
O artigo discute o problema de limpar imagens que se acumulam em registros de contêiner (Docker Registry e seus análogos) nas realidades dos pipelines CI / CD modernos para aplicativos nativos em nuvem entregues ao Kubernetes. São apresentados os principais critérios de relevância das imagens e as dificuldades daí decorrentes na automatização da limpeza, economia de espaço e atendimento das necessidades das equipas. Finalmente, usando um exemplo de um projeto de código aberto específico, vamos contar como essas dificuldades podem ser superadas.
Introdução
O número de imagens no registro do contêiner pode crescer rapidamente, ocupando mais espaço de armazenamento e, consequentemente, aumentando significativamente seu custo. Para controlar, limitar ou manter um crescimento aceitável do espaço ocupado no cadastro, aceita-se:
- use um número fixo de tags para imagens;
- limpe as imagens de qualquer maneira.
A primeira limitação às vezes é válida para equipes pequenas. Se os desenvolvedores têm tag permanente suficiente (
latest, main, test, borisetc.), o registro não vai inchar em tamanho e pode ser um longo tempo para não pensar em limpeza. Afinal, todas as imagens irrelevantes estão desgastadas e simplesmente não há trabalho para limpar (tudo é feito por um coletor de lixo comum).
No entanto, essa abordagem limita severamente o desenvolvimento e raramente é aplicável a projetos de CI / CD hoje. A automação tornou-se parte integrante do desenvolvimentoque permite testar, implantar e entregar novas funcionalidades aos usuários com muito mais rapidez. Por exemplo, em todos os nossos projetos, um pipeline de CI é criado automaticamente a cada confirmação. Ele cria uma imagem, testa-a, lança-a em vários circuitos do Kubernetes para depuração e verificações restantes e, se tudo correr bem, as alterações chegam ao usuário final. E isso não é ciência de foguetes por muito tempo, mas a vida cotidiana de muitos - provavelmente para você, já que está lendo este artigo.
Uma vez que os bugs são corrigidos e novas funcionalidades são desenvolvidas em paralelo, e os lançamentos podem ser realizados várias vezes ao dia, é óbvio que o processo de desenvolvimento é acompanhado por um número significativo de commits, o que significa um grande número de imagens no registro... Como resultado, o problema de organizar uma limpeza de registro eficaz torna-se grave, ou seja, remoção de imagens irrelevantes.
Mas como saber se uma imagem está atualizada?
Critérios de relevância da imagem
Na grande maioria dos casos, os critérios principais serão os seguintes:
1. O primeiro (o mais óbvio e o mais crítico de todos) são as imagens que são usadas atualmente no Kubernetes . A remoção dessas imagens pode levar a sérios custos de paralisação da produção (por exemplo, imagens podem ser necessárias durante a replicação) ou anular os esforços da equipe que está envolvida na depuração em qualquer um dos circuitos. (Por esse motivo, criamos até um exportador especial do Prometheus que monitora a ausência dessas imagens em qualquer cluster do Kubernetes.)
2. O segundo (menos óbvio, mas também muito importante e novamente relacionado à operação) - imagens que precisam ser revertidas em caso de problemas graves problemasna versão atual. Por exemplo, no caso do Helm, essas são as imagens usadas nas versões salvas do lançamento. (Aliás, o limite padrão no Helm é de 256 revisões, mas quase ninguém realmente precisa salvar um número tão grande de versões? ..) Afinal, para isso, em particular, armazenamos versões para que você possa depois usar, ou seja, "Reverta" para eles, se necessário.
3. Terceiro - as necessidades dos desenvolvedores : todas as imagens que estão associadas ao seu trabalho atual. Por exemplo, se estamos considerando PR, então faz sentido deixar a imagem correspondente ao último commit e, digamos, ao commit anterior: desta forma o desenvolvedor pode retornar rapidamente a qualquer tarefa e trabalhar com as últimas mudanças.
4. Quarto - imagens quecorrespondem às versões de nosso aplicativo , ou seja, são o produto final: v1.0.0, 20.04.01, sierra, etc.
