Olá! Meu nome é Igor Narazin, sou o líder da equipe de logística do Delivery Club. Quero contar a vocês como construímos e transformamos nossa arquitetura e como isso afeta nossos processos de desenvolvimento.
Agora o Delivery Club (assim como todo o mercado de foodtech) está crescendo muito rapidamente, o que cria um grande número de desafios para a equipe técnica, que podem ser resumidos por dois dos critérios mais importantes:
- É necessário garantir alta estabilidade e disponibilidade de todas as partes da plataforma.
- Ao mesmo tempo, mantenha um alto ritmo de desenvolvimento de novos recursos.
Parece que esses dois problemas são mutuamente exclusivos: ou transformamos a plataforma, tentando fazer novas alterações o mínimo possível até terminar, ou desenvolvemos rapidamente novos recursos sem mudanças drásticas no sistema.
Mas conseguimos (até agora) ambos. Como fazemos isso será discutido mais adiante.
Em primeiro lugar, falarei sobre nossa plataforma : como a transformamos, levando em consideração os volumes de dados em constante crescimento, que critérios aplicamos aos nossos serviços e que problemas enfrentamos ao longo do caminho.
Em segundo lugar, vou compartilhar como resolvemos o problema de entrega de recursos sem entrar em conflito com as mudanças na plataforma e sem degradação desnecessária do sistema.
Vamos começar com a plataforma.
No começo havia um monólito
As primeiras linhas do código do Delivery Club foram escritas 11 anos atrás e, nas melhores tradições do gênero, a arquitetura era um monólito em PHP. Durante 7 anos foi preenchido com cada vez mais funcionalidade até enfrentar os problemas clássicos da arquitetura monolítica.
No início, ficamos completamente satisfeitos com ele: era fácil de manter, testar e implantar. E ele lidou com as cargas iniciais sem problemas. Mas, como geralmente é o caso, em algum ponto alcançamos tais taxas de crescimento que nosso monólito se tornou um gargalo muito perigoso:
- qualquer falha ou problema no monólito afetará absolutamente todos os nossos processos;
- o monólito está rigidamente ligado a uma pilha específica que não pode ser alterada;
- levando em consideração o crescimento da equipe de desenvolvimento, torna-se difícil fazer mudanças: a alta conectividade dos componentes não permite entrega rápida de recursos;
- o monólito não pode ser dimensionado de forma flexível.
Isso nos levou à (surpresa) arquitetura de microsserviço - muito foi dito e escrito sobre seus méritos e deméritos. O principal é que resolve um dos nossos principais problemas e permite-nos obter a máxima disponibilidade e tolerância a falhas de todo o sistema. Não vou me alongar sobre isso neste artigo; em vez disso, vou contar a você com exemplos como fizemos isso e por quê.
Nosso principal problema era o tamanho da base de código monolith e a pouca experiência da equipe nela (a plataforma é o que chamamos de velha). Claro, no início queríamos apenas pegar e cortar o monólito para resolver completamente o problema. Mas percebemos muito rapidamente que levaria mais de um ano, e o número de mudanças que foram feitas ali nunca permitiria que isso terminasse.
Portanto, tomamos um caminho diferente: deixamos como está e decidimos construir o resto dos serviços em torno do monólito. Ele continua a ser o principal ponto de lógica de processamento de pedido e mestre de dados, mas começa a transmitir dados para outros serviços.
Ecossistema
Como Andrey Evsyukov disse em um artigo sobre nossas equipes, destacamos as principais áreas nas áreas de domínio: P&D, Logística, Consumidor, Fornecedor, Interno, Plataforma. Dentro destas áreas, as principais áreas de domínio com as quais os serviços trabalham já se concentram: por exemplo, para a Logística, são os correios e encomendas, e para o Vendedor - restaurantes e postos.
Em seguida, precisamos subir a um nível mais alto e construir um ecossistema de nossos serviços em torno da plataforma: o processamento de pedidos está no centro e é o mestre dos dados, o restante dos serviços é construído em torno dele. Ao mesmo tempo, é importante que tornemos nossas direções autônomas: se uma parte falha, o resto continua funcionando.
Com cargas baixas, construir o ecossistema necessário é bastante simples: nossos processos de processamento e armazenamento de dados e serviços de referência recorrem a eles quando necessário.
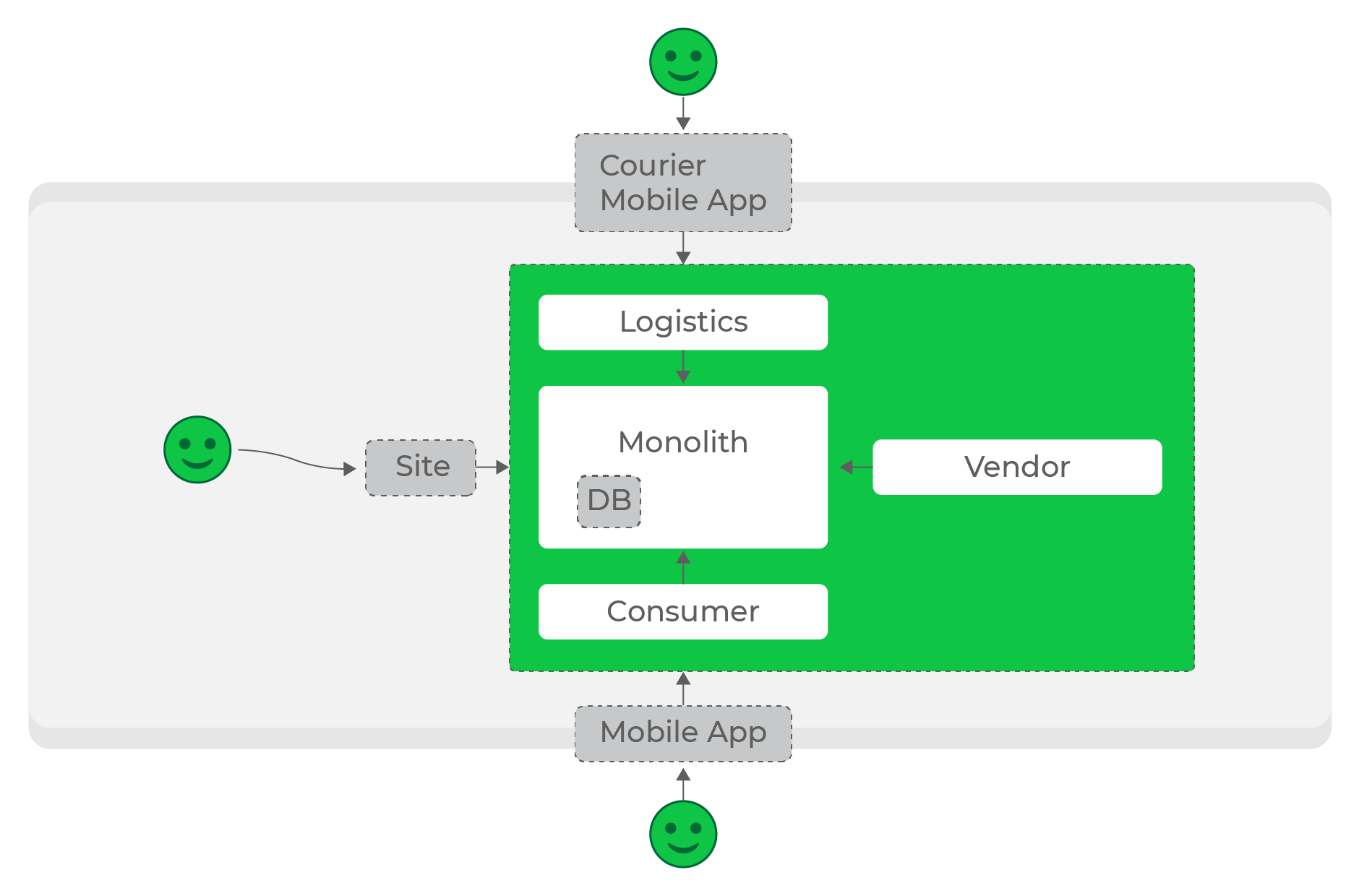 Baixas cargas, solicitações síncronas, tudo funciona muito bem.
