
WebAssembly (abreviado WASM) é uma tecnologia para executar código binário pré-compilado em um navegador no lado do cliente. Foi introduzido pela primeira vez em 2015 e atualmente é compatível com a maioria dos navegadores modernos.
Um caso de uso comum é o pré-processamento de dados do lado do cliente antes de enviar os arquivos para o servidor. Neste artigo, vamos entender como isso é feito.
Antes do começo
A arquitetura WebAssembly e as etapas gerais são descritas com mais detalhes aqui e aqui . Examinaremos apenas os fatos básicos.
Trabalhar com WebAssembly começa com a pré-montagem dos artefatos necessários para executar o código compilado no lado do cliente. Existem dois deles: o próprio arquivo binário WASM e uma camada JavaScript por meio da qual você pode chamar os métodos exportados para ele.
Um exemplo do código C ++ mais simples para compilação
#include <algorithm>
extern "C" {
int calculate_gcd(int a, int b) {
while (a != 0 && b != 0) {
a %= b;
std::swap(a, b);
}
return a + b;
}
}Para a montagem, é usado o Emscripten , que, além da interface principal de tais compiladores, contém sinalizadores adicionais através dos quais a configuração da máquina virtual e os métodos exportados são definidos. O lançamento mais simples se parece com isto:
em++ main.cpp --std=c++17 -o gcd.html \
-s EXPORTED_FUNCTIONS='["_calculate_gcd"]' \
-s EXTRA_EXPORTED_RUNTIME_METHODS='["cwrap"]'Especificando um arquivo * .html como um objeto , ele informa ao compilador para criar uma marcação html simples com um console js também. Agora, se iniciarmos o servidor nos arquivos recebidos, veremos este console com a capacidade de iniciar _calculate_gcd:
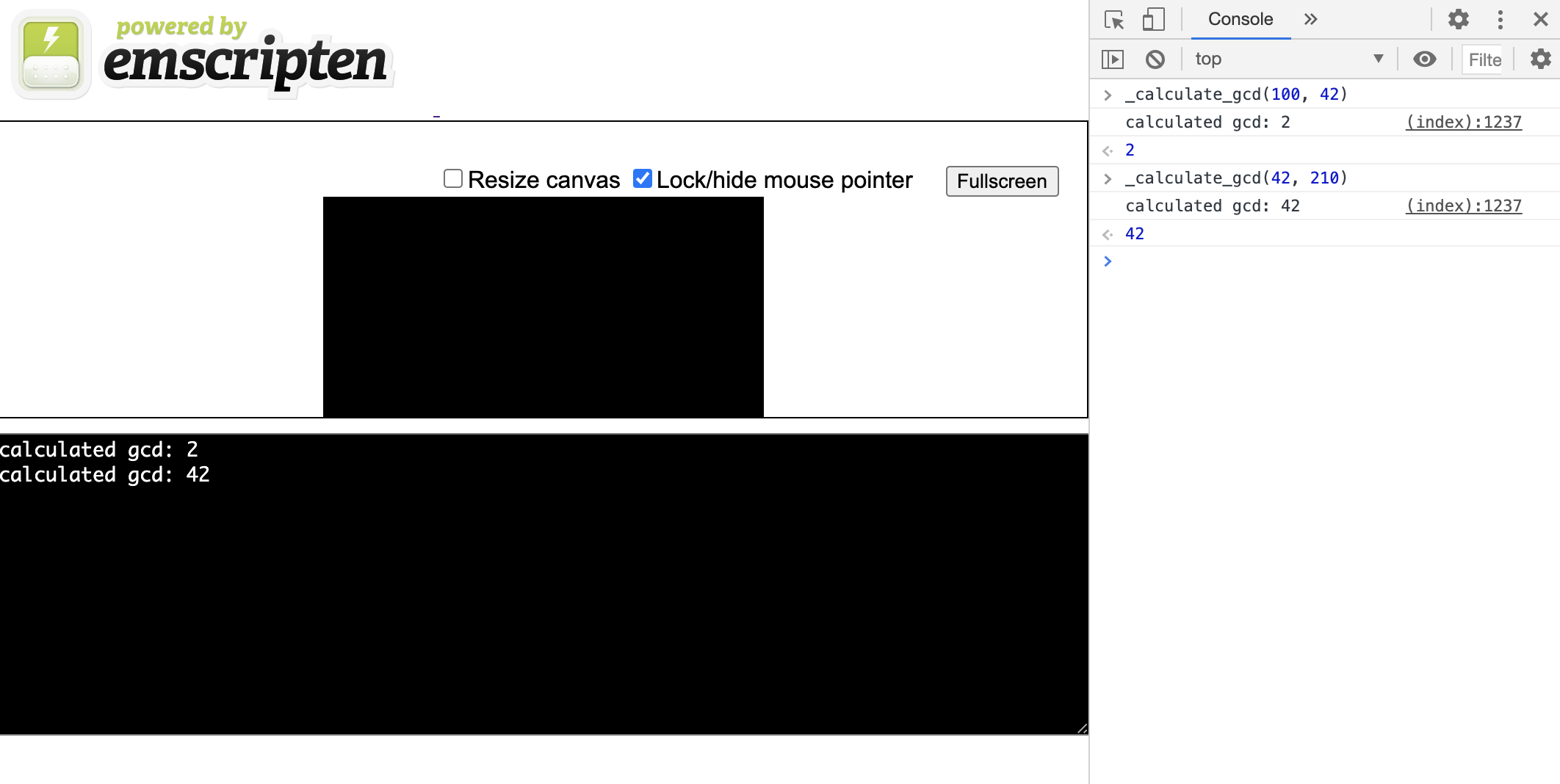
Processamento de dados
Vamos analisá-lo usando um exemplo simples de compressão lz4 usando uma biblioteca escrita em C ++. Observe que os muitos idiomas suportados não param por aí.
