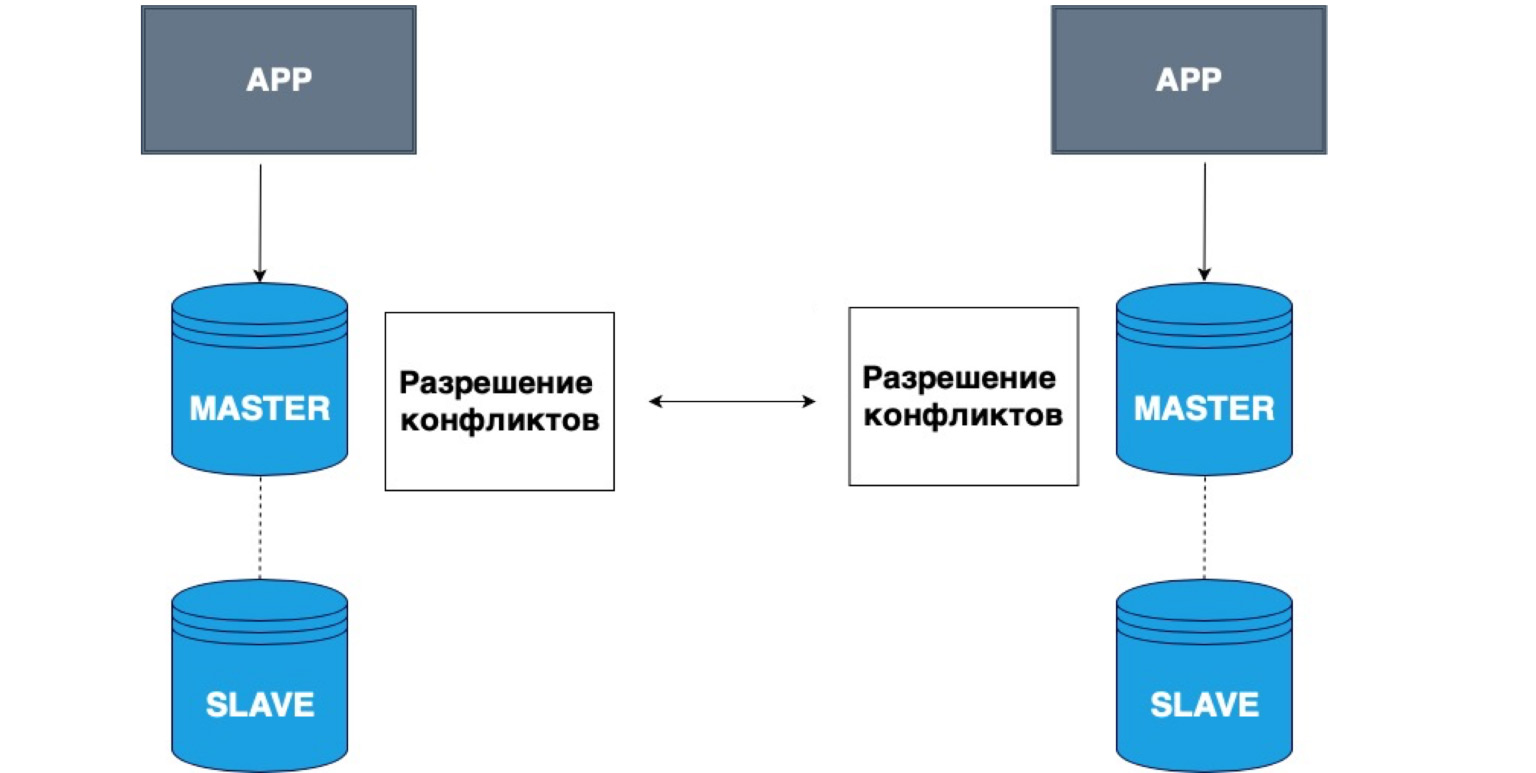
Um exemplo muito simples de uso de tais dados são todos os tipos de aplicativos offline. Por exemplo, você tem um calendário em seu telefone. Você se desconectou da rede e registrou um evento no calendário. Nesse caso, seu armazenamento local, seu telefone, é o Master. Ele mesmo armazenou os dados e, quando a rede Master aparecer, sua cópia local e a cópia no servidor resolverão os conflitos e combinarão esses dados.
Este é um exemplo muito simples de tal replicação. Geralmente é usado para edição colaborativa de documentos online ou quando há uma grande probabilidade de perda da rede.
