
Cada vez mais, as seguintes solicitações vêm dos clientes: “Queremos como o Amazon RDS, mas mais barato”; "Queremos como RDS, mas em qualquer lugar, em qualquer infraestrutura." Para implementar essa solução gerenciada no Kubernetes, examinamos o estado atual dos operadores mais populares para PostgreSQL (Stolon, operadores de Crunchy Data e Zalando) e fizemos nossa escolha.
Este artigo é a nossa experiência tanto do ponto de vista teórico (revisão das soluções) como do ponto de vista prático (o que foi escolhido e o que resultou). Mas, primeiro, vamos determinar quais são os requisitos gerais para uma possível substituição do RDS ...
O que é RDS
Quando as pessoas falam sobre RDS, em nossa experiência, elas se referem a um serviço DBMS gerenciado que:
- facilmente personalizável;
- tem a capacidade de trabalhar com instantâneos e recuperar-se deles (de preferência com suporte PITR );
- permite criar topologias mestre-escravo;
- tem uma lista rica de extensões;
- fornece auditoria e gerenciamento de usuário / acesso.
De um modo geral, as abordagens para a implementação da tarefa podem ser muito diferentes, mas o caminho com Ansible condicional não está perto de nós. (Uma conclusão semelhante foi alcançada por colegas da 2GIS como resultado de sua tentativa de criar uma "ferramenta para implantar rapidamente um cluster de failover baseado em Postgres".) Os
operadores são a abordagem geralmente aceita para resolver esses problemas no ecossistema Kubernetes. Mais detalhes sobre eles em relação aos bancos de dados executados dentro do Kubernetes já foram informados pelo departamento técnico do Flant,destol, em um de seus relatórios .
NB : Para criar operadores simples rapidamente, recomendamos que você preste atenção ao nosso utilitário shell-operator de código aberto . Usando-o, você pode fazer isso sem conhecimento do Go, mas de maneiras mais familiares aos administradores de sistemas: em Bash, Python, etc.
Existem vários operadores K8s populares para PostgreSQL:
- Stolon;
- Operador PostgreSQL de dados crocantes;
- Operador Zalando Postgres.
Vamos examiná-los mais de perto.
Seleção de operador
Além dos recursos importantes já mencionados acima, nós - como engenheiros de operações de infraestrutura no Kubernetes - também esperávamos o seguinte dos operadores:
- implantar a partir do Git e de recursos personalizados ;
- suporte de antiafinidade de pod;
- instalar afinidade de nó ou seletor de nó;
- definição de tolerâncias;
- disponibilidade de oportunidades de ajuste;
- tecnologias compreensíveis e até comandos.
Sem entrar em detalhes sobre cada um dos pontos (pergunte nos comentários se você tem alguma dúvida sobre eles depois de ler todo o artigo), observo em geral que esses parâmetros são necessários para uma descrição mais detalhada da especialização dos nós do cluster, a fim de ordená-los para aplicativos específicos. Dessa forma, podemos alcançar o equilíbrio ideal entre desempenho e custo.
Agora, para os próprios operadores PostgreSQL.
1. Stolon
O stolon da empresa italiana Sorint.lab no relatório já citado foi considerado um certo padrão entre os operadores para DBMS. Este é um projeto bastante antigo: seu primeiro lançamento público ocorreu em novembro de 2015 (!), E o repositório GitHub possui quase 3.000 estrelas e mais de 40 colaboradores.
Na verdade, Stolon é um ótimo exemplo de uma arquitetura bem pensada:
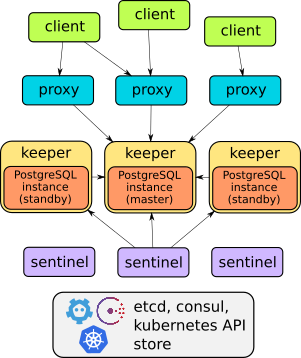
Os detalhes do dispositivo deste operador podem ser encontrados no relatório ou documentação do projeto . Em geral, basta dizer que ele pode fazer tudo o que foi descrito: failover, proxies para acesso de cliente transparente, backups ... Além disso, os proxies fornecem acesso por meio de um serviço de endpoint - ao contrário das outras duas soluções discutidas abaixo (eles têm dois serviços de acesso base).
