Introdução
Este artigo é uma compilação de outro artigo . Nele pretendo me concentrar em ferramentas para trabalhar com Big data voltadas para análise de dados.
Então, digamos que você aceitou os dados brutos, os processou e agora está pronto para uso posterior.
Existem muitas ferramentas usadas para manipular dados, cada uma com suas próprias vantagens e desvantagens. A maioria deles é orientada para OLAP, mas alguns também são otimizados para OLTP. Alguns deles usam formatos padrão e se concentram apenas na execução de consultas, outros usam seu próprio formato ou armazenamento para transferir os dados processados para a fonte a fim de melhorar o desempenho. Alguns são otimizados para armazenar dados usando certos esquemas, como estrela ou floco de neve, mas outros são mais flexíveis. Resumindo, temos as seguintes oposições:
- Data Warehouse vs. Lake
- Hadoop vs. armazenamento offline
- OLAP vs OLTP
- Mecanismo de consulta versus mecanismos OLAP
Também examinaremos ferramentas para processamento de dados com a capacidade de executar consultas.
Ferramentas de processamento de dados
A maioria das ferramentas mencionadas pode se conectar a um servidor de metadados como o Hive e executar consultas, criar visualizações, etc. Isso geralmente é usado para criar níveis de relatório adicionais (aprimorados).
O Spark SQL oferece uma maneira de misturar perfeitamente consultas SQL com programas Spark, para que você possa misturar APIs DataFrame com SQL. Ele tem integração com o Hive e uma conexão JDBC ou ODBC padrão, para que você possa conectar o Tableau, Looker ou qualquer ferramenta de BI aos seus dados por meio do Spark.

Apache Flinktambém fornece API SQL. O suporte SQL do Flink é baseado no Apache Calcite, que implementa o padrão SQL. Ele também se integra ao Hive via HiveCatalog. Por exemplo, os usuários podem armazenar suas tabelas Kafka ou ElasticSearch no Hive Metastore usando o HiveCatalog e reutilizá-las posteriormente em consultas SQL.
O Kafka também fornece recursos SQL. Em geral, a maioria das ferramentas de processamento de dados fornece interfaces SQL.
Ferramentas de Consulta
Este tipo de ferramenta está focado em uma consulta unificada a diferentes fontes de dados em diferentes formatos. A ideia é rotear consultas para seu data lake usando SQL como se fosse um banco de dados relacional regular, embora tenha algumas limitações. Algumas dessas ferramentas também podem consultar bancos de dados NoSQL e muito mais. Essas ferramentas fornecem uma interface JDBC para ferramentas externas como Tableau ou Looker para se conectar com segurança ao seu data lake. As ferramentas de consulta são a opção mais lenta, mas fornecem a maior flexibilidade.
Porco apache: uma das primeiras ferramentas ao lado do Hive. Tem sua própria linguagem diferente de SQL. Uma característica distintiva dos programas criados pelo Pig é que sua estrutura se presta a uma paralelização significativa, o que, por sua vez, permite que eles processem conjuntos de dados muito grandes. Por causa disso, ele ainda não está desatualizado em comparação com os sistemas modernos baseados em SQL.
Presto: Uma plataforma de código aberto do Facebook. É um mecanismo de consulta SQL distribuído para realizar consultas analíticas interativas em fontes de dados de qualquer tamanho. O Presto permite consultar dados onde quer que estejam, incluindo Hive, Cassandra, bancos de dados relacionais e sistemas de arquivos. Ele pode consultar grandes conjuntos de dados em segundos. O Presto é independente do Hadoop, mas se integra com a maioria de suas ferramentas, especialmente Hive, para executar consultas SQL.
Apache Drill: Fornece um mecanismo de consulta SQL sem esquema para Hadoop, NoSQL e até mesmo armazenamento em nuvem. Não depende do Hadoop, mas tem muitas integrações com ferramentas de ecossistema como o Hive. Uma única consulta pode combinar dados de vários armazenamentos, realizando otimizações específicas para cada um deles. Isso é muito bom porque permite que os analistas tratem quaisquer dados como uma tabela, mesmo que estejam realmente lendo o arquivo. O Drill oferece suporte total ao SQL padrão. Os usuários de negócios, analistas e cientistas de dados podem usar ferramentas de business intelligence padrão, como Tableau, Qlik e Excel para interagir com armazenamentos de dados não relacionais usando Drill JDBC e drivers ODBC. Além disso,os desenvolvedores podem usar o simples REST API Drill em seus aplicativos personalizados para criar belas visualizações.
Bancos de dados OLTP
Embora o Hadoop seja otimizado para OLAP, ainda existem situações em que você deseja executar consultas OLTP em um aplicativo interativo.
O HBase tem propriedades ACID muito limitadas por design, pois foi criado para escalar e não fornece recursos ACID prontos para uso, mas pode ser usado para alguns cenários OLTP.
O Apache Phoenix é construído com base no HBase e fornece uma maneira de fazer consultas OTLP em todo o ecossistema Hadoop. O Apache Phoenix é totalmente integrado a outros produtos Hadoop, como Spark, Hive, Pig, Flume e Map Reduce. Ele também pode armazenar metadados, oferecer suporte à criação de tabelas e alterações incrementais de versão usando comandos DDL. Funciona muito rápido, mais rápido do que usar Drill ou outro
mecanismo de solicitações.
Você pode usar qualquer banco de dados de grande escala fora do ecossistema Hadoop, como Cassandra, YugaByteDB, ScyllaDB para OTLP.
Por fim, é muito comum que bancos de dados rápidos de qualquer tipo, como MongoDB ou MySQL, tenham um subconjunto de dados mais lento, geralmente o mais recente. Os mecanismos de consulta mencionados acima podem combinar dados entre armazenamento lento e rápido em uma única consulta.
Indexação Distribuída
Essas ferramentas fornecem maneiras de armazenar e recuperar dados de texto não estruturados e vivem fora do ecossistema Hadoop, pois requerem estruturas especiais para armazenar os dados. A ideia é usar um índice invertido para fazer buscas rápidas. Além da pesquisa de texto, essa tecnologia pode ser usada para uma variedade de finalidades, como armazenamento de registros, eventos, etc. Existem duas opções principais:
Solr: Esta é uma plataforma de pesquisa corporativa de software livre popular e muito rápida desenvolvida no Apache Lucene. Solr é uma ferramenta robusta, escalável e resiliente, fornecendo indexação distribuída, replicação e consultas de balanceamento de carga, failover e recuperação automáticos, configuração centralizada e muito mais. É ótimo para pesquisa de texto, mas seus casos de uso são limitados em comparação com ElasticSearch.
ElasticSearch: Também é um índice distribuído muito popular, mas cresceu em um ecossistema próprio que abrange muitos casos de uso, como APM, pesquisa, armazenamento de texto, análise, painéis, aprendizado de máquina e muito mais. Definitivamente, é uma ferramenta para ter em sua caixa de ferramentas para DevOps ou pipeline de dados, pois é muito versátil. Ele também pode armazenar e pesquisar vídeos e imagens.
ElasticSearchpode ser usado como uma camada de armazenamento rápida para seu data lake para funcionalidade de pesquisa avançada. Se você estiver armazenando seus dados em um grande banco de dados de valor-chave como HBase ou Cassandra, que fornece recursos de pesquisa muito limitados devido à falta de conexões, você pode colocar ElasticSearch na frente dele para executar consultas, retornar IDs e, em seguida, faça uma busca rápida em seu banco de dados.
Ele também pode ser usado para análises. Você pode exportar seus dados, indexá-los e, em seguida, consultá-los usando KibanaAo criar painéis, relatórios e muito mais, você pode adicionar histogramas, agregações complexas e até mesmo executar algoritmos de aprendizado de máquina sobre seus dados. O ecossistema ElasticSearch é enorme e vale a pena explorar.
Bancos de dados OLAP
Aqui, examinamos os bancos de dados que também podem fornecer um armazenamento de metadados para esquemas de consulta. Em comparação com os sistemas de execução de consultas, essas ferramentas também fornecem armazenamento de dados e podem ser aplicadas a esquemas de armazenamento específicos (esquema estrela). Essas ferramentas usam sintaxe SQL. Spark ou outras plataformas podem interagir com eles.
Colmeia apache: Já discutimos o Hive como um repositório de esquema central para Spark e outras ferramentas para que eles possam usar SQL, mas o Hive também pode armazenar dados para que você possa usá-lo como um repositório. Ele pode acessar HDFS ou HBase. Quando solicitado pelo Hive, ele usa Apache Tez, Apache Spark ou MapReduce, sendo muito mais rápido que Tez ou Spark. Ele também possui uma linguagem procedural chamada HPL-SQL. O Hive é um armazenamento de metadados extremamente popular para Spark SQL.
Apache Impala: É um banco de dados analítico nativo para Hadoop que você pode usar para armazenar dados e consultá-los com eficiência. Ela pode se conectar ao Hive para obter metadados usando Hcatalog. O Impala fornece baixa latência e alta simultaneidade para consultas de inteligência de negócios e análise no Hadoop (que não é fornecido por plataformas empacotadas como Apache Hive). O Impala também é escalonado linearmente, mesmo em ambientes multiusuário, o que é uma alternativa de consulta melhor do que o Hive. O Impala é integrado com segurança proprietária Hadoop e Kerberos para autenticação, para que você possa gerenciar o acesso aos dados com segurança. Ele usa HBase e HDFS para armazenamento de dados.

Apache Tajo: Este é outro data warehouse para Hadoop. Tajo foi projetado para executar consultas ad-hoc com baixa latência e escalabilidade, agregação online e ETL para grandes conjuntos de dados armazenados em HDFS e outras fontes de dados. Ele suporta integração com o Hive Metastore para acessar esquemas comuns. Ele também tem muitas otimizações de consulta, é escalonável, tolerante a falhas e fornece uma interface JDBC.
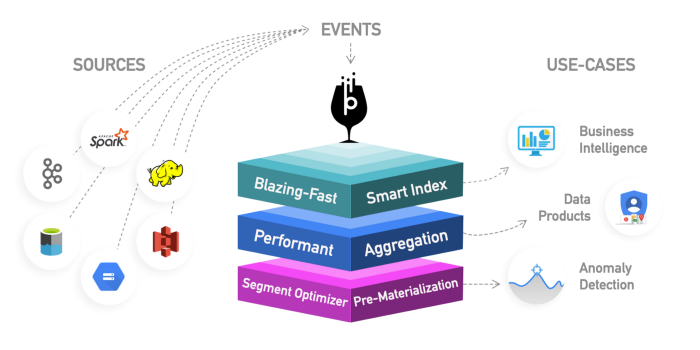
Apache Kylin: Este é um novo data warehouse analítico distribuído. Kylin é extremamente rápido, portanto, pode ser usado para complementar alguns outros bancos de dados, como o Hive, para casos de uso em que o desempenho é crítico, como painéis ou relatórios interativos. Este é provavelmente o melhor data warehouse OLAP, mas difícil de usar. Outro problema é que mais espaço de armazenamento é necessário devido ao grande estiramento. A ideia é que se os motores de consulta ou Hive não forem rápidos o suficiente, você pode criar um "Cubo" no Kylin, que é uma tabela multidimensional otimizada para OLAP com dados pré-computados
valores que você pode consultar em painéis ou relatórios interativos. Ele pode criar cubos diretamente do Spark e até quase em tempo real do Kafka.
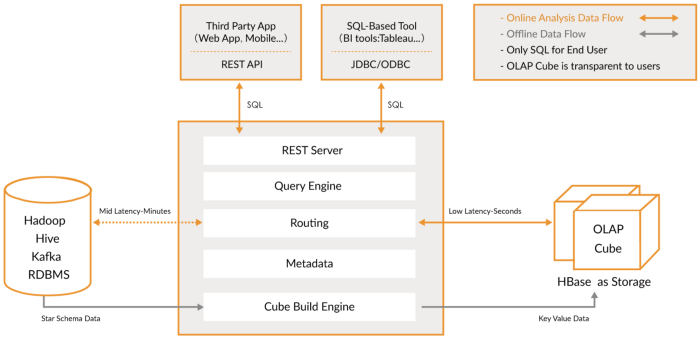
Ferramentas OLAP
Nesta categoria, incluo mecanismos mais recentes, que são evoluções de bancos de dados OLAP anteriores, que fornecem mais funcionalidade, criando uma plataforma analítica abrangente. Na verdade, eles são um híbrido das duas categorias anteriores que adicionam indexação aos seus bancos de dados OLAP. Eles residem fora da plataforma Hadoop, mas são totalmente integrados. Nesse caso, você geralmente pula a etapa de processamento e usa essas ferramentas diretamente.
Eles tentam resolver o problema de consultar dados em tempo real e dados históricos de maneira uniforme, para que você possa consultar dados em tempo real imediatamente assim que estiverem disponíveis, junto com dados históricos de baixa latência para que você possa construir aplicativos e painéis interativos. Essas ferramentas permitem, em muitos casos, consultar dados brutos com pouca ou nenhuma transformação no estilo ELT, mas com alto desempenho, melhor do que os bancos de dados OLAP convencionais.
O que eles têm em comum é que fornecem uma visão unificada de dados, ingestão de dados ao vivo e em lote, indexação distribuída, formato de dados nativo, suporte SQL, interface JDBC, suporte de dados quente e frio, múltiplas integrações e armazenamento de metadados.
Apache Druid: Este é o mecanismo OLAP em tempo real mais famoso. É focado em dados de série temporal, mas pode ser usado para qualquer dado. Ele usa seu próprio formato colunar que pode compactar muito os dados e tem muitas otimizações integradas, como índices invertidos, codificação de texto, recolhimento automático de dados e muito mais. Os dados são carregados em tempo real usando Tranquility ou Kafka, que têm latência muito baixa, são armazenados na memória em um formato de string otimizado para gravação, mas assim que chegam, ficam disponíveis para consulta como os dados baixados anteriormente. O processo em segundo plano é responsável por mover dados de forma assíncrona para um sistema de armazenamento profundo, como HDFS. Quando os dados são movidos para o armazenamento profundo, eles são divididos em pedaços menores,segregados por tempo, chamados de segmentos, que são bem otimizados para consultas de baixa latência. Este segmento tem um registro de data e hora para várias dimensões que você pode usar para filtrar e agregar, e métricas, que são estados pré-calculados. Na recepção de burst, os dados são salvos diretamente em segmentos. O Apache Druid suporta engolir push e pull, integração com Hive, Spark e até NiFi. Ele pode usar o armazenamento de metadados Hive e oferece suporte a consultas Hive SQL, que são então convertidas em consultas JSON usadas pelo Druid. A integração do Hive oferece suporte a JDBC, para que você possa conectar qualquer ferramenta de BI. Ele também tem seu próprio repositório de metadados, normalmente MySQL é usado para isso.Ele pode aceitar grandes quantidades de dados e escalas muito bem. O principal problema é que ele tem muitos componentes e é difícil de gerenciar e implantar.
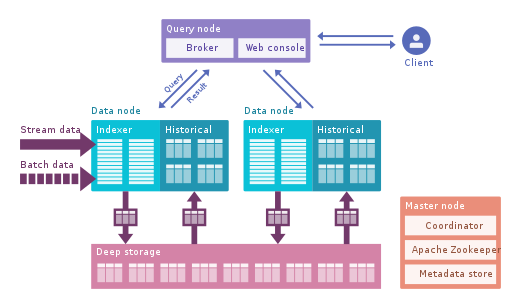
Apache Pinot : Esta é uma alternativa druida de código aberto mais recente do LinkedIn. Comparado ao Druid, ele oferece latência mais baixa graças ao índice Startree, que faz pré-cálculo parcial, portanto, pode ser usado para aplicativos centrados no usuário (era usado para obter feeds do LinkedIn). Ele usa um índice classificado em vez de um invertido, que é mais rápido. Ele tem uma arquitetura de plug-in extensível e também muitas integrações, mas não oferece suporte a Hive. Ele também integra processamento em lote e em tempo real, fornece carregamento rápido, índice inteligente e armazena dados em segmentos. É mais fácil e rápido de implantar em comparação com o Druida, mas parece um pouco imaturo no momento.
ClickHouse: Escrito em C ++, esse mecanismo oferece um desempenho incrível para consultas OLAP, especialmente para agregados. É como um banco de dados relacional, então você pode modelar os dados facilmente. É muito fácil de configurar e possui muitas integrações.
Leia este artigo que compara os 3 motores em detalhes.
Comece examinando seus dados antes de tomar uma decisão. Esses novos mecanismos são muito poderosos, mas difíceis de usar. Se você puder esperar por horas, use o processamento em lote e um banco de dados como o Hive ou o Tajo; em seguida, use Kylin para acelerar as consultas OLAP e torná-las mais interativas. Se isso não for suficiente e você precisar de ainda menos latência e dados em tempo real, considere os mecanismos OLAP. O Druid é mais adequado para análises em tempo real. Kaileen está mais focada em casos OLAP. Druid tem uma boa integração com Kafka como streaming ao vivo. Kylin está recebendo dados do Hive ou Kafka em lotes, embora a recepção ao vivo esteja planejada.
Finalmente, Greenplum É mais um motor OLAP, mais focado em inteligência artificial.
Visualização de dados
Existem várias ferramentas comerciais para visualização, como Qlik, Looker ou Tableau.
Se você preferir Open Source, procure SuperSet. É uma ótima ferramenta que suporta todas as ferramentas que mencionamos, tem um ótimo editor e é muito rápido, usa SQLAlchemy para suportar vários bancos de dados.
Outras ferramentas interessantes são Metabase ou Falcon .
Conclusão
Há uma ampla gama de ferramentas que podem ser usadas para manipular dados, desde mecanismos de consulta flexíveis como o Presto até armazenamentos de alto desempenho como Kylin. Não existe uma solução única para todos, aconselho você a pesquisar os dados disponíveis e começar pequeno. Os motores de consulta são um bom ponto de partida devido à sua flexibilidade. Então, para diferentes casos de uso, pode ser necessário adicionar outras ferramentas para atingir o nível de serviço desejado.
Preste atenção especial às novas ferramentas como Druid ou Pinot, que fornecem uma maneira fácil de analisar grandes quantidades de dados com latência muito baixa, eliminando a lacuna entre OLTP e OLAP em termos de desempenho. Você pode ficar tentado a pensar sobre processamento, pré-cálculo de agregados e coisas do gênero, mas considere essas ferramentas se quiser simplificar seu trabalho.