
Neste artigo vou explicar:
- que tipo de besta é este Airflow, em quais componentes ele consiste e como eles interagem entre si
- sobre as principais entidades do Airflow: pipelines chamados DAG, Operator e mais algumas coisas
- como ter sucesso no desenvolvimento no Airflow
- como implementamos a geração de pipelines e a chamada "escrita declarativa de pipelines"
- sobre os prós e contras de usar o Airflow
O que é Airflow
Airflow é uma plataforma para criar, monitorar e orquestrar pipelines. Este projeto de código aberto, escrito em Python, foi criado em 2014 na Airbnb. Em 2016, o Airflow ficou sob a proteção da Apache Software Foundation, passou por uma incubadora e, no início de 2019, tornou-se um projeto Apache de nível superior.
No mundo do processamento de dados, alguns chamam de ferramenta ETL, mas isso não é exatamente ETL no sentido clássico, como Pentaho, Informatica PowerCenter, Talend e outros como eles. O Airflow é um orquestrador, “cron com baterias”: ele não faz o trabalho pesado de transferência e processamento de dados, mas diz a outros sistemas e estruturas o que fazer e monitora o status de execução. Nós o usamos principalmente para executar consultas em jobs Hive ou Spark.
Spoiler
Airflow, worker ( ), . , , .
A gama de tarefas resolvidas com o Airflow não se limita a executar algo em um cluster Hadoop. Ele pode executar código Python, executar comandos Bash, hospedar contêineres Docker e pods no Kubernetes, executar consultas em seu banco de dados favorito e muito mais.
Arquitetura Airflow
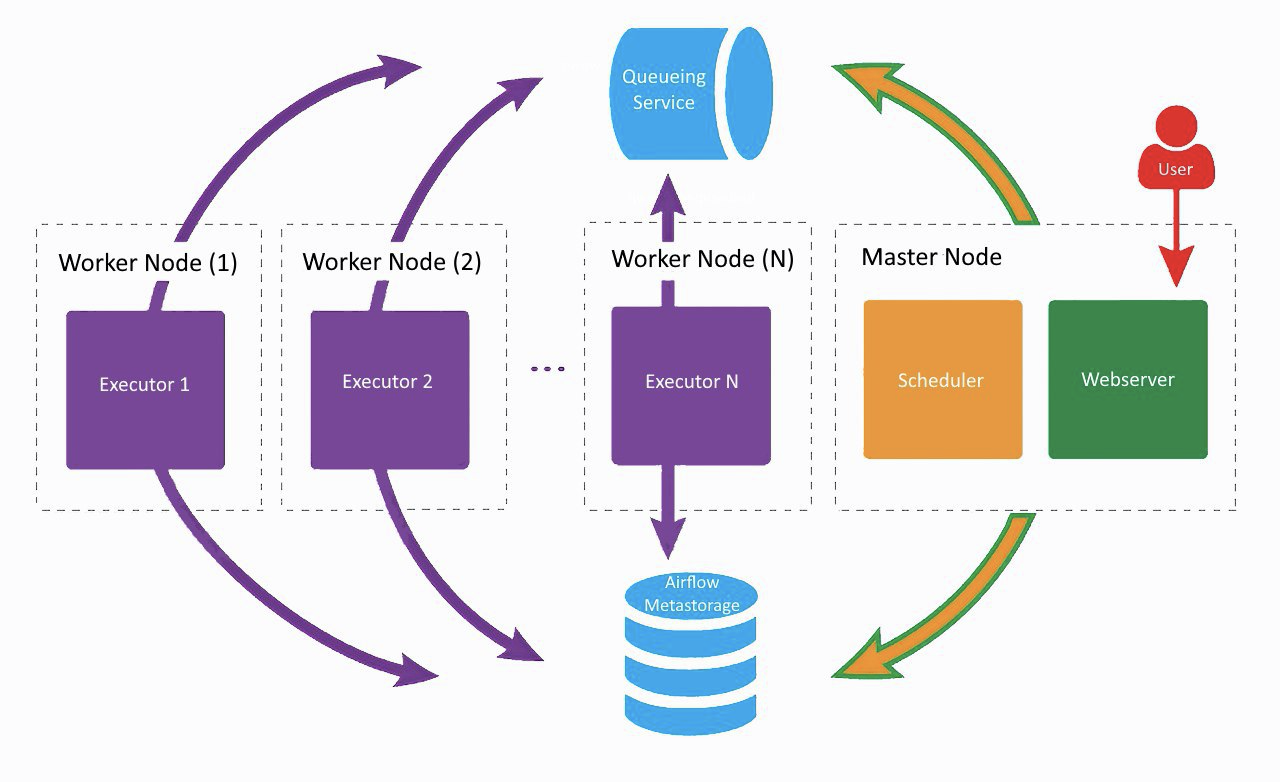
Esta é aproximadamente a aparência de nossa configuração atual do Airflow, apenas Lamoda usa dois trabalhadores. Em uma máquina separada, o servidor web e o agendador estão girando, os trabalhadores estão bufando nos vizinhos. Um foi criado para tarefas regulares, o segundo foi adaptado para executar o treinamento de modelos de ML usando Vowpal Wabbit. Todos os componentes se comunicam entre si por meio de uma fila de tarefas e uma base de metadados.
No início do desenvolvimento do Airflow na empresa, todos os componentes (exceto o banco de dados) trabalhavam na mesma máquina, mas em algum momento isso gerou falta de recursos no servidor e atrasos na operação do planejador. Portanto, decidimos distribuir os serviços para diferentes servidores e chegamos à arquitetura mostrada na imagem acima.
Componentes de fluxo de ar
Webserver
Webserver é uma interface da web que mostra o que está acontecendo com o pipeline. Esta página é
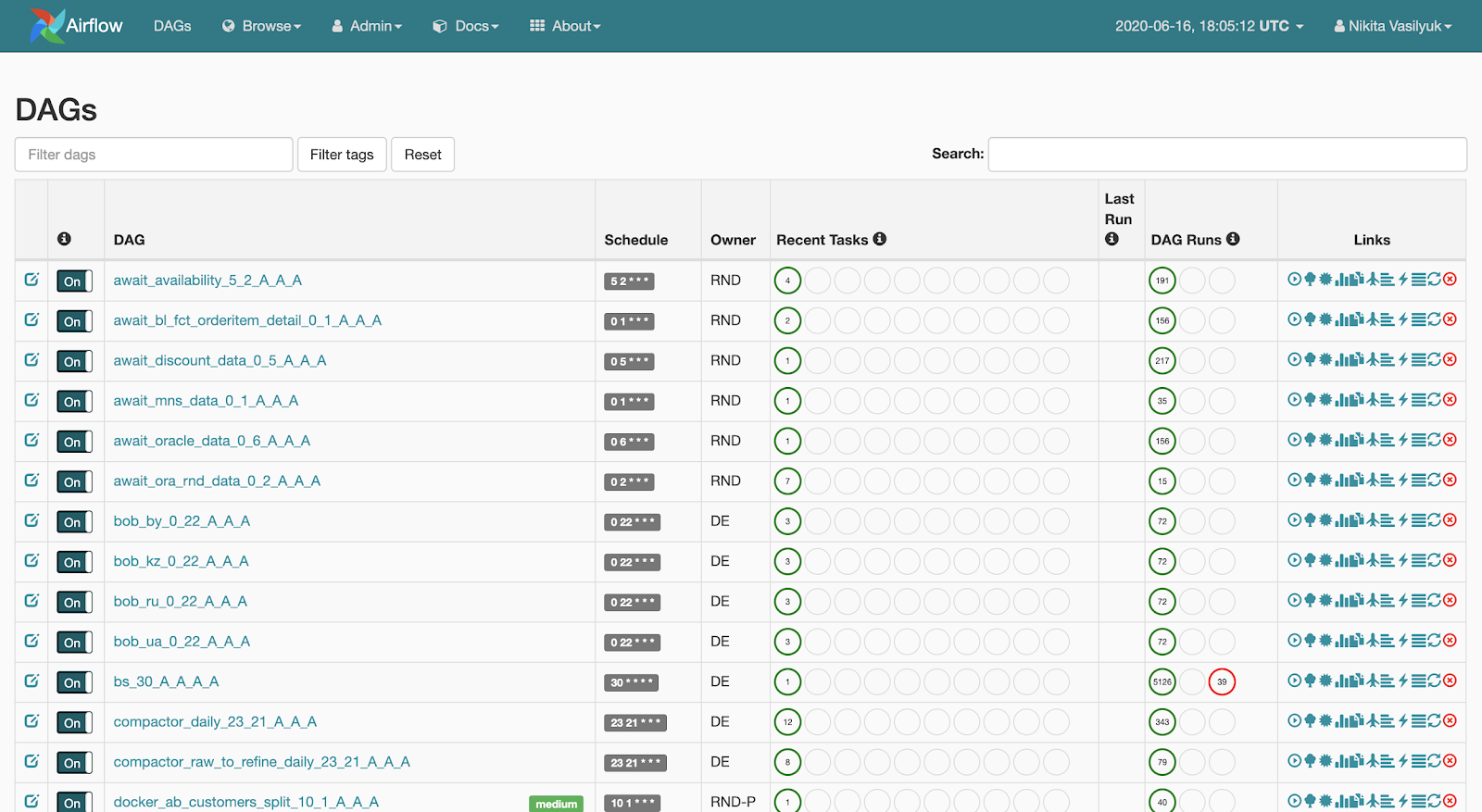
visível para o usuário: O servidor web permite visualizar a lista de pipelines disponíveis. Breves estatísticas de lançamentos são exibidas ao lado de cada pipeline. Existem também vários botões que ativam o pipeline com força ou mostram informações detalhadas: estatísticas de lançamento, o código-fonte do pipeline, sua visualização em forma de gráfico ou tabela, uma lista de tarefas e o histórico de seus lançamentos.
Se clicarmos no pipeline, passaremos pelo menu Graph View. Tarefas e links entre eles são exibidos aqui.
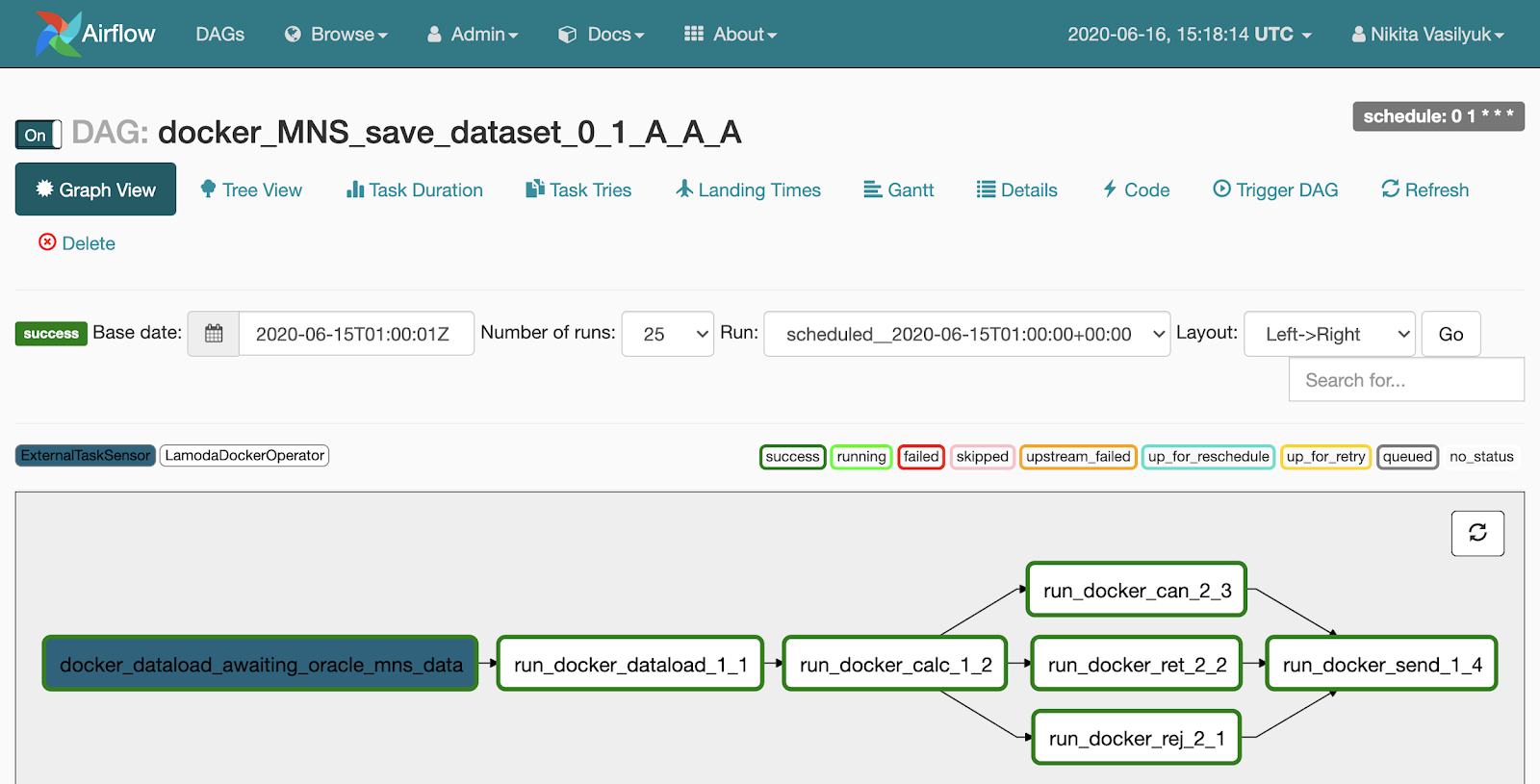
Há um menu Tree View próximo à Graph View. Ele foi criado para reiniciar tarefas, visualizar estatísticas e logs. A visualização em árvore do gráfico é exibida no lado esquerdo, do lado oposto é uma tabela com o histórico de lançamento de tarefa.
Cada linha desta tabela assustadora é uma tarefa, cada coluna é um início do pipeline. Em seu cruzamento existe uma praça com o lançamento de uma tarefa específica para uma data específica. Se você clicar nele, aparecerá um menu onde você pode ver informações detalhadas e logs desta tarefa, iniciá-la ou reiniciá-la, e também marcá-la como bem ou malsucedida.

Scheduler - como o nome indica, lança pipelines quando chega a hora. É um processo Python que vai periodicamente para o diretório com pipelines, puxa seu estado atual de lá, verifica o status e o inicia. Em geral, Scheduler é o mais interessante e ao mesmo tempo o gargalo da arquitetura do Airflow.
- A primeira ressalva é que apenas uma instância do Scheduler pode estar em execução por vez. Isso significa que no momento é impossível operar em alta disponibilidade (os desenvolvedores estão planejando adicionar Scheduler HA ao Airflow versão 2.0).
- : , - . , - , .
Até algum tempo, o atraso é ajustado pelos parâmetros do arquivo de configuração do Airflow, mas o atraso de inicialização ainda permanece. Conclui-se que o Airflow não se trata de processamento de dados em tempo real. Se você agir inadvertidamente e especificar um intervalo de inicialização muito frequente (uma vez a cada dois minutos), poderá ocorrer um atraso no pipeline. A experiência mostra que uma vez a cada 5 minutos já é bastante frequente, e alguns não recomendam executar o pipeline a cada 10 minutos. Temos alguns pipelines que começam a cada 10 minutos, eles são muito simples e até agora não houve problemas com eles.
Worker
Worker é onde nosso código é executado e as tarefas são realizadas. O Airflow oferece suporte a vários executores:
- O primeiro, o mais simples, é o SequentialExecutor. Ele inicia tarefas de entrada sequencialmente e pausa o agendador durante sua execução.
- LocalExecutor , , LocalExecutor . : - SQLite, LocalExecutor SequentialExecutor.
- CeleryExecutor , . Celery – , RabbitMQ Redis. , .
- DaskExecutor Dask – .
- KubernetesExecutor pod Kubernetes.
- DebugExecutor IDE.
Entidades Apache Airflow
Pipeline ou DAG
A essência mais importante do Airflow é o DAG, também conhecido como pipeline, também conhecido como gráfico acíclico direcionado. Para deixar mais claro como cozinhar e por que você precisa, analisarei um pequeno exemplo.
Digamos que um analista venha até nós e nos peça para preencher os dados em uma determinada tabela uma vez por dia. Ele preparou todas as informações: o que obter de onde, quando começar, com qual SLA. Aqui está um exemplo de como podemos descrever nosso pipeline.
dag = DAG(
dag_id="load_some_data",
schedule_interval="0 1 * * *",
default_args={
"start_date": datetime(2020, 4, 20),
"owner": "DE",
"depends_on_past": False,
"sla": timedelta(minutes=45),
"email": "<your_email_here>",
"email_on_failure": True,
"retries": 2,
"retry_delay": timedelta(minutes=5)
}
)
O dag_id contém o nome exclusivo do pipeline. Em seguida, usamos schedule_interval para especificar a freqüência com que deve ser executado.
Ponto muito importante: como o Airflow foi desenvolvido por uma empresa internacional, ele só funciona na UTC. No momento, não existe uma maneira sensata de fazer o Airflow funcionar em um fuso horário diferente, então você precisa se lembrar constantemente da diferença entre nosso fuso horário e o UTC. Na versão 1.10.10, tornou-se possível alterar o fuso horário na IU, mas isso só se aplica à interface da web, os pipelines ainda serão executados em UTC.
O parâmetro default_args é um dicionário que descreve os argumentos padrão para todas as tarefas dentro deste pipeline. Os nomes da maioria dos parâmetros se descrevem bem, não vou me alongar sobre eles.
Operador
Um operador é uma classe Python que descreve quais ações precisam ser executadas em nossas tarefas diárias para encantar o analista.
Podemos usar o HiveOperator, que, estranhamente, é projetado para enviar solicitações de execução ao Hive. Para iniciar o operador, você precisa especificar o nome da tarefa, o pipeline, o ID da conexão com o Hive e a solicitação que está sendo executada.
run_sql = HiveOperator(
dag=dag,
task_id="run_sql",
hive_cli_conn_id="hive",
hql="""
INSERT OVERWRITE TABLE some_table
SELECT * FROM other_table t1
JOIN another_table t2 on ...
WHERE other_table.dt = '{{ ds }}'
"""
)
notify = SlackAPIPostOperator(
dag=dag,
task_id="notify_slack",
slack_conn_id="slack",
token=token,
channel="airflow_alerts",
text="Guys, I'm done for {{ ds }}"
)
run_sql >> notify
Há um pedaço do modelo Jinja na solicitação que passamos ao construtor do operador. Jinja é uma biblioteca de modelos Python.
Cada lançamento de pipeline armazena informações sobre a data de lançamento. Encontra-se em uma variável chamada data_de_execução. {{ds}} é uma macro que pegará apenas a data no formato% Y-% m-% d em run_date. Em um determinado momento antes de iniciar o operador, o Airflow renderizará uma string de consulta, substituirá a data exigida ali e enviará uma solicitação de execução.
ds não é a única macro, existem cerca de 20 delas (uma lista de todas as macros disponíveis) . Eles incluem formatos de data diferentes e algumas funções para trabalhar com datas - adicionar ou subtrair dias.
Quando conheci o Airflow, não entendi por que todos os tipos de macros são necessários, quando você pode simplesmente inserir uma chamada datetime.now () lá e aproveitar a vida. Mas, em alguns casos, isso pode arruinar muito a vida de nós e do analista. Por exemplo, se quisermos recalcular algo para alguma data no passado, o Airflow substituirá ali não a data de início do pipeline, mas o tempo de execução real. E, em alguns casos, podemos não obter o que esperamos.
Por exemplo, se quisermos reiniciar o pipeline para a última terça-feira, ao usar datetime.now (), iremos recalcular o pipeline para hoje, e não para a data necessária. Além disso, os dados de hoje podem nem estar prontos neste momento.
Após completar a solicitação com sucesso, podemos enviar uma notificação para slack sobre o carregamento de dados. Em seguida, comandamos o Airflow, em que ordem iniciar as tarefas. Graças à sobrecarga do operador no Airflow, posso usar facilmente o operador >> para especificar a ordem das etapas no pipeline. No meu exemplo, dizemos que primeiro começaremos a executar a solicitação e, em seguida, enviaremos uma notificação ao slack.
Idempotência
É impossível falar sobre o Airflow sem mencionar a idempotência. Por precaução, deixe-me lembrá-lo: idempotência é uma propriedade de um objeto, quando você reaplica uma operação a um objeto, sempre retorna o mesmo resultado.
No contexto do Airflow, isso significa que se hoje é sexta-feira e reiniciarmos a tarefa na terça-feira passada, a tarefa será iniciada como se fosse na última terça-feira e nada mais. Ou seja, o lançamento ou reinício de uma tarefa para alguma data no passado não deve depender de forma alguma de quando essa tarefa foi realmente lançada. A idempotência é implementada usando a variável running_date mencionada anteriormente.
O Airflow foi desenvolvido como uma ferramenta para resolver tarefas de processamento de dados. Nesse mundo, geralmente processamos uma grande quantidade de dados apenas quando eles estão prontos, ou seja, no dia seguinte. E os criadores do Airflow estabeleceram originalmente esse conceito em seus produtos.
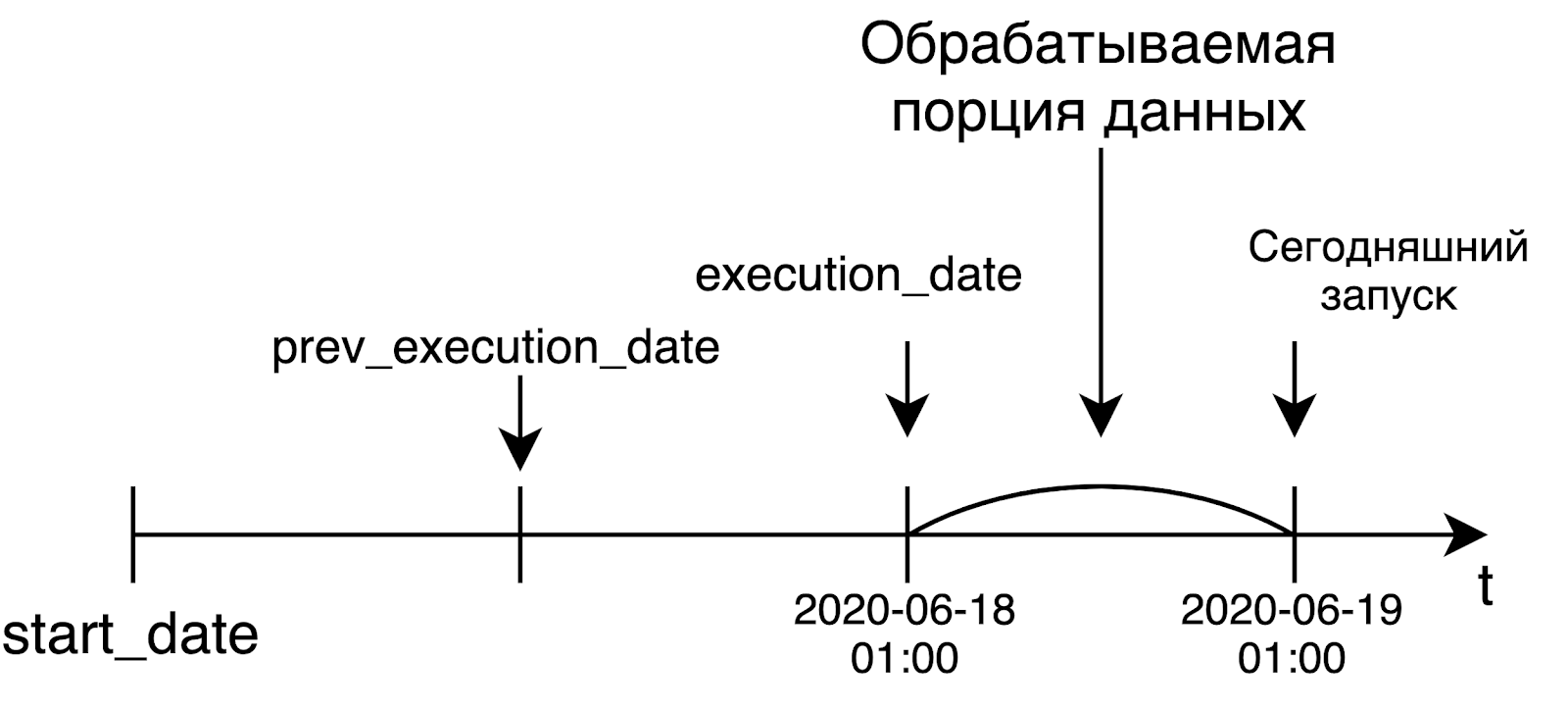
Quando lançarmos um pipeline diário, provavelmente desejaremos processar os dados de ontem. É por isso que running_date será igual à borda esquerda do intervalo para o qual processamos os dados. Por exemplo, o lançamento de hoje, que começou à 1h UTC, receberá a data de ontem como data_de_execução. No caso de um pipeline de hora em hora, a situação é a mesma: para iniciar o pipeline às 6h, o tempo em running_date será igual a 5h. Esta ideia não é muito óbvia no início, mas, no entanto, é muito significativa e importante.
Operadores mais comuns do Airflow
No Airflow, não existem apenas operadores que vão ao Hive e mandam algo para o vazio. Na verdade, existem muitos operadores por aí. No artigo, destaquei os mais populares e úteis.
- BashOpetator e PythonOperator. Tudo é claro com eles: eles enviam um comando bash e uma função python para execução, respectivamente.
- Há uma grande variedade de operadores para enviar consultas a vários bancos de dados. Postgres padrão, MySQL, Oracle, Hive, Presto são suportados. Se por algum motivo não houver um operador para seu banco de dados favorito, você pode usar um JdbcOperator mais geral ou escrever o seu próprio, o Airflow permite isso.
- Sensor – , . , - . , , . , : 3 , . . , , .
- BranchPythonOperator – , , python , , .
- DockerOpetator Docker- . , Docker- , . , .
- KubernetesPodOperator pod Kubernetes.
- DummyOperator , .
Lamoda
- – LamodaDockerOperator. , : - Hadoop, . LamodaDockerOperator Spark- , python.
- LamodaHiveperator – , . Hive. , - , , . , , HiveCliHook HiveServer2Hook, .
- – ExternalTaskSensor. . , Hadoop . , , , - , , . , - HDFS, Airflow.
- BashOperator, PythonOperator – , bash- python .
- , . - , .
Airflow
- Variables – , , , . , . , Hive, HDFS, . dev- prod-, .
- Connections – , . Airflow : http ftp, .
- Hooks – , .
- SLA -. , . SLA , , - - . - : - , Airflow .
- – XCom, cross-communication. : , json-. – 48 .
- – , . , . , 5, , , , .

Além disso, você pode ver como a duração das tarefas mudou durante o dia. Em nosso caso, este é o processo de transferência de dados do Kafka para o Hive com verificação da qualidade dos dados. Além disso, você pode rastrear quando a tarefa, por algum motivo, demorou mais do que o normal.

Como ter sucesso no desenvolvimento de fluxo de ar
Abaixo estão algumas dicas para ajudá-lo a evitar levar um tiro no pé ao usar o Airflow:
- É útil manter cada pipeline (ou gerador de pipeline, mais sobre isso abaixo) em um arquivo separado. Eu sei imediatamente qual arquivo preciso acessar para examinar o pipeline ou gerador necessário.
- , , . , -, . , - , . : , , .
- – schedule_interval start_date dag_id. , Airflow , - -. DAGS , Scheduler, . , , dag_id. , .
- catchup. True, Airflow , start_date . , . False Airflow . , Airflow True ( -).
- – . , python , airflow DAG, , DAG. . , , . REST API, requests.get() .
:
Desde o início do uso do Airflow, mantivemos as configurações do pipeline separadas do código. Inicialmente, isso ocorreu devido às peculiaridades do esquema de implantação, mas aos poucos essa abordagem foi se enraizando. E agora usamos configs sempre que houver uma sugestão de clichê. Isso se refere especialmente a jobs do Spark que executamos no Docker. Daí veio a história com a escrita declarativa de pipelines.
A abordagem é que temos um diretório com configs. Cada arquivo de configuração contém um ou vários pipelines com sua descrição: como devem funcionar, quando iniciar, quais tarefas estão nele e em que ordem devem ser realizadas.
Vou mostrar como é o código para chamar nosso gerador de pipeline. Na entrada, ele recebe um diretório com configs, um prefixo e uma classe que será responsável por preencher o pipeline de tarefas. Nos bastidores, o gerador vai para o diretório especificado, encontra os arquivos de configuração lá e cria tarefas nesses arquivos para cada pipeline e os vincula.
from libs.dag_from_config.dag_generator import DagGenerator
from libs.runners.docker_runner import DockerRunner
generator = DagGenerator(config_dir='dag_configs/docker_runner', prefix='docker')
dags = generator.generate(task_runner=DockerRunner)
for dag in dags:
globals()[dag.dag_id] = dag #
Esta é a aparência de um arquivo de configuração típico. Para descrever as configurações, usamos o formato HOCON , que é um superconjunto de JSON. Ele suporta a importação de outros arquivos HOCON e pode se referir aos valores de outras variáveis.
Na configuração no nível do pipeline (bloco de atribuição), você pode especificar muitos parâmetros, mas os mais importantes são name, start_date e schedule_interval.
docker_image = "docker_registry/attribution/calculation:1.1.0"
dags {
attribution {
owner = "RND"
name = "attribution"
start_date = "20190601"
emails = [...]
schedule_interval = "0 1 * * *"
depends_on_past = true
concurrency = 4
description = """
- z_log
-
- ,
-
"""
tags = ["critical"]
Aqui você pode especificar a simultaneidade - quantas tarefas serão executadas simultaneamente em uma execução. Recentemente, adicionamos um bloco com uma breve descrição de redução do pipeline aqui. Em seguida, ele, junto com o resto das informações sobre o pipeline, irá para o Confluence (implementamos o envio usando o Foliant ). Ficou superconveniente: desta forma, economizamos tempo para desenvolvedores experientes criarem páginas no Confluence.
Em seguida, vem a parte responsável pela formação das tarefas. Primeiro, no bloco de conexões, indicamos de qual conexão no Airflow precisamos tomar parâmetros para conectar a uma fonte externa - no exemplo, este é nosso DWH.
docker {
connections {
LMD_DWH = "dwh"
}
containers {
desktop {
image = ${docker_image}
connections = [LMD_DWH]
environment {
LMD_YARN_QUEUE = "{{ var.value.YARN_QUEUE }}"
LMD_INSTANCES = 60
LMD_MEMORY_PER_INSTANCE = "4g"
LMD_ZLOG_SOURCE = "z_log_db.z_log"
LMD_ATTRIBUTION_TABLE = "{{ var.value.HIVE_DB_DERIVATIVES }}.z_log_attribution"
LMD_ORDERS_TABLE = "rocket_dwh_bl.fct_orderitem_detail"
LMD_PLATFORMS = "desktop"
LMD_RUN_DATE = "{{ ds_nodash }}"
}
}
mobile {...}
iOS {...}
Android {...}
}
tasks = [[desktop, mobile, iOS, Android]]
}
Todas as informações necessárias, como usuário, senha, URL e assim por diante, serão encaminhadas para o contêiner do docker como variáveis de ambiente. No bloco Containers, indicamos quais tarefas iremos lançar. Dentro, está o nome da imagem, uma lista de conexões usadas e uma lista de variáveis de ambiente.
Você pode notar que os modelos Jinja aparecem nos valores de algumas variáveis de ambiente. Para especificar uma fila no YARN, usamos a sintaxe padrão do Airflow para recuperar os valores das variáveis. Para indicar a data de lançamento, usamos a macro {{ds_nodash}}, que representa a data de sua execução_data sem hífens. A configuração contém mais 3 tarefas semelhantes, elas estão ocultas para maior clareza.
A seguir, usando tarefas, indicamos como essas tarefas serão iniciadas. Você notará que eles estão listados como uma lista em uma lista. Isso significa que todas as 4 tarefas serão executadas em paralelo umas com as outras.
E uma última coisa: especificamos de quais pipelines base nosso DAG atual depende. Números e letras estranhos no final dos nomes dos dags básicos são a programação que incorporamos ao nome do pipeline. Portanto, nosso pipeline começará a ser preenchido somente depois que os dags básicos e as tarefas neles especificadas forem concluídas.
awaits {
z_log_compaction {
dag = "compactor_daily_23_21_A_A_A"
task = "compact_z_log_db_z_log"
timedelta = 3hr37m
}
oracle_bl_fct_orderitem_detail {
dag = "await_bl_fct_orderitem_detail_0_1_A_A_A"
}
}
}
}
Texto completo do arquivo de configuração
docker_image = "docker_registry/attribution/calculation:1.1.0"
dags {
attribution {
owner = "RND"
name = "attribution"
start_date = "20190601"
emails = [...]
schedule_interval = "0 1 * * *"
depends_on_past = true
concurrency = 4
description = """
- z_log
-
- ,
-
"""
tags = ["critical"]
docker {
connections {
LMD_DWH = "dwh"
}
containers {
desktop {
image = ${docker_image}
connections = [LMD_DWH]
environment {
LMD_YARN_QUEUE = "{{ var.value.YARN_QUEUE }}"
LMD_INSTANCES = 60
LMD_MEMORY_PER_INSTANCE = "4g"
LMD_ZLOG_SOURCE = "z_log_db.z_log"
LMD_ATTRIBUTION_TABLE = "{{ var.value.HIVE_DB_DERIVATIVES }}.z_log_attribution"
LMD_ORDERS_TABLE = "rocket_dwh_bl.fct_orderitem_detail"
LMD_PLATFORMS = "desktop"
LMD_RUN_DATE = "{{ ds_nodash }}"
}
}
mobile {...}
iOS {...}
Android {...}
}
tasks = [[desktop, mobile, iOS, Android]]
}
awaits {
z_log_compaction {
dag = "compactor_daily_23_21_A_A_A"
task = "compact_z_log_db_z_log"
timedelta = 3hr37m
}
oracle_bl_fct_orderitem_detail {
dag = "await_bl_fct_orderitem_detail_0_1_A_A_A"
}
}
}
}
Isso é o que obtemos após a geração:
- 2 pontos no bloco awaits transformados em dois sensores que aguardam a execução do pipeline básico,
- As 4 tarefas que especificamos no bloco docker se transformaram em 4 tarefas em execução em paralelo,
- adicionamos um DummyOperator entre os dois blocos de operadores para que não haja uma rede de conexões entre as tarefas.
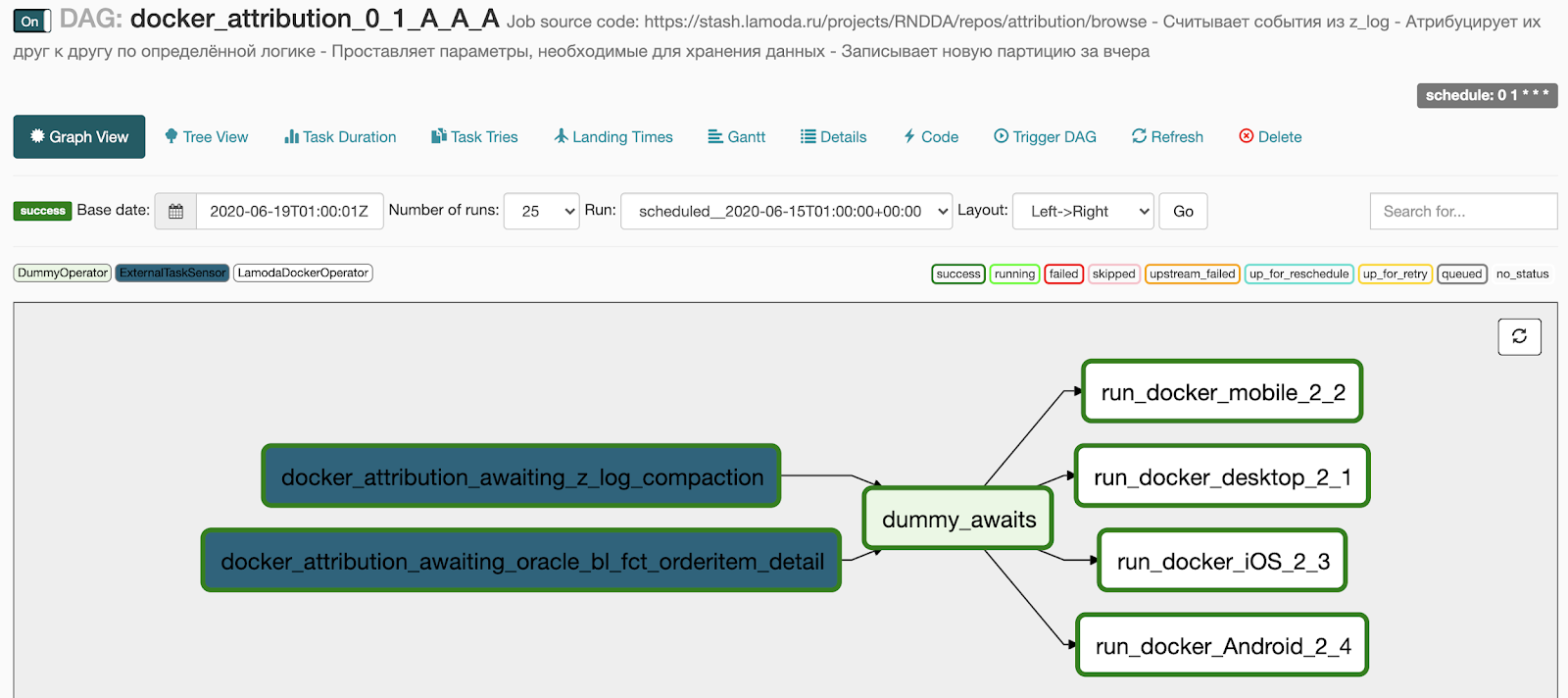
O que queremos fazer a seguir
Primeiro, crie um ambiente de recursos completo. Agora temos um estande de desenvolvimento para testar todos os nossos pipelines. E antes de testar, você precisa ter certeza de que o ambiente de desenvolvimento está livre agora.
Recentemente, nossa equipe se expandiu e o número de candidatos aumentou. Encontramos uma solução temporária para o problema e agora vamos saber no Slack quando pegarmos dev. Funciona, mas ainda é um gargalo no desenvolvimento e nos testes.
Uma opção é mudar para o Kubernetes. Por exemplo, ao criar uma solicitação pull no mestre, você pode gerar um namespace separado no Kubernetes, onde implantar o Airflow, implantar o código e, em seguida, espalhar variáveis e conexões. Após a implantação, o desenvolvedor chegará à instância do Airflow recém-criada e testará seus pipelines. Temos um trabalho de base sobre esse tópico, mas nossas mãos não chegaram ao cluster de combate do Kubernetes, onde poderíamos executar tudo.
A segunda opção para implementar o ambiente Feature é organizar um repositório com uma ramificação de desenvolvimento comum, onde o código dos desenvolvedores é mesclado e automaticamente distribuído para o ambiente de desenvolvimento. Agora estamos olhando ativamente para este esquema.
Também queremos tentar implementar plug-ins - coisas para expandir a funcionalidade da interface da web. O principal objetivo da implementação de plug-ins é construir um gráfico de Gantt no nível de todo o Airflow, ou seja, no nível de todos os pipelines, bem como construir um gráfico de dependência entre diferentes pipelines.
Por que escolhemos o Airflow
- Em primeiro lugar, este é o Python, onde com a ajuda de dois loops e algumas condições, você pode fazer um pipeline elegante e funcionando corretamente. E não precisará ser descrito em um grande pedaço de XML. Além disso, quase todo o ecossistema Python e todo o zoológico de bibliotecas estão disponíveis prontos para uso, que podem ser usados como você quiser.
- A ausência de XML simplifica muito a revisão do código. Escrevemos o código do pipeline e as configurações para ele e está tudo ótimo, tudo funciona. Na verdade, você pode arrastar XML ou qualquer outro formato de configuração, mas isso já é uma questão de gosto.
- unit-, , .
- , «», . Airflow . , , .
- Airflow ( ).
- Active Directory RBAC (role-based access control, )
- Worker Celery Kubernetes.
- open source-, , .
- Airflow , . .
- : statsd , Sentry – , Airflow , . Airflow-exporter Prometheus.
Airflow,
- – : , , execution_date – , .
- - -, , , Apache NiFi. – code-review diff- , .
- Scheduler - .
- – , . – .
- Airflow : . , , . RBAC ( ) , UI (, , ). RBAC – security Flask, .
- : , , -, , . , .
Airflow
- crontab’a cron .
- Python.
- - Docker, , .
- , , real time.
- Airflow , “, , , Z – ”.