Baixas cargas, solicitações síncronas, tudo funciona muito bem.
Nos primeiros estágios, fizemos exatamente isso: a maioria dos serviços se comunicava com solicitações HTTP síncronas. Sob uma certa carga, isso era permitido, mas quanto mais o projeto e o número de serviços cresciam, mais problema se tornava.
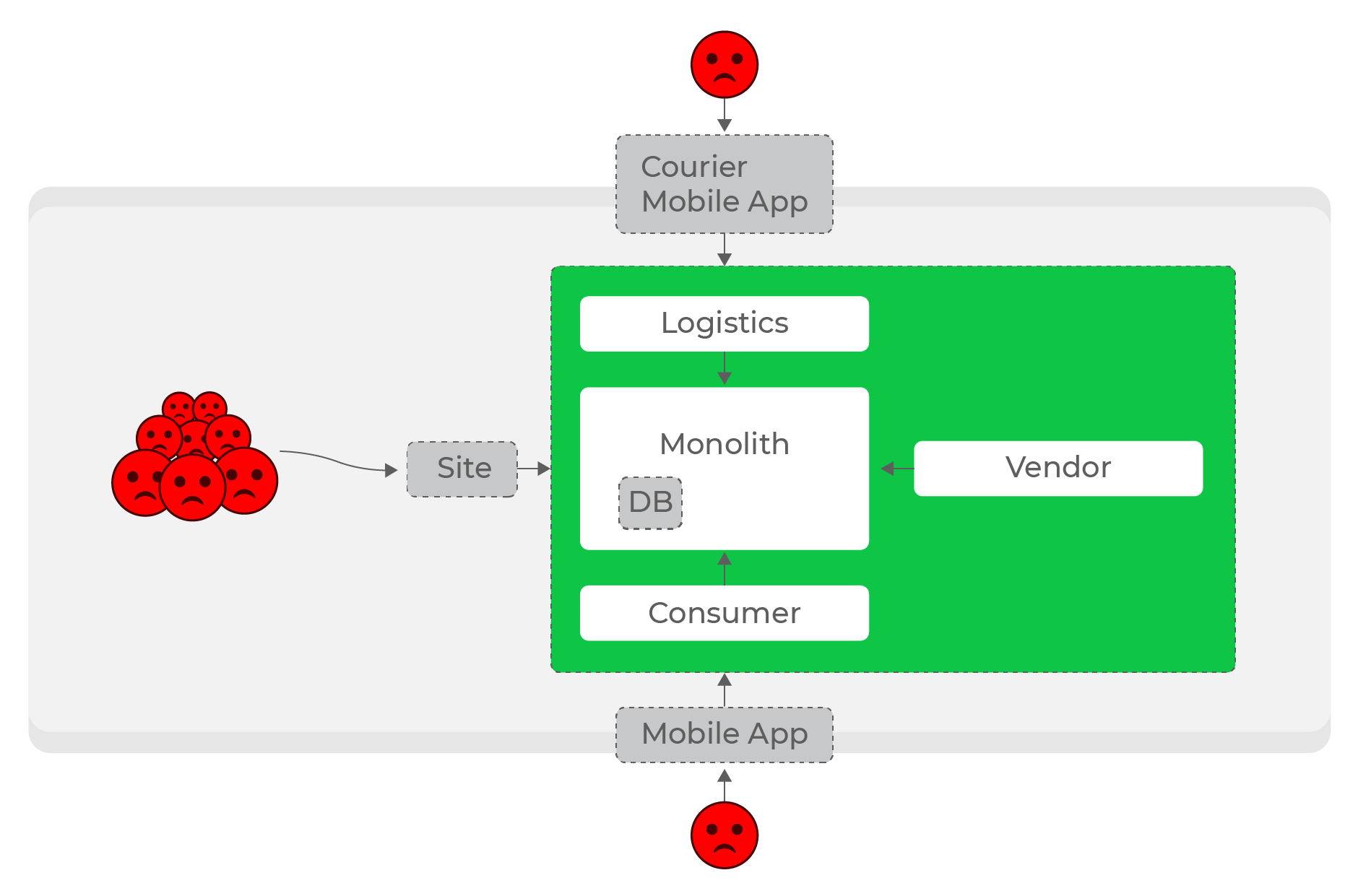
Cargas elevadas, solicitações síncronas: todos sofrem, até mesmo usuários de domínios completamente diferentes - correios.
É ainda mais difícil tornar os serviços autônomos dentro das direções: por exemplo, um aumento na carga de logística não deve afetar o resto do sistema. Com qualquer número de solicitações síncronas, esse é um problema insolúvel. Obviamente, era necessário abandonar as solicitações síncronas e passar para a comunicação assíncrona.
Barramento de dados
Assim, tivemos muitos gargalos, onde acessamos os dados em modo síncrono. Esses locais eram muito perigosos em termos de aumento de carga.
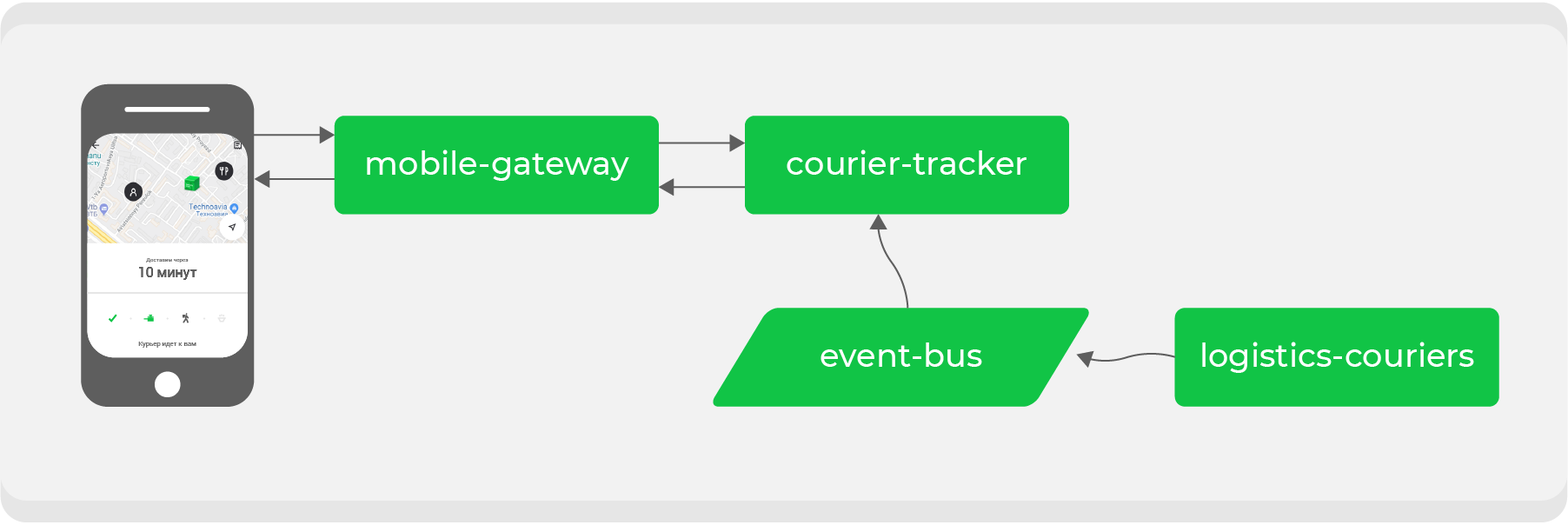
Aqui está um exemplo. Quem fez uma encomenda através do Delivery Club, pelo menos uma vez, sabe que depois de o transportador levantar a encomenda, o cartão fica visível. Nele você pode acompanhar o movimento do mensageiro em tempo real. Vários microsserviços estão envolvidos para esse recurso, os principais são:
mobile-gatewayque é um back-end para front-end de um aplicativo móvel;courier-tracker, que armazena a lógica de recebimento e envio de coordenadas;logistics-couriersque armazena essas coordenadas. Eles são enviados de aplicativos móveis de correio.
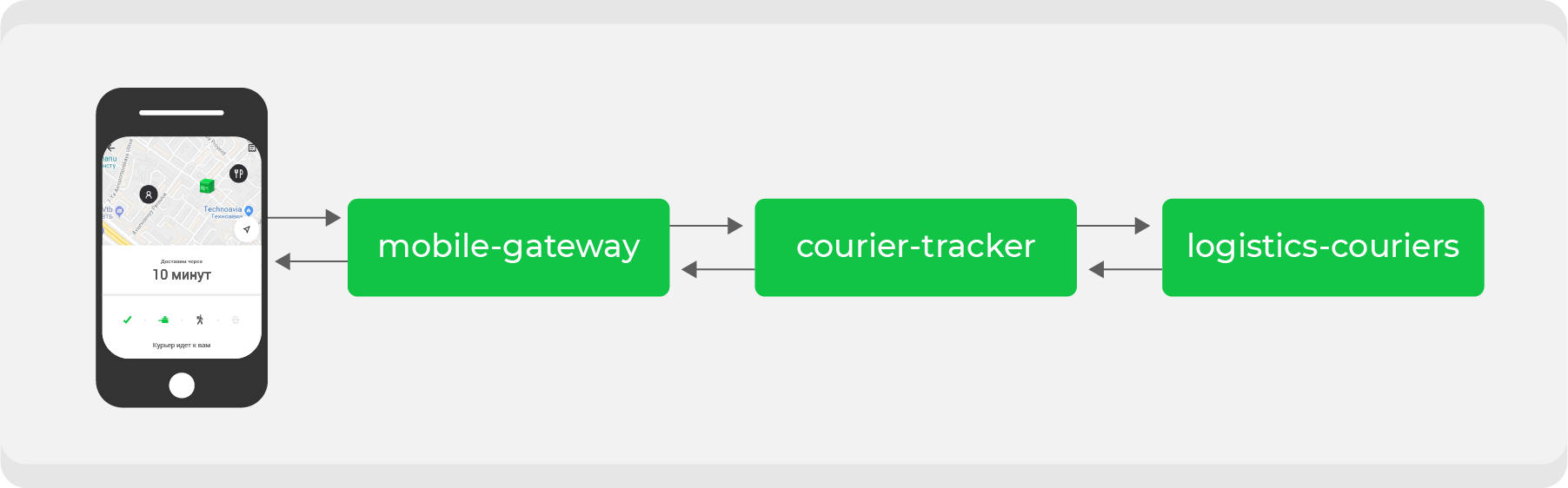
No esquema original, tudo funcionava de forma síncrona: as solicitações do aplicativo móvel, uma vez por minuto, passavam
mobile-gatewaypara o serviço courier-trackerque acessava logistics-courierse recebia as coordenadas. Claro, neste esquema não era tão simples, mas no final tudo se resumia a uma conclusão simples: quanto mais pedidos ativos tivermos, mais solicitações de coordenadas recebidas logistics-couriers.
Nosso crescimento às vezes é imprevisível e, o mais importante, rápido - uma questão de tempo antes que tal esquema falhe. Isso significa que precisamos refazer o processo de interação assíncrona: tornar a solicitação de coordenadas o mais barata possível. Para fazer isso, precisamos transformar nossos fluxos de dados.
Transporte
Já utilizamos RabbitMQ, inclusive para comunicação entre serviços. Mas como principal meio de transporte, optamos pela ferramenta já comprovada - Apache Kafka. Escreveremos um artigo detalhado separado sobre isso, mas agora gostaria de falar brevemente sobre como o usamos.
Quando começamos a implementar o Kafka como um transporte, o usamos em sua forma bruta, conectando-nos diretamente aos corretores e enviando mensagens a eles. Essa abordagem nos permitiu testar Kafka rapidamente em combate e decidir se continuaríamos a usá-lo como nosso principal meio de transporte.
Mas essa abordagem tem uma desvantagem significativa: as mensagens não têm nenhuma digitação e validação - não sabemos ao certo qual formato de mensagem lemos no tópico.
Isso aumenta o risco de erros e inconsistências entre os serviços que fornecem os dados e aqueles que os consomem.
Para resolver esse problema, escrevemos um wrapper - um microsserviço em Go, que esconde o Kafka por trás de sua API. Isso acrescentou dois benefícios:
- validação de dados no momento do envio e recebimento. Na verdade, esses são os mesmos DTOs, portanto, sempre estamos confiantes no formato dos dados esperados.
- integração rápida de nossos serviços com este transporte.
Portanto, trabalhar com o Kafka se tornou o mais abstrato possível para nossos serviços: eles só funcionam com a API de nível superior deste wrapper.
Vamos voltar ao exemplo
Ao transferir a comunicação síncrona para o barramento de eventos, precisamos inverter o fluxo de dados: o que pedimos agora deve chegar até nós através do próprio Kafka. No exemplo, estamos falando das coordenadas do correio, para o qual iremos agora criar um tópico especial e os produziremos à medida que os recebermos dos correios pelo serviço
logistics-couriers.
O serviço
courier-trackersó tem que acumular coordenadas na quantidade necessária e pelo período exigido. Como resultado, nosso endpoint se torna o mais simples possível: pegue os dados do banco de dados do serviço e os entregue a um aplicativo móvel. O aumento da carga agora é seguro para nós.
Além de resolver um problema específico, no final obtemos um tópico de dados com as coordenadas reais dos transportadores, que qualquer um dos nossos serviços pode utilizar para os seus próprios fins.
Eventualmente consistência
Neste exemplo, tudo funciona bem, exceto que as coordenadas dos couriers nem sempre estarão atualizadas em comparação com a opção síncrona: em uma arquitetura construída sobre interação assíncrona, surge a questão sobre a relevância dos dados em um determinado momento. Mas não temos muitos dados críticos que precisamos manter sempre atualizados, então esse esquema é ideal para nós: sacrificamos a relevância de algumas informações para aumentar o nível de disponibilidade do sistema. Mas garantimos que, em última instância, em todas as partes do sistema, todos os dados serão relevantes e consistentes (eventualmente consistência).
Essa desnormalização de dados é necessária quando se trata de um sistema de alta carga e arquitetura de microsserviço: cada serviço em si garante o armazenamento dos dados de que precisa para funcionar. Por exemplo, uma das principais entidades do nosso domínio é o correio. Muitos serviços operam com ele, mas todos precisam de um conjunto diferente de dados: alguém precisa de dados pessoais e alguém precisa apenas de informações sobre o tipo de movimento. O mestre de dados deste domínio produzirá toda a entidade no fluxo e os serviços acumulam as partes necessárias:
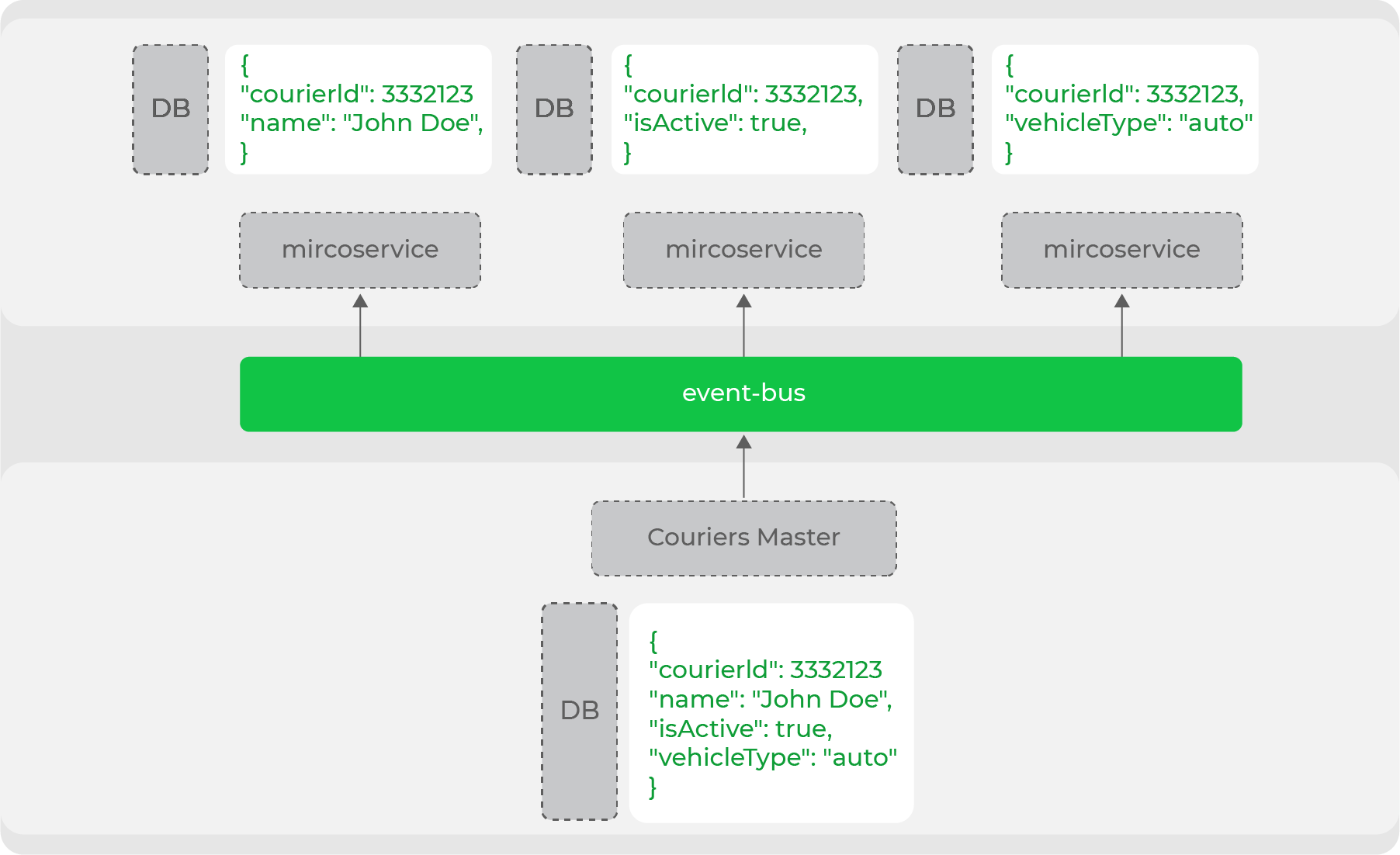
Assim, dividimos claramente nossos serviços entre aqueles que são mestres de dados e aqueles que usam esses dados. Na verdade, este é o comércio sem cabeça da arquitetura evolucionária - separamos claramente todas as "vitrines" (site, aplicativos móveis) dos produtores desses dados.
Desnormalização
Outro exemplo: temos um mecanismo para notificações direcionadas aos mensageiros - são as mensagens que chegarão a eles no aplicativo. No lado do back-end, há uma API poderosa para enviar essas notificações. Nele, você pode configurar filtros de mailing: de um mensageiro específico a grupos de mensageiros de acordo com determinados critérios.
O serviço é responsável por essas notificações
logistics-courier-notifications. Depois de receber um pedido de envio, sua tarefa é gerar mensagens para os mensageiros que foram visados. Para fazer isso, ele precisa saber as informações necessárias sobre todos os mensageiros do Delivery Club. E temos duas opções para resolver esse problema:
- fazer um endpoint no lado do serviço - o assistente de dados do correio (
logistics-couriers), que poderá filtrar e devolver os correios necessários pelos campos transmitidos; - armazenar todas as informações necessárias diretamente no serviço, consumindo-as do tópico correspondente e salvando os dados pelos quais precisaremos filtrar no futuro.
Parte da lógica para geração de mensagens e filtragem de correios não é carregada, é executada em segundo plano, portanto, não há dúvida de cargas de serviço
logistics-couriers. Mas se escolhermos a primeira opção, nos deparamos com um conjunto de problemas:
- você terá que oferecer suporte a um endpoint altamente especializado em um serviço de terceiros, o que, muito provavelmente, só nós precisaremos;
- Se você selecionar um filtro muito largo, todos os mensageiros que simplesmente não se encaixam na resposta HTTP serão incluídos na amostra e você terá que implementar a paginação (e iterar sobre ela ao pesquisar o serviço).
Obviamente, paramos de armazenar dados no próprio serviço. Realiza todo o trabalho de forma autônoma e isolada, não acessando de lugar nenhum, mas apenas acumulando todos os dados necessários de si mesmo do tópico Kafka. Existe o risco de recebermos posteriormente uma mensagem sobre a criação de um novo correio, que não será incluído em alguma seleção. Mas essa desvantagem de uma arquitetura assíncrona é inevitável.
Como resultado, formulamos vários princípios importantes para a concepção de serviços:
- O serviço deve ter uma responsabilidade específica. Se um serviço ainda for necessário para seu funcionamento completo, isso é um erro de design, eles devem ser combinados ou a arquitetura deve ser revisada.
- Analisamos criticamente todas as chamadas síncronas. Para serviços em uma direção, isso é aceitável, mas para comunicação entre serviços em direções diferentes - não
- Não compartilhe nada. Não vamos ao banco de dados de serviços ignorando-os. Todas as solicitações apenas por meio da API.
- Especificação primeiro. Primeiro, descrevemos e aprovamos os protocolos.
Assim, ao transformar iterativamente nosso sistema de acordo com os princípios e abordagens aceitos, chegamos à seguinte arquitetura:
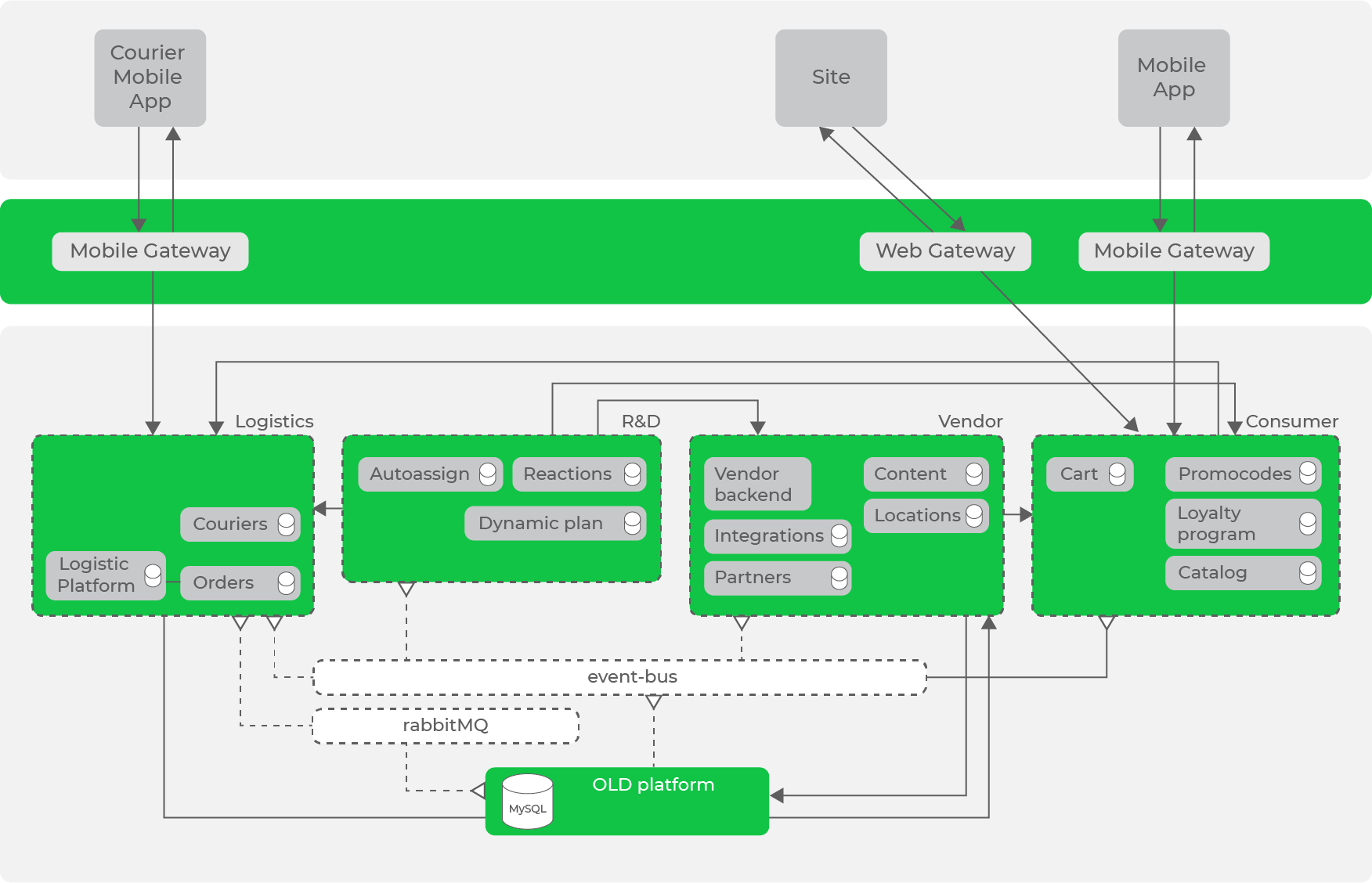
Já temos um barramento de dados na forma de Kafka, que já tem um número significativo de fluxos de dados, mas ainda existem solicitações síncronas entre as direções.
Como planejamos desenvolver nossa arquitetura
O Delivery Club, como eu disse no início, está crescendo rapidamente, estamos lançando um grande número de novos recursos em produção. E experimentamos ainda mais ( Nikolay Arkhipov falou sobre isso em detalhes ) e testamos hipóteses. Tudo isso dá origem a um grande número de fontes de dados e ainda mais opções para seu uso. E a gestão correta dos fluxos de dados, que é muito importante construir corretamente - esta é a nossa tarefa.
De agora em diante, continuaremos a implementar as abordagens desenvolvidas para todos os serviços do Delivery Club: construir ecossistemas de serviços em torno de uma plataforma com transporte na forma de um barramento de dados.
A tarefa principal é garantir que as informações sobre todos os domínios do sistema sejam fornecidas ao barramento de dados. Para novos serviços com novos dados, isso não é um problema: na fase de preparação do serviço, ele será obrigado a transmitir seus dados de domínio para Kafka.
Mas além dos novos, temos grandes serviços legados com dados em nossos principais domínios: pedidos e correios. É problemático transmitir esses dados “como estão”, pois eles são armazenados em dezenas de tabelas e será muito caro construir a entidade final para produzir todas as alterações a cada vez.
Portanto, para serviços antigos, decidimos usar Debezium, que permite transmitir informações diretamente de tabelas com base em bin-log: como resultado, você obtém um tópico pronto com dados brutos da tabela. Mas eles são inadequados para uso em sua forma original, portanto, por meio dos transformadores no nível Kafka, eles serão convertidos em um formato compreensível para os consumidores e empurrados para um novo tópico. Assim, teremos um conjunto de tópicos privados com dados brutos de tabelas, que serão transformados em um formato conveniente e transmitidos para um tópico público para uso dos consumidores.
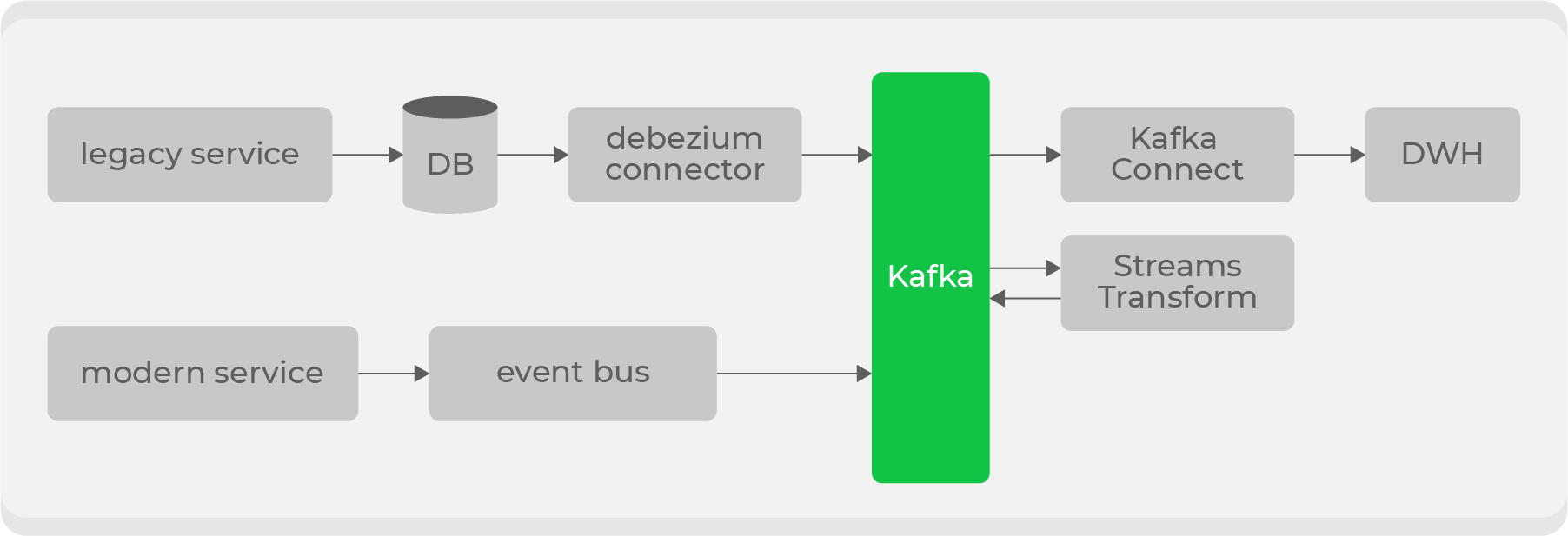
Haverá vários pontos de entrada para escrever no Kafka e diferentes tipos de tópicos, portanto, ainda implementaremos direitos de acesso por função no lado do armazenamento e adicionaremos validação de esquema no lado do barramento de dados via Confluent .
Além do barramento de dados, os serviços consumirão dados dos tópicos necessários. E nós mesmos usaremos esses dados em nossos sistemas: por exemplo, transmitir por meio do Kafka Connect to ElasticSearch ou DWH. Com este último, o processo será mais complicado: para que a informação nele contida seja acessível a todos, deve ser apagada de todos os dados pessoais.
Também precisamos finalmente resolver o problema com o monólito: ainda há processos críticos que enfrentaremos em um futuro próximo. Mais recentemente, já implementamos um serviço separado que trata da primeira etapa da criação de um pedido: formação de uma cesta, recebimento e pagamento. Em seguida, ele envia esses dados ao monólito para processamento posterior. Bem, todas as outras operações não requerem mais sincronização.
Como fazer essa refatoração de forma transparente para os clientes
Vou te contar mais um exemplo: um catálogo de restaurante. Obviamente, este é um lugar muito movimentado e decidimos mudá-lo para um serviço separado no Go. Para acelerar o desenvolvimento, dividimos o takeaway em dois estágios:
- Primeiro, dentro do serviço, vamos diretamente para uma réplica da base do nosso monólito e obtemos dados de lá.
- Em seguida, começamos a transmitir os dados de que precisamos por meio do Debezium e os acumulamos no banco de dados do próprio serviço.
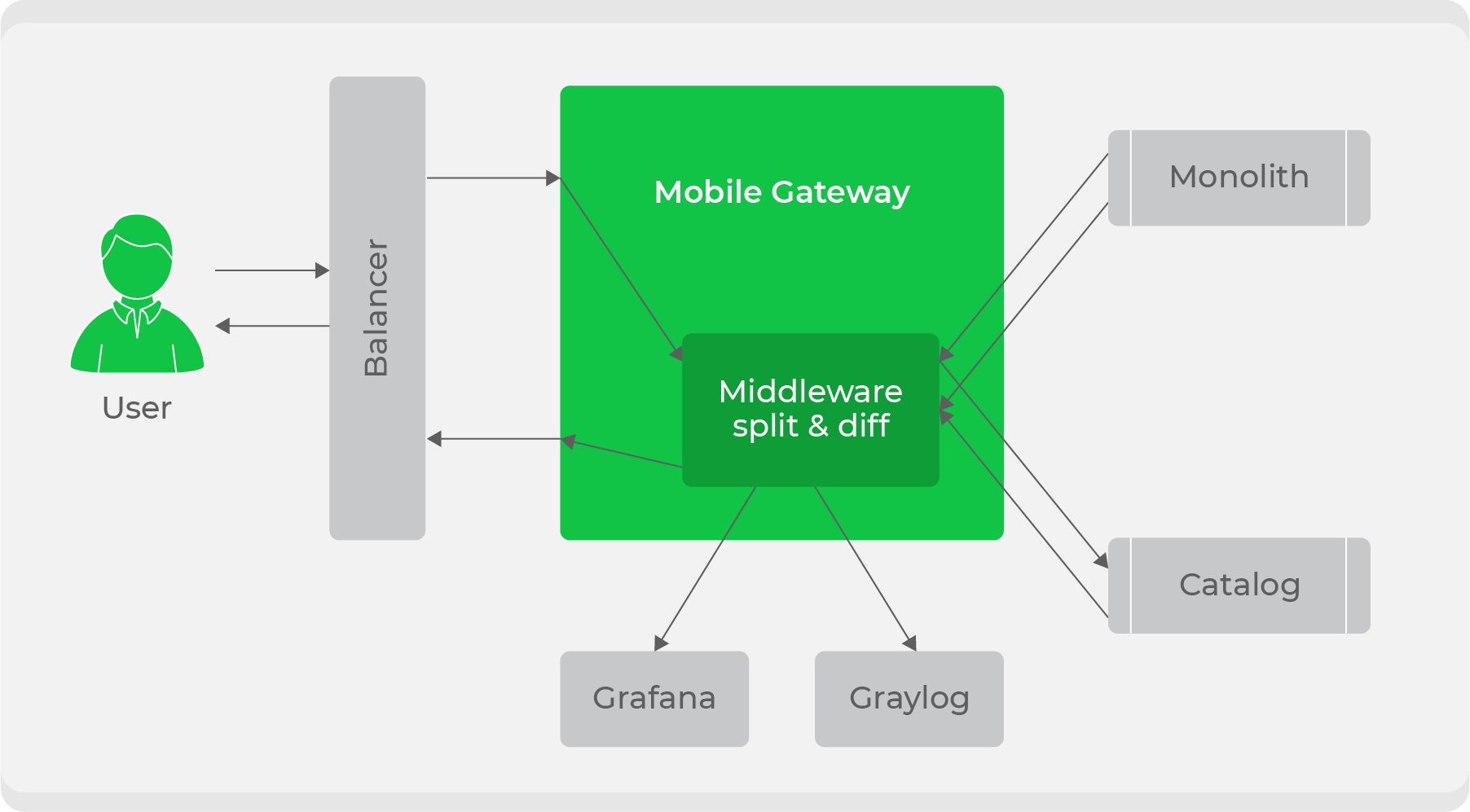
Quando o serviço está pronto, surge a questão de como integrá-lo de forma transparente ao fluxo de trabalho atual. Usamos um esquema de divisão de tráfego: todo o tráfego dos clientes foi para o serviço
mobile-gatewaye, em seguida, foi dividido entre o monólito e o novo serviço. Inicialmente, continuamos a processar todo o tráfego por meio do monólito, mas duplicamos alguns deles em um novo serviço, comparamos suas respostas e anotamos logs sobre discrepâncias em nossas métricas. Com isso, garantimos a transparência dos testes do serviço em condições de combate. Depois disso, só faltou mudar gradualmente e aumentar o tráfego nele até que o novo serviço substituísse completamente o monólito.
Em geral, temos muitos planos e ideias ambiciosos. Estamos apenas no início do desenvolvimento de nossa estratégia futura, enquanto sua forma final não está clara e não se sabe se tudo funcionará como esperamos. Assim que implementarmos e tirarmos conclusões, definitivamente compartilharemos os resultados.
Junto com todas essas mudanças conceituais, continuamos a desenvolver ativamente e fornecer recursos para o produto, o que leva a maior parte do tempo. Aqui chegamos ao segundo problema, do qual falei no início: levando em consideração o número de desenvolvedores (180 pessoas), surge a questão da validação da arquitetura e da qualidade dos novos serviços. O novo não deve degradar o sistema, deve ser integrado corretamente desde o início. Mas como controlar isso em escala industrial?
Comitê de Arquitetura
A necessidade disso não surgiu imediatamente. Quando a equipe de desenvolvimento era pequena, qualquer mudança no sistema era fácil de controlar. Mas quanto mais gente houver, mais difícil será fazer isso.
Isso dá origem tanto a problemas reais (o serviço não suportava a carga devido a um projeto inadequado) quanto a conceituais (“vamos caminhar sincronicamente aqui, a carga é pequena”).
É claro que a maioria dos problemas é resolvida no nível da equipe. Mas se estivermos falando sobre algum tipo de integração complexa no sistema atual, então a equipe pode simplesmente não ter experiência suficiente. Portanto, eu queria criar algum tipo de associação de pessoas de todas as direções, para a qual alguém pudesse fazer qualquer pergunta sobre arquitetura e obter uma resposta exaustiva.
Assim, chegamos à criação de um comitê de arquitetura, que inclui líderes de equipe, líderes de direção e CTOs. Nos reunimos a cada duas semanas para discutir as principais mudanças planejadas no sistema ou apenas resolver problemas específicos.
Como resultado, fechamos o problema de controlar grandes mudanças, a questão da abordagem geral para a qualidade do código no Delivery Club permanece: problemas específicos do código ou estrutura em diferentes equipes podem ser resolvidos de diferentes maneiras. Chegamos às guildas no modelo Spotify: são uniões de pessoas que não são indiferentes a alguma tecnologia. Por exemplo, existem guildas Go, PHP e Frontend.
Eles desenvolvem estilos de programação uniformes, abordagens de design e arquitetura, ajudam a formar e manter uma cultura de engenhariano nível mais alto. Eles também têm seu próprio backlog, no qual eles aprimoram as ferramentas internas, por exemplo, nosso modelo Go para microsserviços.
Código do produto
Além de grandes mudanças passarem pelo comitê de arquitetura e as guildas monitorarem a cultura do código em geral, ainda temos uma etapa importante na preparação do serviço para produção: a elaboração de um checklist no Confluence. Primeiro, ao elaborar uma lista de verificação, o desenvolvedor avalia novamente sua decisão; em segundo lugar, este é um requisito operacional, pois eles precisam entender que tipo de novo serviço aparece na produção.
A lista de verificação geralmente indica:
- responsável pelo serviço (normalmente é o responsável técnico do serviço);
- links para o painel com alertas personalizados;
- descrição do serviço e link para Swagger;
- uma descrição dos serviços com os quais irá interagir;
- carga estimada no serviço;
- health-check. URL, . Health-check - : 200, , - . , health check URL’ , , , PostgreSQL Redis.
Os alertas de serviço são projetados no estágio de aprovação arquitetônica. É importante que o desenvolvedor entenda que o serviço está ativo e leva em consideração não apenas as métricas técnicas, mas também as do produto. Isso não significa nenhuma conversão de negócios, mas métricas que mostram que o serviço está funcionando como deveria.
Por exemplo, você pode pegar o serviço já discutido acima
courier-tracker, que rastreia mensageiros no mapa. Uma das principais métricas é o número de mensageiros cujas coordenadas são atualizadas. Se de repente algumas rotas não forem atualizadas por um longo tempo, um alerta “algo deu errado” vem. Talvez em algum lugar onde eles não procuraram os dados, ou entraram no banco de dados incorretamente, ou algum outro serviço caiu. Esta não é uma métrica técnica ou de produto, mas mostra a viabilidade do serviço.
Para métricas, usamos Graylog e Prometheus, construímos painéis e configuramos alertas no Grafana.
Apesar do volume de preparação, a entrega dos serviços à produção é bastante rápida: todos os serviços são inicialmente empacotados no Docker, são lançados no palco automaticamente depois que o gráfico digitado para Kubernetes é formado, e então tudo é decidido por um botão no Jenkins.
O lançamento de um novo serviço para prod consiste em atribuir uma tarefa aos administradores em Jira, que fornece todas as informações que preparamos anteriormente.
Sob o capô
Agora temos 162 microsserviços escritos em PHP e Go. Eles foram distribuídos entre os serviços cerca de 50% a 50%. Inicialmente, reescrevemos alguns serviços de alta carga em Go. Então ficou claro que Go é mais fácil de manter e monitorar na produção, ele tem um limite de entrada baixo, então recentemente temos escrito serviços apenas nele. Não há propósito em reescrever os serviços PHP restantes no Go: ele lida com suas funções com bastante sucesso.
Em serviços PHP, temos Symfony, além do qual usamos nosso próprio pequeno framework. Ele impõe uma arquitetura comum aos serviços, graças à qual diminuímos o limite para inserir o código-fonte dos serviços: não importa qual serviço você abra, sempre será claro o que está nele e onde. E a estrutura também encapsula a camada de transporte de comunicação entre os serviços, para o desenvolvedor, uma solicitação a um serviço de terceiros tem um alto nível de abstração:
Aqui formamos o DTO do request ($courierResponse = $this->courierProtocol->get($courierRequest);
$courierRequest), chamamos o método do objeto de protocolo de um serviço específico, que é um wrapper sobre um ponto de extremidade específico. Sob o capô, nosso objeto é $courierRequestconvertido em um objeto de solicitação, que é preenchido com campos do DTO. Tudo isso é flexível: os campos podem ser inseridos tanto nos cabeçalhos quanto na própria URL de solicitação. Em seguida, a solicitação é enviada por meio de cURL, obtemos o objeto Response e o transformamos de volta no objeto que esperamos $courierResponse.
Isso permite que os desenvolvedores se concentrem na lógica de negócios, sem detalhes de interação em um nível inferior. Objetos de protocolos, solicitações e respostas de serviços estão em um repositório separado - o SDK deste serviço. Graças a isso, qualquer serviço que deseje utilizar seus protocolos receberá todo o pacote de protocolos digitado após a importação do SDK.
Mas esse processo tem uma grande desvantagem: repositórios com o SDK são difíceis de manter, porque todos os DTOs são escritos manualmente, e a geração de código conveniente não é fácil: houve tentativas, mas no final, dada a transição para Go, eles não investiram tempo nisso.
Como resultado, as mudanças no protocolo de serviço podem se transformar em várias solicitações pull: no próprio serviço, em seu SDK e em um serviço que precisa desse protocolo. Neste último, precisamos aumentar a versão do SDK importado para que as alterações cheguem lá. Isso geralmente levanta dúvidas de novos desenvolvedores: "Acabei de alterar o parâmetro, por que preciso fazer três solicitações para três repositórios diferentes?!"
Em Go, tudo é muito mais simples: temos um excelente gerador de código (Sergey Popov escreveu um artigo detalhado sobre isso), graças ao qual todo o protocolo é digitado, e agora até a opção de armazenar todas as especificações em um repositório separado está sendo discutida. Assim, se alguém alterar a especificação, todos os serviços que dependem dela começarão imediatamente a usar a versão atualizada.
Radar técnico
Além do Go e PHP já mencionados, usamos um grande número de outras tecnologias. Eles variam de direção para direção e dependem de tarefas específicas. Basicamente, no back-end, usamos:
Python, no qual a equipe de Data Science escreve.KotlineSwift- para o desenvolvimento de aplicativos móveis.PostgreSQLcomo um banco de dados, mas alguns serviços mais antigos ainda executam o MySQL. Em microsserviços, usamos várias abordagens: cada serviço tem seu próprio banco de dados e não compartilha nada - não vamos para bancos de dados ignorando serviços, apenas por meio de sua API.ClickHouse- para serviços altamente especializados relacionados a análises.RediseMemcachedcomo armazenamento na memória.
Ao escolher uma tecnologia, somos guiados por princípios especiais . Um dos principais requisitos é a facilidade de uso: utilizamos a tecnologia mais simples e compreensível para o desenvolvedor, aderindo ao stack aceito sempre que possível. Para quem deseja conhecer toda a pilha de tecnologias específicas, compilamos um radar técnico muito detalhado .
Longa história curta
Como resultado, mudamos de uma arquitetura monolítica para uma de microsserviço e agora já temos grupos de serviços unidos por direções (áreas de domínio) em torno da plataforma, que é o núcleo e o mestre de dados.
Temos uma visão de como reorganizar nossos fluxos de dados e como fazer isso sem afetar a velocidade de desenvolvimento de novos recursos. No futuro, com certeza contaremos aonde isso nos levou.
E graças à transferência ativa de conhecimento e um processo formalizado de fazer mudanças, somos capazes de entregar um grande número de recursos que não atrasam o processo de transformação de nossa arquitetura.
Isso é tudo para mim, obrigado pela leitura!