Nota: Os critérios aqui definidos foram formulados com base na experiência de interação com dezenas de equipas de desenvolvimento de diferentes empresas. No entanto, é claro, dependendo das especificações dos processos de desenvolvimento e da infraestrutura usada (por exemplo, o Kubernetes não é usado), esses critérios podem ser diferentes.
Elegibilidade e soluções existentes
Os serviços populares com registro de container, via de regra, oferecem suas próprias políticas de limpeza de imagens: neles você pode definir as condições sob as quais uma tag é removida do registro. No entanto, essas condições são limitadas por parâmetros como nomes, hora de criação e número de tags *.
* Depende de implementações específicas de registro de contêiner. Consideramos as possibilidades das seguintes soluções: Azure CR, Docker Hub, ECR, GCR, GitHub Packages, GitLab Container Registry, Harbor Registry, JFrog Artifactory, Quay.io - em setembro de 2020.
Este conjunto de parâmetros é suficiente para satisfazer o quarto critério - ou seja, selecionar imagens que correspondam às versões. No entanto, para todos os outros critérios, é necessário escolher algum tipo de solução de compromisso (mais dura ou, inversamente, política econômica) - dependendo das expectativas e capacidades financeiras.
Por exemplo, o terceiro critério - relacionado às necessidades dos desenvolvedores - pode ser resolvido organizando processos dentro das equipes: nomenclatura específica de imagens, manutenção de listas especiais de permissões e acordos internos. Mas, em última análise, ainda precisa ser automatizado. E se as possibilidades de soluções prontas não forem suficientes, você deve fazer algo por si mesmo.
A situação é semelhante com os dois primeiros critérios: eles não podem ser satisfeitos sem receber dados de um sistema externo - aquele em que os aplicativos são implantados (em nosso caso, é o Kubernetes).
Ilustração de um fluxo de trabalho no Git
Suponha que você trabalhe assim no Git: o
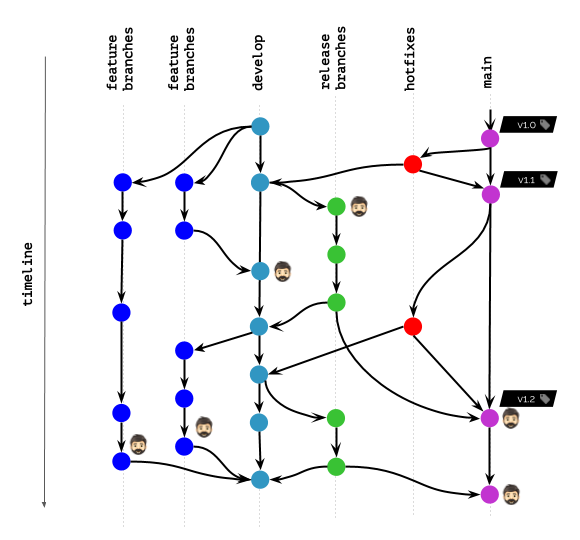
ícone com um cabeçalho no diagrama marca as imagens do contêiner que estão atualmente implantadas no Kubernetes para qualquer usuário (usuários finais, testadores, gerentes, etc.) ou são usadas por desenvolvedores para depuração e objetivos semelhantes.
O que acontecerá se as políticas de limpeza permitirem que você mantenha (não exclua) imagens apenas para os nomes de tag especificados ?

Obviamente, este cenário não agradará a ninguém.
O que mudará se as políticas permitirem que você não exclua imagens por um determinado intervalo de tempo / número de confirmações recentes ?

O resultado ficou muito melhor, mas ainda longe do ideal. Afinal, ainda temos desenvolvedores que precisam de imagens no registro (ou mesmo implantadas no K8s) para depurar bugs ...
Resumindo a situação atual do mercado: as funções disponíveis nos registros de contêineres não oferecem flexibilidade suficiente na limpeza, e o principal motivo é que não há possibilidade interagir com o mundo exterior . Acontece que as equipes que precisam dessa flexibilidade são forçadas a implementar de forma independente a remoção da imagem "externa" usando a API Docker Registry (ou a API nativa da implementação correspondente).
