
Desde a invenção de sua primeira GPU em 1999, a NVIDIA está na vanguarda dos gráficos 3D e da computação acelerada por GPU. Cada arquitetura NVIDIA é cuidadosamente projetada para oferecer níveis revolucionários de desempenho e eficiência.
O A100, o primeiro GPU com arquitetura NVIDIA Ampere, foi lançado em maio de 2020. Ele fornece uma tremenda aceleração para treinamento de IA, HPC e análise de dados. O A100 é baseado no chip GA100, que é puramente computacional e, ao contrário do GA102, ainda não é para jogos.
As GPUs GA10x são baseadas na arquitetura de GPU NVIDIA Turing. Turing é a primeira arquitetura do mundo a oferecer traçado de raios em tempo real de alto desempenho, gráficos com aceleração de IA e renderização de gráficos profissionais, tudo em um único dispositivo.
Neste artigo, analisaremos as principais mudanças na arquitetura das novas placas de vídeo NVIDIA em comparação com seu antecessor.

Figura 1. Arquitetura Ampere GA10x
Principais recursos do GA102
O GA102 é fabricado com a tecnologia proprietária da NVIDIA de 8 nm - 8N NVIDIA Custom. O chip contém 28,3 bilhões de transistores em um die de 628,4 mm2. Como com todos os RTXs GeForce, o GA102 é baseado em um processador que contém três tipos diferentes de recursos de computação:
- Kernels CUDA para sombreamento programável;
- RT-, (BVH) ;
- , .
Ampere
GPC, TPC SM
Como seus predecessores, o GA102 consiste em Graphics Processing Clusters (GPCs), Texture Processing Clusters (TPCs), Streaming Multiprocessors (SM), unidades de rasterização Raster Operator (ROP) e controladores de memória. O chip completo possui sete unidades GPC, 42 TPCs e 84 SMs.
O GPC é o bloco de alto nível dominante que contém todos os gráficos principais. Cada GPC tem um Raster Engine dedicado e agora também tem duas seções ROP de oito blocos cada, o que é uma inovação na arquitetura Ampere. Além disso, o GPC contém seis TPCs, cada um contendo dois multiprocessadores e um PolyMorph Engine.
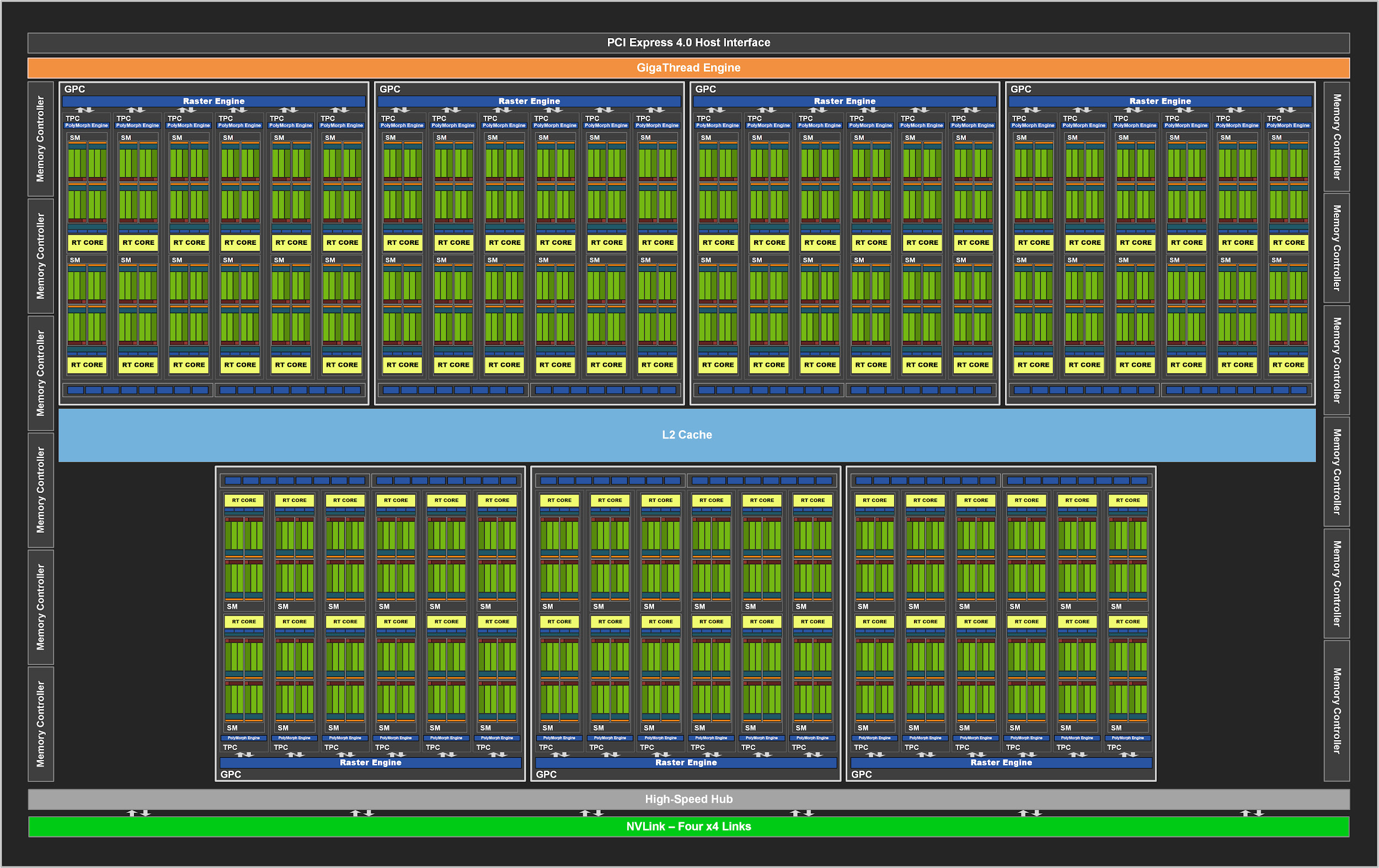
Figura 2. GPU GA102 completo com 84 blocos SM
Por sua vez, cada SM no GA10x contém 128 núcleos CUDA, quatro núcleos tensores de terceira geração, um arquivo de registro de 256 KB, quatro unidades de textura, um núcleo de rastreamento de raio de segunda geração e 128 KB L1 / memória compartilhada, que pode ser configurada para diferentes capacidades dependendo das necessidades de tarefas de computação ou gráficos.
Otimização ROP
Nas GPUs NVIDIA anteriores, os ROPs eram vinculados a um controlador de memória e cache L2. A partir do GA10x, eles fazem parte do GPC, o que melhora o desempenho das operações raster ao aumentar o número total de ROPs.
No total, com sete GPCs e 16 ROPs em cada GPC, a GPU GA102 consiste em 112 ROPs em vez de 96, por exemplo, no TU102. Tudo isso tem um efeito positivo no anti-aliasing de várias amostras, na taxa de preenchimento de pixels e na combinação.
NVLink terceira geração
As GPUs GA102 suportam a interface NVIDIA NVLink de terceira geração, que inclui quatro vias x4, cada uma fornecendo 14,0625 GB / s de largura de banda entre duas GPUs em qualquer direção. Os quatro canais juntos fornecem 56,25 GB / s de largura de banda em cada direção e um total de 112,5 GB / s entre as duas GPUs. Assim, usando NVLink, você pode conectar duas GPUs RTX 3090.
PCIe Gen 4
As GPUs GA10x são equipadas com PCI Express 4.0, que oferece o dobro da largura de banda do PCIe 3.0, taxas de transferência de até 16GTransfers por segundo e, graças ao slot PCIe 4.0 x16, pico de largura de banda de até 64GB / s.
Arquitetura multiprocessador GA10x
A arquitetura de multiprocessador Turing foi a primeira na NVIDIA a ter núcleos separados para acelerar as operações de rastreamento de raios. Então Volta introduziu os primeiros kernels de tensores e Turing introduziu os kernels de tensores avançados de segunda geração. Outra inovação em Turing e Volta é a capacidade de executar operações FP32 e INT32 simultaneamente. O multiprocessador do GA10x oferece suporte a todos os recursos acima e também possui diversos aprimoramentos próprios.
Ao contrário do TU102, que tem oito núcleos tensores de segunda geração, o multiprocessador GA10x tem quatro núcleos tensores de terceira geração, com cada núcleo tensor GA10x duas vezes mais poderoso que o Turing.
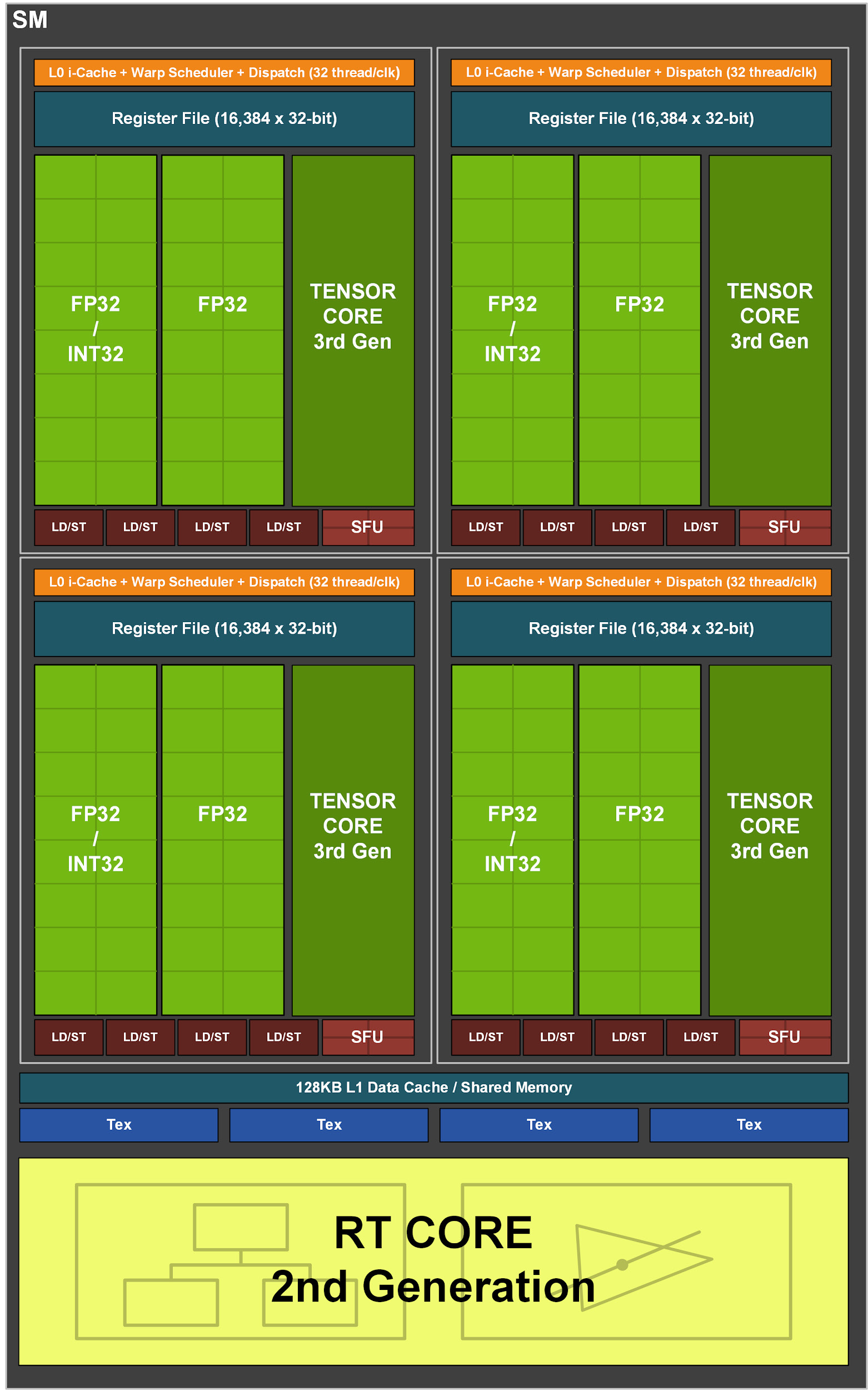
Figura 3. Multiprocessador de streaming GA10x
Dobre a velocidade da computação FP32
A maioria dos cálculos gráficos são operações de ponto flutuante de 32 bits (FP32). O Multiprocessador de streaming Ampere GA10x oferece o dobro da velocidade de operações FP32 em ambos os canais de dados. Como resultado, no contexto do FP32, a GeForce RTX 3090 fornece mais de 35 teraflops, o que é mais de 2 vezes a capacidade de Turing.
O GA10X pode executar 128 operações FP32 ou 64 operações FP32 e 64 operações INT32 por clock, o que é o dobro da velocidade dos cálculos de Turing.
As tarefas de jogos modernos têm uma ampla gama de necessidades de processamento. Muitos cálculos requerem várias operações FP32 (como FFMA, adição de ponto flutuante (FADD) ou multiplicação de ponto flutuante (FMUL)), bem como muitos cálculos inteiros mais simples.
Os multiprocessadores GA10x continuam a suportar operações FP16 de velocidade dupla (HFMA), que também eram suportadas em Turing. E, semelhante às GPUs TU102, TU104 e TU106, no GA10x, as operações FP16 padrão também são tratadas por núcleos tensores.
Memória compartilhada e cache de dados L1
GA10x tem uma arquitetura unificada para memória compartilhada, cache de dados L1 e cache de textura. Este design unificado pode ser modificado com base na carga de trabalho e nas necessidades.
O chip GA102 contém 10.752 KB de cache L1 (em comparação com 6.912 KB no TU102). Além disso, o GA10x também tem o dobro da largura de banda da memória compartilhada de Turing (128 bytes / ciclo versus 64 bytes / ciclo). A largura de banda L1 total para a GeForce RTX 3080 é de 219 GB / s contra 116 GB / s para a GeForce RTX 2080 Super.
Desempenho por watt
Toda a arquitetura NVIDIA Ampere é construída para eficiência - desde lógica, memória, gerenciamento de energia e térmico até design de PCB, software e algoritmos. No mesmo nível de desempenho, as GPUs Ampere são até 1,9x mais eficientes em termos de energia do que dispositivos Turing comparáveis.
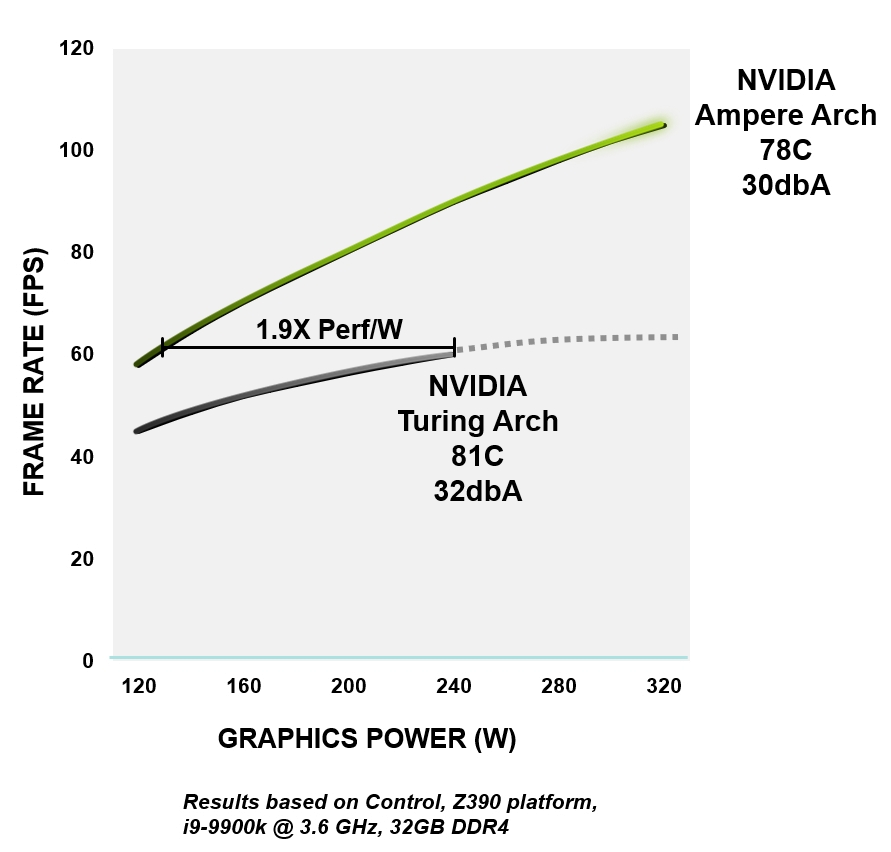
Figura 4. Eficiência energética do RTX 3080 versus arquitetura GeForce RTX 2080 Super
Núcleos RT de segunda geração
Os novos núcleos RT apresentam uma série de melhorias que, combinadas com sistemas de cache atualizados, efetivamente dobram o desempenho de rastreamento de raio dos processadores Ampere em relação ao Turing. Além disso, o GA10x permite que outros processos sejam executados simultaneamente com a computação RT, acelerando significativamente muitas tarefas.
Traçado de raio de segunda geração em GA10x
GeForce RTX baseada na arquitetura Turing foram as primeiras GPUs com as quais o rastreamento de raios cinematográfico se tornou uma realidade em jogos de PC. O GA10x está equipado com tecnologia de rastreamento de raio de segunda geração. Como Turing, os multiprocessadores do GA10x têm blocos de hardware especializados para verificar as interseções dos raios com BVHs e triângulos. Ao mesmo tempo, os núcleos dos multiprocessadores Ampere têm o dobro da velocidade de teste da interseção de raios e triângulos em comparação com Turing.
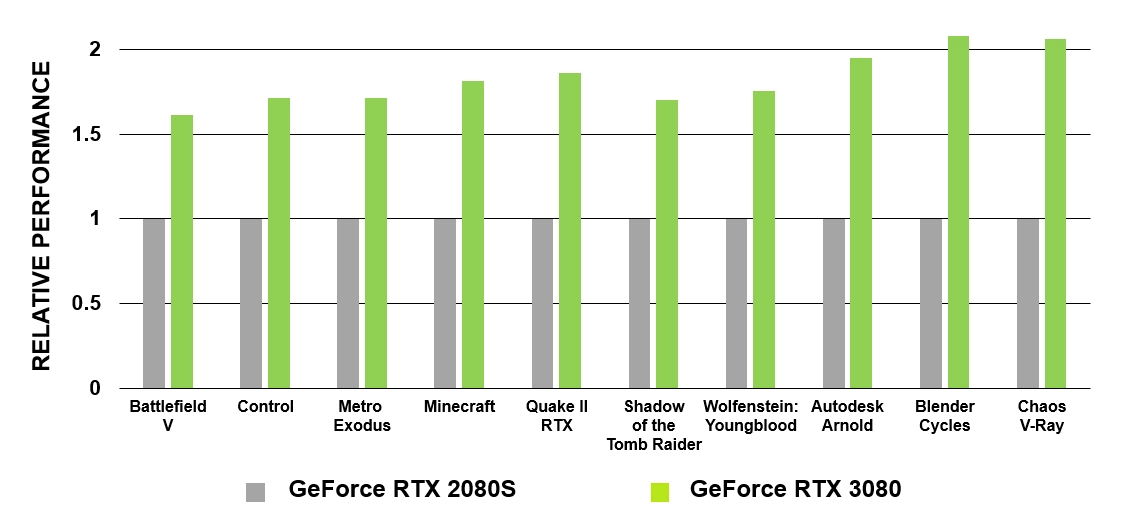
Figura 5. Comparação de desempenho dos núcleos RT da GeForce RTX 3080 e GeForce RTX 2080 Super
O multiprocessador GA10x pode realizar operações simultaneamente e não se limita a computação e gráficos, como era o caso nas gerações anteriores de GPUs. Assim, por exemplo, no GA10x, o algoritmo de redução de ruído pode ser executado simultaneamente com o traçado de raio.

Figura 6. Núcleo RT de segunda geração em GPUs GA10x
Observe que as cargas de trabalho intensivas de RT não aumentam significativamente a carga nos núcleos do multiprocessador, permitindo assim que o poder de processamento do multiprocessador seja usado para outras tarefas. Esta é uma grande vantagem sobre outras arquiteturas concorrentes que não têm núcleos RT dedicados e, portanto, precisam usar seus blocos de construção para gráficos e traçado de raio.
Processadores Ampere RTX em ação
O rastreamento de raios e os sombreadores são intensivos em computação. Mas seria muito mais caro executar tudo apenas com núcleos CUDA, portanto, incluir núcleos tensor e RT ajuda a acelerar o processamento significativamente. A Figura 7 mostra um exemplo de Wolfenstein: Youngblood com traçado de raio ativado em vários cenários.
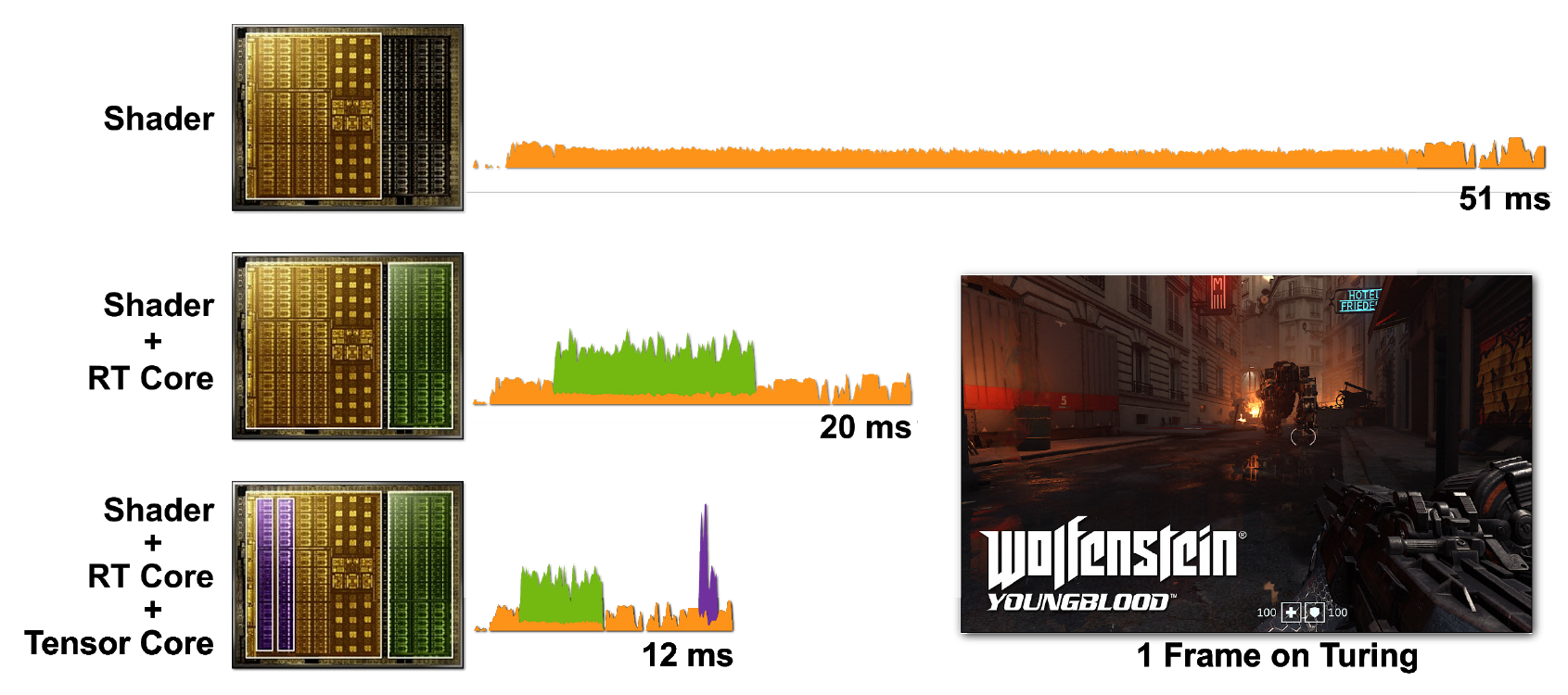
Figura 7. Renderizando um único frame de Wolfenstein: Youngblood em um RTX 2080 Super GPU usando a) núcleos de sombreador (CUDA), b) núcleos de sombreador e núcleos RT, c) núcleos de sombreador, núcleos tensores e núcleos RT. Observe os tempos de quadro decrescentes progressivamente conforme você adiciona a potência dos vários núcleos do processador RTX.
No primeiro caso, leva 51 ms (~ 20 fps) para iniciar um quadro. Quando os núcleos RT são ativados, o quadro é renderizado muito mais rápido - em 20 ms (50 fps). Usar DLSS em núcleos tensores reduz o tempo de quadro para 12 ms (~ 83 fps).
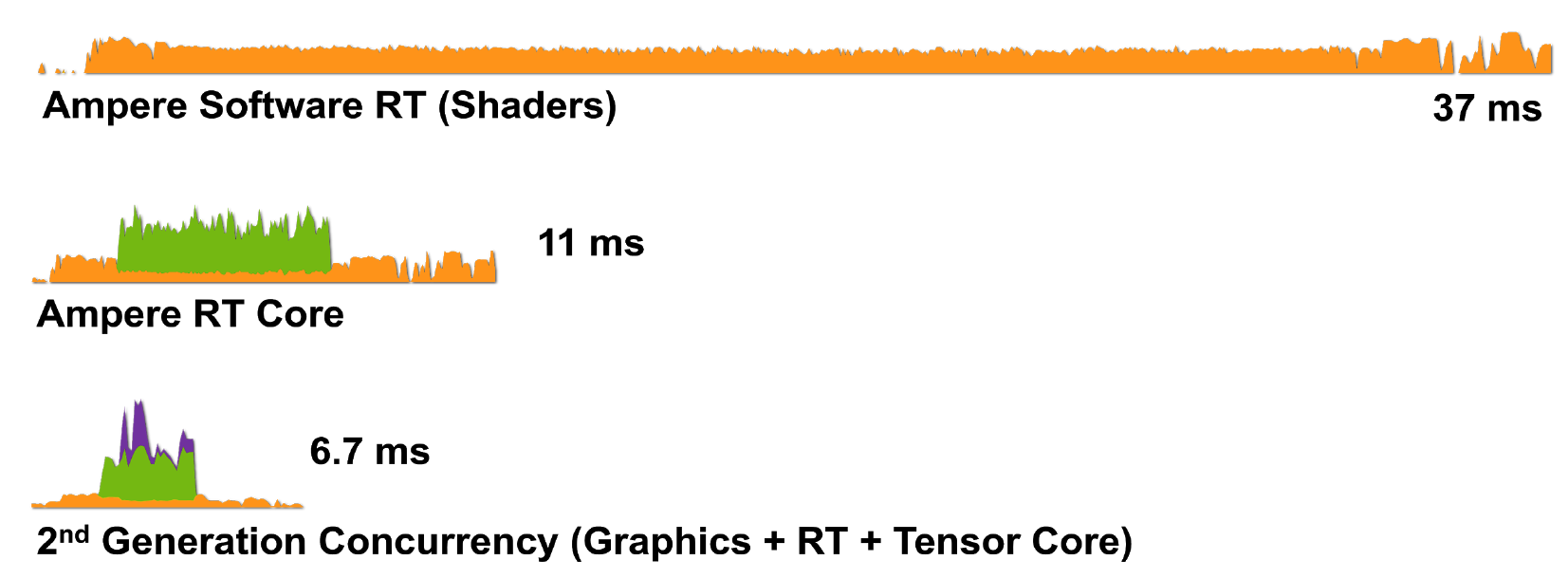
Figura 8. Renderização de um único frame de Wolfenstein: Youngblood em um RTX 3080 usando a) núcleos de shader (CUDA), b) núcleos de shader e núcleos RT, c) núcleos de shader, tensor e núcleos RT.
Portanto, a tecnologia RTX com arquitetura Ampere é ainda mais eficiente para lidar com tarefas de renderização: o RTX 3080 renderiza um quadro em 6,7 ms (150 fps), o que é uma grande melhoria em relação ao RTX 2080.
Traçado de raio acelerado por hardware usando desfoque de movimento
O desfoque de movimento é um movimento frequentemente usado em computação gráfica. Uma imagem fotográfica não é criada instantaneamente, mas expondo o filme à luz por um período limitado de tempo. Os objetos que se movem rápido o suficiente em comparação com o tempo de exposição da câmera aparecerão na foto como listras ou manchas. Para que a GPU crie um desfoque de movimento de aparência realista quando os objetos em uma cena se movem rapidamente na frente de uma câmera estática, ela deve ser capaz de simular como a câmera e o filme funcionam com tais cenas. O desfoque de movimento é especialmente importante na produção de filmes porque os filmes são reproduzidos a 24 quadros por segundo e uma cena sem desfoque de movimento aparecerá nítida e instável.
As GPUs Turing fazem um bom trabalho na aceleração do desfoque de movimento em geral. Porém, no caso da geometria em movimento, a tarefa pode ser mais difícil, uma vez que a informação sobre o BVH muda com a posição dos objetos no espaço.
Como você pode ver na Figura 9, o núcleo de Turing RT realiza uma travessia de hardware da hierarquia BVH, verificando a interseção de raios com BBox e triângulos. O GA10x pode fazer tudo a mesma coisa, mas, além disso, tem um novo bloco Interpolar Posição do Triângulo, que acelera o borrão de movimento no traçado de raio.
Os núcleos Turing e GA10x RT implementam a arquitetura Multiple Instruction Multiple Data (MIMD), que permite que múltiplos feixes sejam processados simultaneamente.
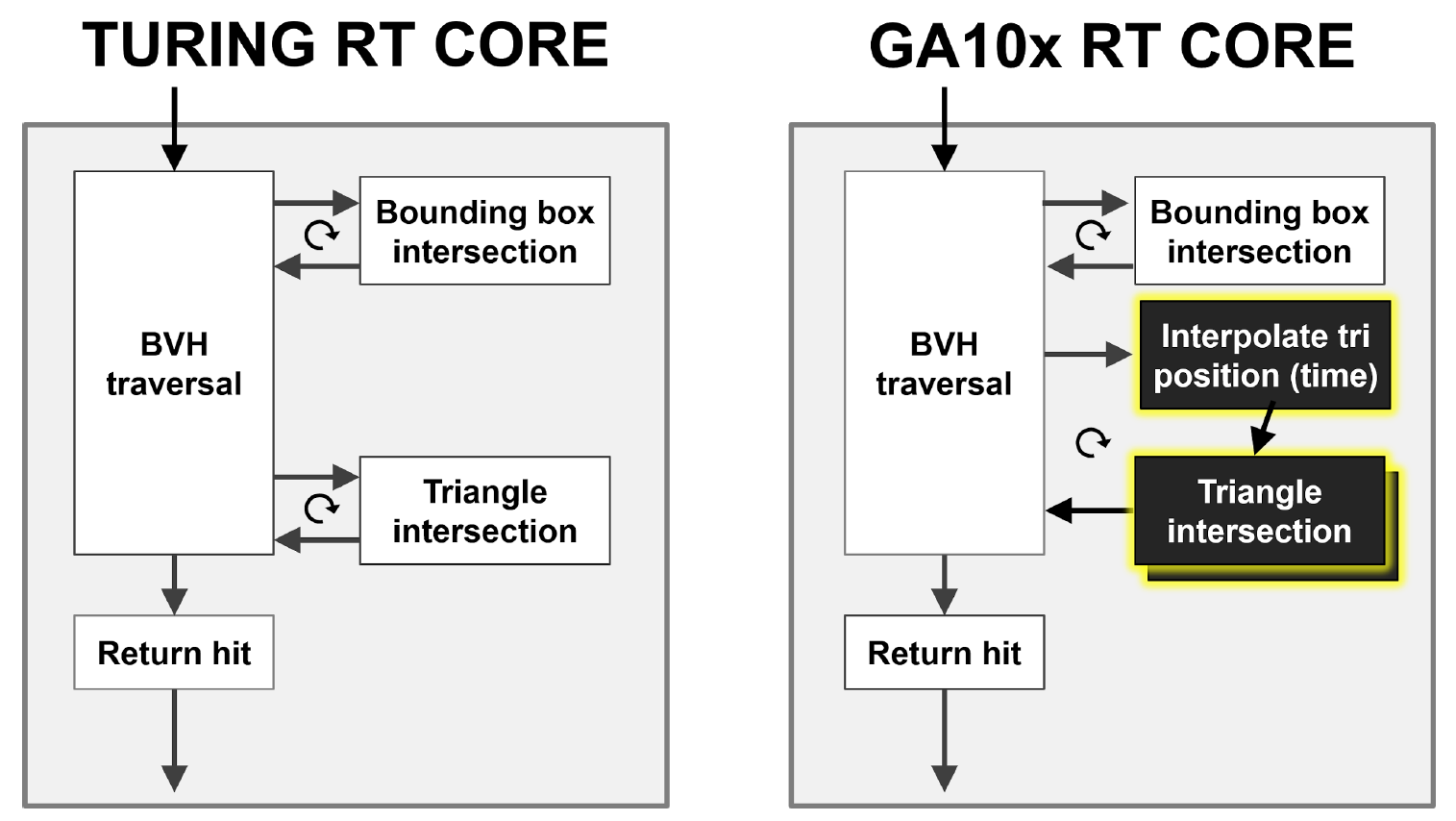
Figura 9. Comparação do desfoque de movimento acelerado por hardware no caso de Turing e Ampere
O principal problema com o desfoque de movimento é que os triângulos na cena não são fixos no tempo. No traçado de raio básico, testes de interseção estática são realizados e, quando um raio atinge um triângulo, ele retorna informações sobre esse acerto. Conforme mostrado na Figura 10, com o desfoque de movimento, nenhum dos triângulos tem coordenadas fixas. Cada raio é marcado com o tempo para indicar seu tempo de rastreamento, e a posição do triângulo e a interseção do raio é determinada a partir da equação BVH.
Se este processo não for acelerado por hardware, pode causar muitos problemas, inclusive devido à sua não linearidade.
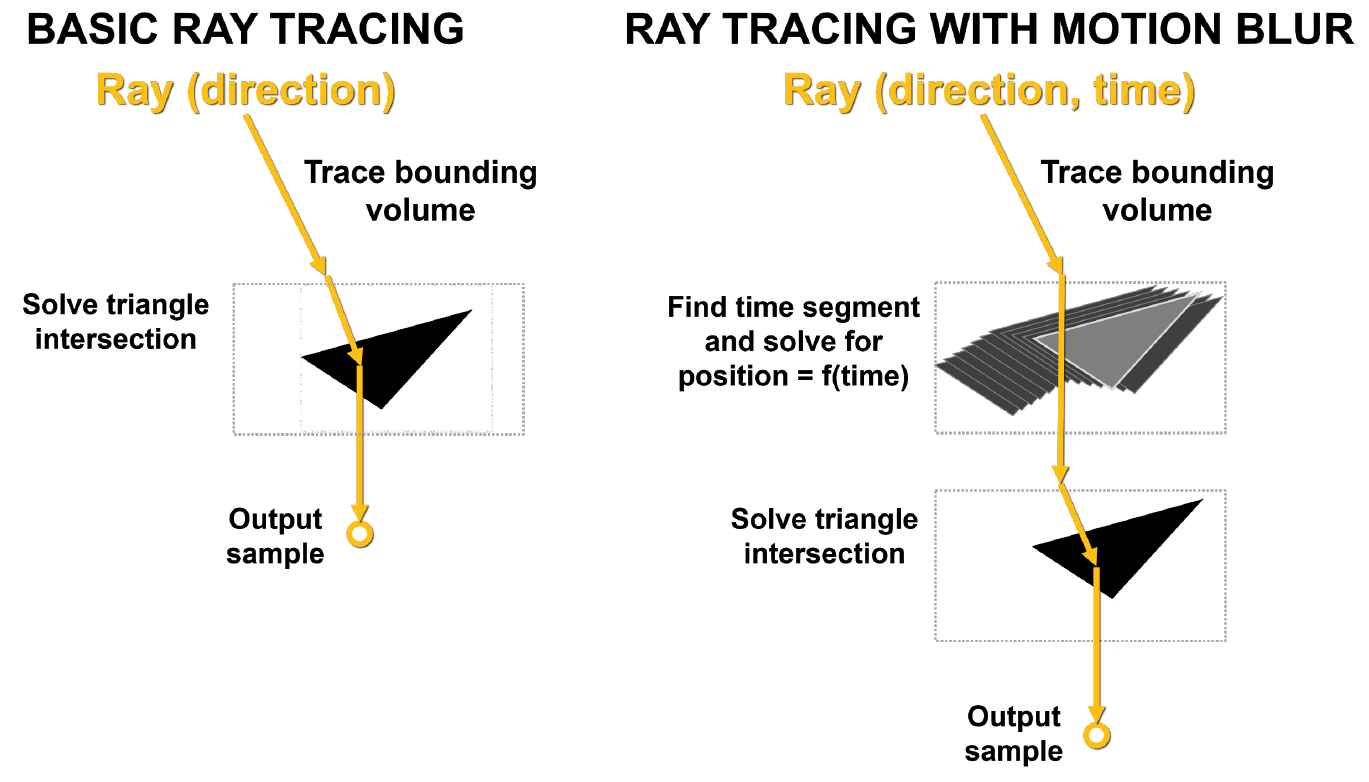
Desenhando. 10. Traçado de raio básico e traçado de raio com borrão de movimento
No lado esquerdo da Figura 11, os raios enviados para uma cena estática atingem o mesmo triângulo ao mesmo tempo. Pontos brancos mostram o local de acerto, este resultado é retornado. No caso de borrão de movimento, cada raio existe em seu próprio momento no tempo. Cada feixe é atribuído aleatoriamente a um carimbo de hora diferente. Por exemplo, os raios laranja tentam cruzar os triângulos laranja ao mesmo tempo, e então os raios verde e azul fazem a mesma coisa. No final, as amostras são misturadas, produzindo um resultado embaçado matematicamente mais correto.
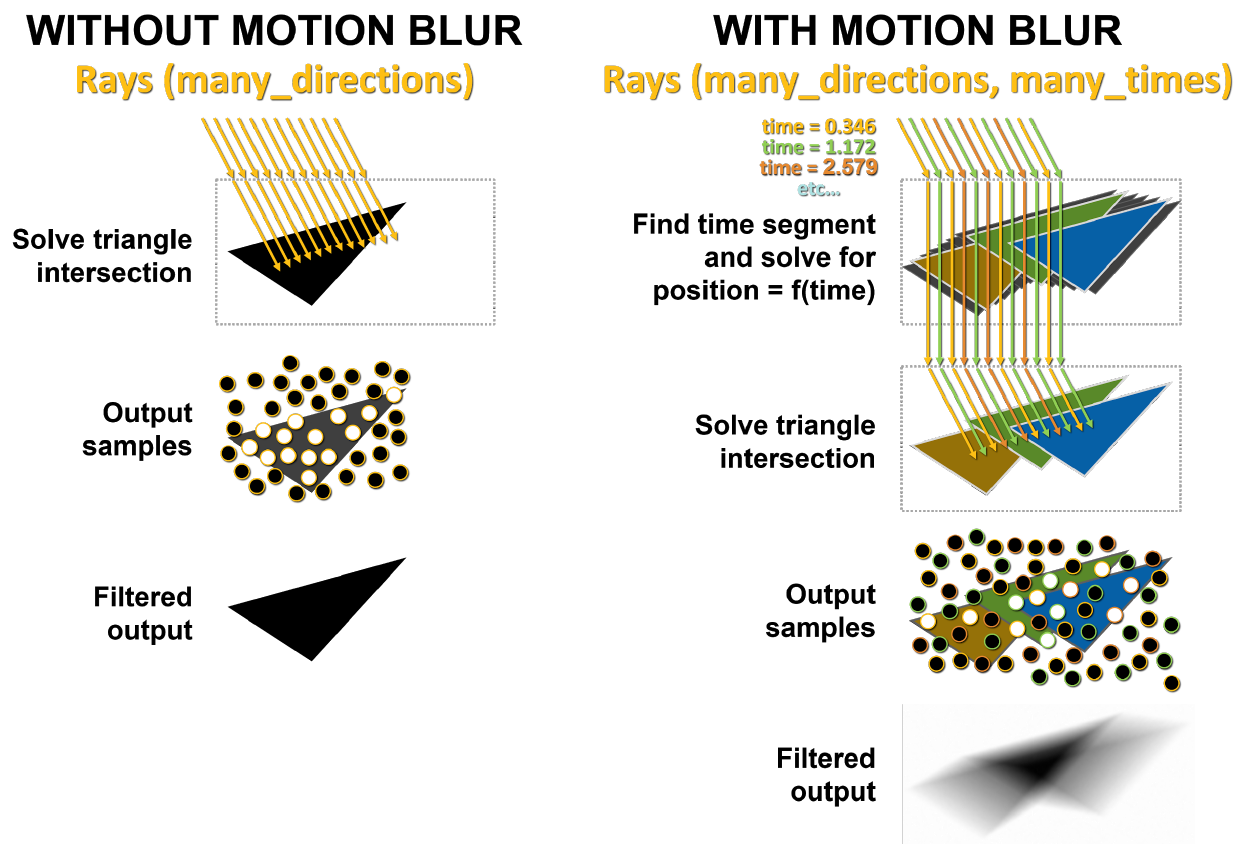
Figura 11. Renderização sem desfoque de movimento e com desfoque em GA10x
O bloco Interpolate Triangle Position interpola os triângulos em BVH entre os triângulos já existentes com base no movimento do objeto, de modo que os raios os cruzem nas localizações esperadas nos momentos especificados pelos carimbos de data / hora dos raios. Esta abordagem permite a renderização precisa de desfoque de movimento traçado por raio até oito vezes mais rápido do que Turing.
O desfoque de movimento acelerado por hardware GA10x é compatível com Blender 2.90, Chaos V-Ray 5.0, Autodesk Arnold e Redshift Renderer 3.0.X usando a API NVIDIA OptiX 7.0.
A velocidade de renderização do desfoque de movimento é até 5x mais rápida com o RTX 3080 em comparação com o RTX 2080 Super.
Núcleos de tensor de 3ª geração em GPUs GA10x
GA10x incorpora novos NVIDIA Tensor Cores de terceira geração, oferecendo suporte para novos tipos de dados, melhor desempenho, eficiência e flexibilidade de programação. O novo recurso de dispersão dobra o desempenho do Tensor Cores em relação à geração anterior de Turing. Funções AI, como NVIDIA DLSS para super-resolução AI (agora com suporte para 8K), NVIDIA Broadcast para processamento de voz e vídeo e NVIDIA Canvas para desenho também são mais rápidas.
Kernels de tensor são unidades de execução especializadas projetadas para realizar operações de tensor / matriz - a principal função computacional no aprendizado profundo. Eles são necessários para melhorar a qualidade gráfica com DLSS (Deep Learning Super Sampling), cancelamento de ruído baseado em IA, remoção de ruído de fundo em bate-papos de voz em jogos com RTX Voice e muitos outros aplicativos.
A introdução do Tensor Cores nas GPUs de jogos GeForce permitiu o aprendizado profundo em tempo real em aplicativos de jogos pela primeira vez. O projeto do núcleo tensor de terceira geração em GPUs GA10x aumenta ainda mais o desempenho bruto e alavanca novos modos de precisão computacional, como TF32 e BFloat16. Isso desempenha um grande papel nos aplicativos de serviços neurais NVIDIA NGX baseados em IA para melhorar gráficos, renderização e outros recursos.
Comparação de núcleos tensores de Turing e Ampere
Os núcleos do tensor de ampere foram reorganizados em Turing para melhorar a eficiência e reduzir o consumo de energia. A arquitetura do núcleo Ampere SM tem menos núcleos tensores, mas cada um é mais poderoso.
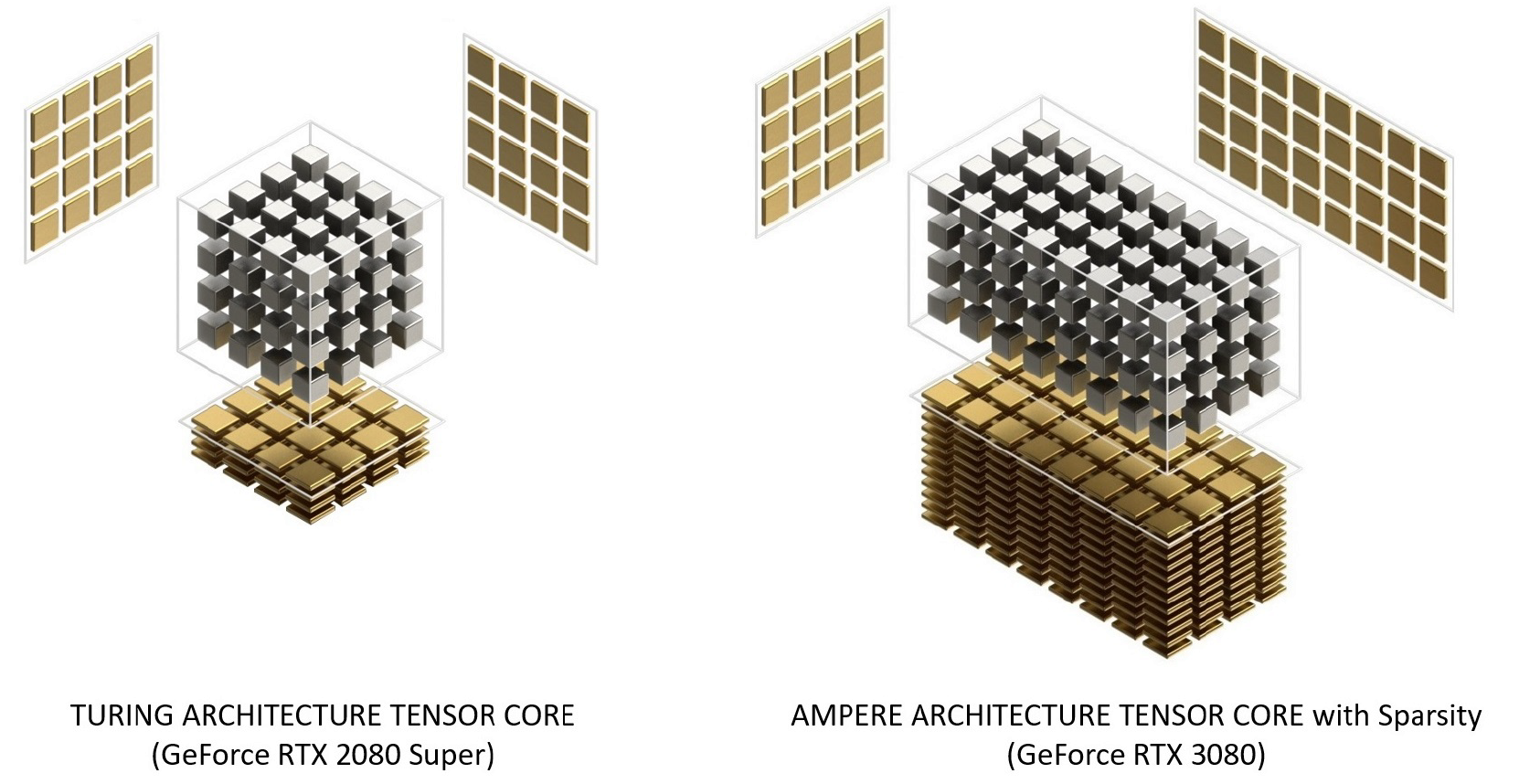
Figura 12. Núcleos de tensor com arquitetura de Turing e Ampere. A GeForce RTX 3080 oferece largura de banda de pico FP16 Tensor Core 2,7x mais rápida do que a GeForce RTX 2080 Super
Esparsidade estruturada de granulação fina
Com a GPU A100, a NVIDIA está apresentando a dispersão estruturada de granulação fina, uma nova abordagem para dobrar a largura de banda computacional para redes neurais profundas. Este recurso também é compatível com GPUs GA10x e ajuda a acelerar algumas operações de renderização de gráficos com base em IA.
Como as redes de aprendizado profundo podem adaptar pesos por meio do aprendizado por feedback, em geral, as restrições estruturais não afetam a precisão dos modelos treinados.
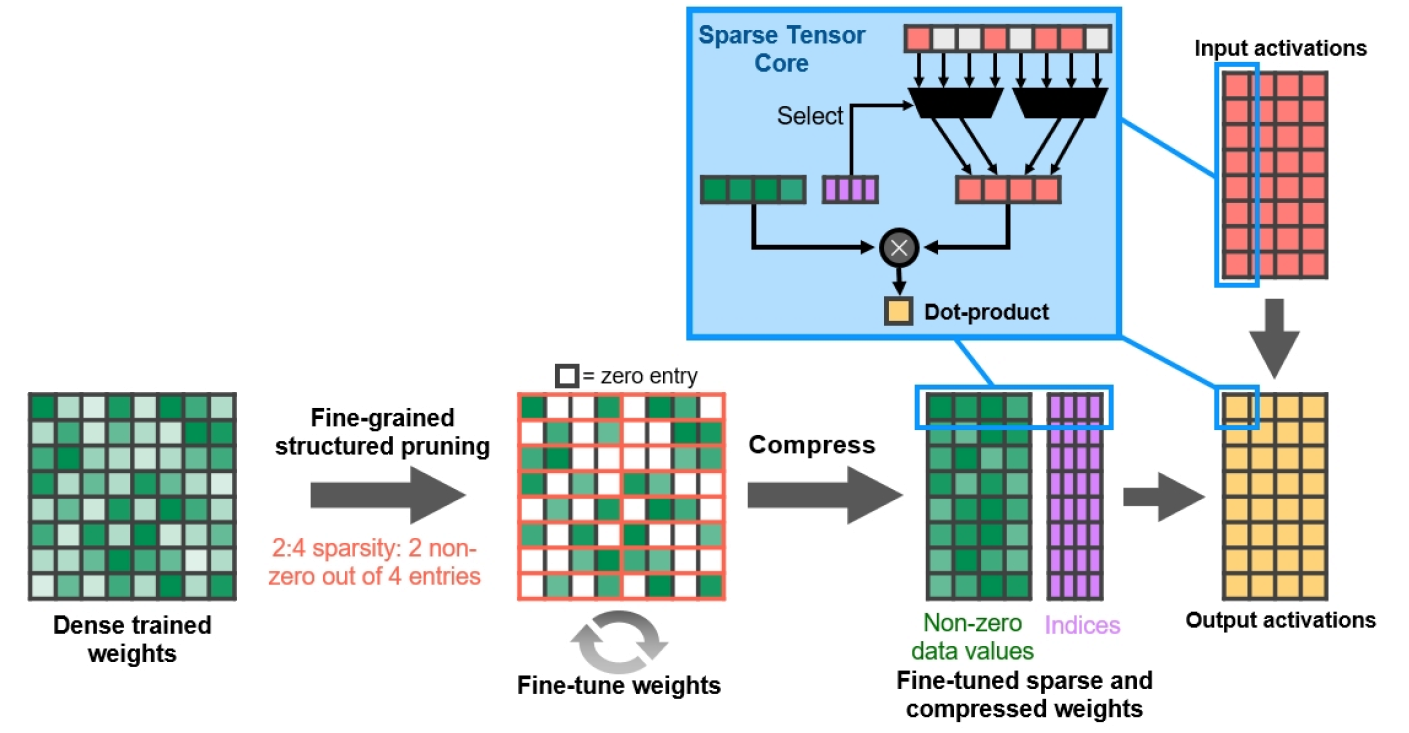
Figura 13. Esparsidade estruturada de granulação fina
A NVIDIA desenvolveu um algoritmo de dispersão de rede neural profunda simples e versátil usando um padrão de dispersão 2: 4 estruturado. A rede é primeiro treinada com pesos densos, então ocorre a poda estruturada de baixa granularidade, após a qual os valores zero podem ser descartados e o restante da matemática é compactado para aumentar o rendimento. O algoritmo não afeta a precisão da rede treinada para inferência, apenas a acelera.
NVIDIA DLSS 8K
Renderizar uma imagem com traçado de raio em uma alta taxa de quadros é extremamente caro do ponto de vista computacional. Antes do advento da NVIDIA Turing, acreditava-se que sua implementação levaria anos. Para ajudar com esse problema, a NVIDIA criou Deep Learning Supersampling (DLSS).

Figura 14. Watch Dogs: Legion com DLSS em 1080p, 4K e 8K. Observe que o texto e os detalhes mais nítidos fornecidos pelo DLSS em 8K
DLSS só estão ficando melhores no NVIDIA Ampere com o uso de núcleos tensores de terceira geração e fator de escala de super-resolução 9x, que pela primeira vez torna possível rodar um jogo ray-traced a 8K a 60 fps.
15. GeForce RTX 3090 60 fps 8K DLSS . , . Core i9-10900K
GDDR6X
Os jogos de PC modernos e os aplicativos criativos exigem muito mais largura de banda de memória para lidar com geometria de cena cada vez mais complexa, texturas mais detalhadas, traçado de raios, inferência de IA e, claro, sombreamento e superamostragem.
GDDR6X é a primeira memória gráfica a exceder 900 GB / s. Para conseguir isso, uma tecnologia de sinalização inovadora e modulação de amplitude de pulso de quatro níveis (PAM4) foram usadas, revolucionando coletivamente a maneira como os dados são movidos na memória. Com o algoritmo PAM4, GDDR6X transmite mais dados a uma taxa muito mais rápida, movendo dois bits de dados por vez, o que dobra a taxa de dados de E / S do esquema PAM2 / NRZ anterior.
O GDDR6X atualmente suporta 19,5 Gbps para a GeForce RTX 3090 e 19 Gbps para a GeForce RTX 3080. Graças a isso, a GeForce RTX 3080 oferece 1,5 vez o desempenho de memória de seu predecessor, o RTX 2080 Super. ...
A Figura 16 mostra uma comparação da estrutura de GDDR6 (esquerda) e GDDR6X (direita). GDDR6X transmite os mesmos dados na metade da frequência de GDDR6. Ou, alternativamente, GDDR6X pode dobrar sua largura de banda efetiva enquanto mantém a mesma frequência.

Figura 16. GDDR6X usando sinais PAM4 mostra melhor desempenho e eficiência do que GDDR6
Para resolver os problemas de SNR encontrados na sinalização PAM4, um novo esquema de codificação MTA (Prevenção de Transição Máxima) foi desenvolvido. O MTA impede que os sinais de alta velocidade vão do mais alto para o mais baixo e vice-versa.

Figura 17. Nova codificação em GDDR6X
Suportando taxas de dados de até 19,5 Gbps em chips GA10x, GDDR6X oferece pico de largura de banda de memória de até 936 GB / s, 52% a mais do que a GPU TU102 usada no GeForce RTX 2080 Ti. GDDR6X tem o maior salto de largura de banda em 10 anos depois das GPUs da série GeForce 200.
RTX IO
Os jogos modernos contêm mundos enormes. Com o desenvolvimento de tecnologias como a fotogrametria, elas estão cada vez mais imitando a realidade e, por isso, estão contidas em arquivos com volume crescente. Os maiores projetos de jogos ocupam mais de 200 GB, o que é 3 vezes mais do que há quatro anos, e esse número só aumentará com o tempo.
Os jogadores estão cada vez mais se voltando para SSDs para reduzir o tempo de carregamento do jogo: enquanto os discos rígidos são limitados a 50-100 MB / s de largura de banda, os SSDs M.2 PCIe Gen4 mais recentes leem dados a até 7 GB / s.
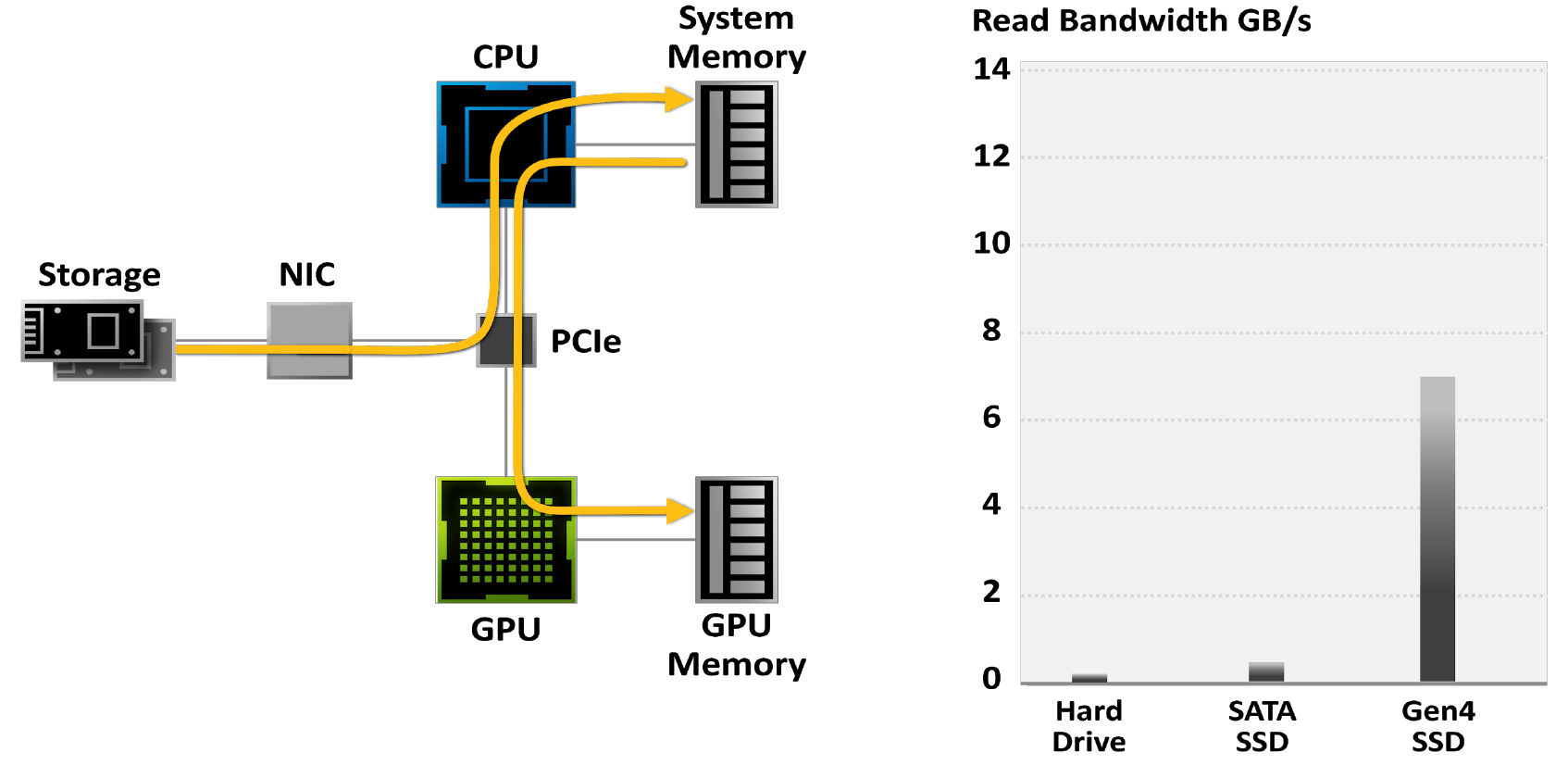
Figura 18. Jogos limitados por sistemas tradicionais de E / S

Figura 19. Usando um modelo de armazenamento tradicional, desempacotar um jogo pode levar todos os 24 núcleos de processador. Os motores de jogos modernos ultrapassaram as capacidades das APIs de armazenamento tradicionais. É por isso que uma nova geração de arquitetura de E / S é necessária. Aqui, as barras cinzas indicam a taxa de transferência de dados, blocos pretos e azuis - os núcleos da CPU necessários para isso.
NVIDIA RTX IO é um conjunto de tecnologias que fornecem carregamento e desempacotamento rápido de ativos baseados em GPU e oferecem desempenho de I / O até 100x mais rápido do que discos rígidos e APIs de armazenamento tradicionais.
NVIDIA RTX IO é alimentado pela API DirectStorage da Microsoft, armazenamento de última geração projetado especificamente para PCs de jogos SSD NVMe atuais. O NVIDIA RTX IO oferece descompressão sem perdas, permitindo que os dados sejam lidos em forma compactada por meio do DirectStorage e entregues à GPU. Isso alivia a carga da CPU movendo os dados do armazenamento para a GPU de uma forma compactada mais eficiente e dobrando o desempenho de E / S.

Figura 20. O RTX IO oferece 100x a largura de banda e 20x a utilização da CPU. Barras cinza e verde indicam a taxa de transmissão, blocos pretos e azuis são necessários para este núcleo da CPU.
Display e mecanismo de vídeo
DisplayPort 1.4a com DSC 1.2a
A marcha em direção a resoluções e taxas de quadros cada vez mais altas continua, e as GPUs NVIDIA Ampere estão se esforçando para permanecer na vanguarda da indústria para oferecer ambos. Os jogadores agora podem jogar em telas 4K (3820 x 2160) a 120 Hz e 8K (7680 x 4320) a 60 Hz - quatro vezes a contagem de pixels de 4K.
O mecanismo de arquitetura Ampere foi projetado para suportar muitas das novas tecnologias incluídas nas interfaces de exibição mais rápidas disponíveis atualmente. Isso inclui DisplayPort 1.4a, que oferece 8K @ 60Hz com VESA Display Stream Compression (DSC) 1.2a. As novas GPUs Ampere podem ser conectadas a dois monitores de 8K 60Hz com apenas um cabo por monitor.
HDMI 2.1 com DSC 1.2a
A arquitetura NVIDIA Ampere adiciona suporte para HDMI 2.1, a atualização mais recente da especificação HDMI, pela primeira vez para GPUs discretas. O HDMI aumentou a largura de banda máxima para 48 Gbps, o que também permite formatos HDR dinâmicos. O suporte para 8K @ 60Hz com HDR requer compressão DSC 1.2a ou formato de pixel 4: 2: 0.
NVDEC de 5ª geração - decodificação de vídeo acelerada por hardware
As GPUs NVIDIA incluem a decodificação de vídeo acelerada por hardware de 5ª geração (NVDEC), que fornece decodificação de vídeo por hardware completa para uma variedade de codecs populares.

Figura 21. Formatos de codificação e decodificação de vídeo suportados por
GPUs GA10x O decodificador NVIDIA de quinta geração no GA10x oferece suporte à decodificação acelerada por hardware dos seguintes codecs de vídeo em plataformas Windows e Linux: MPEG-2, VC-1, H.264 (AVCHD), H.265 (HEVC), VP8, VP9 e AV1.
NVIDIA é o primeiro fabricante de GPU a fornecer suporte de hardware para decodificação AV1.
Decodificação de hardware AV1
Embora o AV1 seja muito eficiente na compactação de vídeo, sua decodificação exige muito do computador. Os decodificadores de software modernos causam alta utilização da CPU e dificultam a reprodução de vídeo de definição ultra-alta. Nos testes da NVIDIA, o processador Intel i9 9900K teve uma média de 28 quadros por segundo no YouTube em 8K60 HDR, com utilização da CPU excedendo 85%. As GPUs GA10x podem reproduzir AV1 passando a decodificação para NVDEC, que é capaz de reproduzir conteúdo HDR de até 8K60 com uso de CPU muito baixo (~ 4% na mesma CPU do teste anterior).
NVENC de sétima geração - codificação de vídeo acelerada por hardware
A codificação de vídeo pode ser uma tarefa computacional complexa, mas se você carregá-la no NVENC, o mecanismo gráfico e a CPU serão liberados para outras operações. Por exemplo, ao fazer streaming de jogos para Twitch.tv usando Open Broadcaster Software (OBS), descarregar a codificação de vídeo para NVENC permitirá que o motor da GPU seja alocado para renderizar o jogo e a CPU para outras tarefas do usuário.
NVENC permite:
- Codificação de latência ultrabaixa de alta qualidade e streaming de jogos e aplicativos sem usar a CPU;
- codificação de altíssima qualidade para arquivamento, streaming OTT, vídeo da web;
- Codificação de potência ultrabaixa por stream (W / stream).
Com configurações de streaming compartilhado para Twitch e YouTube, a codificação de hardware baseada em NVENC em GPUs GA10x supera os codificadores de software x264 usando a predefinição Rápida e está no mesmo nível de x264 Médio, uma predefinição que normalmente requer a alimentação de dois computadores. Isso tira drasticamente a carga da CPU. A codificação 4K é muita carga de trabalho para uma configuração típica de CPU, mas o codificador GA10x NVENC fornece codificação de alta resolução contínua de até 4K em H.264 e até 8K em HEVC.
Conclusão
Com cada nova arquitetura de processador, a NVIDIA se esforça para oferecer um desempenho revolucionário à próxima geração, ao mesmo tempo que apresenta novos recursos que melhoram a qualidade da imagem. Turing foi a primeira GPU a introduzir o traçado de raios acelerado por hardware, um recurso que já foi considerado o Santo Graal da computação gráfica. Hoje, efeitos de traçado de raio incrivelmente realistas e fisicamente precisos estão sendo adicionados a muitos novos jogos AAA para PC, e traçado de raio acelerado por GPU é considerado uma obrigação para a maioria dos jogadores de PC. As novas GPUs NVIDIA GA10x Ampere oferecem os recursos e o desempenho de que você precisa para aproveitar esses novos jogos com traçado de raios com taxas de quadros até 2x mais rápidas do que as disponíveis atualmente.Outro recurso do Turing - processamento AI acelerado por CPU aprimorado que melhora o cancelamento de ruído, renderização e outros aplicativos gráficos - também é levado para o próximo nível graças à arquitetura Ampere.
Finalmente, um link para o documento completo .