No Surf, escrevemos nosso próprio intérprete e o usamos no cliente do aplicativo móvel - embora inicialmente, ao que parece, isso geralmente tenha pouco a ver com o desenvolvimento móvel. Na verdade, intérpretes e compiladores são ferramentas para resolver problemas que podem ser encontrados em qualquer lugar. Portanto, compreender como funciona e ser capaz de escrever o seu é útil.
Hoje, usando o exemplo da tradução de máscaras de um formato para outro, vamos nos familiarizar com os fundamentos da construção de intérpretes e ver como usar gramáticas formais, uma árvore de sintaxe abstrata, regras de tradução - inclusive para resolver problemas de negócios.

Um pouco sobre as máscaras: o que são e por que você precisa delas
. , , - — , . -: , , .
, . , . , API - , : 9161234567 — 8, .
, , :
, , . , , , — . ? — .
— , . , .
, :

, , : . .
, . , . , API - , : 9161234567 — 8, .
, , :
- , , .
- : , , , .
- , .
, , . , , , — . ? — .
— , . , .
, :
- . , , .
- « »: -, .
- .
, , : . .
— UX-
Por que você não pode simplesmente pegar e descrever a máscara
As máscaras são legais e confortáveis. Mas há um problema que é inevitável em certas condições: quando o cliente tem um formato de máscara e o servidor tem muitos provedores de dados diferentes e cada um tem seu próprio formato. Não podemos contar com o fato de ter o mesmo formato. Perguntar ao servidor: "Coloque as máscaras para nós como quisermos" - também. Você precisa ser capaz de viver com isso.
O problema surge: há uma especificação de back-end, você precisa escrever um front-end - um aplicativo móvel. Você pode escrever manualmente todas as máscaras para o aplicativo - e esta é uma boa opção quando há apenas um provedor e há poucas máscaras. O programador, é claro, terá que gastar tempo para entender pelo menos duas especificações para máscaras: o back-end e a frente. Em seguida, ele precisa traduzir máscaras de back-end específicas em máscaras de front-end correspondentes. Isso também leva tempo, há um fator humano - você pode estar errado. Não é um trabalho fácil, a tradução é difícil: algumas linguagens de máscara são escritas principalmente para computadores, não para humanos.
Se repentinamente a máscara no servidor mudar ou uma nova aparecer, então o aplicativo, em primeiro lugar, pode parar de funcionar. Em segundo lugar, o árduo trabalho de tradução precisa ser feito novamente, um novo aplicativo deve ser lançado, isso leva tempo, esforço e dinheiro. Surge a pergunta: como minimizar o trabalho do programador? Parece que tudo isso deveria ser feito por uma máquina, mas por algum motivo uma pessoa está fazendo isso.
A resposta é sim, temos uma solução. As máscaras são escritas na linguagem dos computadores - e esse é um dos motivos pelos quais é difícil para uma pessoa trabalhar com ela e traduzir de um idioma para outro. Precisamos transferir esse trabalho para o computador. Uma vez que a máscara parece ser uma gramática formal , a maneira mais segura de traduzir uma gramática em outra é:
- entender as regras para construir a gramática original,
- entender as regras para construir a gramática alvo,
- escrever regras de tradução da gramática de origem para o destino,
- implementar tudo isso no código.
É para isso que os compiladores e tradutores são escritos.
Agora, vamos examinar mais de perto nossa solução baseada em gramáticas formais.
fundo
Em nosso aplicativo, existem algumas telas diferentes que são formadas de acordo com o princípio do backend: uma descrição completa da tela, junto com os dados, vem do servidor.

A maioria das telas contém uma variedade de formulários de entrada. O servidor determina quais campos estão no formulário e como eles devem ser formatados. Máscaras também são usadas para descrever esses requisitos.
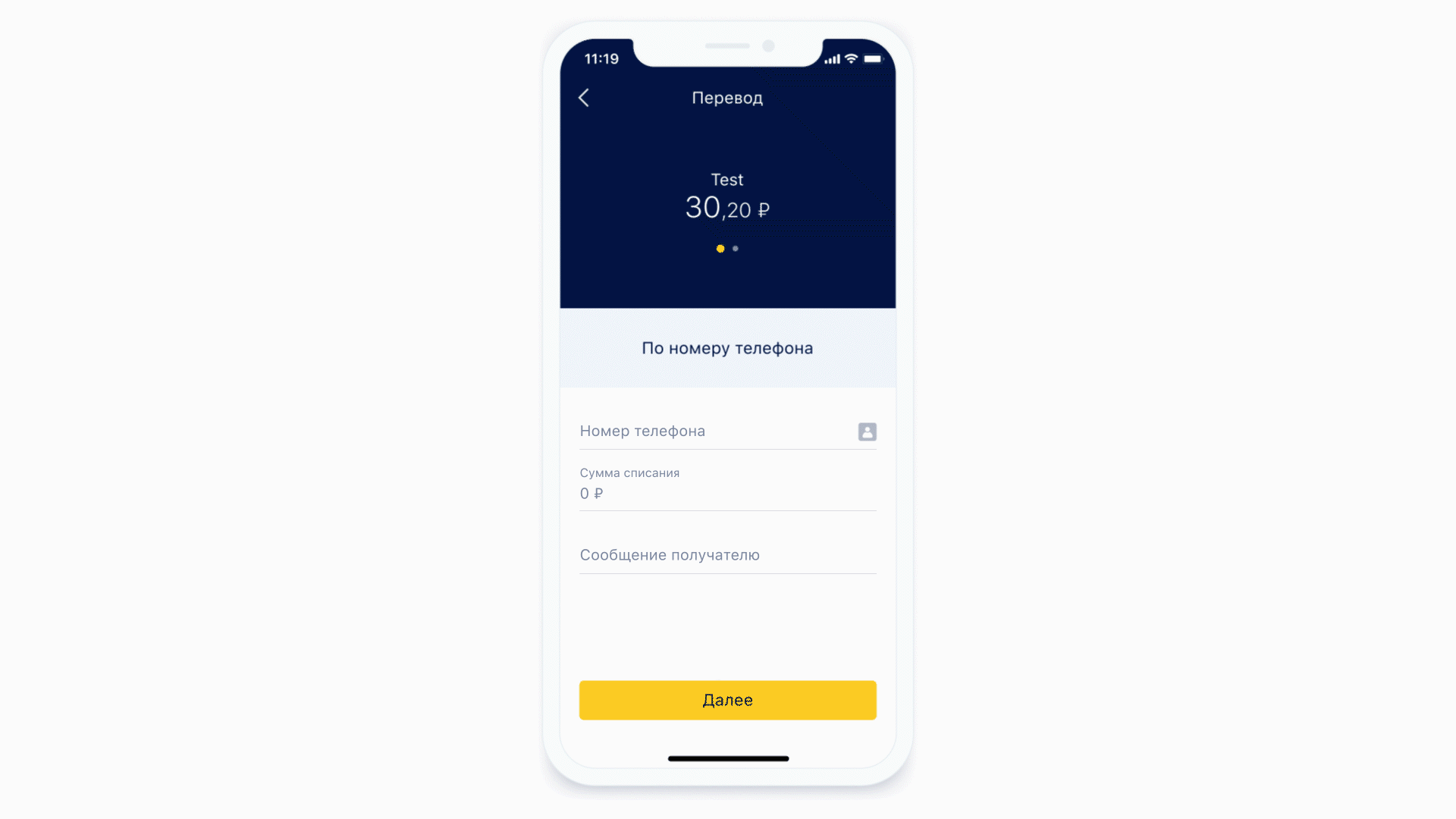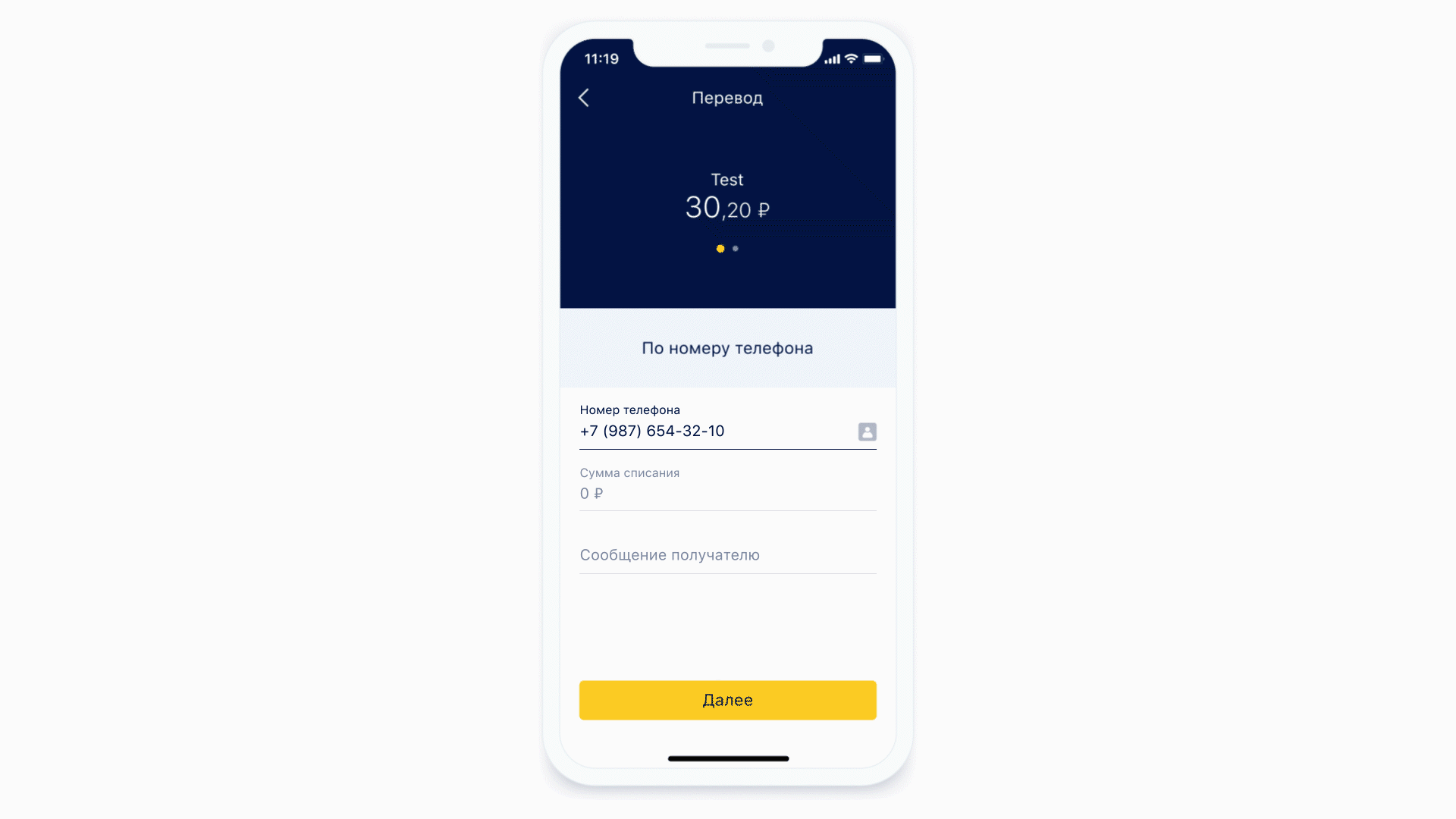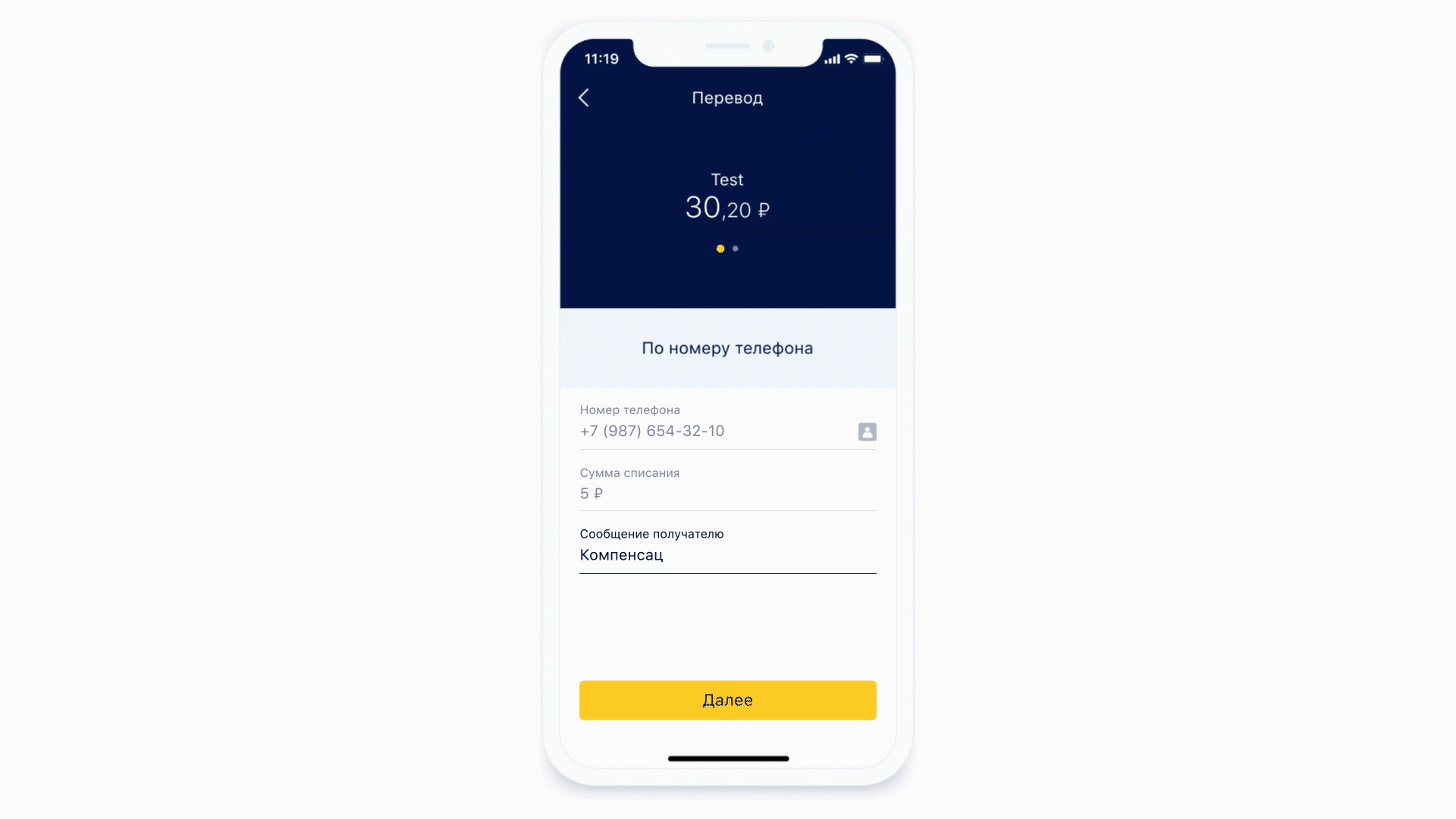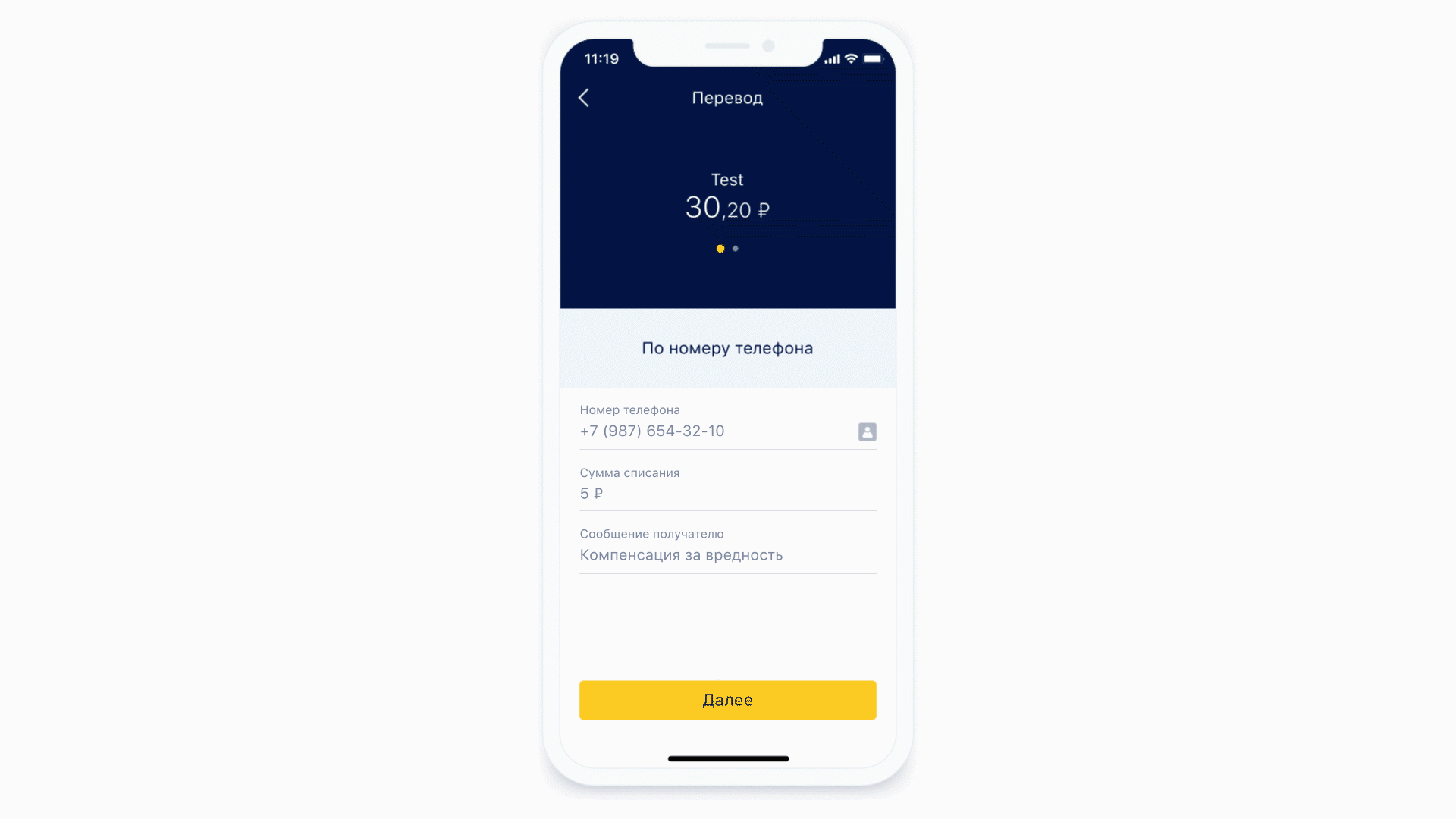
Vamos ver como as máscaras funcionam.
Exemplos de máscaras em diferentes formatos
Como primeiro exemplo, vamos usar a mesma forma de inserir um número de telefone. A máscara para esse formato pode ter esta aparência.

Por outro lado, a própria máscara adiciona delimitadores, parênteses e proíbe a inserção de caracteres incorretos. Por outro lado, a mesma máscara extrai informações úteis da entrada formatada para enviar ao servidor.
A parte chamada constante é destacada em vermelho. Estes são símbolos que aparecerão automaticamente - o usuário não deve inseri-los:

Em seguida, vem a parte dinâmica - ela está sempre entre colchetes angulares:

Mais adiante no texto, chamarei esta expressão de "expressão dinâmica" - ou DW para abreviar
Aqui está a expressão pela qual iremos formatar nossa entrada: As

peças que são responsáveis pelo conteúdo da parte dinâmica são destacadas em vermelho.
\\ d - qualquer dígito.
+ - repetidor regular: repita pelo menos uma vez.
$ {3} é um símbolo de meta informação que especifica o número de repetições. Nesse caso, deve haver três caracteres.
Então, a expressão \\ d + $ {3} significa que deve haver três dígitos.
Nesse formato de máscaras, pode haver apenas um repetidor dentro da parte dinâmica:

Essa limitação apareceu por um motivo - agora vou explicar o porquê.
Digamos que temos um DW, em que o tamanho é embutido em código: 4 elementos. E damos a ele 2 elementos com um repetidor: `<! ^ \\ d + \\ v + $ {4}>`. As seguintes combinações se enquadram em um DV:
- 1abc
- 12ab
- 123a
Acontece que tal DV não nos dá uma resposta inequívoca, o que esperar no lugar do segundo caractere: um número ou uma letra.
Pegue a máscara, adicione-a com a entrada do usuário. Obtemos o número de telefone formatado:

no cliente, o formato das máscaras pode ser diferente. Por exemplo, na biblioteca Input Mask do Redmadrobot, a máscara para o número de telefone se

parece com isto: Parece melhor e mais fácil de entender.
Acontece que a máscara para o servidor e a máscara para o cliente são escritas de forma diferente, mas fazem a mesma coisa.

Vamos reformular o problema: como combinar máscaras de diferentes formatos
Precisamos combinar essas máscaras umas com as outras - ou de alguma forma obter a segunda de uma.
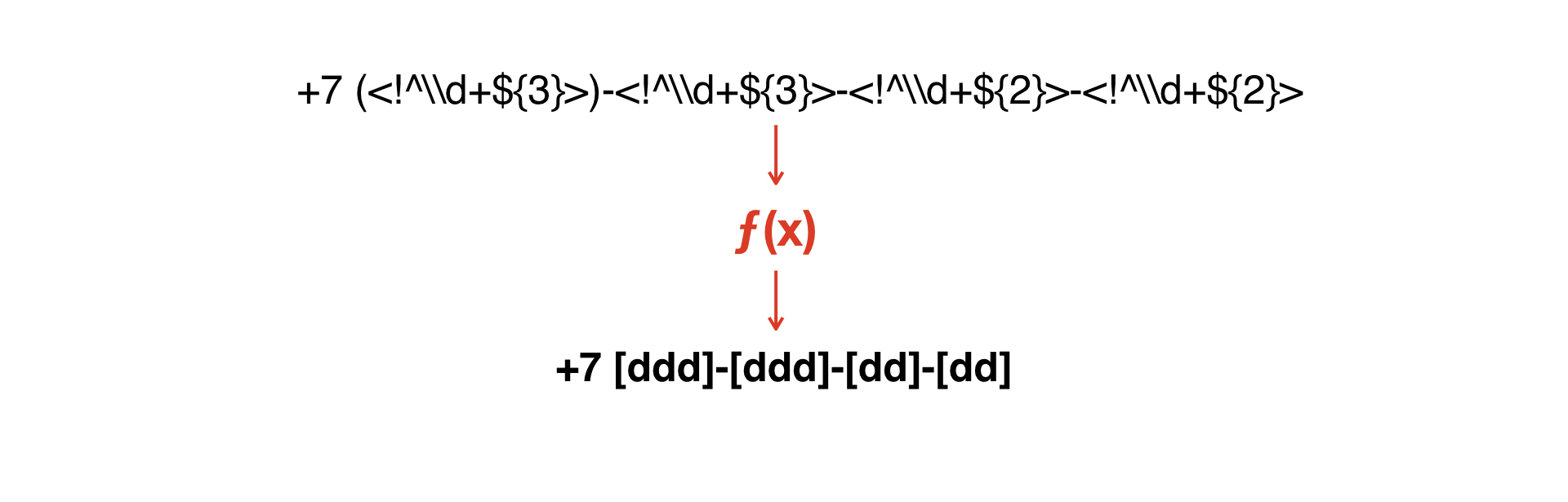
Precisamos construir uma função que converteria uma máscara na segunda.
E aqui surgiu a ideia de escrever um intérprete muito simples que permitisse obter uma segunda gramática de uma gramática.
Já que chegamos ao intérprete, vamos falar sobre gramáticas.
Como a análise é feita
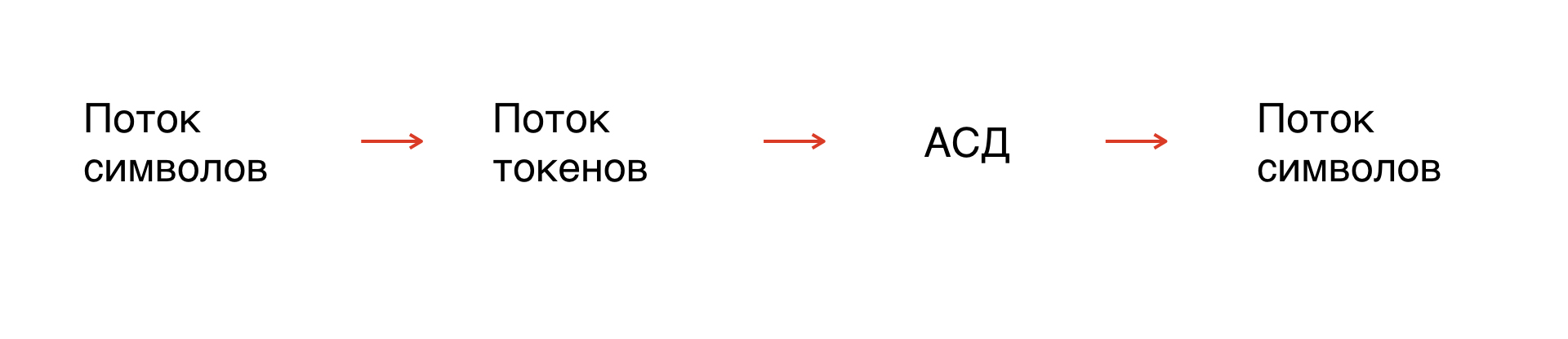
Primeiro, temos um fluxo de personagens - nossa máscara. Na verdade, esta é a string em que operamos. Mas uma vez que os símbolos não são formalizados, você precisa formalizar a string: divida-a em elementos que serão compreensíveis para o interpretador.
Esse processo é chamado de tokenização: um fluxo de símbolos se transforma em um fluxo de tokens. O número de tokens é limitado, eles são formalizados, portanto, podem ser analisados.
Além disso, com base nas regras gramaticais, construímos uma árvore de sintaxe abstrata ao longo do fluxo do token. Da árvore, obtemos um fluxo de símbolos da gramática de que precisamos.
Existe uma expressão. Olhamos para ela e vemos que temos uma constante, sobre a qual falei acima:

Representamos todas as constantes como um token CS, cujo argumento é a própria constante:

O próximo tipo de tokens é o início do DW:

Além disso, todos esses tokens serão interpretados como caracteres especiais. Em nosso exemplo, não há muitos deles, em máscaras reais pode haver muito mais deles.

Então temos um repetidor.
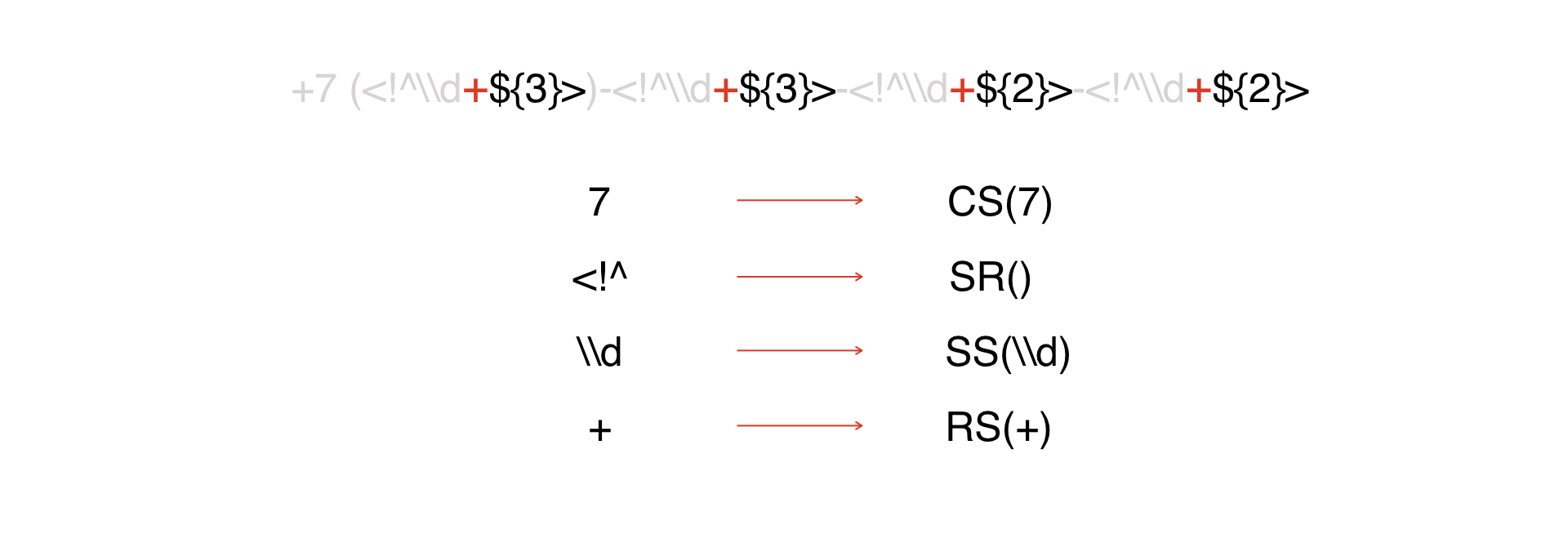
Então - alguns caracteres que são considerados metadados. Iremos trapacear e representá-los como um token, porque é mais fácil dessa maneira.

Fim do Extremo Oriente. Portanto, temos decomposto tudo em tokens.

Um exemplo de tokenização de uma máscara para um número de telefone
Para ver como, em princípio, o processo de tokenização ocorre e como o interpretador funcionará, pegamos uma máscara para um número de telefone e o transformamos em um fluxo de tokens.

Primeiro, o símbolo +. Converta para constante +. Em seguida, fazemos o mesmo para o 7 e para todos os outros símbolos. Recebemos uma série de tokens. Esta não é uma estrutura ainda - analisaremos essa matriz mais detalhadamente.
Lexer e construção ASD
Agora, a parte complicada é o lexer.

À esquerda, uma legenda é descrita - caracteres especiais usados para descrever regras lexicais. À direita estão as próprias regras.
O symbolRule descreve um símbolo. Se esta regra se aplica, se for verdadeira, significa que encontramos um caractere especial ou um caractere constante. Podemos dizer que esta é uma função.
O próximo é repeaterRule. Esta regra descreve uma situação em que um caractere é encontrado, seguido por um token de repetidor.
Então, tudo parece semelhante. Se for LW, então é símbolo ou repetidor. No nosso caso, essa regra é mais ampla. E no final deve haver um token com metadados.
A última regra é maskRule. Esta é uma sequência de símbolos e DV.
Agora vamos construiruma árvore de sintaxe abstrata (AST) de uma matriz de tokens.
Aqui está uma lista de tokens. O primeiro nó da árvore é o raiz, a partir do qual começaremos a construir. Não faz sentido, só precisa de uma raiz.

Temos o primeiro token +, o que significa que apenas adicionamos um nó filho e pronto.

Fazemos o mesmo com todos os outros símbolos constantes, mas então é mais complicado. Encontramos um token DV.

Este não é apenas um site normal - sabemos que deve ter algum tipo de conteúdo.

Um nó de conteúdo é apenas um nó técnico para o qual podemos navegar no futuro. Ele tem seus próprios nós filhos e qual nó terá a seguir? O próximo token em nosso stream é um caractere especial. Será um nó filho?

Na verdade, neste caso, não. Teremos um repetidor como um nó filho.

Por quê? Porque é mais conveniente trabalhar com madeira no futuro. Digamos que queremos analisar esta árvore e construir algum tipo de gramática a partir dela. Ao analisar uma árvore, observamos os tipos de nós. Se tivermos um nó CS, então o analisamos no mesmo nó CS, mas para uma gramática diferente. Por convenção, iteramos no topo da árvore e executamos algum tipo de lógica.
A lógica depende do tipo de nó - ou do tipo de token que está no nó. Para análise, é muito mais conveniente entender imediatamente qual token está na sua frente: composto, como um repetidor, ou simples, como CS. Isso é necessário para que não haja interpretações duplas ou pesquisas constantes de nós filhos.
Isso seria especialmente perceptível em grupos de caracteres: por exemplo, [abcde]. Nesse caso, obviamente, deve haver algum tipo de nó GRUPO pai que terá uma lista de nós filhos CS (a) CS (b), etc.
De volta ao token com metadados. Não está incluído no conteúdo, está na lateral.

Isso é necessário apenas para facilitar o trabalho com a árvore, para que não consideremos o conteúdo desse nó - porque na verdade ele não pertence a ele.
O DV terminou, e não o consideramos uma espécie de nó: era um token que agora pode ser jogado fora. Não vamos transformá-lo em um nó de árvore.
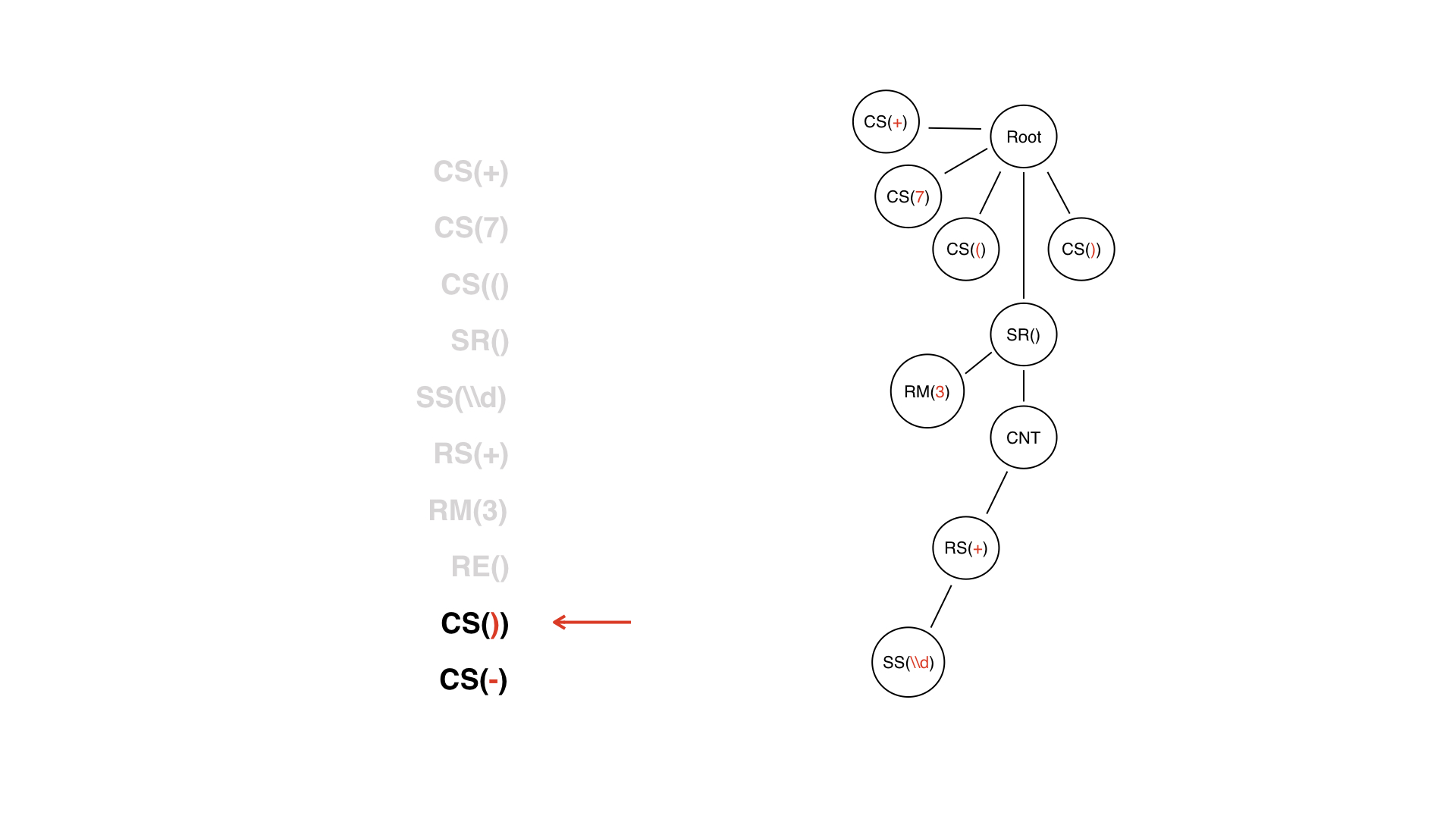
Já temos uma subárvore, a raiz da qual é o nó SR - ou seja, a parte muito dinâmica. O token final LW nos ajuda muito no processo de construção da árvore - podemos entender quando a subárvore para LW está concluída. Mas esse token não tem valor para a lógica: olhando para uma árvore linha por linha, já entendemos quando o DW vai terminar, porque é, por assim dizer, fechado pelo nó SR.
Além disso - apenas símbolos constantes comuns.

Temos uma árvore. Agora vamos percorrer esta árvore em profundidade e construir com base em alguma outra gramática: você precisa ir a um nó, ver que tipo de nó é e gerar um elemento de outra gramática a partir desse nó.
Sintaxe da biblioteca InputMask por Redmadrobot
Vejamos a sintaxe da biblioteca Redmadrobot.

Aqui está a mesma expressão. +7 é uma constante que será adicionada automaticamente. Dentro das chaves, o DV é descrito - a parte dinâmica. Dentro do DV existe um caractere especial d. Redmadrobot tem esta notação padrão que denota um dígito.
Esta é a aparência da notação:

A notação consiste em três partes:
- caractere é o caractere que usaremos para escrever a máscara. Em que consiste o alfabeto da máscara. Por exemplo, d.
- characterSet - quais caracteres digitados pelo usuário são correspondidos por esta notação. Por exemplo, 0, 1, 2, 3, 4 e assim por diante.
- isOptional - se o usuário deve inserir um dos caracteres do characterSet ou não deve inserir nada.
Olha, agora teremos essa máscara.

- O caractere "b" tem uma notação de dígito especial e não é opcional.
- O caractere "c" tem uma notação diferente - CharacterSet é diferente. Também não é opcional.
- E o caractere "C" é o mesmo que "c", mas é opcional. Isso é necessário para que na máscara olhemos os metadados e vejamos que não há um limite rígido, mas fraco.
Se você precisar escrever uma regra quando puder ter de um a dez caracteres, um caractere não será opcional. E nove caracteres serão opcionais. Ou seja, na notação do exemplo, eles serão escritos em maiúsculas. Como resultado, esta regra será semelhante a esta: [cCCCCCCCCC]
Exemplo: traduzir a máscara de número de telefone do formato de back-end para o formato InputMask
Aqui está a árvore que obtivemos na última etapa. Precisamos caminhar sobre isso. A primeira coisa que chegamos é a raiz.

Mais longe da raiz, nos encontramos no símbolo constante + - imediatamente geramos +. À direita, uma máscara é escrita no formato InputMask.

O próximo caractere é compreensível - apenas 7, seguido por um parêntese aberto.
Então, uma parte da parte dinâmica é gerada, mas ainda não está preenchida.

Entramos, temos conteúdo, este é um nó técnico. Não escrevemos nada em lugar nenhum.

Aqui temos um repetidor, também não escrevemos nada em lugar nenhum, porque não existe tal símbolo na máscara. Essa regra não pode ser escrita.

Finalmente, chegamos a algum tipo de símbolo de conteúdo.
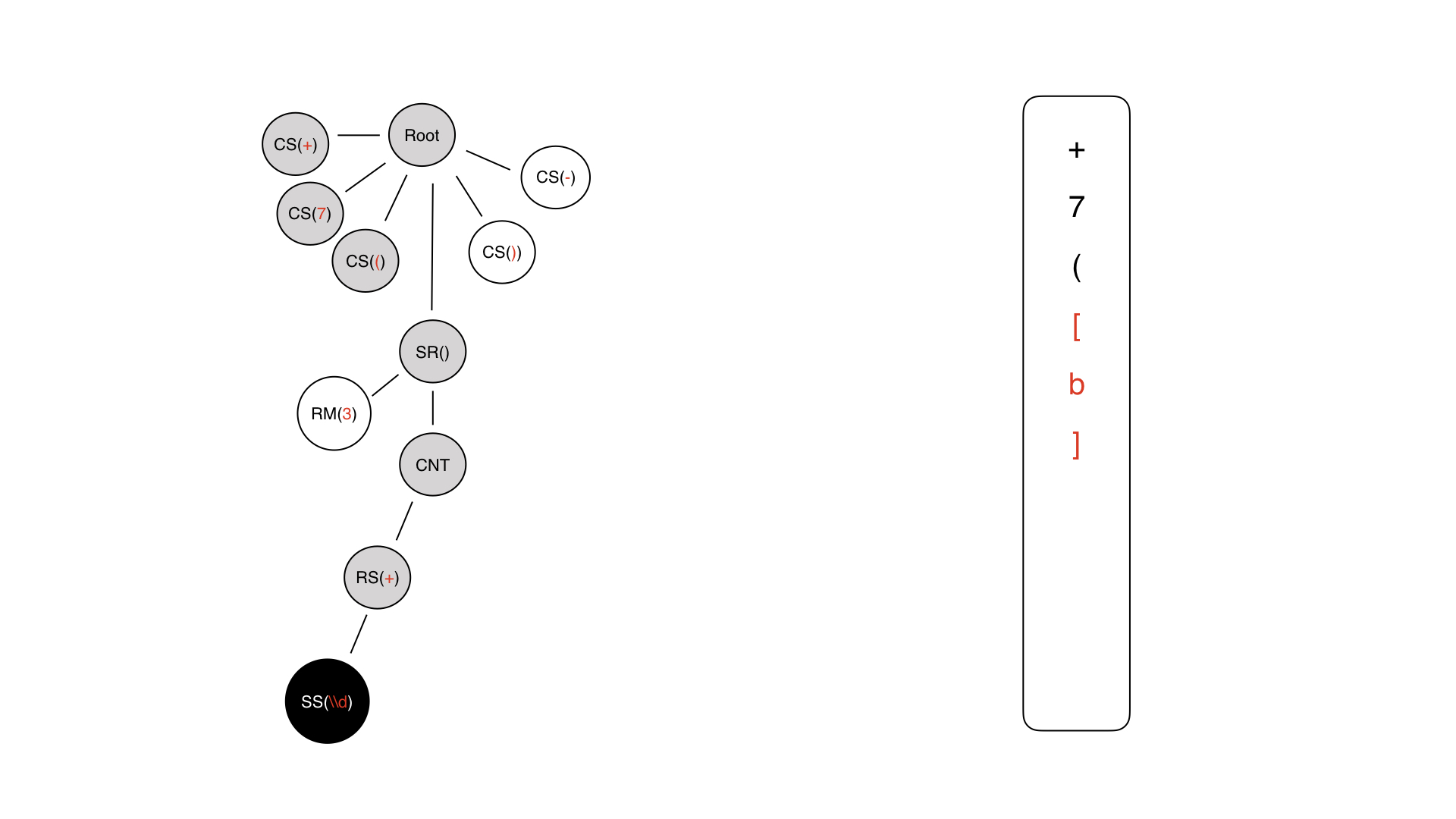
O símbolo de conteúdo pode ser um símbolo constante ou um símbolo especial. Nesse caso, um especial é usado, porque apenas ele carrega algum tipo de carga semântica para entrada.
Então, nós escrevemos, voltamos e vamos apenas para a meta informação.

Vamos ver que temos um repetidor ali e aqui temos 3 - um limite rígido. Portanto, repetimos três vezes e obtemos uma peça tão dinâmica. Em seguida, adicionamos nossos símbolos constantes.

Como resultado, obtemos uma máscara que se parece com uma máscara no formato de robô.
Na prática, pegamos uma gramática e geramos outra gramática a partir dela.
Regras para gerar gramática do lado do cliente a partir do lado do servidor
Agora um pouco sobre as regras de geração. É importante.
Pode haver casos tão difíceis: dentro da parte dinâmica, existem várias peças diferentes de DW. Dentro das chaves: é o mesmo que em DV - um de muitos. Vamos ver como o interpretador vai lidar com essa situação.

Primeiro vem o conjunto de caracteres, e temos que convertê-lo em algum tipo de notação em termos de InputMask. Por quê? Porque este é algum tipo de conjunto limitado de caracteres que precisamos combinar. Precisamos combinar a entrada do usuário e o caractere e, portanto, teremos alguma notação específica escrita aqui.
Em seguida, temos o caractere \\ d.
Além disso - DV com um tamanho opcional.

O primeiro, ao que parece, é algum personagem b. Ele terá um conjunto de caracteres contendo abcd.
Além disso, está claro que já haverá um símbolo diferente, porque você não o corrigirá de maneira diferente ou o corrigirá incorretamente. E então temos essa expressão se transforma em algo assim.
A última parte deve conter pelo menos um símbolo. Vamos designar esse requisito como d. Mas também o usuário pode inserir dois caracteres adicionais, e então eles são designados como DD.
Juntando tudo.

Aqui está um exemplo dos conjuntos de caracteres que são gerados. Pode-se ver que b corresponde ao Conjunto de caracteres abcd, para dígitos - o conjunto de caracteres predefinido correspondente. Para d e D, o conjunto de caracteres correspondente contém 12vf.
Resultado
Aprendemos a converter automaticamente uma gramática em outra: agora as máscaras de acordo com a especificação do servidor funcionam em nosso aplicativo.
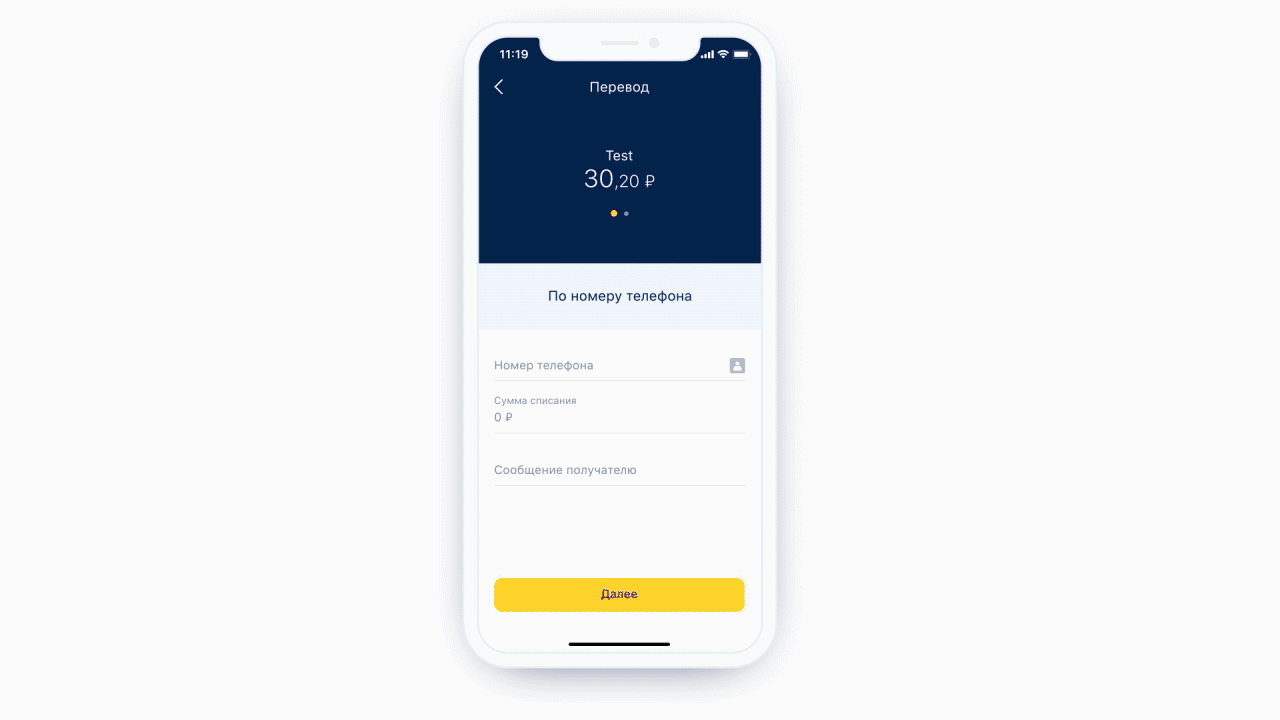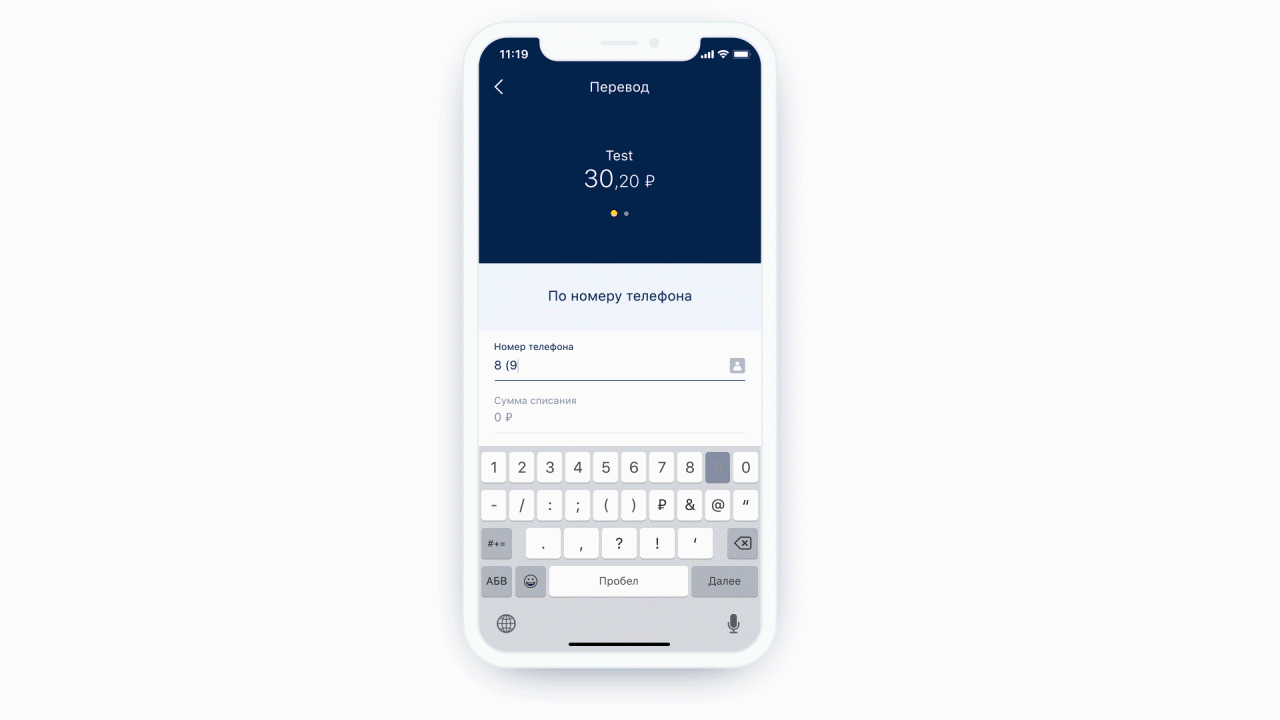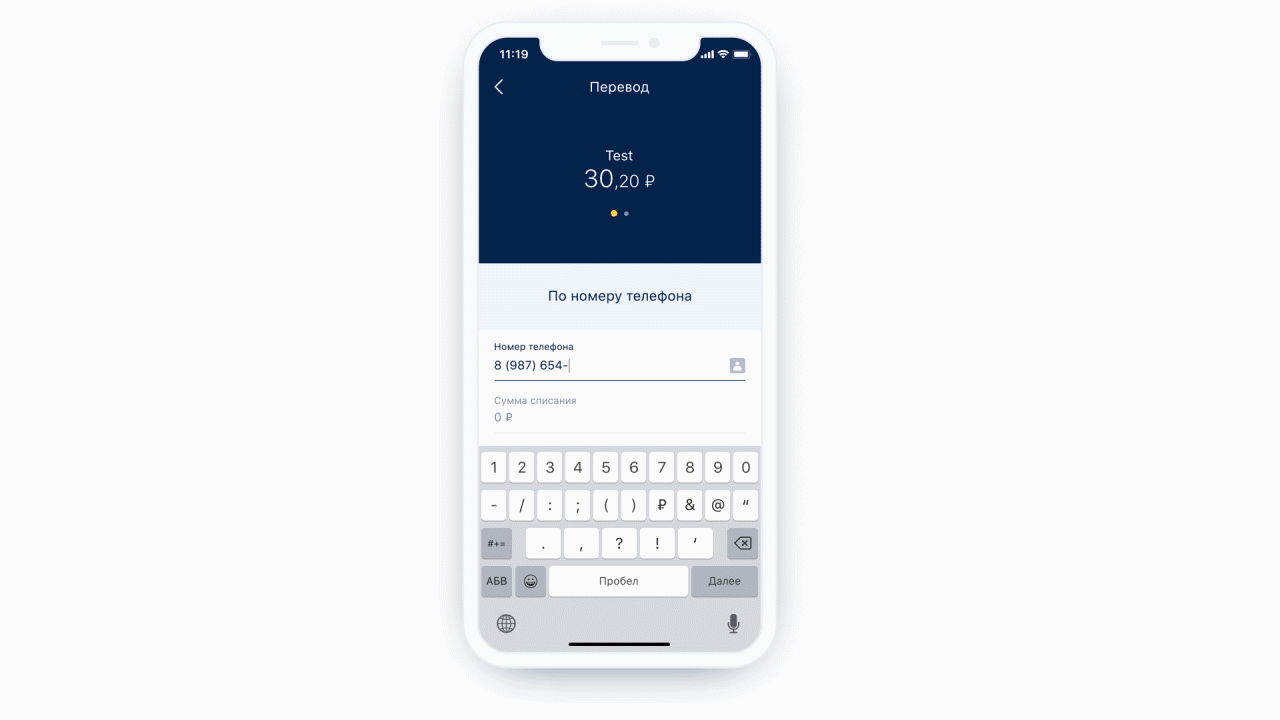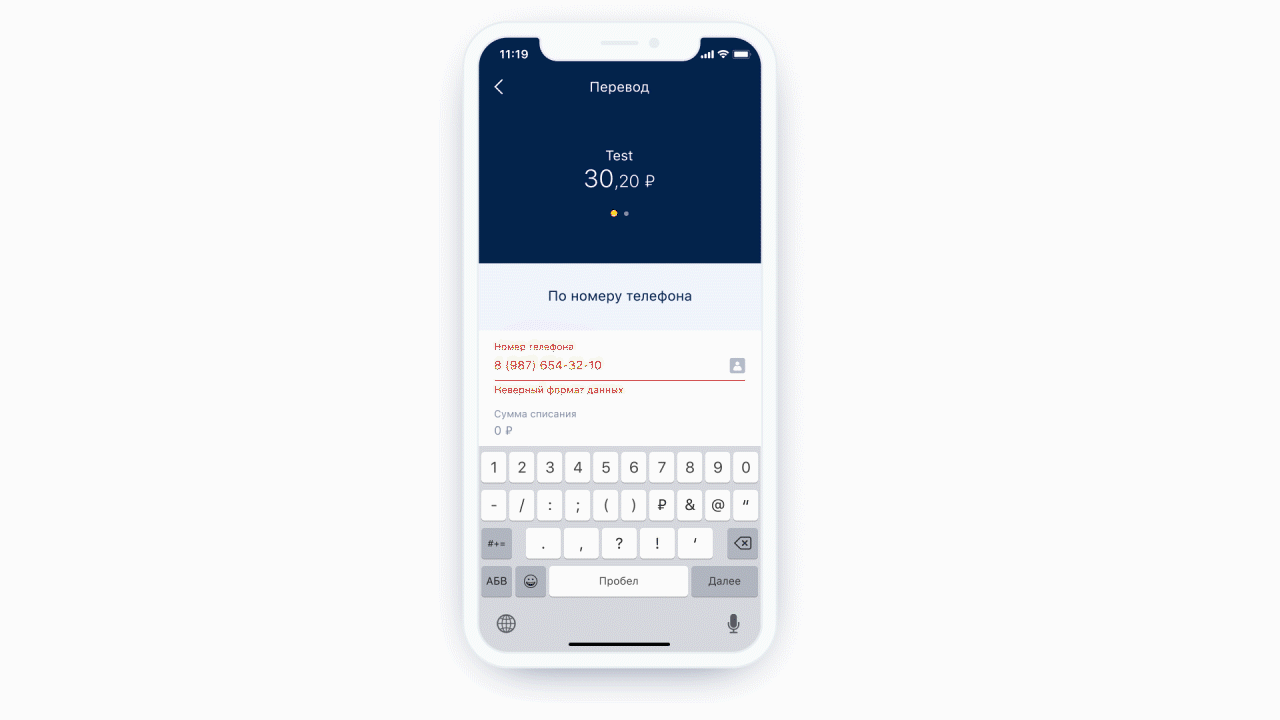
Outro recurso que obtivemos gratuitamente é a capacidade de realizar análise estática da máscara que chegou até nós. Ou seja, podemos entender que tipo de teclado é necessário para esta máscara e qual o número máximo de caracteres que pode haver nesta máscara. E é ainda mais legal, porque agora não mostramos o mesmo teclado o tempo todo para cada elemento de formulário - mostramos o teclado necessário sob o elemento de formulário necessário. E também podemos definir condicionalmente exatamente que algum campo é um campo de entrada de telefone.
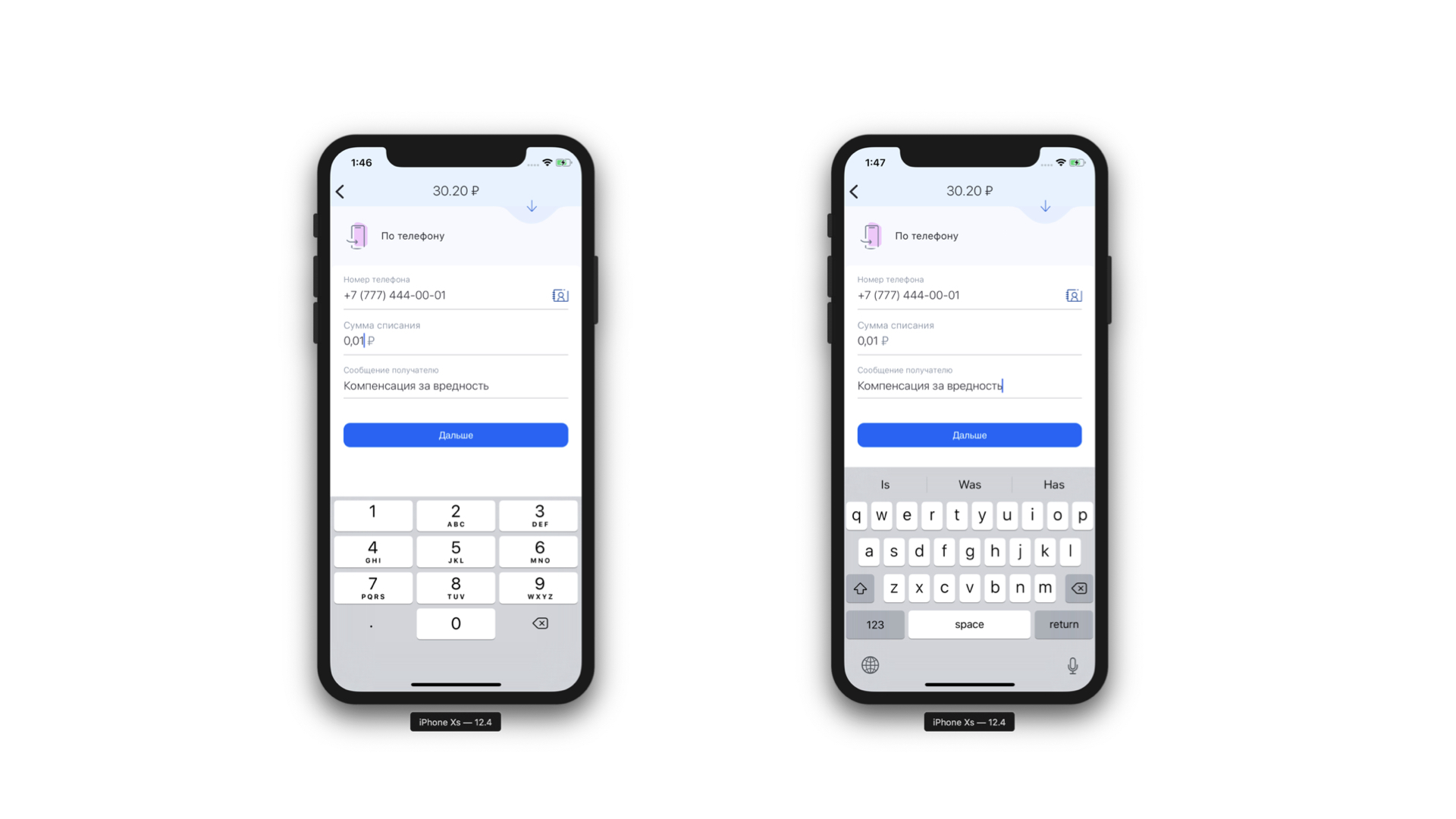
Esquerda: na parte superior do campo de entrada do telefone, há um ícone (na verdade um botão) que direcionará o usuário para a lista de contatos. À direita: exemplo de teclado para uma mensagem de texto normal.
Biblioteca de trabalho para traduzir máscaras
Você pode dar uma olhada em como implementamos a abordagem acima. A biblioteca está localizada no Github .
Exemplos de tradução de diferentes máscaras
Esta é a primeira máscara que vimos no início. É interpretado nesta representação RedMadRobot.

E esta é a segunda máscara - apenas uma máscara de entrada para algo. É convertido em tal representação.
