Mas e se você começar a usar algum produto não SAP e de preferência OpenSource como armazenamento? Nós do X5 Retail Group escolhemos GreenPlum. Isso, é claro, resolve a questão dos custos, mas, ao mesmo tempo, surgem imediatamente questões que, ao usar o SAP BW, foram resolvidas quase que por padrão.

Em particular, como obter dados de sistemas de origem, que são principalmente soluções SAP?
HR Metrics foi o primeiro projeto a resolver esse problema. Nosso objetivo era criar um warehouse para dados de RH e construir relatórios analíticos na área de trabalho com os funcionários. Nesse caso, a principal fonte de dados é o sistema transacional SAP HCM, no qual todas as atividades de pessoal, organizacionais e salariais são realizadas.
Extração de dados
Existem extratores de dados padrão no SAP BW para sistemas SAP. Esses extratores podem coletar automaticamente os dados necessários, rastrear sua integridade e determinar os deltas de mudanças. Por exemplo, aqui está uma fonte de dados padrão para os atributos do funcionário 0EMPLOYEE_ATTR:

Resultado da extração de dados, um funcionário por vez:
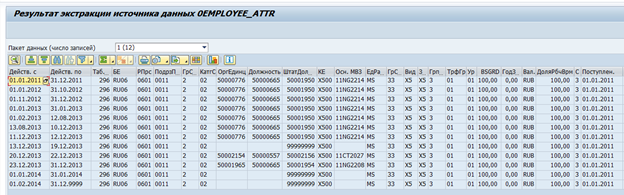
Se necessário, esse extrator pode ser modificado para atender às suas próprias necessidades ou pode ser criado seu próprio extrator.
Surgiu a primeira ideia sobre a possibilidade de seu reaproveitamento. Infelizmente, isso provou ser uma tarefa impossível. A maior parte da lógica é implementada no lado do SAP BW e não foi possível separar sem dor o extrator na fonte do SAP BW.
Ficou óbvio que seria necessário desenvolver um mecanismo personalizado para extrair dados de sistemas SAP.
Estrutura de armazenamento de dados em SAP HCM
Para entender os requisitos de tal mecanismo, primeiro você precisa determinar que tipo de dados precisamos.
A maioria dos dados no SAP HCM é armazenada em tabelas SQL simples. Com base nesses dados, os aplicativos SAP visualizam estruturas organizacionais, funcionários e outras informações de RH para o usuário. Por exemplo, esta é a aparência de uma estrutura organizacional no SAP HCM:
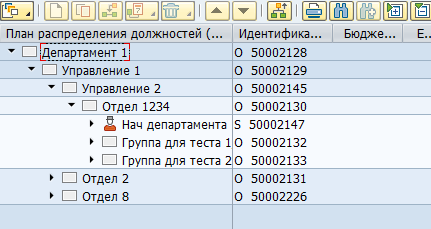
Fisicamente, essa árvore é armazenada em duas tabelas - em objetos hrp1000 e em hrp1001 os links entre esses objetos.
Objetos "Departamento 1" e "Escritório 1":

Comunicação entre objetos:

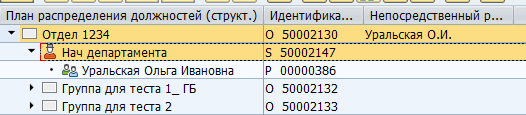
Pode haver um grande número de ambos os tipos de objetos e tipos de comunicação entre eles. Existem links padrão entre objetos e personalizados para suas necessidades específicas. Por exemplo, o relacionamento padrão B012 entre uma unidade organizacional e uma posição de tempo integral indica o chefe do departamento.
Mapeamento do gerente no SAP:
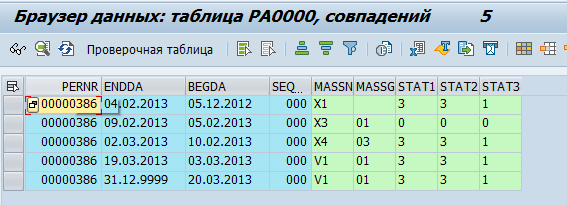
Armazenamento na tabela do banco de dados: os

dados dos funcionários são armazenados nas tabelas pa *. Por exemplo, os dados sobre as atividades de pessoal de um funcionário são armazenados na tabela pa0000.
Decidimos que o GreenPlum pegará dados "brutos", ou seja, basta copiá-los das tabelas SAP. E já diretamente no GreenPlum, eles serão processados e convertidos em objetos físicos (por exemplo, Departamento ou Funcionário) e métricas (por exemplo, número médio de funcionários).
Foram definidas cerca de 70 tabelas, cujos dados devem ser transferidos para a GreenPlum. Depois disso, começamos a descobrir uma maneira de transferir esses dados.
SAP oferece um número bastante grande de mecanismos de integração. Mas a maneira mais fácil - o acesso direto ao banco de dados é proibido devido a restrições de licenciamento. Portanto, todos os fluxos de integração devem ser implementados no nível do servidor de aplicativos.
O próximo problema foi a falta de dados sobre registros excluídos no banco de dados SAP. Quando uma linha é excluída do banco de dados, ela é excluída fisicamente. Essa. a formação de um delta de mudanças ao longo do tempo de mudança não foi possível.
Claro, SAP HCM tem mecanismos para confirmar alterações de dados. Por exemplo, para a transmissão subsequente aos sistemas, os destinatários têm indicadores de modificação que registram todas as modificações e com base nos quais um Idoc é formado (um objeto para transmissão a sistemas externos).
Exemplo de IDoc para modificação do infotipo 0302 para empregado com número pessoal 1251445:
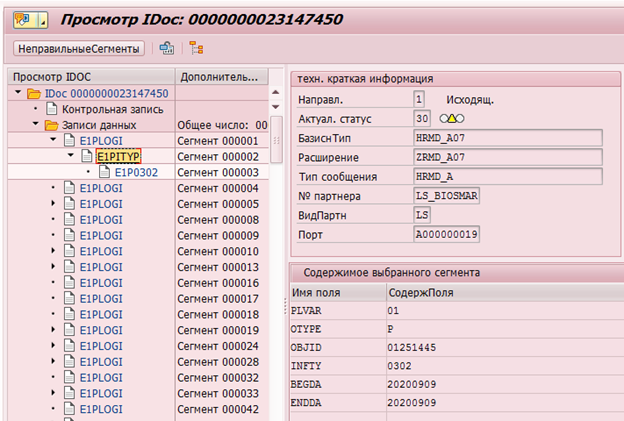
ou atualização de logs de modificação de dados na tabela DBTABLOG.
Um exemplo de log para excluir uma entrada com a chave QK53216375 da tabela hrp1000:

Mas esses mecanismos não estão disponíveis para todos os dados necessários e seu processamento no nível do servidor de aplicativos pode consumir muitos recursos. Portanto, a inclusão massiva de registro em todas as tabelas necessárias pode levar a uma degradação perceptível do desempenho do sistema.
As tabelas agrupadas foram o próximo grande problema. A estimativa de tempo e os dados da folha de pagamento na versão RDBMS do SAP HCM são armazenados como um conjunto de tabelas lógicas por funcionário por folha de pagamento. Essas tabelas lógicas são armazenadas como dados binários na tabela pcl2.
Cluster da folha de pagamento: os
dados de tabelas em cluster não podem ser lidos pelo comando SQL e requerem o uso de macros SAP HCM ou módulos de função especial. Conseqüentemente, a velocidade de leitura dessas tabelas será bastante baixa. Por outro lado, esses clusters armazenam dados que são necessários apenas uma vez por mês - a folha de pagamento final e a estimativa de tempo. Portanto, a velocidade neste caso não é tão crítica.
Avaliando as opções com a formação de um delta de mudança de dados, decidimos considerar também a opção com descarga total. A opção de transferir gigabytes de dados inalterados entre sistemas todos os dias não pode parecer bonita. No entanto, também tem uma série de vantagens - não há necessidade de implementar o delta no lado da fonte ou de implementar a incorporação deste delta no lado do receptor. Consequentemente, o custo e o tempo de implementação são reduzidos e a confiabilidade da integração é aumentada. Ao mesmo tempo, foi determinado que quase todas as mudanças no SAP HR ocorrem no horizonte de três meses antes da data atual. Assim, decidiu-se parar com um download completo diário dos dados do SAP HR N meses antes da data atual e com um download completo mensal. O parâmetro N depende da tabela específica
e varia de 1 a 15.
Para a extração dos dados, foi proposto o seguinte esquema:

O sistema externo gera uma solicitação e a envia para o SAP HCM, onde essa solicitação é verificada quanto à integridade dos dados e autorização para acessar as tabelas. Se a verificação for bem-sucedida, o SAP HCM executa um programa que coleta os dados necessários e os transfere para a solução de integração Fuse. O Fuse define o tópico necessário no Kafka e passa os dados para lá. Em seguida, os dados de Kafka são transferidos para o GP da Stage Area.
Nesta cadeia, estamos interessados na questão da extração de dados do SAP HCM. Vamos morar nisso com mais detalhes.
Diagrama de interação SAP HCM-FUSE.
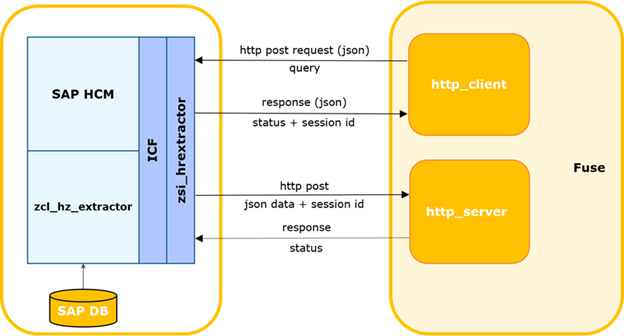
O sistema externo determina a hora da última solicitação bem-sucedida ao SAP.
O processo pode ser iniciado por um cronômetro ou outro evento, incluindo um tempo limite para aguardar uma resposta com dados do SAP e o início de uma solicitação repetida. Em seguida, ele gera uma solicitação delta e a envia ao SAP.
Os dados da solicitação são transmitidos no corpo no formato json.
O método http: POST.
Solicitação de amostra:

o serviço SAP verifica a solicitação quanto à integridade, conformidade com a estrutura SAP atual e a disponibilidade de permissão para acessar a tabela solicitada.
Em caso de erros, o serviço retorna uma resposta com o código e a descrição apropriados. Se o controle for bem-sucedido, ele cria um processo de segundo plano para gerar uma seleção, gera e retorna de forma síncrona um id de sessão exclusivo.
O sistema externo irá registrá-lo em caso de erro. Em caso de resposta com sucesso, envia o id da sessão e o nome da mesa para a qual foi feita a solicitação.
O sistema externo registra a sessão atual como aberta. Se houver outras sessões para esta tabela, elas serão fechadas com um aviso registrado.
O trabalho em segundo plano SAP gera um cursor de acordo com os parâmetros especificados e um pacote de dados do tamanho especificado. Tamanho do pacote - o número máximo de registros que o processo lê do banco de dados. Por padrão, presume-se que seja 2.000. Se a amostra do banco de dados contiver mais registros do que o tamanho do pacote usado, após o primeiro pacote ser transmitido, o próximo bloco é formado com o deslocamento correspondente e o número de pacote incrementado. Os números são incrementados em 1 e enviados estritamente sequencialmente.
Em seguida, o SAP passa o pacote como entrada para o serviço da web do sistema externo. E é o sistema que controla o pacote de entrada. Uma sessão com o id recebido deve ser registrada no sistema e deve estar em um estado aberto. Se o número do pacote for> 1, o sistema deve registrar o recebimento bem-sucedido do pacote anterior (package_id-1).
Em caso de controle bem-sucedido, o sistema externo analisa e salva os dados da tabela.
Além disso, se o sinalizador final estiver presente no pacote e a serialização for bem-sucedida, o módulo de integração é notificado sobre a conclusão bem-sucedida do processamento da sessão e o módulo atualiza o status da sessão.
No caso de um erro de controle / análise, o erro é registrado e os pacotes para esta sessão serão rejeitados pelo sistema externo.
Da mesma forma, no caso contrário, quando o sistema externo retorna um erro, ele é logado e a transmissão dos pacotes é interrompida.
Um serviço de integração foi implementado para solicitar dados no lado SAP HM. O serviço é implementado na estrutura ICF (SAP Internet Communication Framework - help.sap.com/viewer/6da7259a6c4b1014b7d5e759cc76fd22/7.01.22/en-US/488d6e0ea6ed72d5e10000000a42189c.html ). Ele permite que você consulte dados do sistema SAP HCM em tabelas específicas. Ao formar uma solicitação de dados, é possível especificar uma lista de campos específicos e parâmetros de filtragem para obter os dados necessários. Ao mesmo tempo, a implementação do serviço não implica nenhuma lógica de negócio. Algoritmos para cálculo de delta, parâmetros de solicitação, controle de integridade, etc. também são implementados no lado do sistema externo.
Este mecanismo permite coletar e transferir todos os dados necessários em poucas horas. Essa velocidade está quase aceitável, portanto consideramos esta solução temporária, o que possibilitou suprir a necessidade de uma ferramenta de extração no projeto.
Na imagem de destino para resolver o problema de extração de dados, as opções para usar sistemas CDC, como Oracle Golden Gate ou ferramentas ETL, como SAP DS, estão sendo trabalhadas.