Inspirado pela palestra, este artigo apresenta uma abordagem para simplificar o processo de criação de operadores para Kubernetes e mostra como você pode fazer o seu próprio usando um operador de shell com o mínimo de esforço.

Apresentamos o vídeo com o relatório (~ 23 minutos em inglês, muito mais informativo do que o artigo) e o trecho principal dele em forma de texto. Ir!
Na Flant, otimizamos e automatizamos tudo constantemente. Hoje vamos falar sobre outro conceito interessante. Conheça o shell script nativo da nuvem !
No entanto, vamos começar com o contexto em que tudo isso acontece - Kubernetes.
API e controladores do Kubernetes
A API no Kubernetes pode ser representada como um tipo de servidor de arquivos com diretórios para cada tipo de objeto. Objetos (recursos) neste servidor são representados por arquivos YAML. Além disso, o servidor possui uma API básica para fazer três coisas:
- obtenha um recurso por seu tipo e nome;
- alterar o recurso (neste caso, o servidor armazena apenas objetos "corretos" - todos os formados incorretamente ou destinados a outros diretórios são descartados);
- ( / ).
Assim, o Kubernetes atua como uma espécie de servidor de arquivos (para manifestos YAML) com três métodos básicos (sim, na verdade, existem outros, mas vamos omiti-los por enquanto).

O problema é que o servidor só pode armazenar informações. Para fazer isso funcionar, você precisa de um controlador - o segundo conceito mais importante e fundamental no mundo do Kubernetes.
Existem dois tipos principais de controladores. O primeiro pega as informações do Kubernetes, as processa de acordo com a lógica aninhada e as retorna ao K8s. O segundo obtém informações do Kubernetes, mas, ao contrário do primeiro tipo, altera o estado de alguns recursos externos.
Vamos dar uma olhada no processo de criação de uma implantação no Kubernetes:
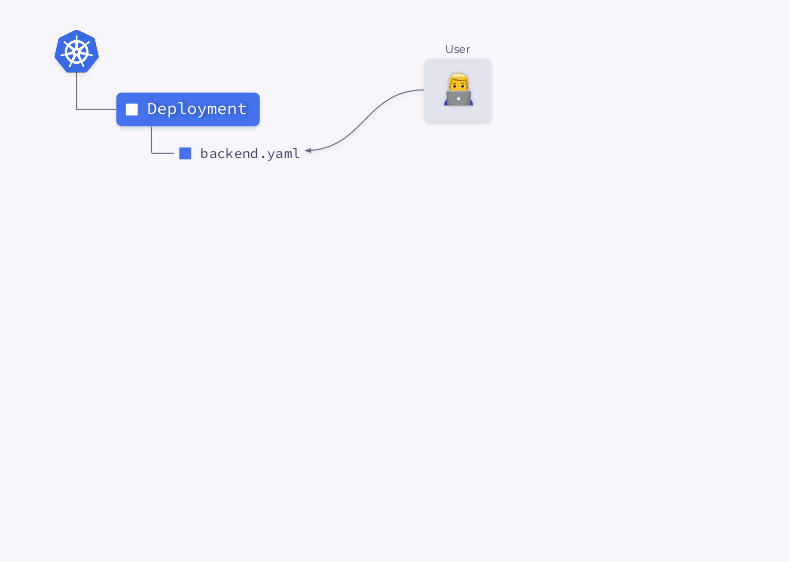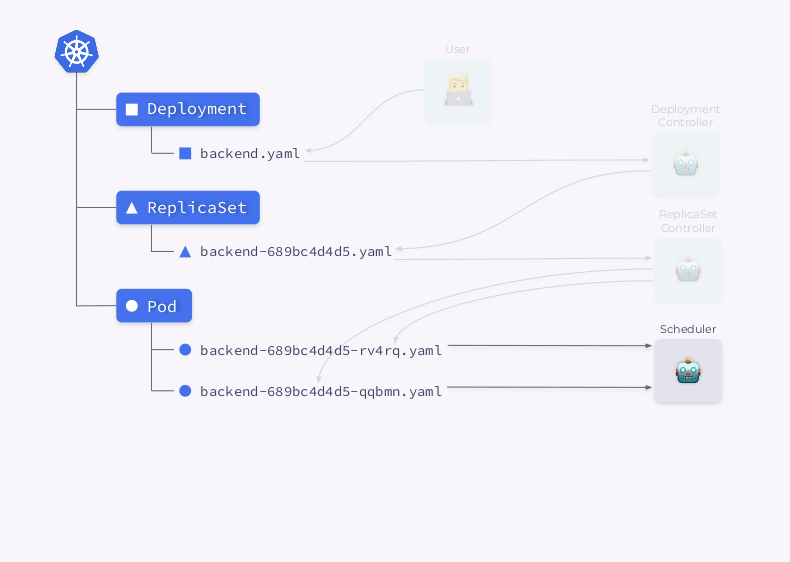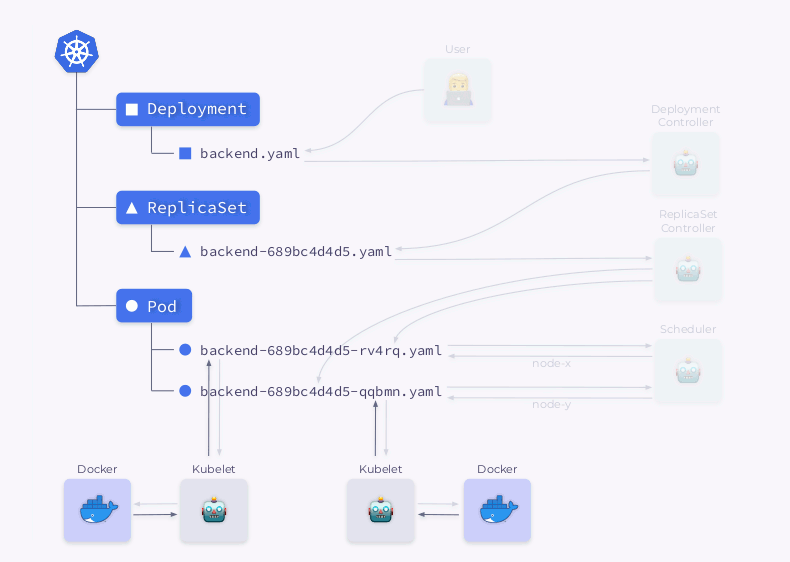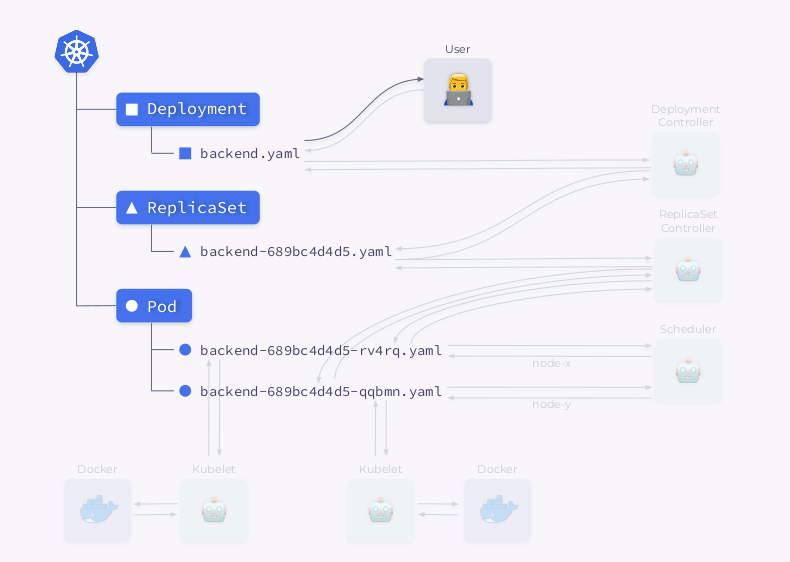
- O Deployment Controller (incluído em
kube-controller-manager) recebe informações sobre a implementação e cria um ReplicaSet. - ReplicaSet cria duas réplicas (dois pods) com base nessas informações, mas esses pods ainda não foram programados.
- O planejador agenda pods e adiciona informações de nó a seus YAMLs.
- Os Kubelets fazem alterações em um recurso externo (digamos, Docker).
Em seguida, toda a sequência é repetida na ordem inversa: o kubelet verifica os contêineres, calcula o status do pod e o envia de volta. O controlador ReplicaSet obtém o status e atualiza o status do conjunto de réplicas. A mesma coisa acontece com o Deployment Controller e o usuário finalmente obtém um status atualizado (atual).
Operador Shell
Acontece que o Kubernetes é baseado na colaboração de vários controladores (os operadores do Kubernetes também são controladores). Surge a pergunta: como criar seu próprio operador com o mínimo de esforço? E aqui o shell-operator desenvolvido por nós vem em nosso socorro . Ele permite que os administradores do sistema criem suas próprias declarações usando métodos familiares.

Exemplo simples: copiar segredos
Vamos dar uma olhada em um exemplo simples.
Digamos que temos um cluster Kubernetes. Tem um namespace
defaultcom algum segredo mysecret. Além disso, existem outros namespaces no cluster. Alguns deles possuem uma etiqueta específica anexada. Nosso objetivo é copiar o Secret em namespaces com um rótulo.
A tarefa é complicada pelo fato de que novos namespaces podem aparecer no cluster, e alguns deles podem ter este rótulo. Por outro lado, ao excluir uma etiqueta, o segredo também deve ser excluído. Além de tudo, o próprio segredo também pode mudar: neste caso, o novo segredo deve ser copiado para todos os namespaces com rótulos. Se o Secret for acidentalmente excluído de qualquer namespace, nosso operador deve restaurá-lo imediatamente.
Agora que a tarefa foi formulada, é hora de começar a implementá-la usando o operador de shell. Mas, primeiro, vale a pena dizer algumas palavras sobre o próprio operador de shell.
Como funciona o shell-operator
Como outras cargas de trabalho no Kubernetes, o shell-operator é executado em seu pod. Este pod
/hookscontém arquivos executáveis no diretório . Podem ser scripts em Bash, Python, Ruby, etc. Chamamos esses executáveis de ganchos .

O operador shell se inscreve em eventos do Kubernetes e aciona esses ganchos em resposta a quaisquer eventos de que precisamos.

Como o operador de shell sabe qual gancho executar e quando? A questão é que cada gancho tem dois estágios. Na inicialização, o operador de shell executa todos os ganchos com um argumento
--config- este é o estágio de configuração. E depois disso, os ganchos são lançados da maneira normal - em resposta aos eventos aos quais estão anexados. No último caso, o gancho recebe o contexto de ligação) - dados no formato JSON, que discutiremos com mais detalhes a seguir.
Fazendo o operador em Bash
Agora estamos prontos para implementação. Para fazer isso, precisamos escrever duas funções (a propósito, recomendamos a biblioteca shell_lib , que simplifica muito a escrita de ganchos no Bash):
- o primeiro é necessário para o estágio de configuração - ele exibe o contexto de ligação;
- o segundo contém a lógica principal do gancho.
#!/bin/bash
source /shell_lib.sh
function __config__() {
cat << EOF
configVersion: v1
# BINDING CONFIGURATION
EOF
}
function __main__() {
# THE LOGIC
}
hook::run "$@"
A próxima etapa é decidir de quais objetos precisamos. Em nosso caso, precisamos rastrear:
- fonte secreta para mudanças;
- todos os namespaces no cluster, para que você saiba a quais deles o rótulo está anexado;
- segredos de destino para garantir que todos estejam sincronizados com o segredo de origem.
Inscreva-se em uma fonte secreta
A configuração de ligação é bastante simples para ele. Indicamos que estamos interessados em Secret com um nome
mysecretno namespace default:

function __config__() {
cat << EOF
configVersion: v1
kubernetes:
- name: src_secret
apiVersion: v1
kind: Secret
nameSelector:
matchNames:
- mysecret
namespace:
nameSelector:
matchNames: ["default"]
group: main
EOF
Como resultado, o gancho será executado quando o secret (
src_secret) de origem for alterado e receber o seguinte contexto de ligação:

Como você pode ver, ele contém o nome e o objeto inteiro.
Manter o controle de namespaces
Agora você precisa se inscrever em namespaces. Para fazer isso, especificaremos a seguinte configuração de ligação:
- name: namespaces
group: main
apiVersion: v1
kind: Namespace
jqFilter: |
{
namespace: .metadata.name,
hasLabel: (
.metadata.labels // {} |
contains({"secret": "yes"})
)
}
group: main
keepFullObjectsInMemory: false
Como você pode ver, um novo campo chamado jqFilter apareceu na configuração . Como o próprio nome sugere, ele
jqFilterfiltra todas as informações desnecessárias e cria um novo objeto JSON com os campos de nosso interesse. Um gancho com essa configuração receberá o seguinte contexto de associação:
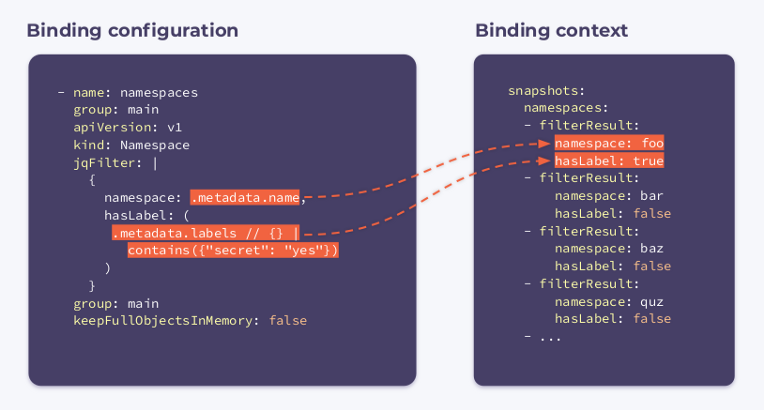
Ele contém uma matriz
filterResultspara cada namespace no cluster. Uma variável booleana que hasLabelindica se o rótulo está anexado ao namespace fornecido. O seletor keepFullObjectsInMemory: falsediz que não há necessidade de manter objetos completos na memória.
Rastreamento de alvos secretos
Assinamos todos os segredos que possuem uma anotação
managed-secret: "yes"(estes são os nossos destinatários dst_secrets):
- name: dst_secrets
apiVersion: v1
kind: Secret
labelSelector:
matchLabels:
managed-secret: "yes"
jqFilter: |
{
"namespace":
.metadata.namespace,
"resourceVersion":
.metadata.annotations.resourceVersion
}
group: main
keepFullObjectsInMemory: false
Nesse caso,
jqFilterfiltra todas as informações, exceto o namespace e o parâmetro resourceVersion. O último parâmetro foi passado para a anotação ao criar o segredo: permite comparar versões de segredos e mantê-los atualizados.
Um gancho configurado desta forma receberá os três contextos de ligação descritos acima quando executado. Pense neles como uma espécie de instantâneo do cluster.

Com base em todas essas informações, um algoritmo básico pode ser desenvolvido. Ele itera em todos os namespaces e:
- se
hasLabelrelevantetruepara o namespace atual:- compara o segredo global com o local:
- se são iguais, não faz nada;
- se forem diferentes, execute
kubectl replaceoucreate;
- compara o segredo global com o local:
- se
hasLabelrelevantefalsepara o namespace atual:
- certifica-se de que o Secret não está no namespace fornecido:
- se o segredo local estiver presente, exclua-o usando
kubectl delete; - se nenhum segredo local for encontrado, ele não fará nada.
- se o segredo local estiver presente, exclua-o usando
- certifica-se de que o Secret não está no namespace fornecido:

Você pode baixar a implementação do algoritmo no Bash em nosso repositório com exemplos .
Foi assim que pudemos criar um controlador Kubernetes simples usando 35 linhas de configurações YAML e quase a mesma quantidade de código Bash! O trabalho do operador de shell é amarrá-los juntos.
No entanto, copiar segredos não é a única área de aplicação do utilitário. Aqui estão mais alguns exemplos para mostrar do que ele é capaz.
Exemplo 1: fazendo alterações no ConfigMap
Vamos dar uma olhada em uma implantação de três pods. Os pods usam o ConfigMap para armazenar algumas configurações. Quando os pods foram lançados, o ConfigMap estava em algum estado (vamos chamá-lo de v.1). Da mesma forma, todos os pods usam essa versão específica do ConfigMap.
Agora, suponha que o ConfigMap tenha mudado (v.2). No entanto, os pods usarão a versão antiga do ConfigMap (v.1):
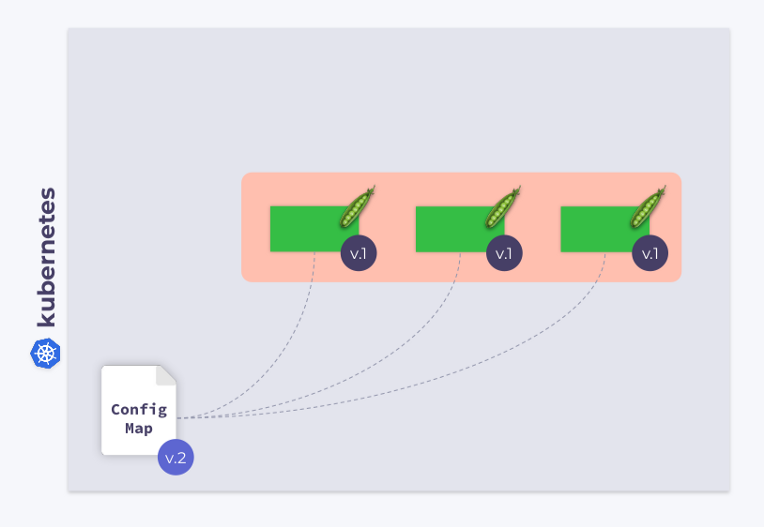
Como faço para que eles migrem para o novo ConfigMap (v.2)? A resposta é simples: use o modelo. Vamos adicionar uma anotação de soma de verificação à seção de
templateconfiguração de implantação:

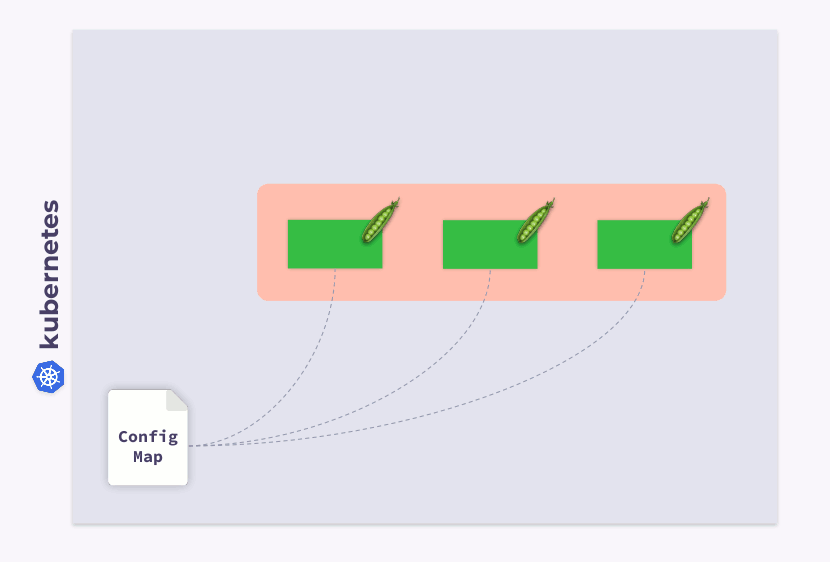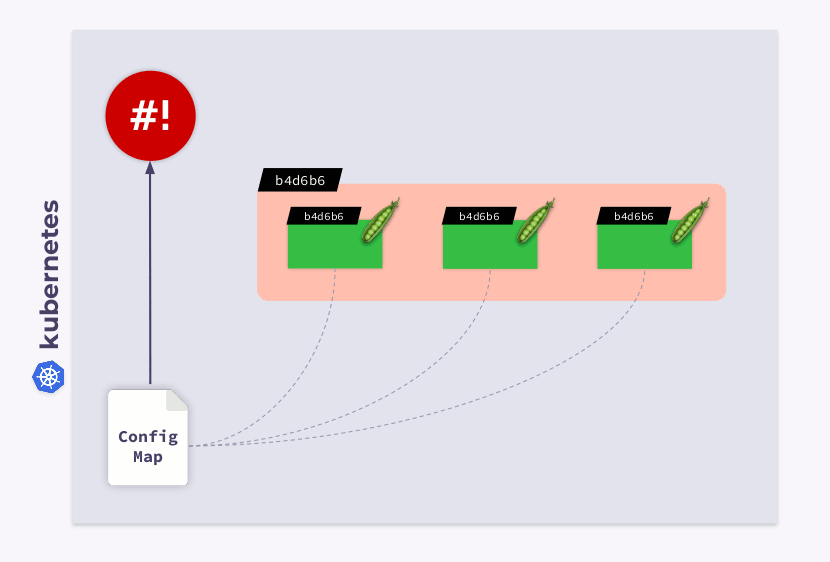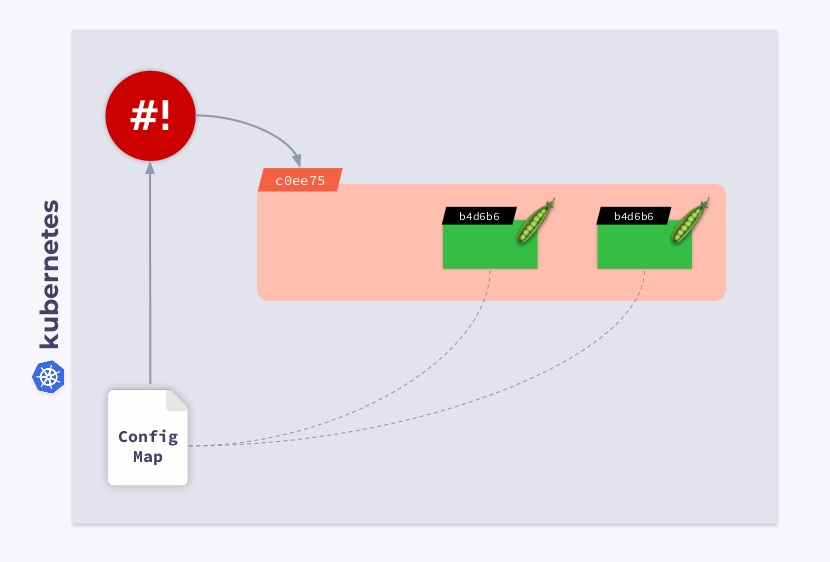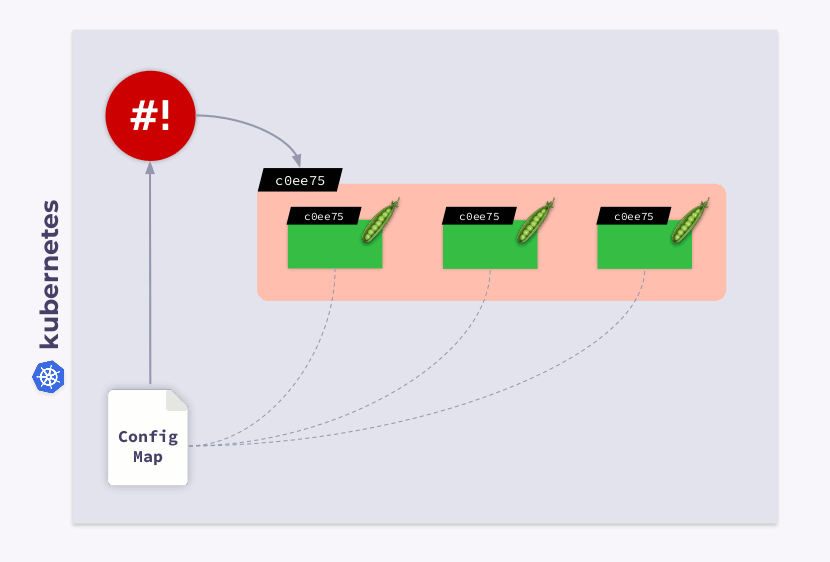
Como resultado, essa soma de verificação será registrada em todos os pods e será a mesma que na implantação. Agora você só precisa atualizar a anotação quando o ConfigMap muda. E o operador shell é útil neste caso. Tudo que você precisa fazer é programar um gancho que se inscreve no ConfigMap e atualiza a soma de verificação .
Se o usuário fizer alterações no ConfigMap, o operador de shell as notará e recalculará a soma de verificação. Então, a mágica do Kubernetes entra em ação: o orquestrador irá matar o pod, criar um novo, esperar que ele se torne realidade
Readye passar para o próximo. Como resultado, a implantação será sincronizada e migrada para a nova versão do ConfigMap.
Exemplo 2: trabalhando com definições de recursos personalizados
Como você sabe, o Kubernetes permite criar tipos personalizados (tipos) de objetos. Por exemplo, você pode criar um tipo
MysqlDatabase. Digamos que este tipo tenha dois parâmetros de metadados: nameenamespace.
apiVersion: example.com/v1alpha1
kind: MysqlDatabase
metadata:
name: foo
namespace: bar
Temos um cluster Kubernetes com diferentes namespaces nos quais podemos criar bancos de dados MySQL. Nesse caso, o operador de shell pode ser usado para rastrear recursos
MysqlDatabase, conectá-los ao servidor MySQL e sincronizar os estados desejados e observados do cluster.

Exemplo 3: monitoramento de uma rede de cluster
Como você sabe, usar o ping é a maneira mais simples de monitorar uma rede. Neste exemplo, mostraremos como implementar esse monitoramento usando o operador shell.
Em primeiro lugar, você precisa se inscrever nos nós. O operador shell precisa do nome e endereço IP de cada nó. Com a ajuda deles, ele executará ping nesses nós.
configVersion: v1
kubernetes:
- name: nodes
apiVersion: v1
kind: Node
jqFilter: |
{
name: .metadata.name,
ip: (
.status.addresses[] |
select(.type == "InternalIP") |
.address
)
}
group: main
keepFullObjectsInMemory: false
executeHookOnEvent: []
schedule:
- name: every_minute
group: main
crontab: "* * * * *"
O parâmetro
executeHookOnEvent: []evita o lançamento do gancho em resposta a qualquer evento (ou seja, em resposta a alterações, adições, exclusões de nós). No entanto, ele será executado (e atualizará a lista de hosts) em uma programação - a cada minuto, conforme o campo ditar schedule.
Agora surge a pergunta: como exatamente sabemos sobre problemas como perda de pacotes? Vamos dar uma olhada no código:
function __main__() {
for i in $(seq 0 "$(context::jq -r '(.snapshots.nodes | length) - 1')"); do
node_name="$(context::jq -r '.snapshots.nodes['"$i"'].filterResult.name')"
node_ip="$(context::jq -r '.snapshots.nodes['"$i"'].filterResult.ip')"
packets_lost=0
if ! ping -c 1 "$node_ip" -t 1 ; then
packets_lost=1
fi
cat >> "$METRICS_PATH" <<END
{
"name": "node_packets_lost",
"add": $packets_lost,
"labels": {
"node": "$node_name"
}
}
END
done
}
Nós iteramos a lista de nós, obtemos seus nomes e endereços IP, fazemos ping e enviamos os resultados para o Prometheus. O operador shell pode exportar métricas para o Prometheus , salvando-as em um arquivo localizado de acordo com o caminho especificado na variável de ambiente
$METRICS_PATH.
É assim que você pode fazer um operador para monitoramento de rede simples em um cluster.
Mecanismo de fila
Este artigo estaria incompleto sem descrever outro mecanismo importante embutido no operador shell. Imagine que ele executa um gancho em resposta a um evento no cluster.
- O que acontece se outro evento ocorrer no cluster ao mesmo tempo ?
- O operador de shell iniciará outra instância do gancho?
- Mas e se, digamos, cinco eventos ocorram imediatamente no cluster?
- O shell-operator tratará deles em paralelo?
- E quanto aos recursos consumidos, como memória e CPU?
Felizmente, o shell-operator tem um mecanismo de enfileiramento embutido. Todos os eventos são enfileirados e processados sequencialmente.
Vamos ilustrar isso com exemplos. Digamos que temos dois ganchos. O primeiro evento vai para o primeiro gancho. Após a conclusão do processamento, a fila avança. Os próximos três eventos são redirecionados para o segundo gancho - eles são removidos da fila e alimentados em um "lote". Ou seja, o gancho recebe uma matriz de eventos - ou mais precisamente, uma matriz de contextos de ligação.
Além disso, esses eventos podem ser combinados em um grande . O parâmetro
groupna configuração de ligação é responsável por isso .

Você pode criar qualquer número de filas / ganchos e suas várias combinações. Por exemplo, uma fila pode funcionar com dois ganchos ou vice-versa.
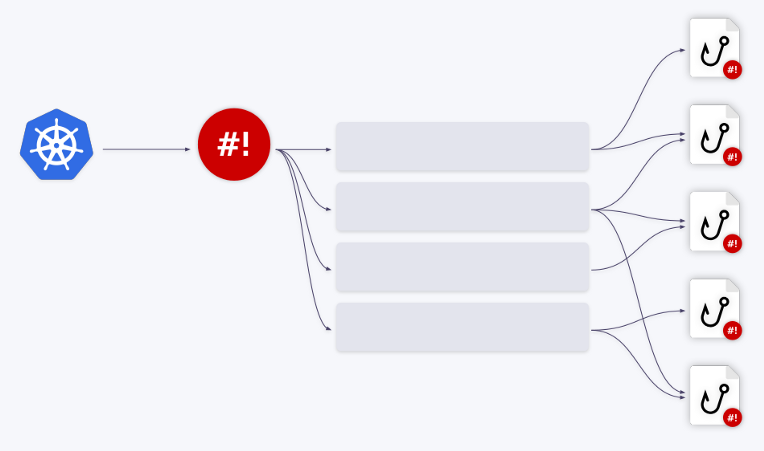
Tudo que você precisa fazer é ajustar o campo de acordo
queuecom a configuração de ligação. Se nenhum nome de fila for especificado, o gancho será executado na fila padrão ( default). Este mecanismo de enfileiramento permite resolver completamente todos os problemas de gerenciamento de recursos ao trabalhar com ganchos.
Conclusão
Falamos sobre o que é um operador de shell, mostramos como ele pode ser usado para criar operadores Kubernetes de maneira rápida e fácil e demos vários exemplos de seu uso.
Informações detalhadas sobre o operador de shell, bem como um guia rápido para usá-lo, estão disponíveis no repositório correspondente no GitHub . Não hesite em nos contatar com perguntas: você pode discuti-las em um grupo especial do Telegram (em russo) ou neste fórum (em inglês).
E se você gostou, ficamos sempre contentes com novas edições / PR / estrelas no GitHub, onde, aliás, você encontra outros projetos interessantes . Dentre eles, vale destacar o operador-addon , irmão mais velho do operador-shell... Este utilitário usa gráficos Helm para instalar add-ons, é capaz de fornecer atualizações e monitorar vários parâmetros / valores de gráficos, controlar o processo de instalação de gráficos e também modificá-los em resposta a eventos no cluster.

Vídeos e slides
Vídeo da apresentação (~ 23 minutos):
Apresentação do relatório:
PS
Leia também em nosso blog:
- " Criação simples de operadores Kubernetes com um operador shell: progresso do projeto em um ano ";
- " Apresentando o operador de shell: criar operadores para Kubernetes ficou mais fácil ";
- “ É fácil e conveniente preparar um cluster Kubernetes? Anunciamos o operador adicional ";
- “ Expandindo e complementando Kubernetes” (revisão e vídeo do relatório) .