No entanto, o Stolon não tem recursos personalizados , por isso não pode ser implantado de forma fácil e rápida - "como bolos quentes" - criar instâncias de DBMS no Kubernetes. O gerenciamento é realizado por meio do utilitário
stolonctl, implantação - por meio do Helm-chart, e as configurações do usuário são definidas no ConfigMap.
Por um lado, verifica-se que o operador não é exatamente um operador (afinal, ele não usa CRD). Mas, por outro lado, é um sistema flexível que permite personalizar recursos no K8s da maneira que você quiser.
Para resumir, para nós, pessoalmente, não parecia ideal criar um gráfico separado para cada banco de dados. Portanto, começamos a buscar alternativas.
2. Operador Crunchy Data PostgreSQL
A operadora da Crunchy Data , uma jovem startup americana, parecia uma alternativa lógica. Sua história pública começa com o primeiro lançamento em março de 2017, desde então o repositório GitHub recebeu pouco menos de 1300 estrelas e mais de 50 contribuidores. A versão mais recente de setembro foi testada para funcionar com Kubernetes 1.15-1.18, OpenShift 3.11+ e 4.4+, GKE e VMware Enterprise PKS 1.3+.
A arquitetura do Crunchy Data PostgreSQL Operator também atende aos requisitos declarados: o
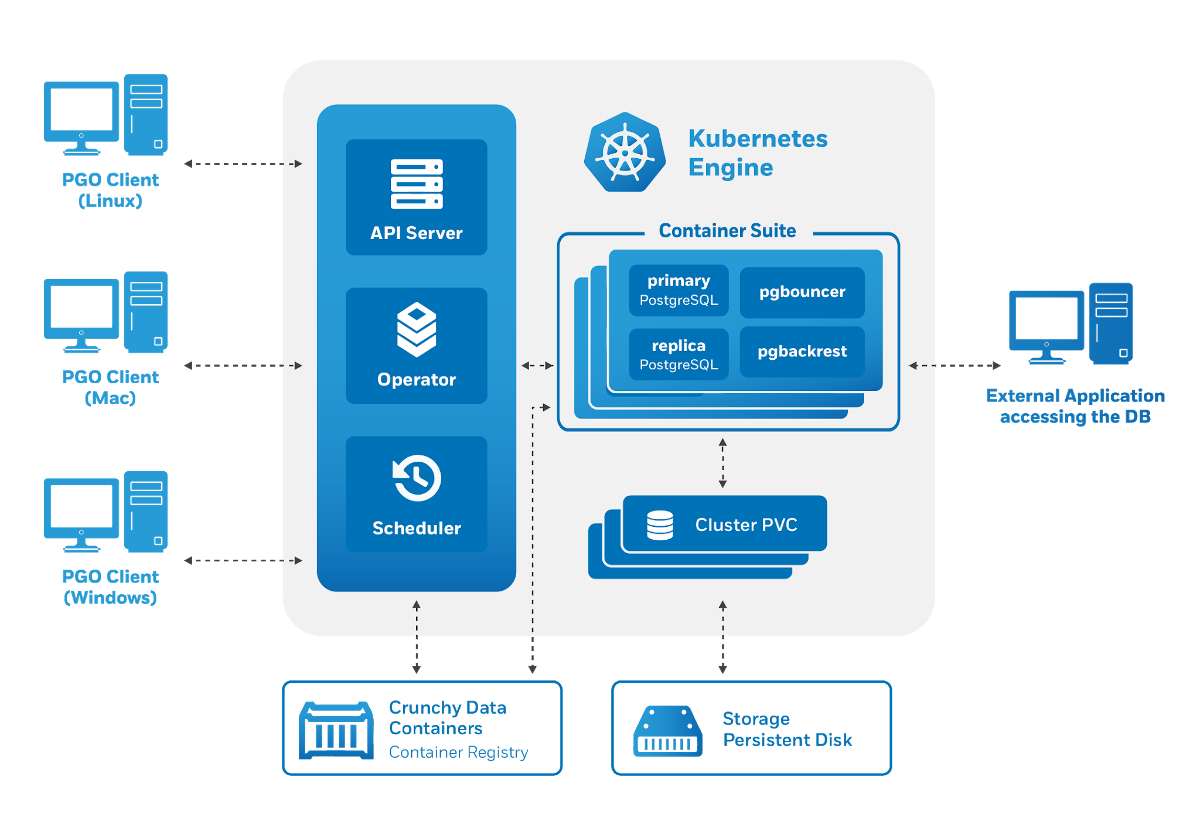
gerenciamento é feito por meio de um utilitário
pgo, mas, por sua vez, gera recursos personalizados para o Kubernetes. Portanto, a operadora nos agradou como usuários em potencial:
- há controle via CRD;
- gerenciamento conveniente do usuário (também via CRD);
- integração com outros componentes do Crunchy Data Container Suite - uma coleção especializada de imagens de contêiner para PostgreSQL e utilitários para trabalhar com ele (incluindo pgBackRest, pgAudit, extensões contrib, etc.).
