
O Amazon SageMaker oferece mais do que apenas a capacidade de gerenciar notebooks no Jupyter, mas um serviço configurável que permite criar, treinar, otimizar e implantar modelos de aprendizado de máquina. Um equívoco comum, especialmente ao começar a usar o SageMaker, é que você precisa da instância do notebook SageMaker ou do notebook SageMaker (Studio) para usar esses serviços. Na verdade, você pode executar todos os serviços diretamente de seu computador local ou mesmo de seu IDE favorito.
Antes de prosseguirmos, vamos dar uma olhada em como interagir com os serviços do Amazon SageMaker. Você tem duas APIs:
SageMaker Python SDK - uma API Python de alto nível que abstrai o código para construir, treinar e implantar modelos de aprendizado de máquina. Em particular, ele fornece avaliadores para algoritmos de primeira classe ou integrados e também oferece suporte a estruturas como TensorFlow, MXNET, etc. Na maioria dos casos, você o usará para interagir com tarefas interativas de aprendizado de máquina.
SDK AWSÉ uma API de baixo nível usada para se comunicar com todos os serviços AWS compatíveis, não necessariamente para SageMaker. O AWS SDK está disponível para as linguagens mais populares, como Java, Javascript, Python (boto), etc. Na maioria dos casos, você usará esta API para coisas como criar recursos de automação ou interagir com outros serviços AWS que não são suportados pelo SageMaker Python SDK.
Por que meio ambiente local?
Custo é a primeira coisa que vem à mente, mas também a flexibilidade de usar seu IDE nativo e a capacidade de trabalhar offline e executar tarefas na nuvem AWS quando pronto desempenham um papel importante.
Como funciona o ambiente local
Você escreve o código para construir o modelo, mas em vez de uma instância do SageMake Notebook ou SageMaker Studio Notebook, você o faz em sua máquina local em Jupyter ou em seu IDE. Então, quando tudo estiver pronto, você começará a treinar nas instâncias do SageMaker no AWS. Após o treinamento, o modelo será armazenado na AWS. Você pode então executar a implantação ou conversão em lote de sua máquina local.
Configurando o ambiente com conda
É recomendado configurar um ambiente virtual Python. No nosso caso, usaremos o conda para gerenciar ambientes virtuais, mas você pode usar o virtualenv. Novamente, o Amazon SageMaker usa conda para gerenciar ambientes e pacotes. Presume-se que você já tenha o conda instalado, se não, clique aqui .
Crie um novo ambiente conda
conda create -n sagemaker python=3Nós ativamos e verificamos o ambiente

Instalando os pacotes necessários
Para instalar pacotes, use os comandos
condaou pip. Vamos escolher a opção com conda .
conda install -y pandas numpy matplotlibInstalação de pacotes AWS
Instale o AWS SDK para Python (boto), awscli e SageMaker Python SDK. O SageMaker Python SDK não está disponível como um pacote conda, então vamos apenas usá-lo aqui
pip.
pip install boto3 awscli sagemakerSe esta é a primeira vez que usa o awscli, você precisa configurá-lo. Aqui você pode ver como fazer.
A segunda versão do SageMaker Python SDK será instalada por padrão. Certifique-se de verificar se há mudanças significativas na segunda versão do SDK.
Instalando o Jupyter e construindo o núcleo
conda install -c conda-forge jupyterlab
python -m ipykernel install --user --name sagemakerVerificamos o ambiente e verificamos as versões
Inicie o Jupyter por meio do jupyter lab e selecione o núcleo
sagemakerque criamos acima.
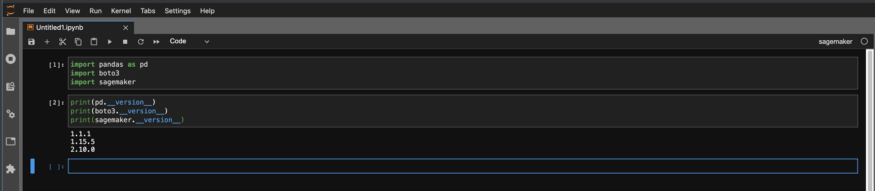
Em seguida, verifique as versões no bloco de notas para ter certeza de que são as que você deseja.
Nós criamos e treinamos
Agora você pode começar a construir seu modelo localmente e começar a aprender na AWS quando estiver pronto.
Importando pacotes
Importe os pacotes necessários e especifique a função. A principal diferença aqui é que você precisa especificar
arnfunções diretamente , não get_execution_role(). Como você está executando tudo em sua máquina local com credenciais AWS e não em uma instância de notebook com uma função, o recurso get_execution_role()não funcionará.
from sagemaker import image_uris # Use image_uris instead of get_image_uri
from sagemaker import TrainingInput # Use instead of sagemaker.session.s3_input
region = boto3.Session().region_name
container = image_uris.retrieve('image-classification',region)
bucket= 'your-bucket-name'
prefix = 'output'
SageMakerRole='arn:aws:iam::xxxxxxxxxx:role/service-role/AmazonSageMaker-ExecutionRole-20191208T093742'Crie um avaliador
Crie um avaliador e defina hiperparâmetros como faria normalmente. No exemplo abaixo, treinamos um classificador de imagem usando o algoritmo de classificação de imagem integrado. Você também especifica o tipo de instância do Stagemaker e o número de instâncias que deseja usar para treinamento.
s3_output_location = 's3://{}/output'.format(bucket, prefix)
classifier = sagemaker.estimator.Estimator(container,
role=SageMakerRole,
instance_count=1,
instance_type='ml.p2.xlarge',
volume_size = 50,
max_run = 360000,
input_mode= 'File',
output_path=s3_output_location)
classifier.set_hyperparameters(num_layers=152,
use_pretrained_model=0,
image_shape = "3,224,224",
num_classes=2,
mini_batch_size=32,
epochs=30,
learning_rate=0.01,
num_training_samples=963,
precision_dtype='float32')
Canais de aprendizagem
Especifique os canais de aprendizagem da maneira que você sempre faz, também não há mudanças em comparação com como você faria em sua cópia do caderno.
train_data = TrainingInput(s3train, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
validation_data = TrainingInput(s3validation, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
train_data_lst = TrainingInput(s3train_lst, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
validation_data_lst = TrainingInput(s3validation_lst, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
data_channels = {'train': train_data, 'validation': validation_data,
'train_lst': train_data_lst, 'validation_lst': validation_data_lst}Começamos a treinar
Inicie a tarefa de treinamento no SageMaker chamando o método fit, que iniciará o treinamento em suas instâncias SageMaker AWS.
classifier.fit(inputs=data_channels, logs=True)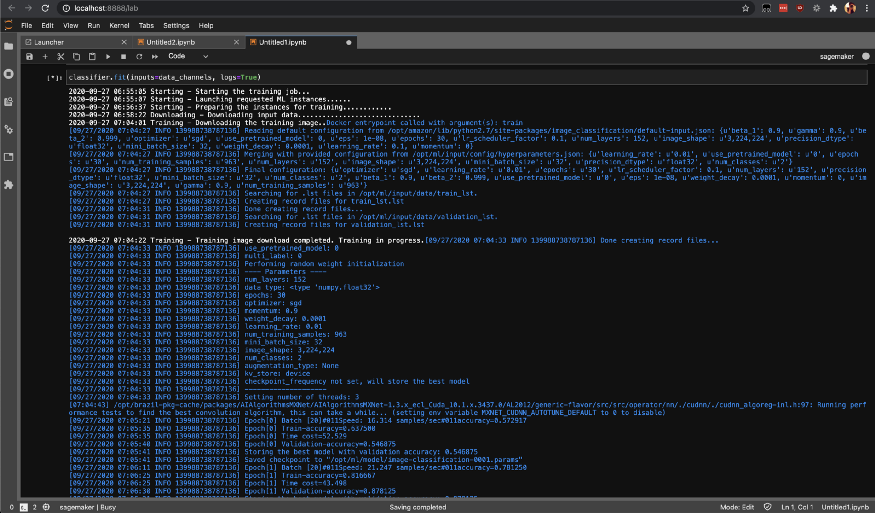
Você pode verificar o status dos jobs de treinamento com list-training-jobs .
Isso é tudo. Hoje descobrimos como configurar localmente o ambiente SageMaker e construir modelos de aprendizado de máquina em uma máquina local usando Jupyter. Além do Jupyter, você pode fazer o mesmo a partir de seu próprio IDE.
Bom aprendizado!
