
O DBMS, a esse respeito, funciona de acordo com os mesmos princípios - " eles disseram para cavar e eu cavo ". Sua solicitação pode não apenas desacelerar processos vizinhos, ocupando constantemente os recursos do processador, mas também "descartar" todo o banco de dados, "consumindo" toda a memória disponível. Portanto, a proteção contra recursão infinita é responsabilidade do próprio desenvolvedor.
No PostgreSQL, a capacidade de usar consultas recursivas
WITH RECURSIVEsurgiu desde tempos imemoriais na versão 8.4, mas você ainda pode encontrar regularmente consultas "indefesas" potencialmente vulneráveis. Como se salvar desse tipo de problema?
Não escreva consultas recursivas
E escreva não recursivo. Respeitosamente seu K.O.Na verdade, o PostgreSQL oferece uma grande quantidade de funcionalidades que você pode usar para evitar a recursão.
Use uma abordagem fundamentalmente diferente para a tarefa
Às vezes, você pode simplesmente olhar para o problema "do outro lado". Dei um exemplo de tal situação no artigo "SQL HowTo: 1000 and one way of aggregation" - multiplicando um conjunto de números sem usar funções de agregação personalizadas:
WITH RECURSIVE src AS (
SELECT '{2,3,5,7,11,13,17,19}'::integer[] arr
)
, T(i, val) AS (
SELECT
1::bigint
, 1
UNION ALL
SELECT
i + 1
, val * arr[i]
FROM
T
, src
WHERE
i <= array_length(arr, 1)
)
SELECT
val
FROM
T
ORDER BY --
i DESC
LIMIT 1;Essa solicitação pode ser substituída por uma variante de especialistas em matemática:
WITH src AS (
SELECT unnest('{2,3,5,7,11,13,17,19}'::integer[]) prime
)
SELECT
exp(sum(ln(prime)))::integer val
FROM
src;Use generate_series em vez de loops
Digamos que enfrentemos a tarefa de gerar todos os prefixos possíveis para uma string
'abcdefgh':
WITH RECURSIVE T AS (
SELECT 'abcdefgh' str
UNION ALL
SELECT
substr(str, 1, length(str) - 1)
FROM
T
WHERE
length(str) > 1
)
TABLE T;Exatamente, você precisa de recursão aqui? .. Se você usa
LATERALe generate_series, mesmo os CTEs não são necessários:
SELECT
substr(str, 1, ln) str
FROM
(VALUES('abcdefgh')) T(str)
, LATERAL(
SELECT generate_series(length(str), 1, -1) ln
) X;Alterar a estrutura do banco de dados
Por exemplo, você tem uma tabela de postagens de fórum com links para quem respondeu a alguém ou um tópico em uma rede social :
CREATE TABLE message(
message_id
uuid
PRIMARY KEY
, reply_to
uuid
REFERENCES message
, body
text
);
CREATE INDEX ON message(reply_to);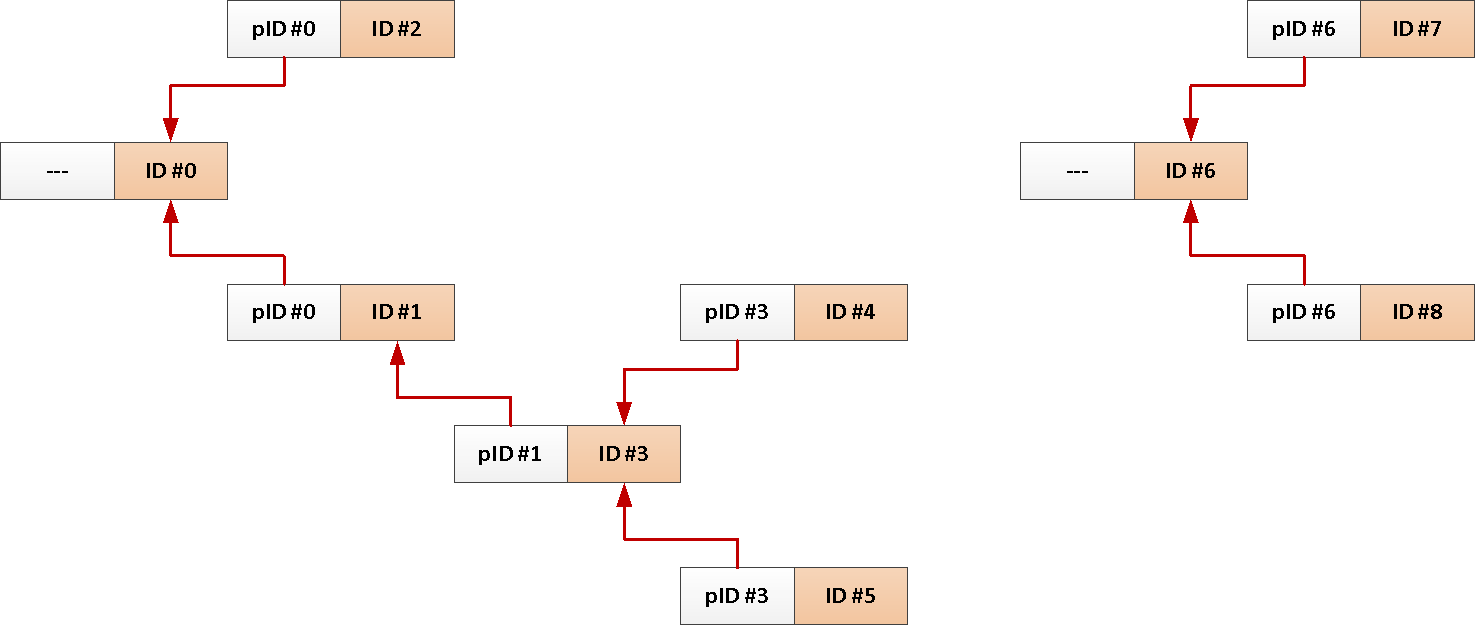
Bem, uma solicitação típica para baixar todas as mensagens em um tópico se parece com isto:
WITH RECURSIVE T AS (
SELECT
*
FROM
message
WHERE
message_id = $1
UNION ALL
SELECT
m.*
FROM
T
JOIN
message m
ON m.reply_to = T.message_id
)
TABLE T;Mas como sempre precisamos de todo o assunto da mensagem raiz, por que não adicionar seu identificador a cada postagem automaticamente?
--
ALTER TABLE message
ADD COLUMN theme_id uuid;
CREATE INDEX ON message(theme_id);
--
CREATE OR REPLACE FUNCTION ins() RETURNS TRIGGER AS $$
BEGIN
NEW.theme_id = CASE
WHEN NEW.reply_to IS NULL THEN NEW.message_id --
ELSE ( -- ,
SELECT
theme_id
FROM
message
WHERE
message_id = NEW.reply_to
)
END;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER ins BEFORE INSERT
ON message
FOR EACH ROW
EXECUTE PROCEDURE ins();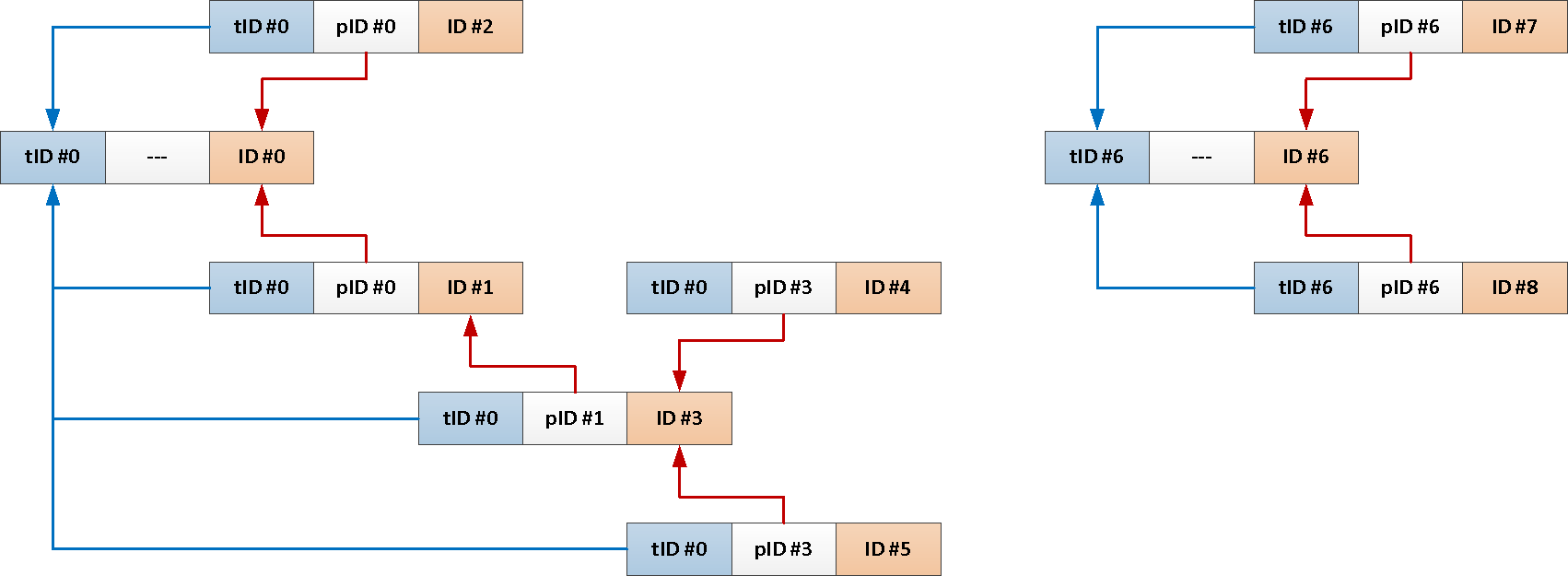
Agora, toda a nossa consulta recursiva pode ser reduzida apenas a isto:
SELECT
*
FROM
message
WHERE
theme_id = $1;Use "restrições" aplicadas
Se não conseguirmos mudar a estrutura do banco de dados por algum motivo, vamos ver no que podemos confiar para que mesmo a presença de um erro nos dados não leve a uma recursão infinita.
Contador de "profundidade" de recursão
Apenas aumentamos o contador em um a cada passo da recursão até que o limite seja alcançado, que consideramos ser obviamente inadequado:
WITH RECURSIVE T AS (
SELECT
0 i
...
UNION ALL
SELECT
i + 1
...
WHERE
T.i < 64 --
)Pro: quando tentamos fazer um loop, ainda não faremos mais do que o limite especificado de iterações "profundas".
Contra: Não há garantia de que não processaremos o mesmo registro novamente - por exemplo, em profundidades de 15 e 25, e então haverá todos os +10. E ninguém prometeu nada sobre "largura".
Formalmente, tal recursão não será infinita, mas se a cada passo o número de registros aumenta exponencialmente, todos sabemos bem como termina ...

Guardião do "caminho"
Um por um, adicionamos todos os identificadores de objeto que encontramos ao longo do caminho de recursão em uma matriz, que é um "caminho" exclusivo para ela:
WITH RECURSIVE T AS (
SELECT
ARRAY[id] path
...
UNION ALL
SELECT
path || id
...
WHERE
id <> ALL(T.path) --
)Pro: Se houver um loop nos dados, absolutamente não processaremos o mesmo registro repetidamente no mesmo caminho.
Contra: Mas ao mesmo tempo, podemos ignorar, literalmente, todas as gravações, sem repetir.
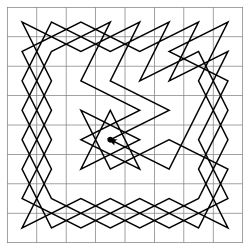
Limitação do comprimento do caminho
Para evitar a situação de recursão "errante" em uma profundidade incompreensível, podemos combinar os dois métodos anteriores. Ou, se não quisermos oferecer suporte a campos desnecessários, complemente a condição de continuação de recursão com uma estimativa do comprimento do caminho:
WITH RECURSIVE T AS (
SELECT
ARRAY[id] path
...
UNION ALL
SELECT
path || id
...
WHERE
id <> ALL(T.path) AND
array_length(T.path, 1) < 10
)Escolha o método ao seu gosto!