No entanto, estávamos procurando uma solução universal que automatizasse a limpeza de imagens para diferentes equipes usando diferentes registros ...
Nosso caminho para a limpeza universal de imagens
De onde vem essa necessidade? O fato é que não somos um grupo separado de desenvolvedores, mas uma equipe que atende muitos deles ao mesmo tempo, ajudando a resolver problemas de CI / CD de forma abrangente. E a principal ferramenta técnica para isso é o utilitário werf de código aberto . Sua peculiaridade é que não desempenha uma função única, mas acompanha os processos de entrega contínua em todas as etapas: da montagem à implantação.
Publicar imagens no registro * (imediatamente depois de construídas) é uma função óbvia desse utilitário. E uma vez que as imagens são colocadas lá para armazenamento, então - se o armazenamento não for ilimitado - você precisa ser responsável pela limpeza subsequente. Como obtivemos sucesso nisso, satisfazendo todos os critérios especificados, será discutido mais adiante.
* Embora os próprios registros possam ser diferentes (Docker Registry, GitLab Container Registry, Harbor, etc.), seus usuários enfrentam os mesmos problemas. A solução universal em nosso caso não depende da implementação do registro, uma vez que é executado fora dos próprios registros e oferece o mesmo comportamento para todos.
Apesar de estarmos usando o werf como exemplo de implementação, esperamos que as abordagens utilizadas sejam úteis para outras equipes que enfrentam dificuldades semelhantes.
Então, pegamos o externoimplementação de um mecanismo para limpar imagens - em vez dos recursos que já estão integrados aos registros de contêineres. A primeira etapa foi usar a API Docker Registry para criar todas as mesmas políticas primitivas pelo número de tags e o tempo de sua criação (mencionado acima). Uma lista de permissões foi adicionada a eles com base nas imagens usadas na infraestrutura implantada , ou seja, Kubernetes. Para o último, bastava, por meio da API Kubernetes, percorrer todos os recursos implantados e obter uma lista de valores
image.
Essa solução trivial fechou o problema mais crítico (critério nº 1), mas foi apenas o início de nossa jornada para melhorar o mecanismo de limpeza. A próxima - e muito mais interessante - etapa foi a decisão de associar as imagens publicadas com a história do Git .
Esquemas de etiquetagem
Para começar, escolhemos uma abordagem em que a imagem final deve armazenar as informações necessárias para a limpeza e construímos o processo em esquemas de marcação. Ao publicar uma imagem, o usuário selecionou uma determinada opção de marcação (
git-branch, git-commitou git-tag) e usou o valor correspondente. Em sistemas de CI, esses valores foram definidos automaticamente com base nas variáveis de ambiente. Basicamente, a imagem final foi associada a uma primitiva Git específica , armazenando os dados necessários para limpeza nos rótulos.
Essa abordagem resultou em um conjunto de políticas que permitiram que o Git fosse usado como a única fonte da verdade:
- Ao excluir um branch / tag no Git, as imagens associadas no registro também foram excluídas automaticamente.
- O número de imagens associadas a tags Git e commits pode ser controlado pelo número de tags usadas no esquema escolhido e a hora em que o commit associado foi criado.
Em geral, a implementação resultante atendeu às nossas necessidades, mas logo um novo desafio nos esperava. O fato é que, durante o uso de esquemas de tagging para primitivos Git, encontramos uma série de deficiências. (Como a descrição deles está além do escopo deste artigo, qualquer pessoa pode ler os detalhes aqui .) Portanto, depois de decidir mudar para uma abordagem mais eficiente de marcação (marcação baseada em conteúdo), tivemos que revisar a implementação da limpeza de imagens.
Novo algoritmo
Por quê? Quando marcada como baseada em conteúdo, cada tag pode acomodar vários commits no Git. Ao limpar imagens, você não pode mais confiar apenas no commit no qual a nova tag foi adicionada ao registro.
