A história descrita não é uma fantasia, mas uma descrição coletiva de alguns eventos em 2020. Em grandes empresas, um plano de recuperação de desastre (DRP) está sempre disponível para esse caso. Nas corporações, os especialistas em continuidade de negócios são responsáveis por isso. Já nas médias e pequenas empresas, a solução para esses problemas recai sobre o departamento de TI. Você precisa entender a lógica do negócio por si mesmo, entender o que pode cair e onde, criar proteção e implementar.
É ótimo se o profissional de TI consegue negociar com a empresa e discutir a necessidade de proteção. Mas eu vi mais de uma vez como a empresa economizou em uma solução de recuperação de desastres (DR), por considerá-la redundante. Quando aconteceu um acidente, uma longa recuperação ameaçou com perdas e o negócio não estava pronto. Você pode repetir o quanto quiser: “Mas eu te disse” - o serviço de TI ainda terá que restaurar os serviços.

Do ponto de vista de um arquiteto, direi como evitar essa situação. Na primeira parte do artigo irei mostrar o trabalho preparatório: como discutir três questões com o cliente para a escolha das ferramentas de proteção:
- O que estamos protegendo?
- Do que estamos protegendo?
- Quão fortes estamos protegendo?
Na segunda parte, falaremos sobre as opções para responder à pergunta: com o que se defender. Darei exemplos de casos de como diferentes clientes constroem sua proteção.
O que protegemos: esclarecimento de funções críticas de negócios
É melhor começar a preparação discutindo o plano de desastre com o cliente comercial. A principal dificuldade aqui é encontrar uma linguagem comum. O cliente geralmente não se importa com o funcionamento da solução de TI. Ele se preocupa se o serviço pode desempenhar funções de negócios e ganhar dinheiro. Por exemplo: se o site está funcionando, e o sistema de pagamento está “mentindo”, não há recebimento de clientes, e os “extremos” ainda são especialistas em TI.
Um profissional de TI pode achar difícil negociar por vários motivos:
- O serviço de TI não está totalmente ciente do papel do sistema de informação nos negócios. Por exemplo, se não houver uma descrição disponível dos processos de negócios ou um modelo de negócios transparente.
- Nem todo o processo depende do departamento de TI. Por exemplo, quando parte do trabalho é executado por contratados e os especialistas de TI não têm influência direta sobre eles.
Eu estruturaria a conversa assim:
- Explicamos às empresas que acidentes acontecem com todos e que a recuperação leva tempo. O melhor é demonstrar a situação, como ela acontece e quais as consequências possíveis.
- Mostramos que nem tudo depende do serviço de TI, mas você está pronto para ajudar com um plano de ação na sua área de responsabilidade.
- Pedimos ao cliente empresarial que responda: se acontecer um apocalipse, qual processo deve ser restaurado primeiro? Quem participa e como?
A empresa precisa de uma resposta simples, por exemplo: é necessário que a central de atendimento continue registrando aplicativos 24 horas por dia, sete dias por semana.
- - .
, .
: - , . 1 -, .
- , . :
- ( ),
- , ( ),
- ( ).
- ( ),
- Descobrimos os possíveis pontos de falha: os nós do sistema, dos quais depende o desempenho do serviço. Separadamente, marcamos os nós que são suportados por outras empresas: operadoras de telecomunicações, provedores de hospedagem, centros de dados e assim por diante. Com isso, você pode voltar ao cliente empresarial para a próxima etapa.
O que protegemos de: riscos
Então, descobrimos com o cliente comercial de quais riscos estamos protegendo em primeiro lugar. Vamos dividir condicionalmente todos os riscos em dois grupos:
- perda de tempo devido ao tempo de inatividade do serviço;
- perda de dados devido a impacto físico, fatores humanos, etc.
As empresas têm medo de perder dados e tempo - tudo isso leva à perda de dinheiro. Então, novamente fazemos perguntas sobre cada grupo de risco:
- Para esse processo, podemos estimar quanto valem a perda de dados e o tempo desperdiçado?
- Que dados não podemos perder?
- Onde não podemos permitir tempo de inatividade?
- Quais eventos são mais prováveis e mais ameaçadores para nós?
Após a discussão, entenderemos como priorizar os pontos de falha.
Quanto protegemos: RPO e RTO
Quando os pontos críticos de falha são compreendidos, calculamos as métricas de RTO e RPO.
Deixe-me lembrar que RTO (objetivo de tempo de recuperação) é o tempo permitido desde o momento do acidente até a recuperação total do serviço. Em linguagem comercial, esse é o tempo de inatividade aceitável. Se soubermos quanto dinheiro o processo trouxe, podemos calcular as perdas de cada minuto de inatividade e calcular a perda permitida.
RPO (objetivo do ponto de recuperação) é um ponto de recuperação de dados válido. Ele determina o tempo em que podemos perder dados. Do ponto de vista comercial, a perda de dados pode levar a, por exemplo, multas. Essas perdas também podem ser convertidas em dinheiro.
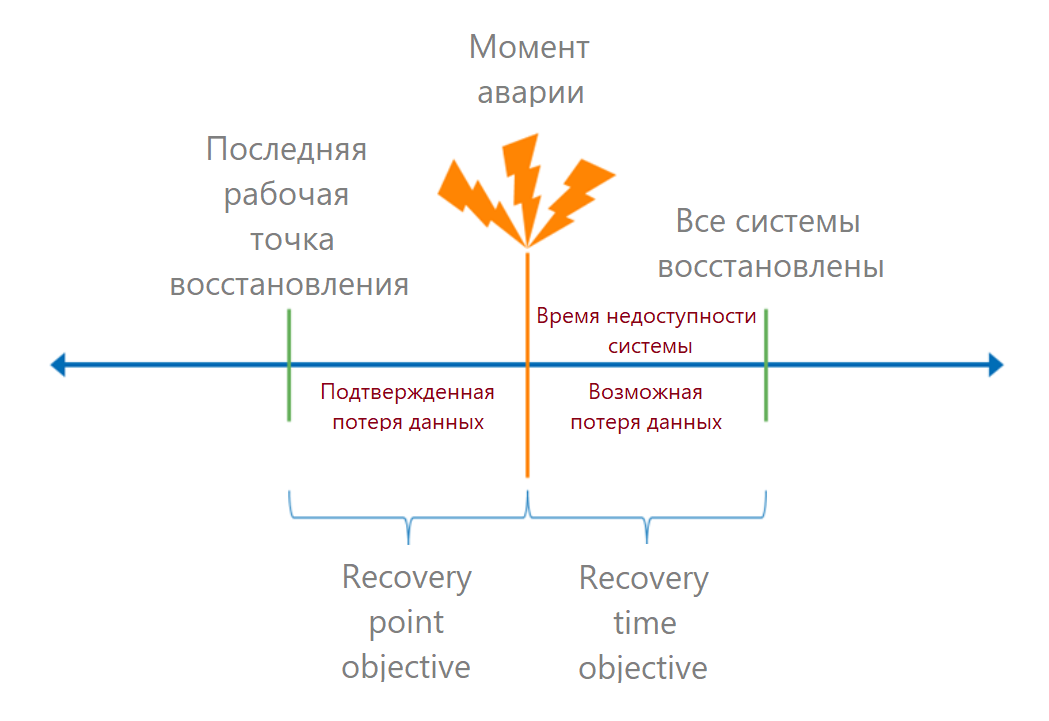
O tempo de recuperação deve ser calculado para o usuário final: quanto tempo levará para fazer logon no sistema. Portanto, primeiro adicionamos os tempos de recuperação de todos os elos da cadeia. Muitas vezes, eles cometem um erro: pegam o RTO do provedor do SLA e esquecem os outros termos.
Vejamos um exemplo específico. O usuário insere 1C, o sistema abre com um erro de banco de dados. Ele contata o administrador do sistema. A base está na nuvem, o administrador do sistema relata o problema ao provedor de serviços. Digamos que todas as comunicações levem 15 minutos. Na nuvem, um banco de dados desse tamanho será restaurado a partir de um backup em uma hora, portanto, RTO do lado do provedor de serviço - uma hora. Mas este não é o prazo final, para o usuário foram adicionados 15 minutos para detectar o problema.Esses cálculos mostrarão à empresa de quais fatores externos o tempo de recuperação depende. Por exemplo, se o escritório estiver inundado, primeiro você precisa detectar o vazamento e consertá-lo. Vai levar um tempo que não depende de TI.
Em seguida, o administrador do sistema precisa verificar se o banco de dados está correto, conectá-lo a 1C e iniciar os serviços. Demora mais uma hora, o que significa que o RTO do lado do administrador já é de 2 horas e 15 minutos. O usuário precisa de mais 15 minutos: faça o login, verifique se apareceram as transações necessárias. 2 horas e 30 minutos é o tempo total de recuperação para o serviço neste exemplo.
Como protegemos: escolhendo ferramentas para diferentes riscos
Depois de discutir todos os pontos, o cliente já entende o custo do acidente para o negócio. Agora você pode selecionar ferramentas e discutir o orçamento. Vou mostrar por meio de exemplos de casos de clientes quais ferramentas oferecemos para diferentes tarefas.
Vamos começar com o primeiro grupo de riscos: perdas devido ao tempo de inatividade do serviço. As soluções para esta tarefa devem fornecer um bom RTO.
-
— . , , , - .
, . . , 2 . , .
RTO: . .
: .
: , , - .
-
RTO, .
active-passive active-active. , . . , .
RTO: .
: , .
: - . .
: - . . DR , . .
. . -
, , 2 -. - , --. , .
RTO: 0.
: .
: , , .
: . :
- .
- . : «» «». «» , . «» . . .
, . . - .
-
, : . , . DR: VMware vCloud Availability (vCAV). on-premise . vCAV .
RPO RTO: 5 .
: , , . vCAV, , PAYG (10% ).
: 6 . : , — . , .
VMware vCloud Availability. - 5 . , - .
Todas as soluções consideradas fornecem alta disponibilidade, mas não evitam a perda de dados devido a um vírus de criptografia ou erro acidental de um funcionário. Nesse caso, precisamos de backups que fornecerão o RPO necessário.
5. Não se esqueça dos backups
Todos sabem que você precisa fazer backups, mesmo se tiver a melhor solução de recuperação de desastres. Portanto, vou relembrar brevemente alguns pontos.
A rigor, o backup não é DR. E é por causa disso:
- Leva muito tempo. Se os dados forem medidos em terabytes, a recuperação levará mais de uma hora. Você precisa restaurar, atribuir uma rede, verificar o que liga, ver se os dados estão em ordem. Portanto, você só pode obter um bom RTO se houver poucos dados.
- Os dados podem não ser recuperados na primeira vez e você precisa dar tempo para uma segunda ação. Por exemplo, há momentos em que não sabemos exatamente quando os dados foram perdidos. Digamos que a perda foi percebida às 15h, e as cópias são feitas a cada hora. A partir das 15h, observamos todos os pontos de recuperação: 14h, 13h e assim por diante. Se o sistema for crítico, tentamos minimizar a idade do ponto de restauração. Mas se os dados necessários não foram encontrados no novo backup, passamos ao próximo ponto - este é o tempo adicional.
Dito isso, a programação de backup pode fornecer o RPO necessário . Para backups, é importante fornecer redundância geográfica em caso de problemas com o site principal. É recomendável manter alguns dos backups separadamente.
O plano final de recuperação de desastres deve incluir pelo menos 2 ferramentas:
- Uma das opções 1-4, que protegerá os sistemas contra travamentos e travamentos.
- Backup para proteger os dados contra perda.
Também vale a pena cuidar de um canal de comunicação de backup para o caso de o provedor de Internet principal travar. E voila! - Já está pronto o DR do salário mínimo.