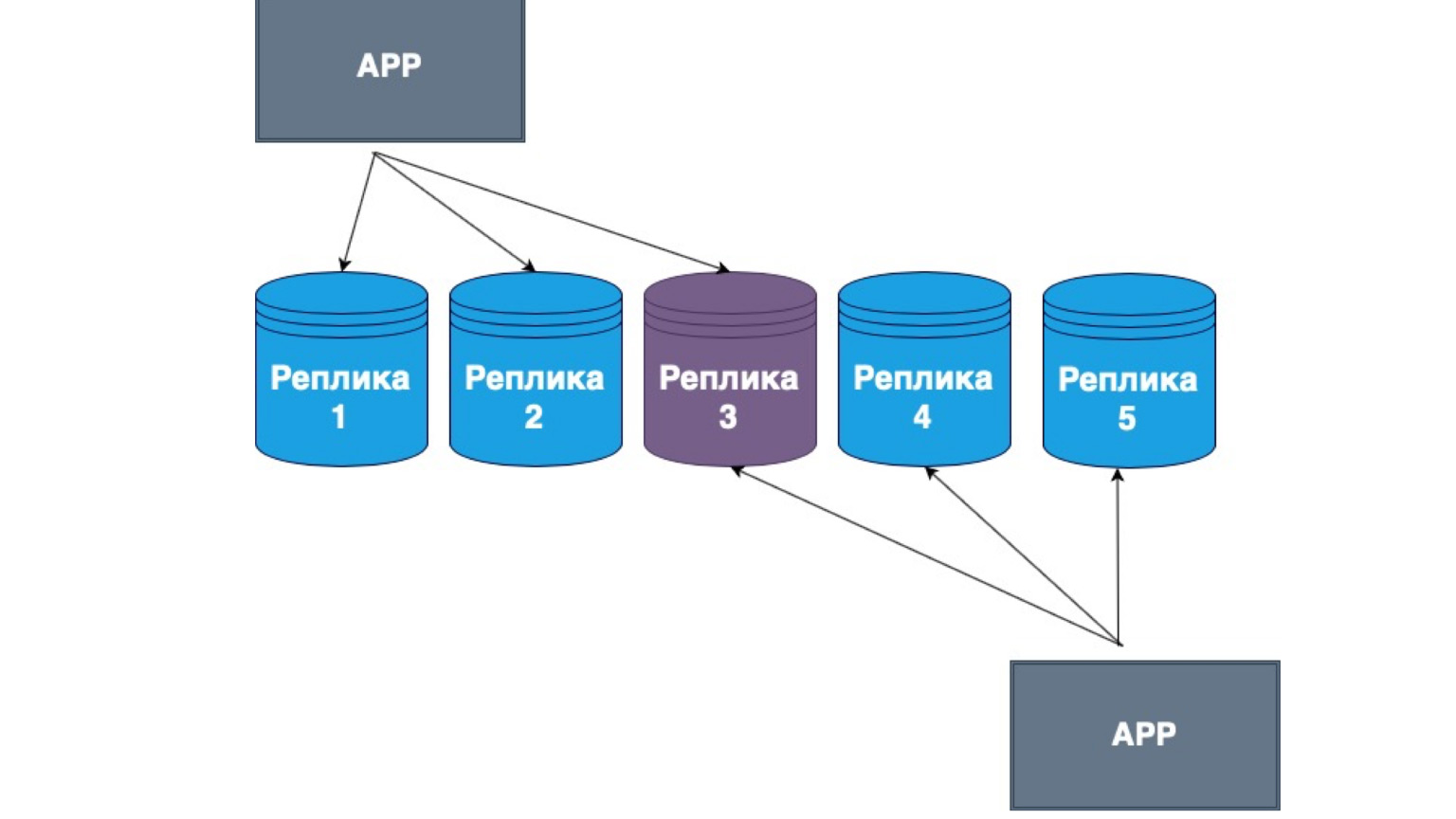
Também existem replicações masterless. O que é isso? Isso é replicação, em que o próprio cliente envia dados para a maioria das réplicas e os lê da maioria das réplicas também. Aqui você pode ver que nossa réplica do meio é a interseção de nossa leitura e atualização.
Ou seja, garantimos que cada vez que lermos os dados, entraremos em pelo menos uma das réplicas, em que os dados são mais relevantes. E entre si, as réplicas constroem um mecanismo de troca de informações com o log principal de alterações e conflitos entre réplicas. Nesse caso, muitas vezes é o cliente gordo que é implementado. Se ele recebeu dados de uma réplica que contém alterações mais recentes do que outra, ele simplesmente envia os dados para outra réplica ou resolve o conflito.

O que é importante saber sobre replicação? O principal ponto de replicação é a tolerância a falhas do sistema e a alta disponibilidade do seu servidor. Aconteça o que acontecer com a base de dados, o sistema estará disponível, seus usuários poderão gravar dados, e quando a conexão com o Master ou com outra réplica for restaurada, todos os dados também serão restaurados.
A replicação é muito útil para descarregar servidores e redistribuir solicitações de leitura do mestre para as réplicas. Podemos dimensionar essa leitura, criar mais réplicas de leitura e tornar nosso sistema ainda mais rápido. Você também pode fazer uma réplica de consultas analíticas complexas e de longo prazo que requerem um grande número de bloqueios e podem afetar a disponibilidade do sistema.
Usando aplicativos offline como exemplo, vimos como você pode armazenar esses dados e resolver conflitos. No caso de uma réplica síncrona, pode haver um atraso de replicação, ou seja, um atraso de tempo. No caso de uma réplica assíncrona, quase sempre está lá. Ou seja, quando você lê dados de uma réplica assíncrona, deve entender que pode não ser relevante.
De acordo com a hierarquia, esqueci de dizer que quando há um Mestre esperando uma resposta de uma réplica síncrona, é lógico supor que se todas as réplicas forem síncronas e algumas ficarem indisponíveis repentinamente, nosso sistema não será capaz de salvar a solicitação. Então, o Master irá nos escrever para o primeiro Slave síncrono, receber uma resposta, perguntar pelo segundo Slave, não receber nenhuma resposta e, como resultado, você terá que reverter toda a transação.
Portanto, em tais sistemas, como regra, uma réplica torna-se síncrona e o restante, assíncrono. A réplica síncrona garante que seus dados sejam salvos em outro lugar. Ou seja, além do Master, com o qual algo pode acontecer, garantimos que exista pelo menos mais um nó que contenha uma cópia completa exatamente do mesmo log de transações, dos mesmos dados.
A réplica assíncrona, por outro lado, não garante a integridade dos dados. Se tivermos apenas réplicas assíncronas e o mestre tiver se desconectado, eles podem ficar para trás, os dados podem não ter chegado lá ainda. Nesses casos, como regra, eles constroem uma hierarquia tal que ou temos Master, uma réplica síncrona e o resto são assíncronos, ou temos Master e todas as réplicas são assíncronas, se a persistência de dados não for importante para nós.
Existe um "mas": todas as réplicas devem ter a mesma configuração. Se falamos do PostgreSQL como exemplo, eles devem ter a mesma versão do próprio PostgreSQL, pois diferentes versões do banco de dados podem ter diferentes formatos de log. E se a réplica vier de uma versão diferente, ela simplesmente não pode ler as operações que a outra base escreveu.
O que é uma réplica? Esta é uma cópia completa de todos os dados. Digamos que haja tantos dados que o servidor não consiga lidar com eles. Qual é a primeira solução?
A primeira solução é comprar uma máquina mais cara com mais memória, uma CPU maior e um disco maior. Essa decisão será acertada em grande parte, desde que não se enfrente o problema do alto custo do ferro. Um dia será muito caro comprar um carro novo ou simplesmente não haverá onde crescer. Há uma enorme quantidade de dados que é simplesmente fisicamente impossível de caber em uma máquina.
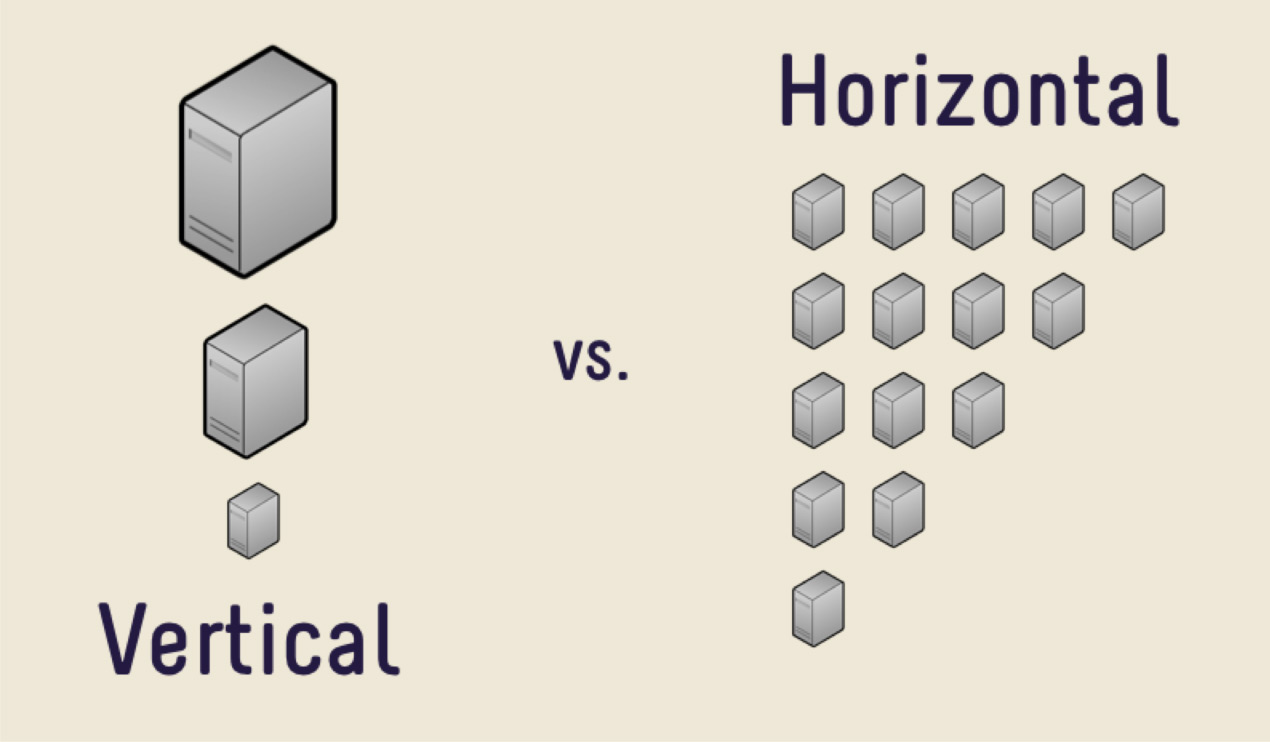
Nesses casos, você pode usar a escala horizontal. O que vimos anteriormente, o aumento no desempenho por máquina, é o dimensionamento vertical. O aumento no número de máquinas é a escala horizontal.
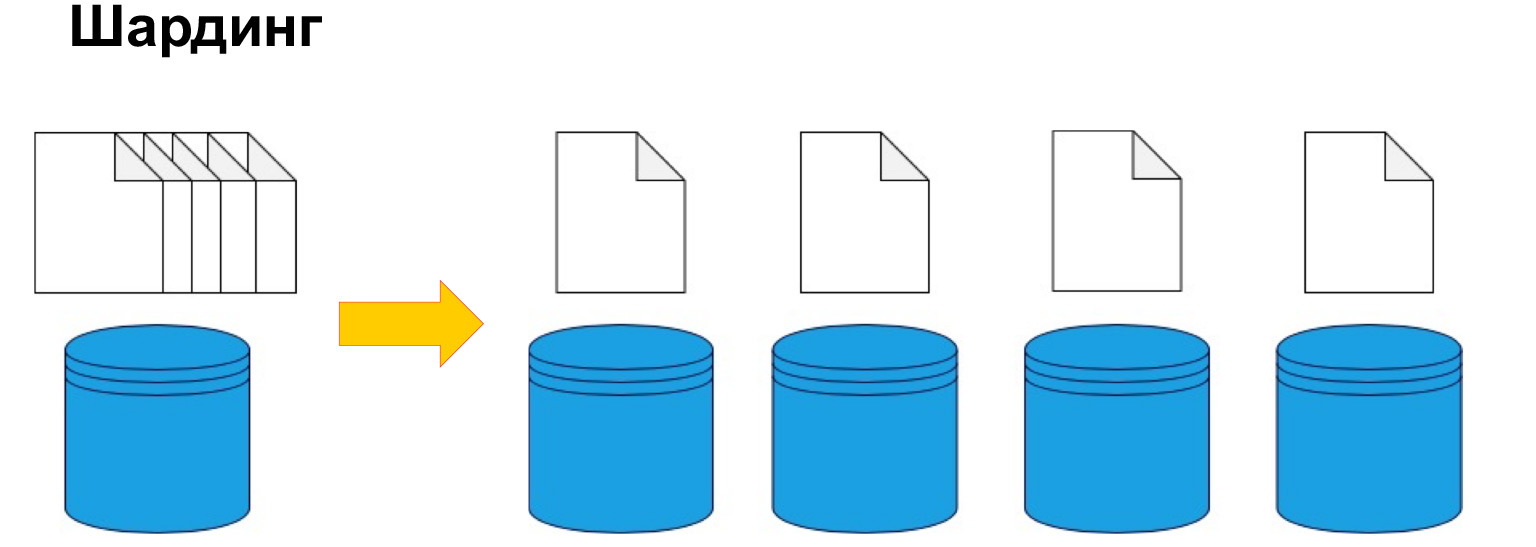
Para dividir dados por máquina, usa-se sharding ou, em outras palavras, particionamento. Ou seja, dividir os dados em seções e blocos por chave, por ID, por data. Falaremos mais sobre isso, esse é um dos parâmetros-chave, mas a questão é justamente dividir os dados de acordo com um determinado critério e enviá-los para máquinas diferentes. Assim, nossas máquinas podem se tornar menos eficientes, mas o sistema ainda pode funcionar e receber dados de máquinas diferentes.
Para entender de maneira geral onde estão os dados, você precisa de uma certa tabela de correspondência do fragmento, nossa cópia e dados.
Há momentos em que um armazenamento de dados especial não é usado e o cliente simplesmente caminha por sua vez até cada fragmento e verifica se há dados que correspondem à sua solicitação.
Existe uma camada de software especial que armazena certo conhecimento sobre qual fragmento está em qual intervalo de dados. E, portanto, vai exatamente lá, para o nó exato onde os dados necessários estão localizados.

Existe um cliente gordo. Isso ocorre quando não costuramos o próprio cliente em uma camada separada, mas costuramos nele os dados sobre como nossos dados são fragmentados.
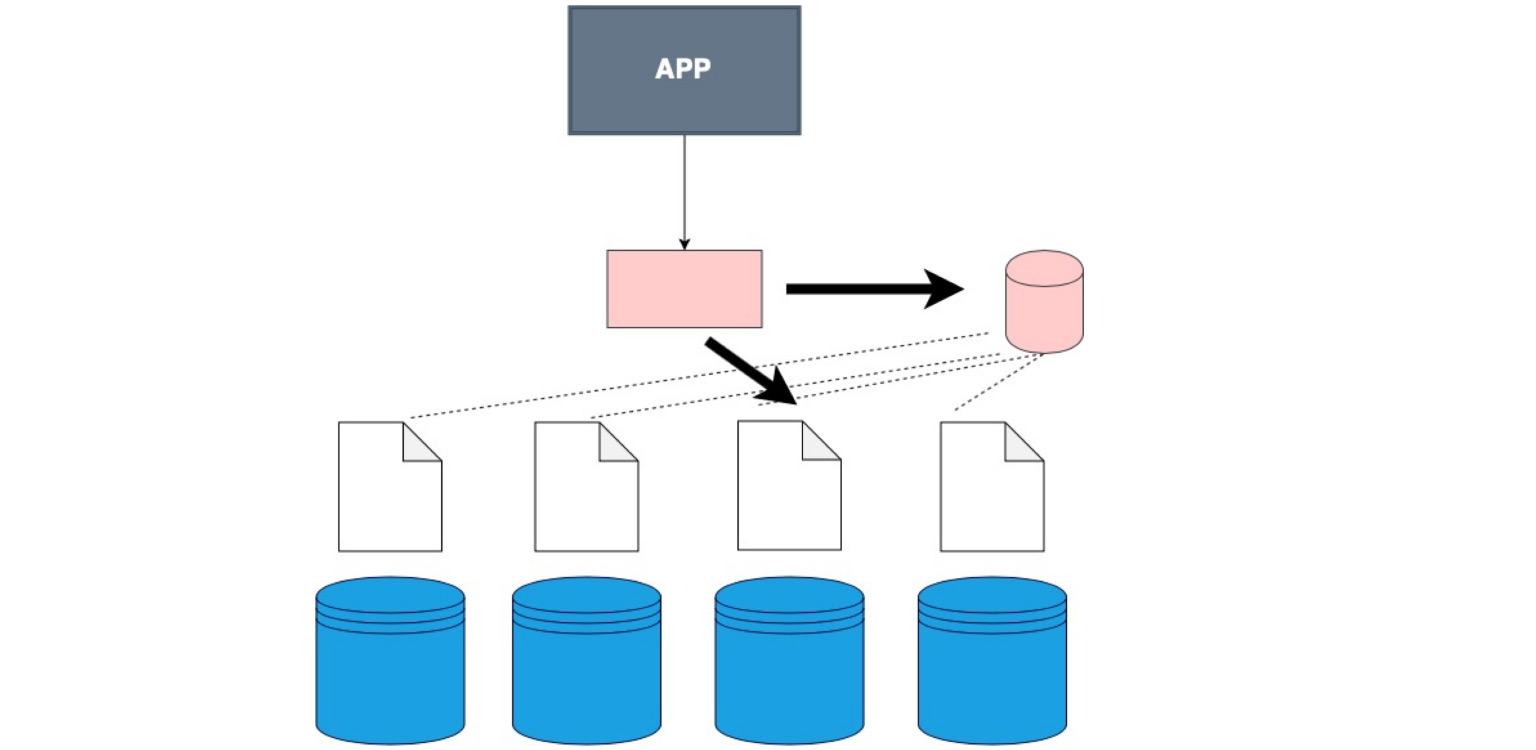
Este é o caso. Aliás, é o mais usado. O bom é que nossa aplicação, nosso cliente, mesmo o código que você escreve, não sabe que a tabela está fragmentada, embora indiquemos isso no config, no próprio banco de dados. Nós apenas dizemos a ela - selecione, e já no próprio banco de dados, há uma divisão em fragmentos e uma compreensão de onde selecionar. Aqui, no próprio código, você define de onde ler os dados.
Existem serviços especiais que auxiliam na estruturação e atualização geral das informações. É difícil mantê-lo consistente e relevante. Selecionamos algo, registramos novos dados. Ou algo mudou e precisamos encaminhar nossas solicitações muito corretamente. Existem serviços especiais para a coordenação de pedidos. Um deles é Zookeper. Você pode ver como eles funcionam em geral. Uma estrutura muito interessante. Eles economizaram muito tempo e nervos para os desenvolvedores.
O que é importante, quais aspectos manter em mente ao particionar? É importante entender qual chave usaremos para fragmentação. Recolher todos esses dados é muito caro, por isso é muito importante não se enganar sobre como os dados serão potencialmente usados no futuro. Se fizermos a fragmentação bem e corretamente, então, com as consultas usadas com mais frequência, sempre saberemos para qual réplica ir.
Por exemplo, se nós, de acordo com os IDs do usuário, armazenarmos todos os seus dados em certas réplicas, então entendemos que podemos chegar a essa réplica e fazer todas as junções nela. Mas mantê-lo por ID não é a ideia mais legal. Agora vou te dizer por quê.
Se identificamos incorretamente a chave no particionamento, se temos uma consulta muito complexa, então realmente temos que ir para diferentes fragmentos, combinar todos os dados e só então fornecê-los ao aplicativo. Felizmente, a maioria dos DBMSs faz isso por nós. Mas que tipo de sobrecarga viria em consultas mal escritas? Ou sob fragmentação, que está quebrado no nó errado?
Sobre IDs. Se o sistema só funcionar com novos usuários e tivermos aumento de IDs, todas as solicitações irão para o último nó.
O que acontece? As outras três máquinas em execução ficarão inativas. E este carro vai simplesmente queimar - o chamado ponto quente. Este é o gargalo do seu sistema potencial, o lugar que pode até recusar conexões.
Portanto, quando definimos a chave de fragmentação, é muito importante entender como esses nós serão equilibrados. Hashes são usados com muita frequência, este é um arranjo de dados mais ou menos neutro e equilibrado. Mas se você tiver uma função hash em uma chave, não será capaz de selecionar, por exemplo, por intervalos. É lógico, porque os intervalos não podem ser divididos em fragmentos diferentes.
Por data - o mesmo. Se, por exemplo, espalharmos análises e fizermos fragmentos por data, então, é claro, algum fragmento de dez anos atrás não será usado. Não é lucrativo para nós. E sempre é muito caro reconstruir os dados e sobrecarregar.
Vou responder à pergunta que veio antes. O que é melhor fazer - definir índices ou criar fragmentos? Índices, é claro.
Veja, os fragmentos são máquinas separadas com toda uma infraestrutura elevada. E esse componente do meio contém algo semelhante a índices. Há uma busca rápida por parâmetros - onde, para onde ir. Aqui está a proporção. Mas se houver fragmentação, a imagem final será assim:

Existem aplicativos, algum tipo de cabeça que sabe para onde ir. E há fragmentos, em cada um dos quais uma réplica é configurada. Esta é uma sobrecarga realmente grande se não houver muitos dados. Ou seja, você só precisa recorrer ao sharding quando realmente tiver atingido o limite de escala vertical, quando comprar uma máquina mais cara não for relevante para seus dados ou receita. Depois, você pode comprar vários carros diferentes e mais baratos e construir uma arquitetura neles.
Para que servem as réplicas, eu acho, é claro: como os fragmentos estão quebrados, eles são pedaços de bancos de dados, mas são únicos. Eles são encontrados apenas nesses lugares. Também os dividimos em cópias, o que torna nossos nós tolerantes a falhas e oferece segurança contra problemas.

O mais importante: a fragmentação é usada exatamente onde você não deseja apenas dividir os dados em classificação, mas exatamente onde há realmente muitos dados.
Agora vamos entrar mais em modelos de dados e ver como os dados podem ser armazenados.
As bases de dados relacionais que vimos anteriormente apresentam um grande número de vantagens, porque, antes de mais, são muito comuns e compreensíveis para todos. Eles mostram visualmente a relação entre os objetos e fornecem integridade.
Mas há uma desvantagem: eles exigem uma estrutura clara. Existe uma tabela na qual devemos enviar todos os dados. Se você olhar para todas as informações e fatos que coletamos em geral, eles são muito diferentes. Ou seja, podemos trabalhar com dados do produto, com dados do usuário, mensagens e assim por diante. Esses dados realmente requerem uma estrutura clara e integridade. Um banco de dados relacional é ideal para eles.
Mas suponha que temos, por exemplo, um log de operações ou uma descrição de objetos, onde cada objeto tem características diferentes. Nós, é claro, podemos escrever isso em um Jason em um banco de dados relacional e ficar contentes porque ele cresce conosco indefinidamente.
E podemos examinar outros esquemas, outros sistemas de armazenamento. NoSQL é uma abreviação muito chamativa, até mesmo diretamente provocativa - "sem SQL". Como isso aconteceu?
Quando as pessoas se depararam com o fato de que bancos de dados relacionais não são bem-sucedidos em todos os lugares, organizaram uma conferência, que precisava de uma hashtag, e criaram #NoSQL. Ele criou raízes. Mais tarde, eles começaram a dizer não “sem SQL”, mas “não apenas SQL”. É apenas qualquer coisa que não seja relacional: uma enorme família de bancos de dados diferentes que não são tão rigidamente estruturados, esquemáticos e tabulares quanto os bancos de dados relacionais.
A família de modelos de dados não relacionais é dividida em quatro tipos: banco de dados de valor-chave, orientado a documento, colunar e gráfico. Vamos considerar cada um desses pontos, descobrir quais dados são melhores para armazenar em quais deles e para que são usados.

Valor chave. Este é o mais simples. Aqui está o dicionário, aqui está a proporção. Este é um banco de dados no qual os dados são armazenados por chaves, e não importa o que está em uma chave específica. Temos a própria chave e os dados podem ser estruturas simples e muito mais complexas. A vantagem desse banco de dados é que, como um índice, ele pesquisa dados muito rapidamente. É por isso que o valor-chave é frequentemente usado para cache. A vantagem é que nosso valor pode ser diferente em chaves diferentes.
Podemos usar a chave, por exemplo, para armazenar sessões de usuário. O usuário clicou, nós escrevemos isso em valor. É um modelo de dados sem esquema, sem um esquema específico, estrutura de valor. Por ser uma estrutura muito simples, é rápida e fácil de escalar. Já temos as chaves e podemos facilmente fragmentá-las e criar seus hashes. É um dos bancos de dados mais escalonáveis.
Os exemplos são Redis, Memcached, Amazon DynamoDB, Riak, LevelDB. Você pode ver os recursos de implementação de armazenamentos de valores-chave.

Os bancos de dados de documentos são muito semelhantes aos valores-chave em alguns de seus usos. Mas sua unidade é um documento. Esta é uma estrutura tão complexa pela qual podemos selecionar certos dados, fazer operações em massa: inserção em massa, atualização em massa.
Cada documento pode armazenar em si, via de regra, XML, JSON ou BSON - JSON de armazenamento binário. Mas agora é quase sempre JSON ou BSON. Isso também é como um par de valores-chave, você pode imaginá-lo como uma tabela em que cada linha tem certas características, e podemos obter algo com essas chaves.
A vantagem dos bancos de dados orientados a documentos é que eles têm disponibilidade e flexibilidade de dados muito altas. Em qualquer documento, em qualquer JSON, você pode escrever absolutamente qualquer conjunto de dados. E são usados com muita frequência - por exemplo, quando você precisa criar um catálogo e quando cada produto do catálogo pode ter características diferentes.
Ou, por exemplo, perfis de usuário. Alguém apontou seu filme favorito, alguém - sua comida favorita. Para não grudar tudo em um campo, que vai armazenar não está claro o que, podemos escrever tudo em JSON de uma base de documentos.
Outro modelo conveniente para armazenar dados são os bancos de dados colunares. Eles também são chamados de banco de dados de colunas, colunas.

Esta é uma estrutura muito interessante que é usada, ao que me parece, em quase todos os projetos grandes e complexos. Tal banco de dados implica que armazenamos dados no disco, não em linhas, mas em colunas. Usado para pesquisas muito rápidas em uma grande quantidade de dados. Como regra - para análises, quando você precisa selecionar valores apenas de certas colunas.
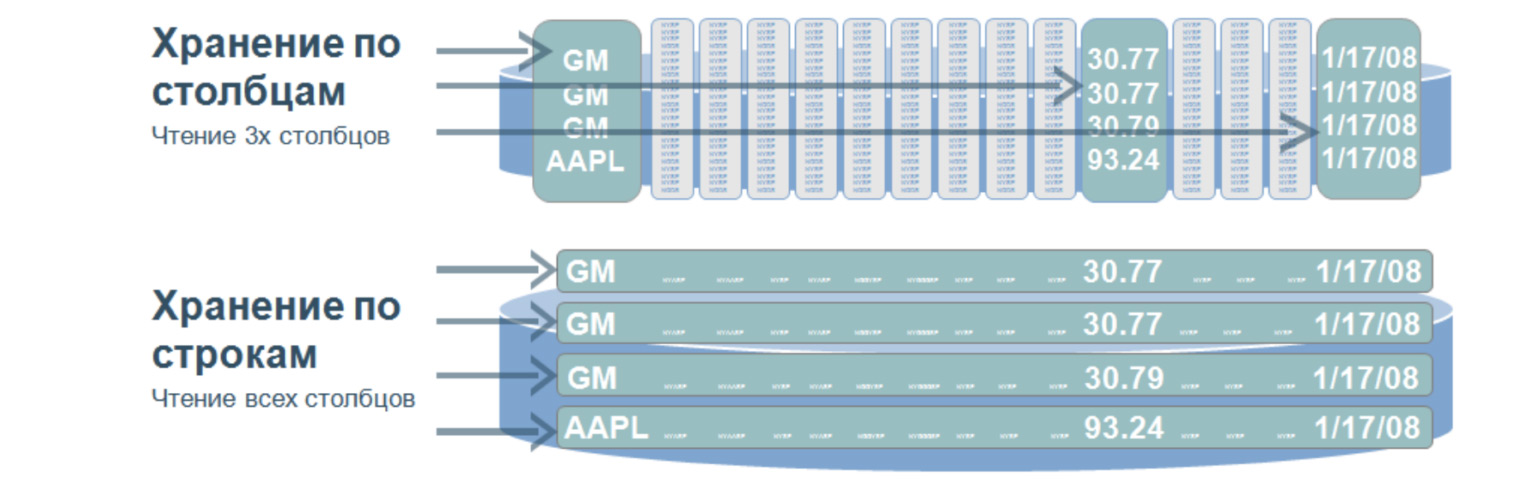
Vamos imaginar que temos uma mesa enorme. E se armazenássemos os dados em linhas, seria o que está abaixo: um grande número de linhas. Para selecionar até três parâmetros desta tabela, precisamos percorrer toda a tabela. E quando armazenamos valores por colunas, ao selecionar por três valores, precisamos passar por apenas três dessas linhas, grosso modo, porque nossas colunas são escritas assim. Passando por essas três linhas, obtemos imediatamente o número ordinal do valor de que precisamos e o obtemos das outras colunas.
Qual é a vantagem de tais bancos de dados? Pelo fato de buscarem uma pequena quantidade de dados, possuem uma velocidade de processamento de consultas muito alta e grande flexibilidade de dados, pois podemos adicionar qualquer quantidade de colunas sem alterar a estrutura. Aqui, ao contrário dos bancos de dados relacionais, não precisamos forçar nossos dados em determinados quadros.
Os colunares mais populares são provavelmente Cassandra, HBase e ClickHouse. Teste-os. É muito interessante inverter a proporção de linhas e colunas em sua cabeça. E isso é um acesso realmente eficiente e rápido a grandes quantidades de dados.

Também existe uma família de bancos de dados de gráficos. Eles também contêm nós e arestas. As arestas são usadas para mostrar relacionamentos, assim como em bancos de dados relacionais. Mas as bases dos gráficos podem crescer infinitamente em diferentes direções. Portanto, é mais flexível. Possui uma velocidade de pesquisa muito alta, pois não há necessidade de selecionar e unir todas as tabelas. Nosso nó imediatamente possui arestas que mostram a relação com todos os diferentes objetos.
Para que são usados esses bancos de dados? Na maioria das vezes - apenas para mostrar o relacionamento. Por exemplo, nas redes sociais, você pode responder à pergunta de quem está seguindo quem. Imediatamente temos links para todos os seguidores da pessoa certa. Ainda muito frequentemente, essas bases de dados são utilizadas para identificar esquemas de fraude, pois também está associada à demonstração da relação das transações entre si. Por exemplo, você pode rastrear quando o mesmo cartão do banco foi usado em outra cidade ou quando outra pessoa entrou na conta de outro usuário do mesmo endereço IP.
São esses relacionamentos complexos que ajudam a resolver situações incomuns que costumam ser usados para analisar tais interações e relacionamentos.
Os bancos de dados não relacionais não substituem os bancos de dados relacionais. Eles são apenas diferentes. Diferentes formatos de dados e diferentes lógicas de trabalho, nem pior nem melhor. É apenas uma abordagem diferente para outros dados. E sim, bancos de dados não relacionais são muito usados. Você não precisa ter medo deles, pelo contrário, você precisa experimentá-los.
Se você fizer um cache, então, é claro, pegue algum tipo de Redis, um valor-chave simples e rápido. Se você tiver um grande número de registros para análise, pode colocá-los no ClickHouse ou em alguma base colunar, o que será muito conveniente para pesquisar. Ou escreva na base de documentos, porque pode haver um significado diferente para documentos. Isso também pode ser útil para seleção.
Escolha um modelo de dados com base nos dados que você usará. Relacional ou não relacional. Descreva os dados. Dessa forma, você pode encontrar o armazenamento mais adequado que pode ser escalado no futuro.

Hoje você aprendeu muito sobre vários problemas e maneiras de armazenar dados. Vou repetir mais uma vez o que disse no início: você não precisa saber tudo em detalhes, você não precisa se aprofundar em nada. Se você estiver interessado, é claro que você pode. Mas é importante saber que existe em geral, que abordagens existem e como você pode pensar em geral. Se você precisa de tolerância a falhas, faz sentido fazer uma réplica. Suponha que eu anotei os dados, mas não os vejo. Então, provavelmente, minha observação deu um atraso. Não há necessidade de reinventar a roda - já existem muitas soluções prontas para diferentes tarefas. Expanda seus horizontes, e se aparecer um bug ou algum outro problema, você entenderá exatamente onde ocorreu a falha pelas características do bug, e poderá encontrar uma solução através de um mecanismo de busca. Obrigado pela atenção.