Apesar da simplicidade e alguma natureza sintética do exemplo, esta é uma ilustração bastante útil de como trabalhar com dados. Da mesma forma, você pode executar qualquer ação neles para a qual o poder do cliente é suficiente: pré-processamento de imagens antes de enviar para o servidor, compressão de áudio, contagem de várias estatísticas e muito mais.
O código completo pode ser encontrado aqui.
Parte C ++
Usamos uma implementação pronta de lz4 . Então, o arquivo principal parecerá muito lacônico:
#include "lz4.h"
extern "C" {
uint32_t compress_data(uint32_t* data, uint32_t data_size, uint32_t* result) {
uint32_t result_size = LZ4_compress(
(const char *)(data), (char*)(result), data_size);
return result_size;
}
uint32_t decompress_data(uint32_t* data, uint32_t data_size, uint32_t* result, uint32_t max_output_size) {
uint32_t result_size = LZ4_uncompress_unknownOutputSize(
(const char *)(data), (char*)(result), data_size, max_output_size);
return result_size;
}
}Como você pode ver, ele simplesmente declara funções externas (usando a palavra-chave extern ) que chamam internamente os métodos correspondentes da biblioteca com lz4.
De um modo geral, no nosso caso, o arquivo é inútil: você pode usar imediatamente a interface nativa do lz4.h . No entanto, em projetos mais complexos (por exemplo, combinar a funcionalidade de diferentes bibliotecas), é conveniente ter um ponto de entrada comum listando todas as funções usadas.
A seguir, compilamos o código usando o compilador Emscripten já mencionado :
em++ main.cpp lz4.c -o wasm_compressor.js \
-s EXPORTED_FUNCTIONS='["_compress_data","_decompress_data"]' \
-s EXTRA_EXPORTED_RUNTIME_METHODS='["cwrap"]' \
-s WASM=1 -s ALLOW_MEMORY_GROWTH=1O tamanho dos artefatos recebidos é alarmante:
$ du -hs wasm_compressor.*
112K wasm_compressor.js
108K wasm_compressor.wasm
Se você abrir o arquivo da camada JS, poderá ver algo assim:

Ele contém muitas coisas desnecessárias: de comentários a funções de serviço, muitos dos quais não são usados. A situação pode ser corrigida adicionando o sinalizador -O2, no compilador Emscripten, também inclui a otimização do código js.
Depois disso, o código js parece melhor:

Código do cliente
Você precisa chamar o manipulador do lado do cliente de alguma forma. Primeiramente, carregue o arquivo fornecido pelo usuário através do
FileReader, vamos armazenar os dados brutos em uma primitiva Uint8Array:
var rawData = new Uint8Array(fileReader.result);Em seguida, você precisa transferir os dados baixados para a máquina virtual. Para fazer isso, primeiro alocamos o número necessário de bytes usando o método _malloc e, em seguida, copiamos o array JS usando o método set. Por conveniência, vamos separar essa lógica na função arrayToWasmPtr (array):
function arrayToWasmPtr(array) {
var ptr = Module._malloc(array.length);
Module.HEAP8.set(array, ptr);
return ptr;
}Depois de carregar os dados na memória da máquina virtual, você precisa de alguma forma chamar a função do processamento. Mas como encontrar essa função? O método cwrap nos ajudará - o primeiro argumento nele especifica o nome da função necessária, o segundo - o tipo de retorno e o terceiro - uma lista com argumentos de entrada.
compressDataFunction = Module.cwrap('compress_data', 'number', ['number', 'number', 'number']);Finalmente, você precisa retornar os bytes finalizados da máquina virtual. Para fazer isso, escrevemos outra função que os copia em uma matriz JS usando o método
subarray
function wasmPtrToArray(ptr, length) {
var array = new Int8Array(length);
array.set(Module.HEAP8.subarray(ptr, ptr + length));
return array;
}O script completo para processamento de arquivos recebidos está aqui . Marcação HTML contendo formulário de upload de arquivo e upload de artefatos wasm aqui .
Resultado
Você pode brincar com o protótipo aqui .
O resultado é um backup de trabalho usando WASM. Das desvantagens - a implementação atual da tecnologia não permite liberar memória alocada na máquina virtual. Isso cria um vazamento implícito quando um grande número de arquivos é carregado em uma sessão, mas pode ser corrigido reutilizando a memória existente em vez de alocar uma nova.

