O Aprendizado por Reforço é ruim, ou melhor, não funciona de forma alguma com dimensões altas. E também enfrenta o problema de que os simuladores de física são bastante lentos. Portanto, recentemente, uma maneira de contornar essas limitações se tornou popular treinando uma rede neural separada que simula um mecanismo de física. Acontece algo como um análogo da imaginação, em que ocorre o aprendizado básico adicional.
Vamos ver quanto progresso foi feito nesta área e olhar as principais arquiteturas.
A ideia de usar uma rede neural em vez de um simulador físico não é nova, uma vez que simuladores simples como MuJoCo ou Bullet em CPUs modernas são capazes de fornecer pelo menos 100-200 FPS (e mais frequentemente a 60), e executar um simulador de rede neural em lotes paralelos produz facilmente 2.000-10000 FPS em qualidade comparável. É verdade que em pequenos horizontes de 10-100 passos, mas para o aprendizado por reforço, isso geralmente é o suficiente.
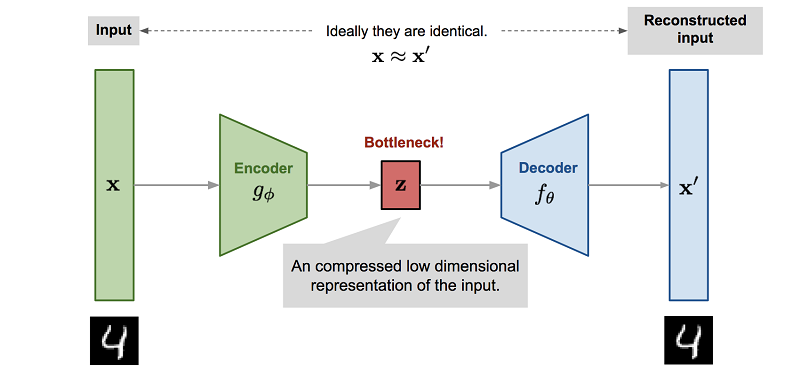
Porém, o mais importante é que o processo de treinamento de uma rede neural para imitar um mecanismo de física geralmente envolve a redução de dimensionalidade. Já que a maneira mais fácil de treinar essa rede neural é usar um autencoder, onde isso acontece automaticamente.
, , . , . - , , , , Z.
Z Reinforcement Learning. , , ( , , ). , .
, — , , . . , Z , model-based , , .
, Reinforcement Learning. "" : , , , .
World Models
( ), 2018 World Models.
: - "" , Z. ( ).
VAE:
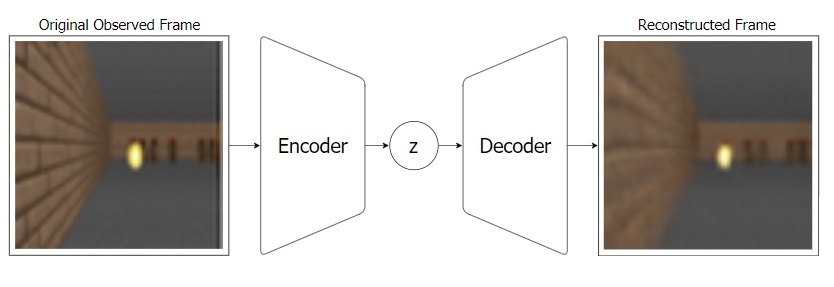
, VAE ( MDN-RNN), . VAE , . , RNN Z . .
:

, : VAE(V) Z MDN-RNN(M) . Z, . MDN-RNN , Z , .
, "" ( - MDN-RNN), . ( ), .
, "" (. ) MDN-RNN (Controller — "", ). , , environment. , C , . VAE(V).
Controller ©, ? ! , -"", Controller. , . , CMA-ES. , Z , . . , , , .
, , .
PlaNet
PlaNet. (, , Controller reinforcement learning), PlaNet Model-Based .
, Model-Based RL — . . , . , , RL , .
Model-Based , , , . (CEM PDDM).
- , ! , .
, . , . .
, . . . (.. state, Reinforcement Learning) , , . Model-Based .
PlaNet, World Models , , Z ( S — state).

Z (, S) , , . , - .
S (, Z) . , , . , .
S , . Model-Based ( ""). .
, , .. -"", A. Model-Based — . , state S . R , state S , ( ). , , ! ( ). Model-Based , .. , , , S R. , World Models, .
Model-Based , PlaNet . 50 . , , , , Model-Free .

Model-Based , (-), . , . . , Model-Based, PlaNet . ( ), .
Dreamer
PlaNet Dreamer. .
PlaNet, Dreamer S, , . Dreamer Value , . Reinforcement Learning. . , . Model-Based ( PlaNet) .

, , Dreamer Actor , . Model-Free , actor-critic.
actor-critic Model-Free , actor , critic ( value, advantage), Dreamer actor . Model-Free .
Dreamer' , . Actor , (. ). Value , , value reward .

, Dreamer Model-Based . Model-Free. model-based ( , ) Actor . Dreamer . , PlaNet Model-Based .
, Dreamer 20 , , Model-Free . , Dreamer 20 , ( ) .

Dreamer Reinforcement Learning . MuJoCo, , .
Plan2Explore
. Reinforcement Learning , .
, - , . , - , , . , , ! Plan2Explore .
Reinforcement Learning , , . , .
, . . , -, . -, , - , .
, . , , Plan2Explore , . , .
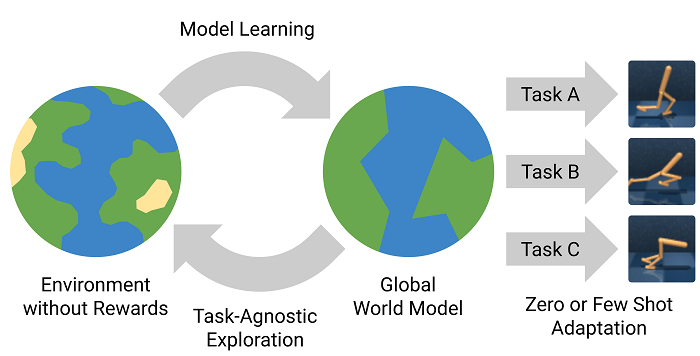
Plan2Explore : , . , - , . . . zero-shot . ( , . World Models ), few-shot .
Plan2Explore , Dreamer Model-Free , , . , .
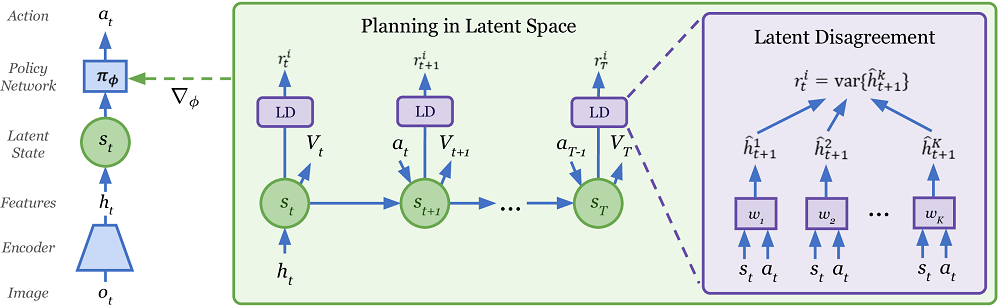
Curiosamente, o Plan2Explore usa uma maneira incomum de avaliar a novidade de novos lugares enquanto explora o mundo. Para isso, é treinado um conjunto de modelos treinados apenas em um modelo de mundo e prevendo apenas um passo à frente. Argumenta-se que suas previsões diferem para estados de alta novidade, mas como conjuntos de dados (visitas frequentes ao site), suas previsões começam a concordar mesmo em ambientes estocásticos aleatórios. Uma vez que as previsões de uma etapa eventualmente convergem para alguns valores médios neste ambiente estocástico. Se você não entendeu nada, então você não está sozinho. Lá no artigo não está muito claro como é descrito. Mas de alguma forma parece funcionar.