No entanto, as tentativas de começar a usar o operador da Crunchy Data revelaram vários problemas:
- Não havia possibilidade de tolerâncias - apenas nodeSelector é fornecido.
- Os pods que criamos faziam parte da implantação, embora tenhamos implantado um aplicativo com estado. Ao contrário dos StatefulSets, as implantações não podem criar discos.
A última desvantagem leva a momentos engraçados: no ambiente de teste, era possível rodar 3 réplicas com um disco de armazenamento local , como resultado o operador relatou que 3 réplicas estavam funcionando (embora não fosse o caso).
Outra característica deste operador é sua integração pronta com vários sistemas auxiliares. Por exemplo, é fácil instalar o pgAdmin e o pgBounce, e a documentação cobre o Grafana e o Prometheus pré-configurados. O lançamento recente 4.5.0-beta1 separadamente observa integração aprimorada com o projeto pgMonitor , graças ao qual o operador oferece uma visualização visual das métricas PgSQL fora da caixa.
No entanto, a estranha escolha dos recursos gerados do Kubernetes nos levou a encontrar outra solução.
3. Operador Zalando Postgres
Já conhecemos os produtos Zalando há muito tempo: temos experiência no uso do Zalenium e, claro, experimentamos o Patroni - sua solução HA popular para PostgreSQL. Um de seus autores, Aleksey Klyukin, falou sobre a abordagem da empresa para a criação do Postgres Operator no Postgres Tuesday # 5 , e nós gostamos.
Esta é a solução mais recente discutida no artigo: o primeiro lançamento ocorreu em agosto de 2018. No entanto, apesar do pequeno número de lançamentos formais, o projeto percorreu um longo caminho, já ultrapassando a popularidade da solução da Crunchy Data com mais de 1300 estrelas no GitHub e o número máximo de colaboradores (70+).
Sob o capô deste operador, soluções testadas pelo tempo são usadas:
É assim que a arquitetura do operador do Zalando é apresentada:
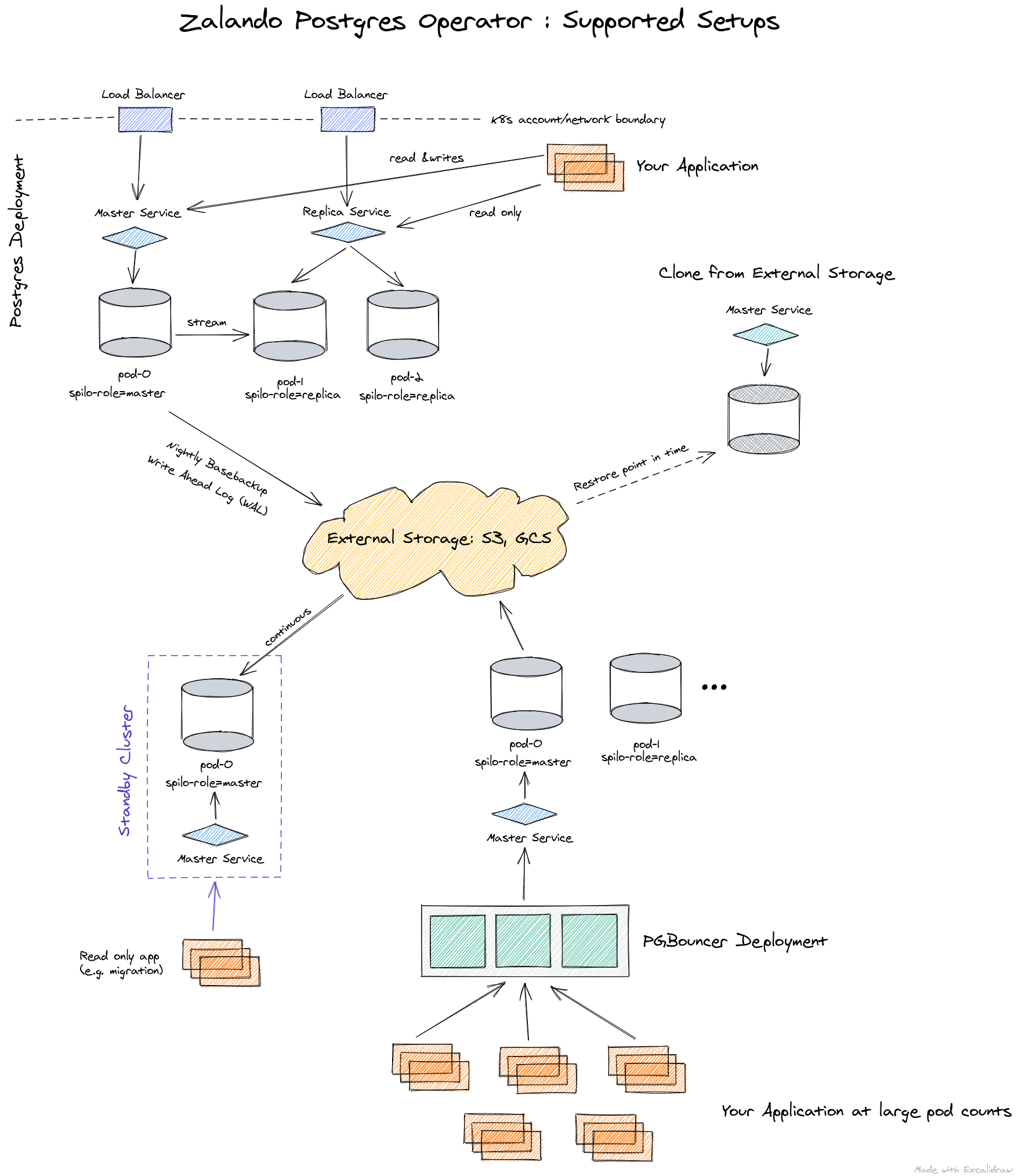