Para o novo algoritmo de limpeza, foi decidido abandonar os esquemas de marcação e construir o processo em meta-imagens , cada uma das quais armazena um monte de:
- o commit no qual a publicação foi realizada (não importa se a imagem foi adicionada, alterada ou permaneceu a mesma no registro do container);
- e nosso identificador interno correspondente à imagem construída.
Em outras palavras, as tags publicadas foram vinculadas aos commits no Git .
Configuração final e algoritmo geral
Ao configurar a limpeza, os usuários agora têm acesso às políticas pelas quais a seleção das imagens reais é realizada. Cada uma dessas políticas é definida:
- múltiplas referências, ou seja, Tags Git ou branches do Git que são usados durante o rastreamento;
- e o limite de imagens necessárias para cada referência do conjunto.
Para ilustrar, é assim que a configuração da política padrão começou a parecer:
cleanup:
keepPolicies:
- references:
tag: /.*/
limit:
last: 10
- references:
branch: /.*/
limit:
last: 10
in: 168h
operator: And
imagesPerReference:
last: 2
in: 168h
operator: And
- references:
branch: /^(main|staging|production)$/
imagesPerReference:
last: 10
Esta configuração contém três políticas que obedecem às seguintes regras:
- Salve uma imagem para as últimas 10 tags Git (na data em que a tag foi criada).
- Salve no máximo 2 imagens publicadas na última semana, para no máximo 10 agências com atividade na última semana.
- Economize 10 imagens para cada ramo
main,stagingeproduction.
O algoritmo final é reduzido às seguintes etapas:
- Obtendo manifestos do registro do contêiner.
- Excluindo imagens usadas no Kubernetes porque nós já os pré-selecionamos pesquisando a API K8s.
- Verificando o histórico do Git e excluindo imagens de acordo com as políticas especificadas.
- Removendo as imagens restantes.
Voltando à nossa ilustração, aqui está o que acontece com o werf:
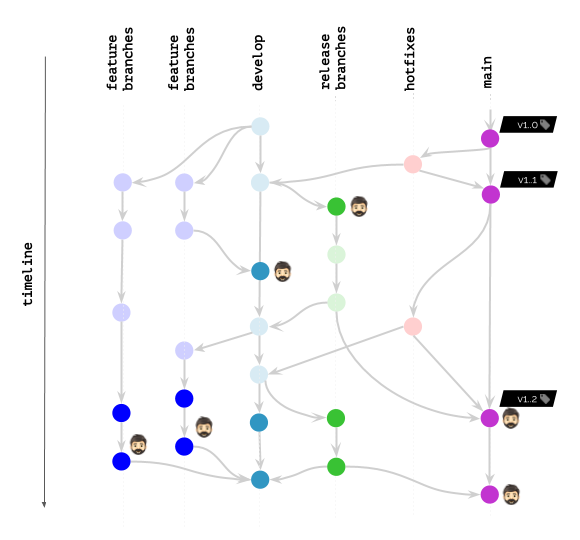
No entanto, mesmo se você não usar o werf, uma abordagem semelhante à limpeza avançada de imagens - em uma implementação ou outra (de acordo com a abordagem preferida para marcar imagens) - pode ser aplicada em outros sistemas também. / Serviços de utilidade pública. Para fazer isso, basta lembrar dos problemas que surgem e encontrar as oportunidades em sua pilha que permitem construir a solução da maneira mais suave. Esperamos que o caminho que percorremos ajude a olhar para o seu caso particular com novos detalhes e pensamentos.
Conclusão
- Mais cedo ou mais tarde, a maioria das equipes enfrenta o problema de estouro de registro.
- Na hora de buscar soluções, antes de mais nada, é preciso determinar os critérios de relevância da imagem.
- As ferramentas oferecidas pelos populares serviços de registro de contêiner permitem uma limpeza muito simples que não leva em consideração o "mundo externo": as imagens usadas no Kubernetes e as especificações dos fluxos de trabalho da equipe.
- Um algoritmo flexível e eficiente deve compreender os processos de CI / CD e operar não apenas com dados de imagem Docker.
PS
Leia também em nosso blog: