Muitas vezes acontece quando há muitas conversões, o preço é aceitável e as vendas não crescem e até caem. Aqui, a análise "antes do lucro por clique" não é mais suficiente para descobrir o motivo. E então a análise "antes do lucro do gerente" vem em socorro. Porque não importa o quão ideal seja a configuração da propaganda, os clientes primeiro interagem com os gerentes e só então tomam uma decisão. O sucesso do seu negócio depende da qualidade do trabalho dos seus funcionários.
Os sistemas analíticos tradicionais usam CRM para registrar o fato de uma venda / contato com um gerente. No entanto, essa abordagem resolve apenas parcialmente o problema: ela avalia a eficiência do funcionário "no resultado final". Ou seja, mostra vendas e conversão, mas deixa a própria comunicação com o cliente “no mar”. Mas o resultado depende do nível de comunicação.
Para preencher essa lacuna, desenvolvemos uma ferramenta que vinculará automaticamente cada chamada ao gerente que a tratou. Você não precisa usar CRM e serviços de terceiros. Na verdade, nosso sistema coloca uma tag "nome do gerente" em cada chamada recebida.
Assim, os chefes do departamento de vendas / atendimento ao cliente controlarão a qualidade do trabalho, encontrarão áreas problemáticas e desenvolverão análises. A segmentação rápida das chamadas para os gerentes que as recebem ajudará nisso.
Formulação do problema
A tarefa que nos propomos é a seguinte: permitir que o sistema conheça os padrões de fala de todos os gerentes que podem receber chamadas. Então, para uma nova chamada, você precisa marcar o gerente, cuja voz é a mais "semelhante" na conversa da lista de conhecidos.
Nesse caso, considera-se a priori que a nova ligação foi bem-sucedida. Ou seja, a conversa entre o gerente e o cliente realmente aconteceu. Informalmente, essa tarefa pode ser atribuída à aula de tarefas de "ensinar com professor", ou seja, classificação.
Como objetos - de alguma forma gravações de áudio vetorizadas (digitalizadas), onde soa apenas a voz do gerente. As respostas são rótulos de classe (nomes de gerentes). Então, a tarefa do algoritmo de marcação é:
- Extração de recursos significativos de arquivos de áudio
- Escolha do algoritmo de classificação mais adequado
- Aprendendo o algoritmo e economizando modelos de gerenciador
- Avaliando a qualidade do algoritmo e modificando seus parâmetros
- Marcação (classificação) de novas chamadas
Algumas dessas tarefas se enquadram em subtarefas separadas. Isso se deve às especificidades das condições nas quais o algoritmo deve operar. Geralmente, as chamadas telefônicas são barulhentas. Um cliente em uma conversa pode se comunicar com vários gerentes. Além disso, não ocorrerá de forma alguma e as chamadas geralmente incluem IVR, etc.
Por exemplo, a tarefa de marcar novas chamadas pode ser dividida em:
- Verificar o sucesso da chamada (o fato de haver uma chamada)
- Divisão de estéreo em faixas mono
- Filtro de ruído
- Identificação de áreas com fala (filtragem de música e outros sons estranhos)
No futuro, falaremos sobre cada uma dessas subtarefas separadamente. Nesse ínterim, formularemos as restrições técnicas que impomos aos dados de entrada, à solução resultante, bem como ao próprio algoritmo de classificação.
Restrições de solução
A necessidade de restrições é parcialmente ditada pela técnica e pelos requisitos da complexidade de implementação, e também pelo equilíbrio entre a universalidade do algoritmo e a precisão de sua operação.
Limitações no arquivo de entrada e nos arquivos de amostra de treinamento:
- Formato - wav ou wave (você pode recodificar posteriormente para mp3)
- O estéreo deve posteriormente ser dividido em 2 faixas - o operador e o cliente
- Taxa de amostragem - 16.000 Hz e acima
- Profundidade de bits - de 16 bits e mais
- O arquivo de treinamento do modelo deve ter pelo menos 30 segundos de duração e conter apenas a voz de um gerente específico
- , , ,
Todos os requisitos acima, exceto o último, foram formulados a partir de uma série de experimentos realizados na fase de configuração dos algoritmos. Esta combinação tem se mostrado a mais eficaz em termos de minimização da probabilidade de erro, ou seja, má classificação em condições de ajuste fácil.
Por exemplo, é óbvio que quanto mais longo o arquivo no conjunto de treinamento, mais preciso será o classificador. Mas o mais difícil é encontrar esse arquivo no registro de chamadas (nosso exemplo de treinamento). Portanto, a duração de 30 segundos é um meio-termo entre a precisão e a complexidade das configurações. O último requisito (sucesso) é necessário. O sistema não deve marcar um gerente para uma chamada em que realmente não houve conversa.
As limitações do algoritmo levaram à seguinte solução:
- , . « ». . - , .
- . , , .
O primeiro requisito veio da experimentação. Então, descobriu-se que o gerente "desconhecido" complicava a arquitetura da solução. Para isso é necessário selecionar os limites a partir dos quais o funcionário será classificado como “não reconhecido”. Além disso, o gerente "desconhecido" reduz a precisão em 10 pontos percentuais.
Além disso, um erro do segundo tipo aparece quando um gerente conhecido é classificado como desconhecido. A probabilidade de tal erro é de 7 a 10%, dependendo do número de erros conhecidos. Esse requisito pode ser chamado de essencial. Ele obriga o sintonizador de algoritmo a indicar todos os gerentes na amostra de treinamento. E também introduzir modelos de novos funcionários lá e remover aqueles que pediram demissão.
O segundo requisito vem de considerações práticas e da arquitetura do algoritmo que estamos usando. Resumindo, o algoritmo quebra o áudio analisado em fragmentos de fala e "compara" cada um com todos os modelos de gerenciadores treinados, um por um.
Como resultado, uma "minitag" é atribuída a cada um dos minifragmentos. Com essa abordagem, há uma grande probabilidade de que alguns dos fragmentos sejam reconhecidos incorretamente. Por exemplo, se eles permanecerem barulhentos ou se seu comprimento for muito curto.
Então, se todas as "mini-tags" forem exibidas na solução final, então, além da tag do gerenciador real, várias "lixeira" serão exibidas. Portanto, apenas a tag mais "frequente" é exibida.
Descrição dos dados de entrada / saída
Dividiremos os dados de entrada em 2 tipos:
Dados na entrada do algoritmo de geração de modelos de gestores (dados para treinamento):
- Arquivo de áudio + etiqueta da classe
Dados na entrada do algoritmo de marcação (dados para teste / operação normal):
- Dados externos (arquivo de áudio)
- Dados internos (modelos salvos)
A saída também é dividida em 2 tipos:
- Dados de saída do algoritmo de geração de modelo
- Modelos de gerentes treinados
- Saída do algoritmo de marcação
- Tag de gerente
Um arquivo de áudio que atenda aos requisitos é recebido na entrada do algoritmo em qualquer modo de seu funcionamento. Eles estão na seção "restrições".
Na entrada do algoritmo de geração do modelo, é permitido que vários arquivos de entrada correspondam a uma classe (gerenciador). Mas um arquivo não pode corresponder a vários gerentes. O nome do rótulo da classe pode ser colocado no nome do arquivo. Ou apenas crie um diretório separado para cada funcionário.
O algoritmo de treinamento do modelo com base nos dados de entrada gera muitos modelos que podem ser carregados durante o treinamento. Seu número corresponde ao número de tags diferentes no conjunto de arquivos de áudio.
Assim, se houver M arquivos marcados com n rótulos de classe diferentes, então o algoritmo no estágio de treinamento cria n modelos de gerentes:
- Model_manager_1.pkl
- Model_manager_2.pkl
- ...
- Model_manager_n.pkl
onde em vez de " gerente _... " é o nome da classe.
A entrada para o algoritmo de etiquetagem é um arquivo de áudio sem etiqueta, no qual a priori há uma conversa entre um gerente e um cliente, além de n modelos de funcionários. Como resultado, o algoritmo retorna uma tag - o nome da classe do gerenciador mais "plausível".
Pré-processamento de dados
Os arquivos de áudio são pré-processados. É sequencial e é executado no modo de marcação e no modo de treinamento do modelo:
- Verificar o sucesso da chamada - apenas na fase de etiquetagem
- Dividir o estéreo em 2 faixas mono e trabalhar posteriormente apenas com a faixa do operador
- Digitalização - extração de parâmetros de sinal de áudio
- Filtro de ruído
- Removendo pausas "longas" - identificando fragmentos com som
- Filtrando fragmentos que não são de fala - remova música, fundo, etc.
- Fusão de fragmentos com a fala (apenas na fase de treinamento)
Não nos deteremos no estágio de verificação de sucesso. Este é um assunto para um artigo separado. Resumindo, a essência do palco é que a chamada é classificada de acordo com se há uma conversa de "pessoas vivas" nela. Por “pessoas vivas”, queremos dizer um cliente e um gerente, não um assistente de voz, música, etc.
O sucesso de uma chamada é verificado usando um classificador especialmente treinado com um limite externo - “a duração mínima de uma conversa após a qual a chamada é considerada bem-sucedida”.
No segundo estágio, o arquivo estéreo é dividido em 2 trilhas: o gerenciador e o cliente. O processamento posterior é realizado apenas para a trilha do funcionário.
Na etapa de digitalização, os parâmetros do “recurso” são extraídos da pista do operador, que são uma representação digital do sinal. Nós da Calltouch usamos componentes de giz cepstral. Além disso, os parâmetros são extraídos em um fragmento muito pequeno, que é chamado de largura da janela (0,025 segundos). Todos os recursos são normalizados ao mesmo tempo.
nfft=2048 //
appendEnergy = False
def get_MFCC(sr,audio): // , sr=16000 -
features = mfcc.mfcc(audio, sr, 0.025, 0.01, 13, 26, nfft, 0, 1000, appendEnergy)
features = preprocessing.scale(features)
return features
count = 1
features = np.asarray(()) //
for path in file_paths: //
path = path.strip()
sr,audio = read(source + path) //
vector = get_MFCC (sr, audio) #
if features.size == 0:
features = vector
else:
features = np.vstack((features, vector))Na saída, cada arquivo de áudio se transforma em uma matriz, na qual as características mel-cepstrais de cada fragmento de 0,025 segundo são gravadas linha por linha.
O processamento posterior do arquivo consiste em filtrar ruídos, remover longas pausas (não pausas entre os sons) e pesquisar a fala. Essas tarefas podem ser realizadas usando várias ferramentas. Em nossa solução, usamos métodos da biblioteca de pyaudioanalysis:
clear_noise(fname,outname,ch_n) # .- fname - arquivo de entrada
- outname - arquivo de saída
- ch_n - número de canais
Na saída, obtemos o arquivo outname, que contém o som, limpo de ruído, do arquivo fname.
silenceRemoval(x, Fs, stWin, stStep) # « »- x - matriz de entrada (sinal digitalizado)
- Fs - taxa de amostragem
- stWin - largura da janela de extração de recursos
- stStep - tamanho do passo de deslocamento
Na saída, obtemos uma matriz da forma:
[l_1, r_1]
[l_2, r_2]
[l_3, r_3]
...
[l_N, r_N]
onde l_i é o tempo de início do i-ésimo segmento (s), r_i é o tempo de término do i-ésimo segmento (s )
detect_audio_segment(x,thrs) # .- x - matriz de entrada (sinal digitalizado)
- horas - duração mínima (em segundos) do fragmento de fala detectado
Na saída, obtemos aqueles fragmentos [l_i, r_i] que contêm fala com duração de três segundos.
Como resultado do pré-processamento, o arquivo de áudio de entrada é convertido na forma de um array:
[l_1, r_1]
[l_2, r_2]
[l_3, r_3]
…
[l_N, r_N],
onde cada fragmento é um intervalo de tempo do arquivo de fala limpo.
Assim, podemos associar cada um desses fragmentos a uma matriz de feições (características pequenas-cepstrais), que serão utilizadas no treinamento do modelo e na etapa de marcação.
Métodos / algoritmos usados
Conforme observado acima, nossa solução é baseada na biblioteca pyaudioanalysis.py escrita em Python 2.7. Tendo em vista que nossa solução geral é implementada em Python 3.7, algumas das funções da biblioteca foram modificadas e adaptadas para esta versão da linguagem.
Em geral, o algoritmo da ferramenta para gerenciadores de etiquetagem pode ser dividido em 2 partes:
- Treinamento de gerente de modelo
- Tagging
Uma descrição mais detalhada de cada parte se parece com esta.
Treinamento de gerente de modelo:
- Carregando a amostra de treinamento
- Pré-processamento de dados
- Contando o número de aulas
- Criação de um modelo de gerente para cada uma das classes
- Salvando o modelo
Etiquetagem:
- Carregando chamada
- Verificando a chamada para o sucesso
- Pré-processando uma chamada de sucesso
- Carregando todos os modelos de gerentes treinados
- Classificação de cada fragmento da chamada processada
- Encontrar o modelo de gerente mais provável
- Tagging
Já discutimos em detalhes as tarefas de pré-processamento de dados. Agora, vamos examinar os métodos de criação de modelos de gerente.
Usamos o algoritmo GMM (Gaussian Mixture Model) como modelo . Ele modela nossos dados assumindo que eles são realizações de uma variável aleatória com uma distribuição que é descrita por uma mistura de gaussianas - cada uma com sua própria variância e sua própria expectativa matemática.
Sabe-se que o algoritmo mais comum para encontrar os parâmetros ótimos de tal mistura é o algoritmo EM (Maximização da Expectativa) . Ele divide o difícil problema de maximizar a probabilidade de uma variável aleatória multidimensional em uma série de problemas de maximização de dimensão inferior.
Como resultado de uma série de experimentos, chegamos aos seguintes parâmetros do algoritmo GMM:
gmm = GMM(n_components = 16, n_iter = 200, covariance_type='diag',n_init = 3)Esse modelo é criado para cada gerente e, em seguida, treinado - seus parâmetros são ajustados a dados específicos.
gmm.fit(features)Em seguida, o modelo é salvo para ser usado na fase de marcação:
picklefile = path[path.find('/')+1:path.find('.')]+".gmm"
pickle.dump(gmm,open(dest + picklefile,'wb'))No estágio de marcação, carregamos os modelos salvos anteriormente:
gmm_files = [os.path.join(modelpath,fname) for fname in
os.listdir(modelpath) if fname.endswith('.gmm')]modelpath é o diretório onde salvamos os modelos.
models = [pickle.load(open(fname,'rb'),encoding='latin1') for fname in gmm_files]E também carregue os nomes dos modelos (essas são as nossas tags):
speakers = [fname.split("/")[-1].split(".gmm")[0] for fname
in gmm_files]O arquivo de áudio carregado para o qual você deseja marcar é vetorizado e pré-processado. Além disso, cada fragmento com a fala é comparado com os modelos treinados e o vencedor é determinado em termos do logaritmo máximo de probabilidade:
log_likelihood = np.zeros(len(models)) #
for i in range(len(models)):
gmm = models[i] #
scores = np.array(gmm.score(vector))
log_likelihood[i] = scores.sum() # i –
winner = np.argmax(log_likelihood) #
print("\tdetected as - ", speakers[winner])Como resultado, nosso algoritmo tem aproximadamente a seguinte conclusão:
começa em: 1,92 termina em: 8,72
[-10400,93604115 -12111,38278205]
detectado como - Olga
começa em: 9,22 termina em: 15,72
[-10193,80504138 -11911.11095894]
detectado como - Olga
começa em: 26,7 termina em: 29,82
[-4.867,97641331 -5.506,44233563]
detectado como - Ivan
começa em: 33.34 extremidades em: 47,14
[-21.143,02629011 -24.796,44582627]
detectado como - Ivan
começa em: 52.56 extremidades em: 59,24
[-10916,83282132 -12.124,26855 starts538]
detectado como - Olga
starts538 in: 116,32 termina em: 134,56
[-36764,94876054 -34810,38959083]
detectado como - Olga
começa em: 151,18 termina em: 154,86
[-8041.33666572 -6859.14253903]
detectado como - Olga
começa em: 159,7 termina em: 162,92
[-6421.72235531 -5983.90538059]
detectado como - Olga
começa em: 185,02 termina em: 208,7
…
começa em: 442,04 termina em: 445,5
[-7451.0289772 ]
detectado como - Olga
*******
VENCEDOR - Olga
Este exemplo assume que existem pelo menos 2 classes - [Olga, Ivan] . O arquivo de áudio é cortado em segmentos [1,92, 8,72], [9,22, 15,72],…, [442,04, 445,5] e o modelo mais adequado é determinado para cada um dos segmentos.
O logaritmo de verossimilhança cumulativo é mostrado entre parênteses ao lado de cada bloco:[-10400,93604115 -12111,38278205] , o primeiro elemento é a probabilidade de Olga e o segundo é Ivan . Como o primeiro argumento é maior que o segundo, esse segmento é classificado como Olga . O vencedor final é determinado pela maioria dos "votos" dos fragmentos.
resultados
Inicialmente, projetamos o algoritmo partindo do pressuposto de que um gerente “desconhecido” pode estar presente nas chamadas recebidas - ou seja, de forma que seu modelo não esteja presente na amostra de treinamento.
Para detectar tal usuário, precisamos inserir algumas métricas no vetor log_likelihood . De forma que alguns de seus valores indicarão que muito provavelmente esse fragmento não está adequadamente descrito por nenhum dos modelos existentes. Sugerimos a seguinte métrica como teste:
Leukl=(log_likelihood-np.min(log_likelihood))/(np.max(log_likelihood)-np.min(log_likelihood))
-sorted(-np.array(Leukl))[1]<TEste valor indica quão “uniformemente” as pontuações são distribuídas no vetor log_likelihood . A uniformidade das estimativas (sua proximidade entre si) significa que todos os modelos se comportam da mesma forma e não há um líder claro.
Isso sugere que muito provavelmente todos os modelos estão errados e temos um gerente que não estava em estágio de treinamento. A relação entre T e a qualidade da classificação é mostrada nas figuras.
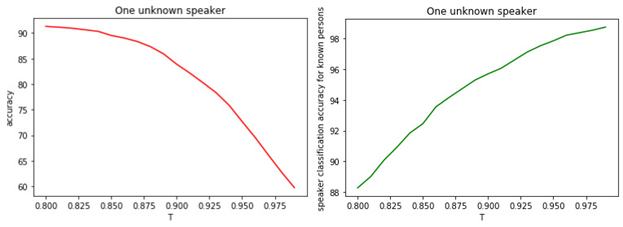
Figura: 1.
a) Precisão da classificação binária de gerentes conhecidos e desconhecidos.
b) A precisão da classificação de gerentes famosos.

Figura: 2.
a) A proporção de gerentes conhecidos designados para a classe de gerentes conhecidos.
b) A proporção de gerentes desconhecidos atribuídos à classe de conhecidos.
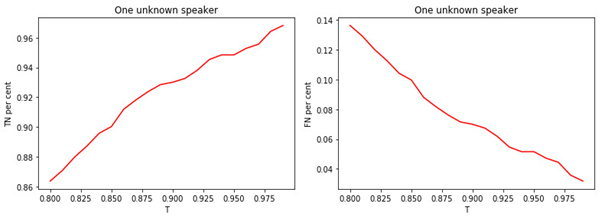
Figura: 3 -
a) A parcela de gerentes desconhecidos atribuídos à classe de desconhecidos.
b) A proporção de gerentes conhecidos atribuídos à classe de desconhecidos.
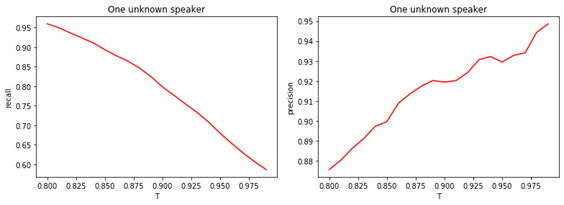
Figura: 4.
a) Completude da classificação binária (rechamada).
b) Precisão da classificação binária (precisão).
A relação entre o valor do limiar T e a qualidade da classificação (marcação) é óbvia. Quanto maior T (quanto mais rígidas as condições para atribuir um gerente à classe de desconhecidos), menos provável que um gerente conhecido seja classificado como desconhecido. No entanto, é mais provável "perder" um gerente desconhecido.
O valor limite ideal é 0,8 . Porque classificamos gerentes conhecidos com uma precisão de cerca de 90%e determinar as "incógnitas" com uma precisão de 81% . Se presumirmos que todos os gerentes são "familiares" para nós, a precisão será de cerca de 98% .
conclusões
No artigo, descrevemos as ideias gerais de funcionamento da nossa ferramenta de identificação de gestores em chamadas. Claro, não pretendemos que nosso algoritmo seja ótimo e não seja capaz de melhorar.
Baseia-se em uma série de premissas que nem sempre são atendidas na prática. Por exemplo, podemos enfrentar um gerente desconhecido se não houver dados sobre ele. Ou dois ou mais gerentes podem conduzir uma conversa com o cliente "em partes iguais". Do ponto de vista do algoritmo, as seguintes direções para melhorias adicionais podem ser propostas:
- Escolha de um modelo de algoritmo diferente do GMM
- Otimizando os parâmetros do GMM
- Seleção de uma métrica diferente para detectar um novo gerente
- Pesquise as características mais significativas do sinal de voz
- Combinação de diferentes ferramentas de pré-processamento de áudio e otimização dos parâmetros desses métodos