o operador é totalmente gerenciado por meio de recursos personalizados, cria automaticamente um StatefulSet a partir de contêineres, que pode então ser personalizado adicionando vários sidecars aos pods. Tudo isso é uma vantagem significativa em comparação com a operadora da Crunchy Data.
Uma vez que foi a solução do Zalando que escolhemos entre as 3 opções em consideração, uma descrição adicional de suas capacidades será apresentada a seguir, juntamente com a prática de aplicação.
Pratique com o Operador Postgres de Zalando
A implantação de um operador é muito simples: basta baixar a versão atual do GitHub e aplicar os arquivos YAML do diretório manifestos . Como alternativa, você também pode usar OperatorHub .
Após a instalação, você deve se preocupar em configurar armazenamentos para logs e backups . Isso é feito por meio do ConfigMap
postgres-operatorno namespace onde você instalou a instrução. Com os repositórios configurados, você pode implantar seu primeiro cluster PostgreSQL.
Por exemplo, nossa implantação padrão se parece com isto:
apiVersion: acid.zalan.do/v1
kind: postgresql
metadata:
name: staging-db
spec:
numberOfInstances: 3
patroni:
synchronous_mode: true
postgresql:
version: "12"
resources:
limits:
cpu: 100m
memory: 1Gi
requests:
cpu: 100m
memory: 1Gi
sidecars:
- env:
- name: DATA_SOURCE_URI
value: 127.0.0.1:5432
- name: DATA_SOURCE_PASS
valueFrom:
secretKeyRef:
key: password
name: postgres.staging-db.credentials
- name: DATA_SOURCE_USER
value: postgres
image: wrouesnel/postgres_exporter
name: prometheus-exporter
resources:
limits:
cpu: 500m
memory: 100Mi
requests:
cpu: 100m
memory: 100Mi
teamId: staging
volume:
size: 2Gi
Este manifesto implanta um cluster de 3 instâncias com um arquivo secundário na forma de postgres_exporter , do qual obtemos as métricas do aplicativo. Como você pode ver, tudo é muito simples e, se desejar, você pode criar literalmente um número ilimitado de clusters.
Vale a pena prestar atenção ao painel de administração da web - postgres-operator-ui . Acompanha a operadora e permite criar e deletar clusters, além de trabalhar com backups feitos pela operadora. Gerenciamento de backups da
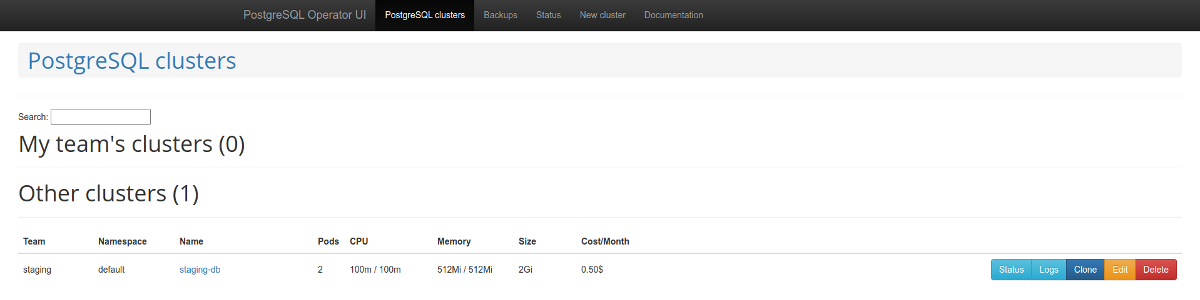
lista de clusters PostgreSQL Outro recurso interessante é o suporte à API Teams . Este mecanismo cria automaticamente funções no PostgreSQL
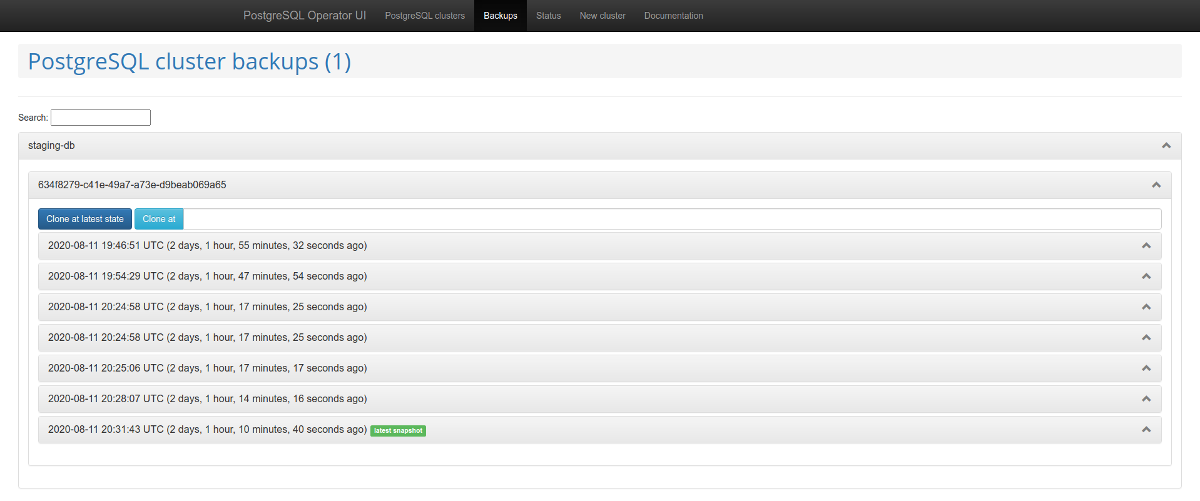
com base na lista de nomes de usuário resultante. Depois disso, a API permite que você retorne uma lista de usuários para os quais as funções são criadas automaticamente.
Problemas e soluções
No entanto, o uso do operador logo revelou várias desvantagens significativas:
- falta de suporte para nodeSelector;
- incapacidade de desabilitar backups;
- ao usar a função de criação de banco de dados, os privilégios padrão não aparecem;
- periodicamente não há documentação suficiente ou está desatualizada.
Felizmente, muitos deles podem ser resolvidos. Vamos começar pelo final - problemas com a documentação .
Provavelmente, você descobrirá que nem sempre é claro como registrar um backup e como conectar um depósito de backup à IU do operador. A documentação fala sobre isso de passagem, mas a verdadeira descrição está no PR :
- você precisa fazer um segredo;
-
pod_environment_secret_nameCRD ConfigMap ( , ).
No entanto, como se viu, isso atualmente é impossível. É por isso que reunimos nossa própria versão do operador com alguns desenvolvimentos de terceiros adicionais. Veja abaixo para mais detalhes.
Se você passar os parâmetros do backup para o operador, a saber, as
wal_s3_bucketchaves de acesso no AWS S3, ele fará o backup de tudo : não apenas das bases em produção, mas também de staging. Não nos convinha.
Na descrição dos parâmetros para Spilo, que é o wrapper básico do Docker para PgSQL ao usar o operador, descobriu-se que você pode passar o parâmetro
WAL_S3_BUCKETvazio, desabilitando os backups. Além disso, para nossa grande alegria, foi encontrado um PR já pronto , que imediatamente aceitamos em nosso fork. Agora é suficiente simplesmente adicionar o enableWALArchiving: falsecluster PostgreSQL ao recurso.
Sim, houve uma oportunidade de fazer isso de forma diferente executando 2 operadores: um para teste (sem backups) e o segundo para produção. Mas assim fomos capazes de sobreviver com um.
Ok, aprendemos como transferir o acesso aos bancos de dados para S3 e os backups começaram a entrar no armazenamento. Como fazer as páginas de backup funcionarem na IU do Operador?

Na IU do Operador, você precisa adicionar 3 variáveis:
-
SPILO_S3_BACKUP_BUCKET -
AWS_ACCESS_KEY_ID -
AWS_SECRET_ACCESS_KEY
Depois disso, o gerenciamento de backups ficará disponível, o que, em nosso caso, simplificará o trabalho com teste, permitindo que você entregue fatias da produção sem scripts adicionais.
Outra vantagem foi o trabalho com a API Teams e as amplas possibilidades de criação de bancos de dados e funções usando ferramentas de operação. No entanto, as funções criadas não tinham direitos padrão . Conseqüentemente, um usuário com direitos de leitura não pôde ler as novas tabelas.
Por que é que? Apesar de o código conter os necessários
GRANT, nem sempre são usados. Existem 2 métodos: syncPreparedDatabasese syncDatabases. B syncPreparedDatabases- apesar do fato de preparedDatabases haver uma condição na seção defaultRolesedefaultUserspara criar funções, os direitos padrão não são aplicados. Estamos preparando um patch para que esses direitos sejam aplicados automaticamente.
E o último momento nas melhorias que são relevantes para nós é um patch que adiciona Node Affinity ao StatefulSet criado. Nossos clientes geralmente preferem cortar custos usando instâncias pontuais, e eles claramente não deveriam hospedar serviços de banco de dados. Este problema poderia ser resolvido através de tolerâncias, mas a presença de Node Affinity dá muita confiança.
O que aconteceu?
Como resultado da solução dos problemas acima, nós colocamos o Postgres Operator do Zalando em nosso repositório , onde ele é construído com esses patches úteis. E por uma questão de conveniência, também montamos uma imagem do Docker .
Lista bifurcada de relações públicas:
- construir uma imagem leve e segura para o operador no Docker ;
- desabilitar backups ;
- atualização de versões de recursos para versões atuais de k8s ;
- implementação de Node Affinity .
Seria ótimo se a comunidade apoiasse esses PRs para que eles fiquem com a próxima versão do operador (1.6).
Bônus! História de sucesso de migração de produção
Se você estiver usando o Patroni, a produção ao vivo pode ser migrada para o operador com tempo de inatividade mínimo.
O Spilo permite que você crie clusters em espera por meio de armazenamentos S3 com Wal-E , quando o log binário PgSQL é primeiro salvo no S3 e depois baixado pela réplica. Mas e se você não tiver o Wal-E em sua antiga infraestrutura? A solução para este problema já foi proposta em Habré.
A replicação lógica do PostgreSQL vem ao resgate. Porém, não entraremos em detalhes sobre como criar publicações e assinaturas, porque ... nosso plano falhou.
O fato é que o banco de dados possuía várias tabelas carregadas com milhões de linhas, que, além disso, eram constantemente reabastecidas e deletadas. Assinatura simples com
copy_data, quando uma nova réplica copia todo o conteúdo do master, ela simplesmente não acompanha o master. Copiar o conteúdo funcionou por uma semana, mas nunca alcançou o mestre. Como resultado, um artigo de colegas da Avito ajudou a lidar com o problema : você pode transferir dados usando pg_dump. Descreverei nossa versão (ligeiramente modificada) desse algoritmo.
A ideia é que você pode fazer uma assinatura desligada vinculada a um slot de replicação específico e, em seguida, corrigir o número da transação. Havia réplicas para o trabalho de produção. Isso é importante porque a réplica ajudará a criar um dump consistente e continuará a receber alterações do mestre.
Em comandos subsequentes que descrevem o processo de migração, as seguintes notações de host serão usadas:
- master - servidor de origem;
- replica1 - replica de streaming na produção antiga;
- replica2 é uma nova réplica lógica.
Plano de migração
1. No assistente, crie uma assinatura para todas as tabelas no esquema do
publicbanco de dados dbname:
psql -h master -d dbname -c "CREATE PUBLICATION dbname FOR ALL TABLES;"
2. Vamos criar um slot de replicação no mestre:
psql -h master -c "select pg_create_logical_replication_slot('repl', 'pgoutput');"
3. Pare a replicação na réplica antiga:
psql -h replica1 -c "select pg_wal_replay_pause();"
4. Obtenha o número da transação do mestre:
psql -h master -c "select replay_lsn from pg_stat_replication where client_addr = 'replica1';"
5. Vamos descartar a réplica antiga. Faremos isso em vários threads, o que ajudará a acelerar o processo:
pg_dump -h replica1 --no-publications --no-subscriptions -O -C -F d -j 8 -f dump/ dbname
6. Faça o upload do dump para o novo servidor:
pg_restore -h replica2 -F d -j 8 -d dbname dump/
7. Depois de baixar o dump, você pode iniciar a replicação na réplica de streaming:
psql -h replica1 -c "select pg_wal_replay_resume();"
7. Vamos criar uma assinatura em uma nova réplica lógica:
psql -h replica2 -c "create subscription oldprod connection 'host=replica1 port=5432 user=postgres password=secret dbname=dbname' publication dbname with (enabled = false, create_slot = false, copy_data = false, slot_name='repl');"
8. Obtenha
oidassinaturas:
psql -h replica2 -d dbname -c "select oid, * from pg_subscription;"
9. Digamos que foi recebido
oid=1000. Vamos aplicar o número da transação à assinatura:
psql -h replica2 -d dbname -c "select pg_replication_origin_advance('pg_1000', 'AA/AAAAAAAA');"
10. Vamos começar a replicação:
psql -h replica2 -d dbname -c "alter subscription oldprod enable;"
11. Verifique o status da assinatura, a replicação deve funcionar:
psql -h replica2 -d dbname -c "select * from pg_replication_origin_status;"
psql -h master -d dbname -c "select slot_name, restart_lsn, confirmed_flush_lsn from pg_replication_slots;"
12. Após o início da replicação e a sincronização dos bancos de dados, você pode alternar.
13. Após desativar a replicação, você precisa corrigir as sequências. Isso está bem documentado em um artigo no wiki.postgresql.org .
Graças a esse plano, a transição ocorreu com atrasos mínimos.
Conclusão
Os operadores do Kubernetes permitem que você simplifique várias atividades, reduzindo-as à criação de recursos do K8s. Porém, tendo conseguido uma automação notável com a ajuda deles, vale lembrar que também pode trazer uma série de nuances inesperadas, portanto escolha seus operadores com sabedoria.
Depois de revisar os três operadores Kubernetes mais populares para PostgreSQL, optamos por um projeto de Zalando. E tivemos que superar algumas dificuldades com ele, mas o resultado foi muito satisfatório, então planejamos expandir esta experiência para algumas outras instalações do PgSQL. Se você tiver experiência no uso de soluções semelhantes, teremos o maior prazer em ver os detalhes nos comentários!
PS
Leia também em nosso blog: