
Imagine um log de 2,5 gigabytes após uma construção com falha. São três milhões de linhas. Você está procurando um bug ou regressão que aparece na milionésima linha. Provavelmente, é simplesmente impossível encontrar uma dessas linhas manualmente. Uma opção é uma diferença entre as últimas compilações bem-sucedidas e as que falharam, na esperança de que o bug grave linhas incomuns nos logs. A solução da Netflix é mais rápida e precisa do que LogReduce - sob o corte.
Netflix e a linha na pilha de log
O diff padrão md5 é rápido, mas imprime pelo menos centenas de milhares de linhas candidatas para visualização porque mostra diferenças de linha. Uma variação de logreduce é um diff difuso usando uma pesquisa de k-vizinho mais próximo que encontra cerca de 40.000 candidatos, mas leva uma hora. A solução abaixo encontra 20.000 strings candidatas em 20 minutos. Graças à magia do código aberto, isso tem apenas cerca de cem linhas de código Python.
Solução - uma combinação de representações de palavras vetoriais que codificam as informações semânticas de palavras e frases e um hash baseado em localização(LSH - Local Sensitive Hash), que efetivamente distribui elementos próximos em alguns grupos e elementos distantes em outros grupos. Combinando representações vetor de palavras e LSH é uma ótima idéia menos de dez anos atrás .
Observação: executamos o Tensorflow 2.2 na CPU e com execução imediata para transferência de aprendizagem e scikit-learnNearestNeighborpara k vizinhos mais próximos. Existem implementações sofisticadas de vizinho mais próximo aproximado que seriam melhores para resolver o problema do vizinho mais próximo baseado em modelo.
Representação de palavras vetoriais: o que é e por quê?
Construir um pacote de palavras com k categorias (codificação k-hot, generalização da codificação unitária) é um ponto de partida típico (e útil) para desduplicação, pesquisa e problemas de similaridade entre texto não estruturado e semiestruturado. Este tipo de pacote de palavras de codificação se parece com um dicionário com palavras individuais e seu número. Exemplo com a frase "log com erro, verifique o log".
{"log": 2, "in": 1, "error": 1, "check": 1}
Essa codificação também é representada por um vetor, onde o índice corresponde a uma palavra e o valor corresponde ao número de palavras. Abaixo é mostrada a frase "log com erro, verificar log" como um vetor, em que a primeira entrada é reservada para contar as palavras "log", a segunda para contar as palavras "in" e assim por diante:
[2, 1, 1, 1, 0, 0, 0, 0, 0, ...]
Observação: o vetor consiste em muitos zeros. Zeros são todas as outras palavras do dicionário que não estão nesta frase. O número total de entradas de vetor possíveis, ou a dimensão de um vetor, é o tamanho do vocabulário do seu idioma, que geralmente é de milhões de palavras ou mais, mas compactado para centenas de milhares com truques inteligentes . Vejamos o dicionário e as representações vetoriais da frase "problema de autenticação". As palavras que correspondem às cinco primeiras entradas do vetor não aparecem na nova frase.
{"problem": 1, "authenticating": 1}
Acontece que:
[0, 0, 0, 0, 1, 1, 0, 0, 0, ...]
As frases "problema de autenticação" e "log in error, check log" são semanticamente semelhantes. Ou seja, eles são essencialmente a mesma coisa, mas lexicalmente tão diferentes quanto possível. Eles não têm palavras comuns. Em termos de diferenças difusas, poderíamos dizer que eles são muito semelhantes para distingui-los, mas a codificação md5 e o documento processado por k-hot com kNN não suportam isso.
A redução de dimensão usa álgebra linear ou redes neurais artificiais para colocar palavras, frases ou linhas de registro semanticamente semelhantes próximas umas das outras em um novo espaço vetorial. São utilizadas representações vetoriais. Em nosso exemplo, "log in error, check log" pode ter um vetor de cinco dimensões para representar:
[0.1, 0.3, -0.5, -0.7, 0.2]
A frase "problema de autenticação" pode ser
[0.1, 0.35, -0.5, -0.7, 0.2]
Esses vetores são próximos uns dos outros em termos de medidas como similaridade de cosseno , ao contrário de seus vetores de bolsas de palavras. As visualizações densas de tamanho reduzido são realmente úteis para documentos curtos, como linhas de montagem ou syslog.
Na verdade, você substituiria milhares ou mais dimensões do dicionário por apenas uma representação de 100 dimensões rica em informações (não cinco). Abordagens modernas para redução de dimensionalidade incluem decomposição de valor singular da matriz de coocorrência de palavras ( GloVe ) e redes neurais especializadas ( word2vec , BERT , ELMo ).
E quanto ao agrupamento? Vamos voltar ao log de construção
Brincamos que o Netflix é um serviço de produção de logs que ocasionalmente exibe vídeos. Log, streaming, tratamento de exceções - são centenas de milhares de solicitações por segundo. Portanto, o escalonamento é necessário quando queremos aplicar o ML aplicado em telemetria e registro. Por esse motivo, temos o cuidado de dimensionar a desduplicação de texto, procurar semelhanças semânticas e detectar outliers de texto. Quando os problemas de negócios são resolvidos em tempo real, não há outra maneira.
Nossa solução envolve representar cada linha em um vetor de baixa dimensão e, opcionalmente, "ajustar" ou simultaneamente atualizar o modelo incorporado, atribuindo-o a um cluster e definindo as linhas em diferentes clusters como "diferentes". Hashing de localização- um algoritmo probabilístico que permite atribuir clusters em tempo constante e pesquisar os vizinhos mais próximos em tempo quase constante.
O LSH funciona mapeando uma representação vetorial para um conjunto de escalares. Os algoritmos de hash padrão tendem a evitar colisões entre quaisquer duas entradas correspondentes. O LSH procura evitar colisões se as entradas estiverem distantes e as promove se forem diferentes, mas próximas umas das outras no espaço vetorial.
O vetor que representa a frase "erro de registro, erro de verificação" pode ser combinado com um número binário
01. Então01representa um cluster. O vetor "problema de autenticação" com alta probabilidade também pode ser exibido em 01. Assim, o LSH fornece uma comparação difusa e resolve o problema inverso - uma diferença difusa. As primeiras aplicações do LSH eram sobre espaços vetoriais multidimensionais de um conjunto de palavras. Não poderíamos pensar em um único motivo pelo qual ele não trabalharia com espaços de representação vetorial de palavras. Há indícios de que outros pensaram o mesmo .

O exemplo acima mostra o uso de LSH ao colocar personagens no mesmo grupo, mas de cabeça para baixo.
O trabalho que fizemos para aplicar LSH e cortes vetoriais detectando outliers de texto em logs de construção agora permite que o engenheiro visualize uma pequena parte das linhas de log para identificar e corrigir possíveis erros críticos para os negócios. Ele também permite que você alcance o agrupamento semântico de quase qualquer linha de log em tempo real.
Essa abordagem agora funciona em todas as versões do Netflix. A parte semântica permite agrupar elementos aparentemente diferentes com base em seu significado e exibir esses elementos em relatórios de emissões.
Alguns exemplos
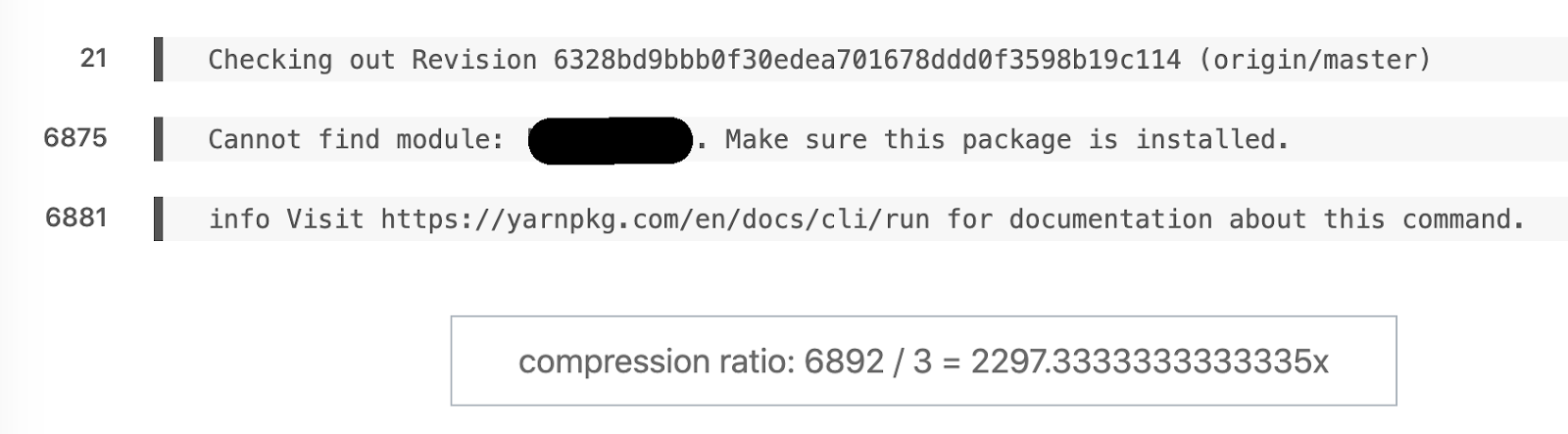
Exemplo favorito de diferença semântica. 6892 linhas se transformaram em 3.
Outro exemplo: esta montagem registrou 6044 linhas, mas permaneceram no relatório 171. O problema principal surgiu quase imediatamente na linha 4036.

Claro, é mais rápido analisar 171 linhas do que 6044. Mas como conseguimos toras de montagem tão grandes? Algumas das milhares de tarefas de construção que são testes de estresse para produtos eletrônicos de consumo são executadas no modo de rastreamento. É difícil trabalhar com tamanho volume de dados sem processamento preliminar.

Taxa de compressão: 91366/455 = 205,3.
Existem vários exemplos que refletem as diferenças semânticas entre estruturas, linguagens e scripts de construção.
Conclusão
A maturidade dos produtos de aprendizagem de transferência de código aberto e SDK permitiu ao LSH resolver o problema de pesquisa semântica do vizinho mais próximo em muito poucas linhas de código. Estávamos interessados nos benefícios especiais que a transferência de aprendizagem e o ajuste fino trazem para o aplicativo. Ficamos felizes em poder resolver esses problemas e ajudar as pessoas a fazerem o que fazem de melhor e mais rápido.
Esperamos que você esteja pensando em ingressar na Netflix e se tornar um dos grandes colegas cuja vida tornamos a vida mais fácil com o aprendizado de máquina. O envolvimento é o valor central da Netflix, e estamos particularmente interessados em formar diferentes perspectivas sobre as equipes de tecnologia. Portanto, se você trabalha em análise, engenharia, ciência de dados ou qualquer outro campo e tem um histórico não típico do setor, gostaríamos especialmente de ouvir de você!
Se você tiver alguma dúvida sobre os recursos do Netflix, entre em contato com os colaboradores do LinkedIn: Stanislav Kirdey , William High Como você resolve o problema da busca de registros
?
Descubra os detalhes de como obter uma profissão de alto perfil do zero ou Subir de nível em habilidades e salários, fazendo cursos online SkillFactory:
- Machine Learning (12 )
- «Machine Learning Pro + Deep Learning» (20 )
- « Machine Learning Data Science» (20 )
- Data Science (12 )
E
