- Vou começar com a origem dos cinemas online.

No decorrer do desenvolvimento da Internet, surgiram os serviços de mídia OTT, que passaram a ser utilizados para a transferência de conteúdo midiático pela Internet, ao contrário dos serviços de mídia tradicionais, onde se utilizavam cabo, satélite e outros canais de comunicação.
Esses serviços de mídia são baseados em OVP - uma plataforma de vídeo online, que inclui um sistema de gerenciamento de conteúdo, um reprodutor web e um CDN. Uma classe separada de tais sistemas é OTT-TV, um cinema online, que, além de OVP, implementa sistemas de controle e gerenciamento para acesso ao conteúdo, um sistema de proteção de direitos de conteúdo digital, gerenciamento de assinaturas, compras e vários produtos e métricas técnicas. E isso impõe a esses sistemas maiores requisitos de tempo de atividade e latência.
Vou falar sobre o backend, que é responsável pelo sistema de gerenciamento de conteúdo, pela funcionalidade do usuário do cinema online e pela parte do sistema de gerenciamento e controle de conteúdo.
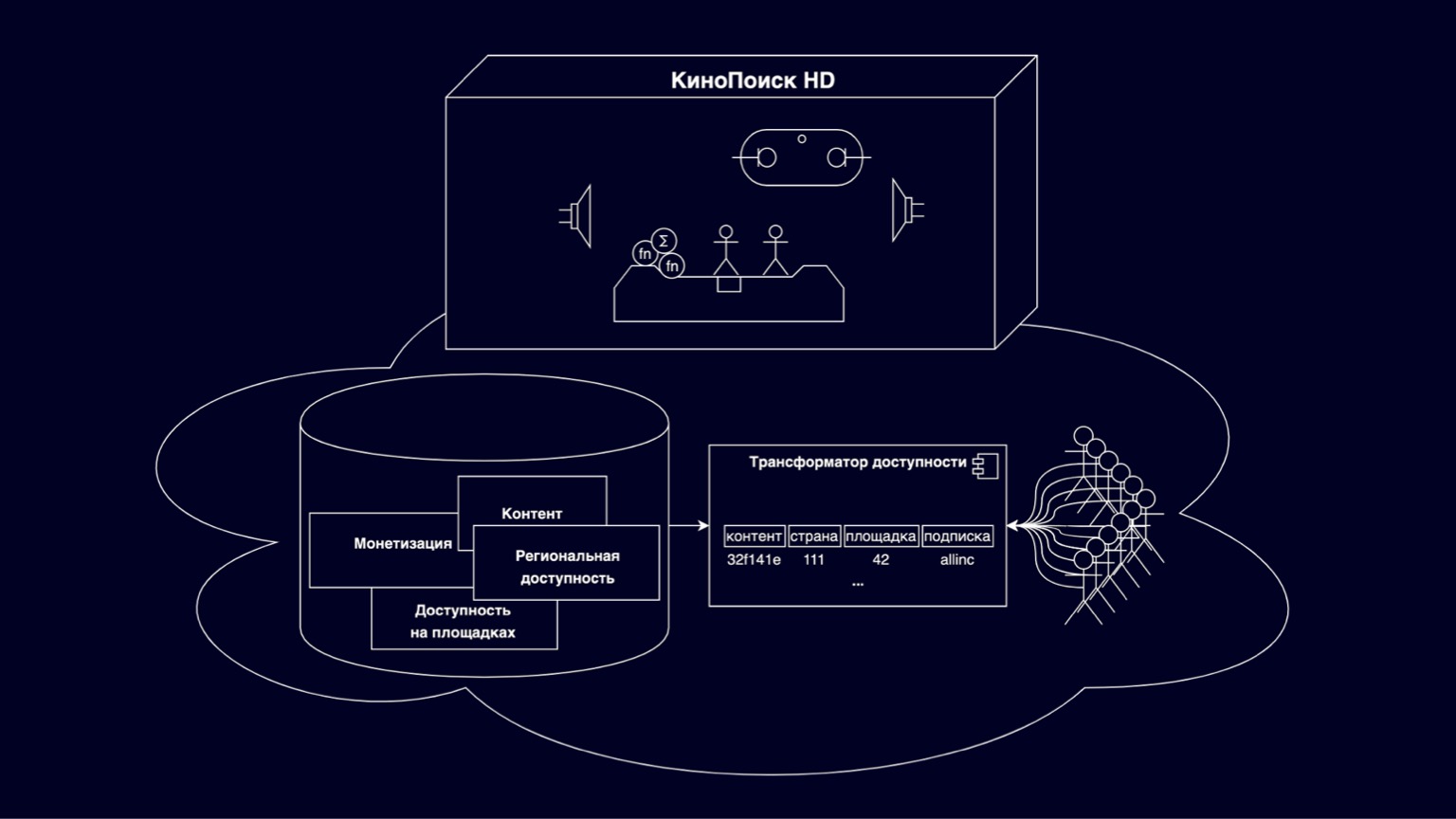
Vamos ver do que são feitos os cinemas online. No paralelepípedo KinoPoisk HD, todos os tipos de coisas legais e modos de visualização são implementados. Milhares de usuários RPS selecionam o conteúdo disponível nas vitrines, assinam e compram. Salve o progresso da navegação e as configurações do usuário. Milhares de RPS geram várias métricas. Este é um conjunto de componentes bastante grande e interessante, cujos detalhes não entraremos em detalhes hoje. Mas vale ressaltar que, em geral, são serviços bons e compreensivelmente escalonáveis - pelo fato de serem fragmentados pelos usuários.
Hoje vamos nos concentrar na nuvem embaixo da caixa. Esta é uma plataforma responsável por armazenar filmes, séries, várias restrições dos detentores de direitos autorais. Apoiado pelos esforços de vários departamentos. Parte desta plataforma é um transformador de acessibilidade que responde a perguntas que posso assistir neste momento neste local. Sem um transformador de acessibilidade, nenhum conteúdo aparecerá literalmente no KinoPoisk HD.
O desafio para o transformador é traduzir um modelo de acessibilidade flexível e em camadas em um modelo eficiente que se adapte ao maior número possível de consumidores de conteúdo.
Por que é flexível e escalonável? Principalmente porque inclui várias entidades que descrevem conteúdo, monetização, disponibilidade relacional e disponibilidade em sites. Tudo isso está nas relações revolucionárias, tem uma hierarquia complexa. E essa flexibilidade é necessária para atender aos requisitos de dezenas de detentores de direitos autorais e várias opções de preços flexíveis.
Por sites, queremos dizer, por exemplo, um cinema online na web, um cinema online em dispositivos e outros serviços OTT parceiros que também reproduzem nosso conteúdo.
É claro que para calcular com eficiência a disponibilidade de tal modelo multinível, você precisa construir junções complexas, e essas consultas não são escalonadas para qualquer carga, elas são bastante complexas na interpretação para construir alguma funcionalidade de forma rápida e clara nelas. Para resolver esses problemas, surgiu um transformador de acessibilidade, desnormalizando o modelo apresentado no slide como uma chave composta, que inclui IDs de conteúdo, países, sites, assinaturas e algum resíduo não chave invisível que compõe a maior parte da memória. Hoje vamos falar sobre as dificuldades de dimensionar o transformador de acessibilidade.
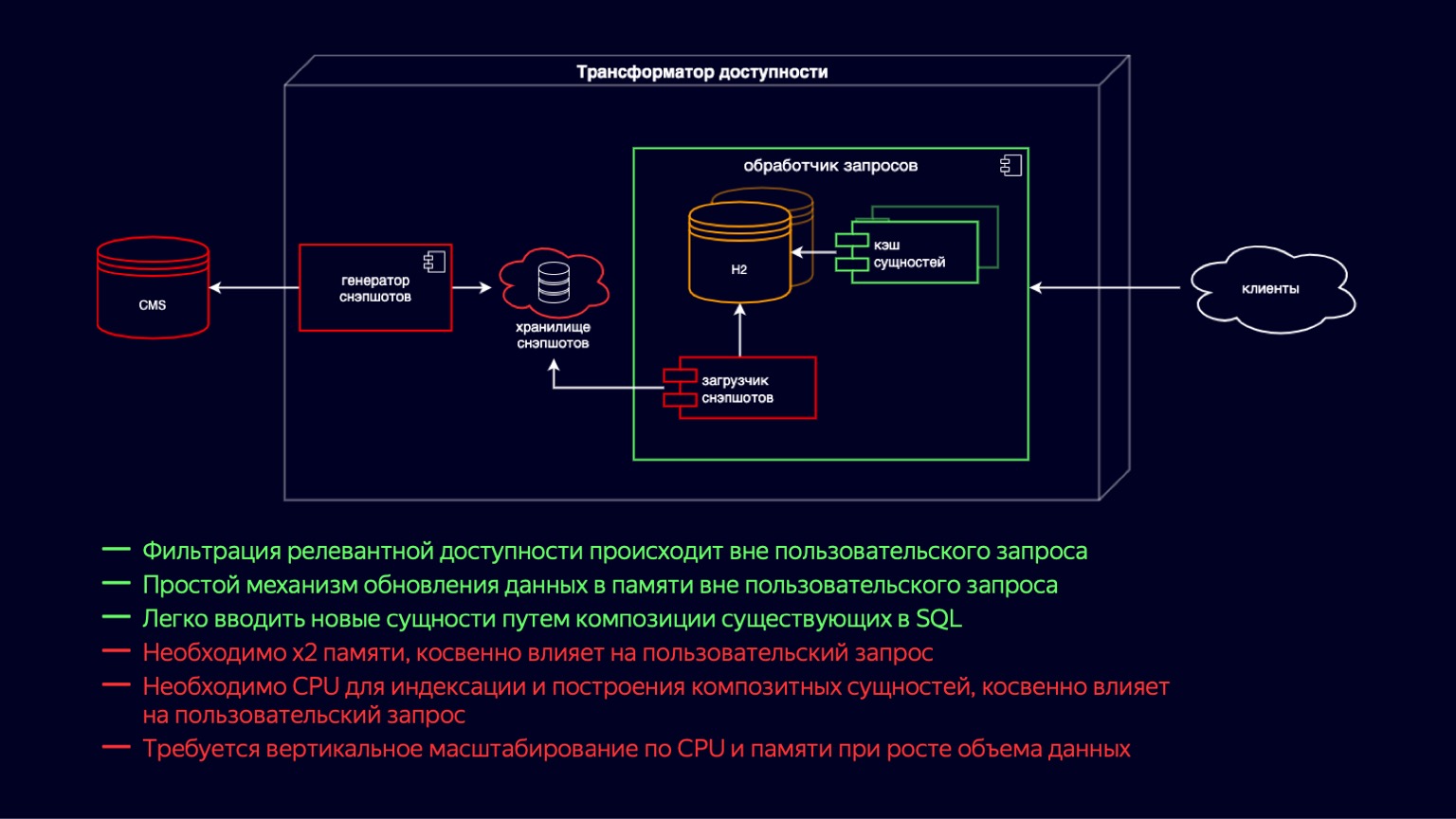
Vamos mergulhar mais fundo neste componente e ver em que consiste. Aqui, vemos o estado do sistema imediatamente antes do início do problema. Todo esse tempo, o transformador de acessibilidade tem se movido ao longo do caminho de desenvolvimento rápido do cinema online. Era importante lançar rapidamente novas funcionalidades, antes de mais nada, para garantir a disponibilidade de dezenas de milhares de filmes e séries de TV.
Se você for da esquerda para a direita, então há um CMS, um banco de dados relacional em que na terceira forma normal e em EAVnossas entidades principais são armazenadas. O próximo é o carregador de instantâneos. Além disso, o gerador de instantâneos, que recebe regularmente dados relevantes, os filtra e os adiciona ao armazenamento de instantâneos. Na verdade, este é um dump SQL. Mais dentro da instância do processador de solicitação, o Snapshot Loader recebe regularmente novos dados e os importa para H2. H2 é um banco de dados em memória escrito em Java que implementa os recursos básicos de um DBMS, ou seja, há um interpretador de consulta, um otimizador de consulta e índices.
Na verdade, este é exatamente o componente que fornece a flexibilidade para criar novas funcionalidades para um cinema online devido ao fato de que você pode simplesmente escrever consultas SQL e juntar entidades desnormalizadas de forma rápida e fácil.
H2 é atualizado em um modelo de cópia na gravação. O Snapshot Loader pega uma nova instância de banco de dados e a preenche. E então, após o enchimento, descarte o antigo utilizando a lixeira.
Simultaneamente com H2, o cache de entidade é gerado, o que inclui entidades compostas e um índice acima delas. As entidades compostas são essencialmente uma continuação da desnormalização do que está em H2 para acomodar as solicitações de latência mais exigentes dos clientes. As entidades de cache são atualizadas da mesma forma de acordo com o modelo copy-on-write, simultaneamente com a geração de novas instâncias H2.
As principais vantagens do sistema: você pode adicionar novas funcionalidades de maneira fácil e flexível usando joins. Um esquema relativamente simples para atualizar dados por cópia na gravação. A desvantagem é, obviamente, que leva x2 de memória para armazenar e atualizar essas entidades. Isso afeta indiretamente a solicitação do usuário à medida que é descartada pelo coletor de lixo.
Além disso, ao construir o cache de entidade, um recurso de CPU é necessário para a indexação. E isso também afeta indiretamente a solicitação do usuário, mas às custas da competição pelos recursos da CPU. Os dois pontos juntos levam ao fato de que, com o crescimento do volume de dados de nossas entidades principais, o processador de consultas precisa ser dimensionado verticalmente, tanto em termos de CPU quanto de memória.
Mas o sistema dependia de dezenas de milhares de filmes e séries de TV disponíveis online. Por isso, durante muito tempo, essas desvantagens foram aceitáveis, permitiram explorar a principal vantagem em termos de flexibilidade e facilidade de introdução de novas funções de um cinema online.
É claro que tudo isso funcionou até certo ponto. Imagine que este ônibus amarelo é nosso transformador de acessibilidade.

Abriga filmes e seriados reproduzidos por desnormalização, ou seja, são dezenas de milhares. E em uma das paradas, centenas de milhares de videoclipes e trailers precisam ser içados a bordo e colocados de alguma forma. Uma vez a bordo, eles também se multiplicarão devido à desnormalização. Aqueles que estão dentro precisam encolher, e aqueles que estão fora precisam pular, se espremer. Você pode imaginar como isso acontece. Tecnicamente, naquele momento, nossa capacidade de memória na instância cresceu para dezenas de gigabytes. A construção do cache e o descarte de instâncias antigas usando o coletor de lixo consumiram vários núcleos virtuais. E como a quantidade de dados cresceu dramaticamente, todo esse procedimento levou ao fato de que leva dezenas de minutos para publicar um novo conteúdo.
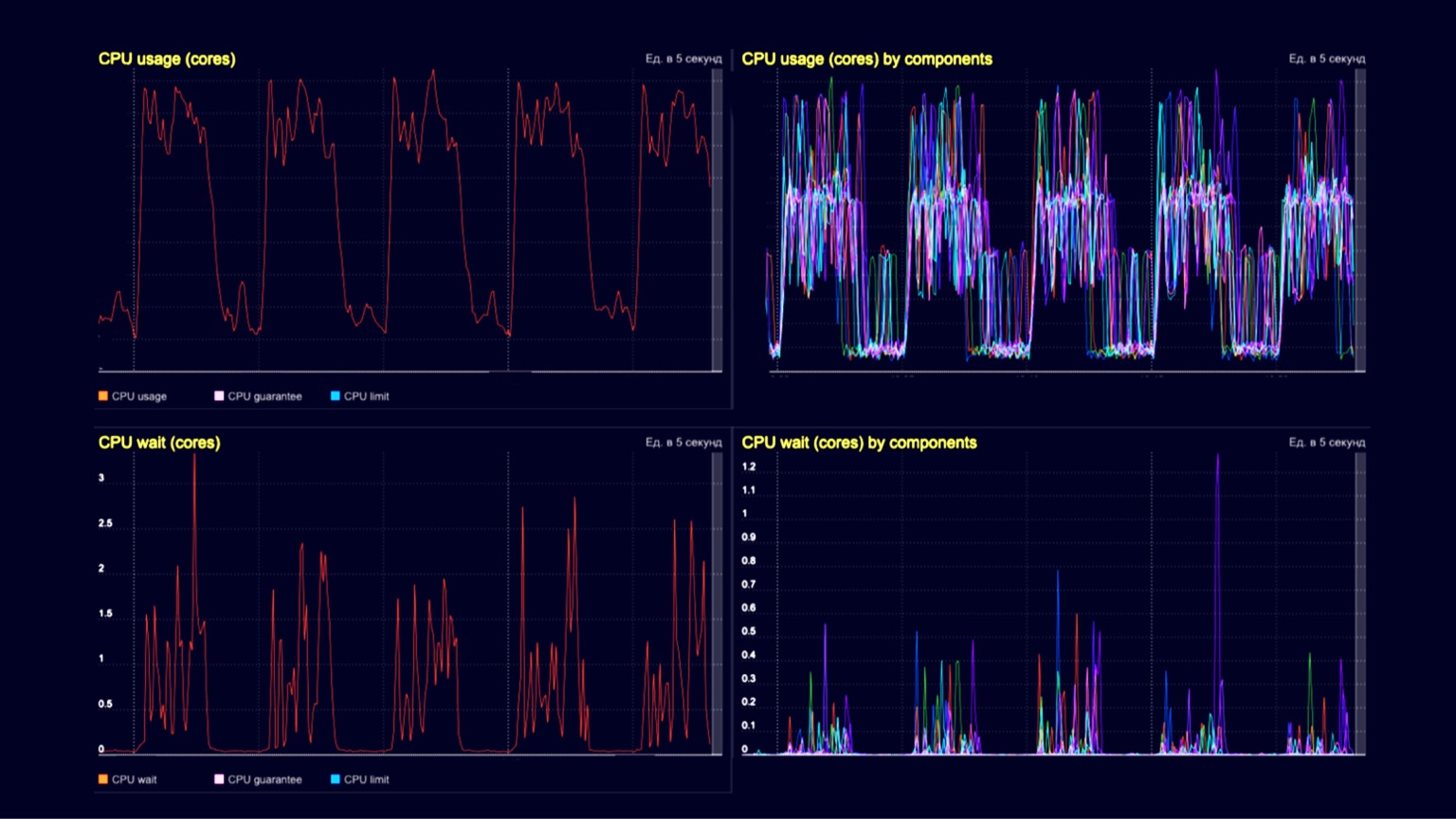
Tecnicamente, estamos vendo a utilização da CPU aqui em um cluster de processador de consulta. Nas trincheiras - o processamento de pedidos de clientes da ordem de vários milhares de RPS, e nas colinas - os mesmos vários milhares de RPS, mais o mesmo carregamento de instantâneos e seu descarte usando um coletor de lixo. Os dois gráficos inferiores são a espera da CPU no contêiner. Vemos que eles também começam a se manifestar no momento do download dos snapshots e do seu descarte.
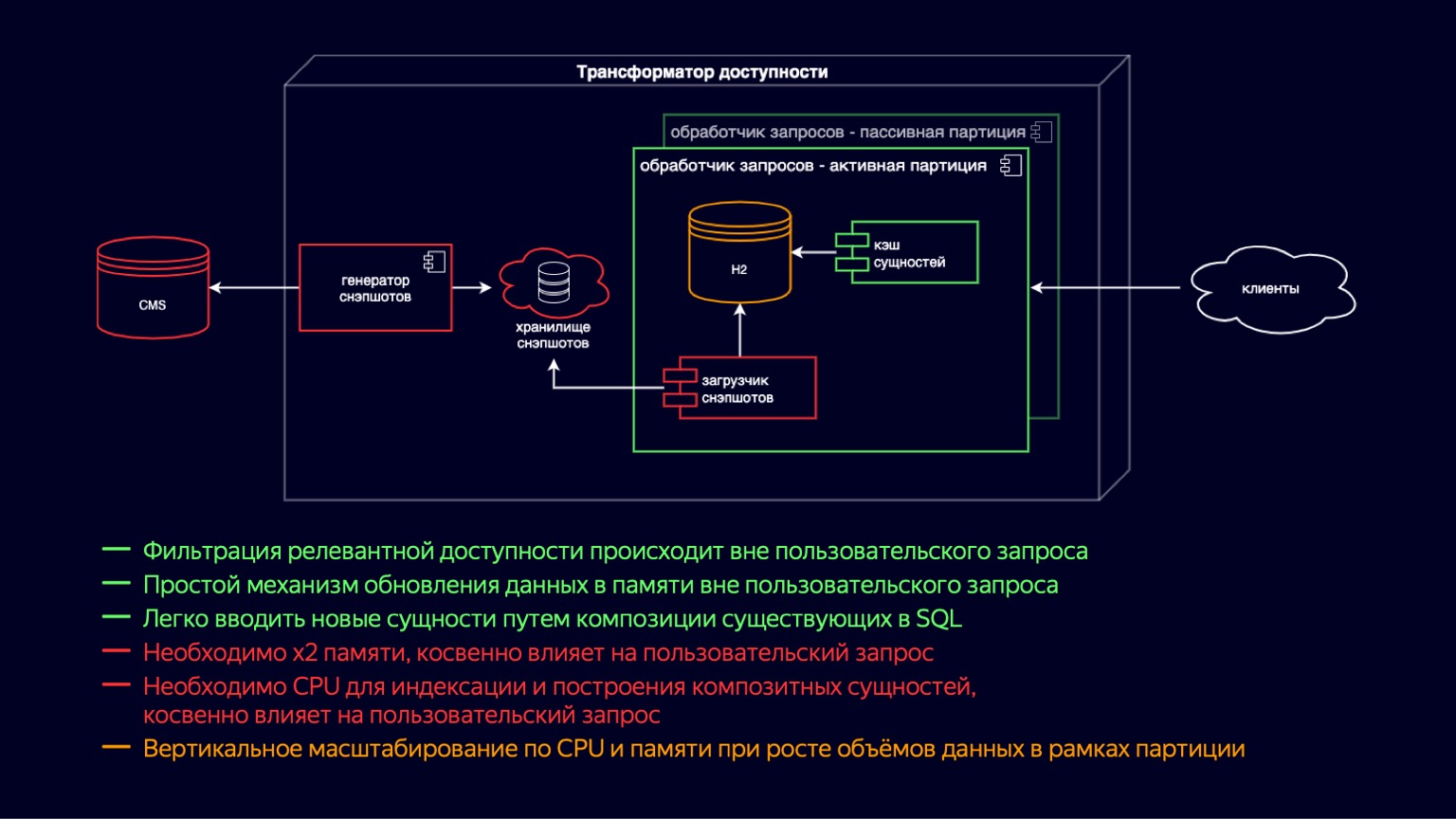
Para acomodar esses vídeos musicais e trailers e continuar a crescer, introduzimos instâncias de processador de solicitação ativa e passiva. Na verdade, esta é uma transferência de cópia na escrita para um nível acima. Agora temos instâncias ativas e passivas no contêiner. O passivo prepara o novo H2 e o cache de entidade, enquanto o ativo simplesmente processa as solicitações do usuário. Assim, reduzimos o impacto da coleta de lixo e suas pausas no processamento das solicitações do usuário. Mas, ao mesmo tempo, como eles ainda vivem no mesmo contêiner, o carregamento de instantâneos e a construção de cache ainda competem por recursos da CPU, e o impacto nas solicitações do usuário ainda está presente.
Além disso, introduzimos o particionamento por site. Isso nos proporcionou uma redução na memória dos sites onde todos esses novos tipos de conteúdo não são necessários. Por exemplo, isso permitiu que um cinema online não baixasse videoclipes e trailers e reduzisse o impacto. Mas, ao mesmo tempo, para sites que precisam fornecer todo o conteúdo com acessibilidade, é claro, nada mudou.
Portanto, os prós e os contras do esquema permaneceram os mesmos de antes. Mas, devido ao particionamento, o dimensionamento vertical em termos de CPU e memória foi movido para sites, e isso permitiu que alguns sites continuassem a ser dimensionados. Em comparação com o esquema anterior de publicação de conteúdo, isso não mudou de forma alguma. Geralmente, levava as mesmas dezenas de minutos, então continuamos procurando maneiras de otimizá-lo.

O que nós entendemos naquela época? Essas consultas de cinema online usam uma pequena parte dos recursos do DBMS. O intérprete e otimizador de consulta degenerou ao longo do tempo em um cache de entidade. Percebemos que a definição de acessibilidade é amplamente universal. As consultas diferem porque você precisa entender a disponibilidade de uma unidade de conteúdo ou lista e adicionar atributos adicionais a essa disponibilidade. Em geral, isso pode ser feito sem um DBMS completo.
E, em segundo lugar, uma parte da chave composta são os parâmetros cardinais baixos. Existem dezenas de países, no limite de algumas centenas, dezenas de sites e apenas algumas assinaturas. Provavelmente, a desnormalização completa não é necessária. Essas duas descobertas nos levaram a avançar para uma representação na memória mais compacta e menos desnormalizada, mas que ainda responde rapidamente às solicitações do usuário.

No slide, vemos a transição do transformador de disponibilidade v1 para v2. Aqui está um esquema de um novo esquema de acessibilidade, onde a chave composta realmente se resume a ser apenas uma chave de ID de conteúdo. E a acessibilidade, física ou lógica, se resume a determinar a disponibilidade por listas de países, sites e assinaturas.
Assim, reduzimos a quantidade de resto de não chave invisível, que compõe a maior parte da memória, e reduzimos a quantidade de memória ao mesmo tempo.
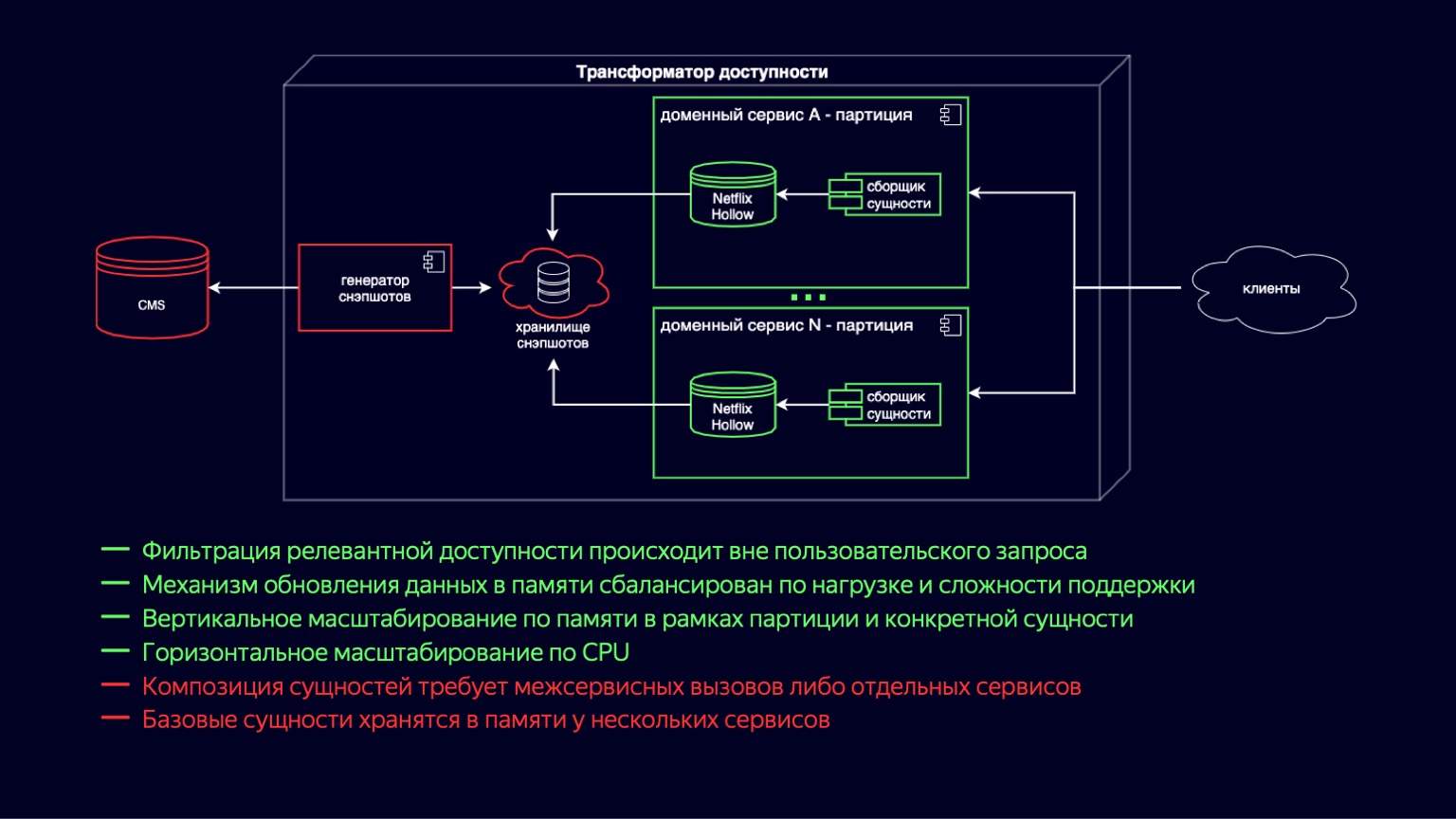
Aqui, vemos o processo de mudança para o novo circuito do transformador de acessibilidade. O Netflix Hollow desempenha o papel de provedor e indexador de entidades básicas, sobre as quais os serviços de domínio coletam montagens de entidades compostas de diferentes escalas em tempo real. Isso funciona porque as entidades subjacentes ainda são desnormalizadas e o número de junções é mínimo durante a construção. Por outro lado, determinar a disponibilidade se resume a ciclos simples e baratos e não deve ser difícil.
Ao mesmo tempo, o Netflix Hollow armazena e trata com bastante cuidado a carga na CPU e a coleta de lixo, tanto durante a atualização dos dados quanto durante o acesso a eles. Isso nos permite reduzir as colinas que vimos nos gráficos de utilização da CPU e mantê-las em um mínimo aceitável. Além disso, como ele implementa um esquema de entrega híbrido na forma de instantâneos e diffs para eles, pode aumentar a velocidade de publicação de novo conteúdo em até alguns minutos.
É claro que a maioria das vantagens do esquema anterior foram preservadas. O mecanismo de atualização de dados na memória tornou-se mais simples e barato em termos de utilização de recursos. O dimensionamento vertical por partições, por sites também foi complementado com o dimensionamento para uma entidade específica, agora é mais barato. E como reduzimos a sobrecarga de atualização das cópias do Snapshot, houve um dimensionamento verdadeiramente horizontal na CPU.
A desvantagem desse esquema é que a composição da entidade requer chamadas entre serviços ou serviços separados. E ainda há duplicação de dados no nível da entidade base, uma vez que agora são armazenados em todos os serviços de domínio onde são usados. Mas o Netflix Hollow armazena dados de forma mais compacta do que H2, e H2 os armazena de forma muito mais compacta do que HashMap com objetos. Portanto, esse sinal de menos definitivamente também é considerado aceitável e permite que você olhe para o futuro com otimismo.

Este slide é capaz de carregar até água da torneira com otimismo. Porque escalar para novos países não é mais um fator multiplicador da memória - nem escalar para novos locais. Devido ao particionamento, ele é convertido em escala horizontal.
Bem, o dimensionamento de novos usuários e a expansão da funcionalidade de cinema online se resumem a um aumento na carga. Para fornecê-lo, estamos prontos para disponibilizar quantos serviços leves vinculados à CPU forem necessários. Por outro lado, acumulamos conhecimentos suficientes na área da acessibilidade para enfrentar novos desafios com confiança. Espero ter podido compartilhar alguns desses conhecimentos com você. Obrigado pela atenção.