
Hoje contaremos como desenvolvemos um sistema de busca de poços candidatos para fraturamento hidráulico (HF) usando aprendizado de máquina (doravante - ML) e o que resultou disso. Vamos descobrir por que o fraturamento hidráulico é necessário, o que o ML tem a ver com ele e por que nossa experiência pode ser útil não apenas para os petroleiros.
Abaixo do corte, uma declaração detalhada do problema, uma descrição de nossas soluções de TI, a escolha de métricas, a criação de um pipeline de ML, o desenvolvimento de uma arquitetura para o lançamento de um modelo em produção.
Escrevemos sobre por que a fratura é feita em nossos artigos anteriores aqui e aqui .
Por que o aprendizado de máquina está aqui? Por um lado, o fraturamento hidráulico é mais barato que a perfuração, mas ainda é caro e, por outro lado, não será possível fazer em todos os poços - não terá efeito. Um geólogo especialista está procurando lugares adequados. Como o número de empresas operacionais é grande (dezenas de milhares), as opções são freqüentemente esquecidas e a empresa não obtém lucros possíveis. O uso de aprendizado de máquina pode acelerar significativamente a análise de informações. No entanto, criar um modelo de ML é apenas metade da batalha. É necessário fazê-lo funcionar em modo constante, conectá-lo ao serviço de dados, desenhar uma interface bonita e fazer com que seja conveniente para o usuário entrar no aplicativo e resolver seu problema em dois cliques.
Abstraindo da indústria do petróleo, percebe-se que tarefas semelhantes estão sendo resolvidas em todas as empresas. Todos desejam:
A. Automatizar o processamento e a análise de grandes fluxos de dados.
B. Reduza custos e não perca benefícios.
C. Torne esse sistema rápido e eficiente.
Com o artigo, você aprenderá como implementamos esse sistema, quais ferramentas usamos e também quais solavancos encontramos no caminho espinhoso de introdução do ML na produção. Temos certeza de que nossa experiência pode interessar a todos que desejam automatizar uma rotina - independente do ramo de atividade.
Como os poços são selecionados para fraturamento hidráulico da maneira "tradicional"
Ao selecionar poços candidatos para fraturamento hidráulico, o homem do petróleo confia em sua ampla experiência e analisa diferentes gráficos e tabelas, após os quais ele prevê onde realizar o fraturamento hidráulico. No entanto, ninguém sabe ao certo o que está acontecendo a uma profundidade de vários milhares de metros, porque não é tão fácil olhar no subsolo (você pode ler mais no artigo anterior ). A análise de dados por métodos "tradicionais" exige custos de mão de obra significativos, mas, infelizmente, não garante uma previsão precisa dos resultados de fraturamento hidráulico (spoiler - com ML também).
Se descrevermos o processo atual de identificação de poços candidatos para fraturamento hidráulico, ele consistirá nas seguintes etapas: descarregar dados em poços de sistemas de informações corporativos, processar os dados obtidos, realizar análises especializadas, concordar em uma solução, conduzir fraturamento hidráulico e analisar os resultados. Parece simples, mas não exatamente.
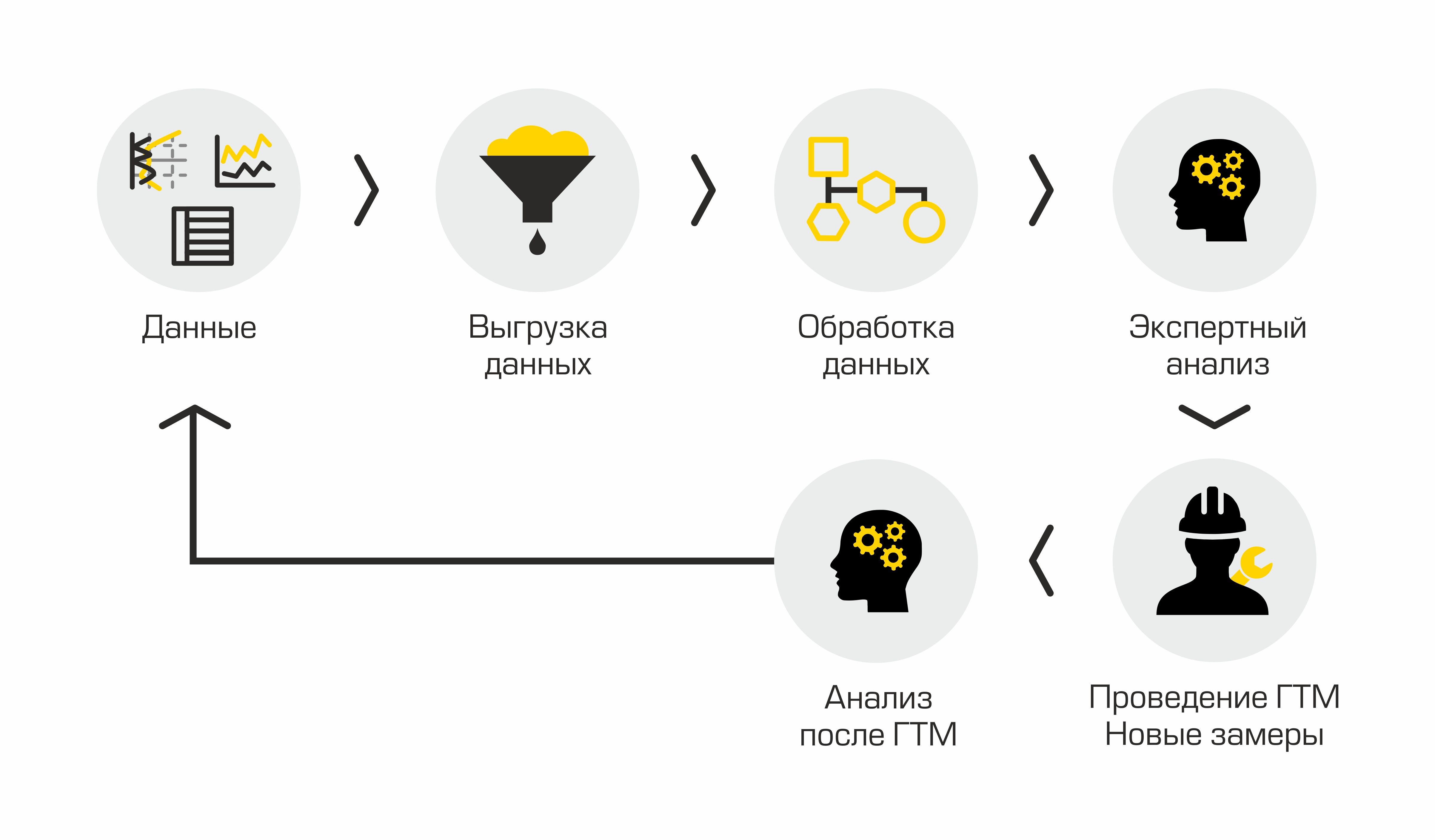
Processo atual de seleção de poços candidatos
A principal desvantagem dessa abordagem “manual” é muita rotina, os volumes aumentam, as pessoas começam a se afogar no trabalho, não há transparência no processo e nos métodos.
Formulação do problema
Em 2019, nossa equipe de análise de dados enfrentou a tarefa de criar um sistema automatizado para a seleção de poços candidatos para fraturamento hidráulico. Para nós, soou assim - para simular o estado de todos os poços, assumindo que agora é necessário realizar o fraturamento hidráulico neles e, em seguida, classificar os poços pelo maior aumento na produção de petróleo e selecionar os poços Top-N para os quais a frota irá viajar e tomar medidas para aumentar a recuperação de petróleo.
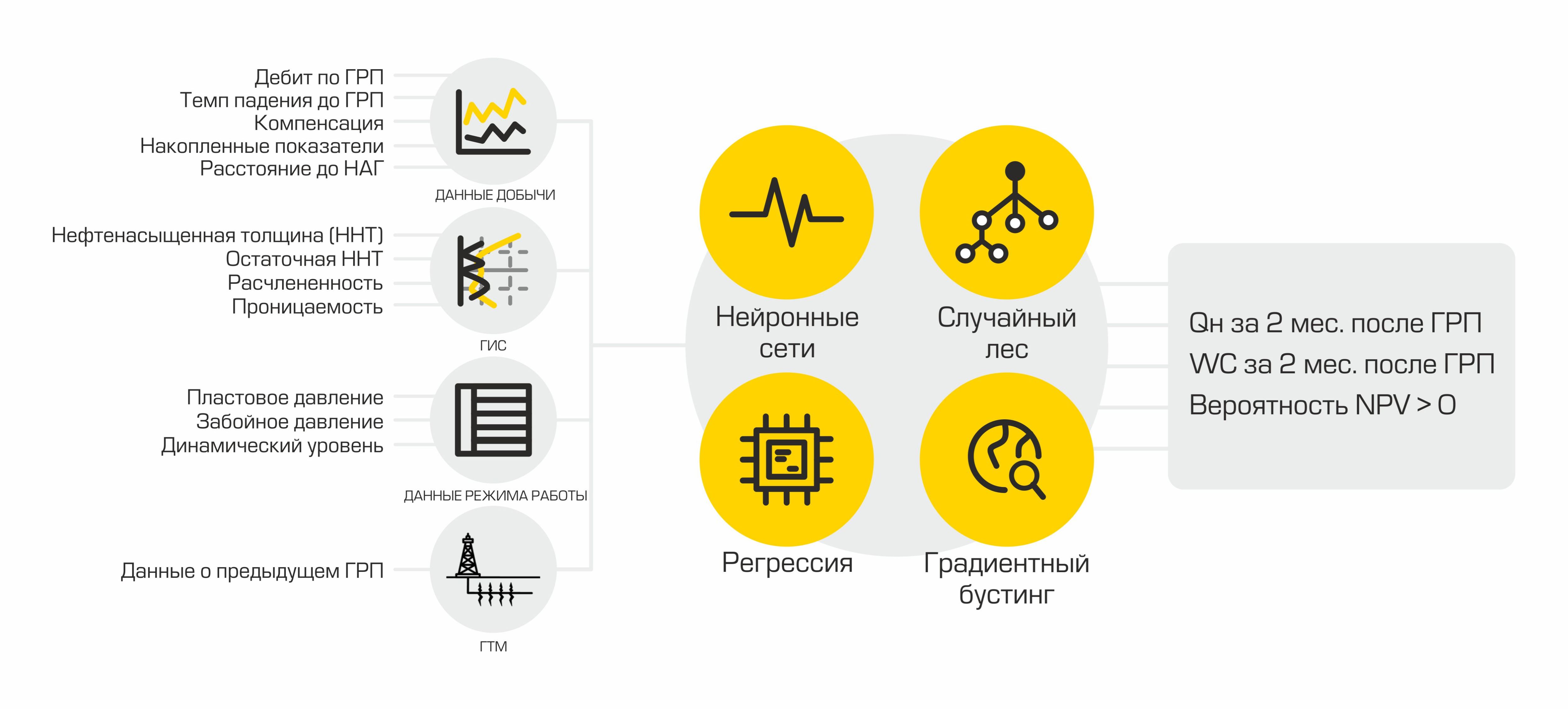
Usando modelos de ML, são formados indicadores que indicam a viabilidade do fraturamento hidráulico em um poço específico: a produção de óleo após o fraturamento hidráulico planejado e o sucesso deste evento.
No nosso caso, a taxa de produção de petróleo é a quantidade de petróleo produzida em metros cúbicos por mês. Este indicador é calculado com base em dois valores: vazão de líquido e corte de água. Os petroleiros chamam um líquido de mistura de óleo e água - é essa mistura que é o produto dos poços. E o corte de água é a proporção do conteúdo de água em uma determinada mistura. A fim de calcular a taxa de produção de óleo esperada após o fraturamento, dois modelos de regressão são usados: um prevê a taxa de fluxo de fluido após o fraturamento, o outro prevê corte de água. Usando os valores retornados pelos dados do modelo, as previsões de produção de petróleo são calculadas usando a fórmula:

O sucesso da fratura é uma variável alvo binária. É determinado com base no valor real do aumento da produção de petróleo, obtido após o fraturamento hidráulico. Se o ganho for maior que um certo limite determinado por um especialista na área de domínio, então o valor do atributo de sucesso é igual a um, caso contrário, é igual a zero. Assim, formamos a marcação para resolver o problema de classificação.
Quanto à métrica ... A métrica deve vir do negócio e refletir os interesses do cliente, qualquer curso de aprendizado de máquina nos informa. Em nossa opinião, é aí que reside o principal sucesso ou fracasso de um projeto de aprendizado de máquina. Um grupo de cientistas de dados pode melhorar a qualidade do modelo pelo tempo que desejarem, mas se isso não aumentar o valor do negócio para o cliente de forma alguma, tal modelo estará condenado. Afinal, era importante para o cliente obter um candidato exato com previsões "físicas" dos parâmetros de desempenho do poço após o fraturamento hidráulico.
Para o problema de regressão, as seguintes métricas foram escolhidas:

Por que não há uma métrica, você pergunta - cada uma reflete sua própria verdade. Para campos onde as taxas médias de produção são altas, o MAE será grande e o MAPE será pequeno. Se pegarmos um campo com baixas taxas médias de produção, o quadro será o oposto.
As seguintes métricas foram escolhidas para o problema de classificação:

( wiki ),
Área sob a curva ROC - AUC ( wiki ).
Erros que encontramos
Erro nº 1 - para construir um modelo universal para todos os campos.
Depois de analisar os conjuntos de dados, ficou claro que os dados mudam de um campo para outro. Isso não é surpreendente, já que os depósitos, via de regra, têm uma estrutura geológica diferente.
Nossa suposição de que, se pegarmos e direcionarmos todos os dados disponíveis para treinamento em um modelo, ele por si só revelará as regularidades da estrutura geológica, falhou. O modelo treinado com os dados de um determinado campo apresentou uma qualidade de predições superior ao modelo, que foi criado a partir de informações sobre todos os campos disponíveis.
Para cada campo, diferentes algoritmos de aprendizado de máquina foram testados e, com base nos resultados da validação cruzada, foi selecionado aquele com o MAPE mais baixo.
Erro # 2 - Falta de compreensão profunda dos dados.
Se você deseja fazer um bom modelo de aprendizado de máquina para um processo físico real, entenda como esse processo acontece.
Inicialmente, nossa equipe não tinha um especialista em domínio e nos mudamos de forma caótica. Infelizmente, não notamos os erros do modelo ao analisar as previsões, eles tiraram conclusões incorretas com base nos resultados.
Erro número 3 - falta de infraestrutura.
No início, baixamos muitos arquivos csv diferentes para campos e parâmetros diferentes. Em algum ponto, um número insuportavelmente grande de arquivos e modelos se acumulou. Tornou-se impossível reproduzir os experimentos já realizados, arquivos foram perdidos e surgiu confusão.
1. PARTE TÉCNICA
Hoje nosso sistema de auto-seleção de candidatos se parece com o seguinte:
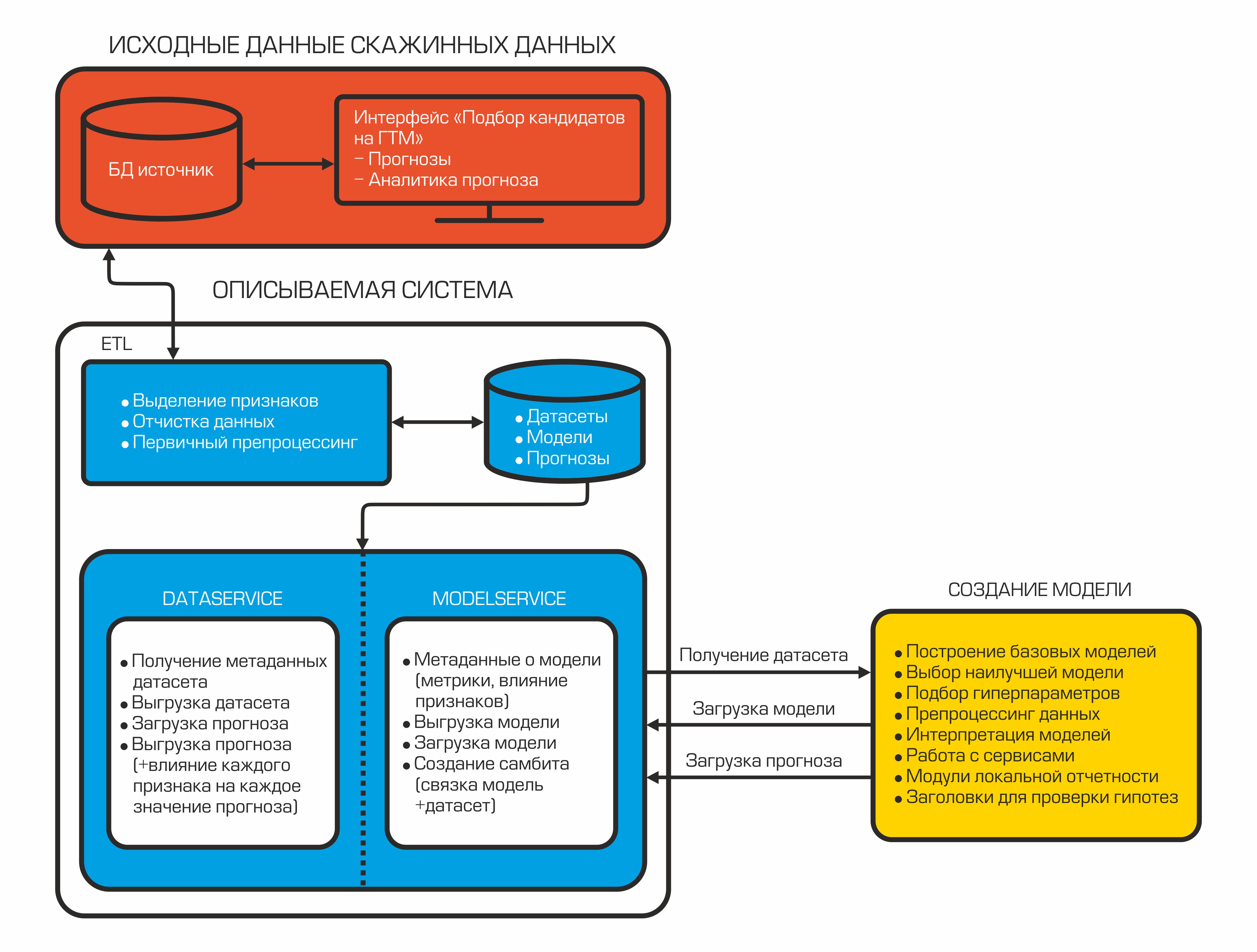
Cada componente é um contêiner isolado que desempenha uma função específica.
2.1 ETL = Carregamento de Dados
Tudo começa com dados. Principalmente se quisermos construir um modelo de aprendizado de máquina. Escolhemos Pentaho Data Integration como sistema de integração.

Captura de tela de uma das transformações
Principais vantagens:
- sistema livre;
- uma grande seleção de componentes para conectar a várias fontes de dados e transformar o fluxo de dados;
- disponibilidade de interface web;
- a capacidade de gerenciar via API REST;
- exploração madeireira.
Além de tudo o que foi mencionado acima, tínhamos uma vasta experiência no desenvolvimento de integrações para este produto. Por que a integração de dados é necessária em projetos de ML? No processo de preparação de conjuntos de dados, é constantemente necessário implementar cálculos complexos, trazer os dados para um único formulário, calcular novos indicadores "ao longo do caminho", mudanças nos parâmetros ao longo do tempo, etc.
Para cada fato de fraturamento hidráulico, mais de 400 parâmetros são descarregados que descrevem a operação do poço no momento atividades, operação de poços adjacentes, bem como informações sobre fraturamento hidráulico realizado anteriormente. Além disso, ocorre a transformação e o pré-processamento dos dados.
Escolhemos o PostgreSQL como repositório dos dados processados. Ele possui um grande conjunto de métodos para trabalhar com json. Como armazenamos os conjuntos de dados finais neste formato, isso se tornou um fator decisivo.
Um projeto de aprendizado de máquina está associado a uma mudança constante nos dados de entrada devido à adição de novos recursos, portanto, o Data Vault é usado como o esquema do banco de dados (link para o wiki). Este esquema de design de armazenamento permite adicionar rapidamente novos dados sobre um objeto e não violar a integridade de tabelas e consultas.
2.2 Serviços de Dados e Modelos
Depois de combinar e calcular os indicadores necessários, os dados são carregados no banco de dados. Eles são armazenados aqui e aguardam que o datasinter os leve para criar o modelo de ML. Para isso, existe o DataService - um serviço escrito em Python e usando o protocolo gRPC. Ele permite que você obtenha conjuntos de dados e seus metadados (tipos de recursos, sua descrição, tamanho do conjunto de dados, etc.), carregue e descarregue previsões, gerencie os parâmetros de filtragem e divisão por trem / teste. As previsões no banco de dados são armazenadas no formato json, o que permite que você receba dados rapidamente e armazene não apenas o valor da previsão, mas também a influência de cada recurso nessa previsão específica.
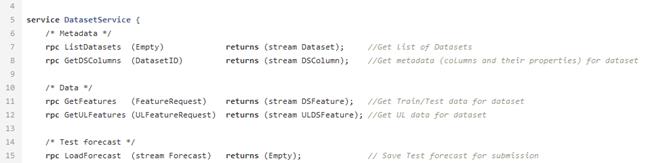
Arquivo proto de amostra para serviço de dados.
Quando o modelo é criado, ele deve ser salvo - para isso, é utilizado o ModelService, também escrito em Python com gRPC. Os recursos deste serviço não se limitam a salvar e carregar um modelo. Além disso, permite monitorar métricas, a importância dos recursos e também implementa uma conexão modelo + conjunto de dados para a criação automática subsequente de uma previsão quando novos dados aparecem.

A estrutura do nosso serviço modelo é assim.
2.3 Modelo de ML
Em um determinado ponto, nossa equipe percebeu que a automação também deveria afetar a criação de modelos de ML. Essa necessidade foi impulsionada pela necessidade de acelerar o processo de fazer previsões e testar hipóteses. E tomamos a decisão de desenvolver e implementar nossa própria biblioteca AutoML em nosso pipeline.
Inicialmente, a possibilidade de usar bibliotecas AutoML prontas foi considerada, mas as soluções existentes acabaram não sendo flexíveis o suficiente para nossa tarefa e não tinham todas as funcionalidades necessárias de uma vez (a pedido dos trabalhadores, podemos escrever um artigo separado sobre nosso AutoML). Notamos apenas que o framework que desenvolvemos contém classes usadas para pré-processar um conjunto de dados, gerar e selecionar recursos. Como modelos de aprendizado de máquina, usamos um conjunto familiar de algoritmos que já usamos com mais sucesso: implementações de aumento de gradiente do xgboost, bibliotecas catboost, uma floresta aleatória de Sklearn, uma rede neural totalmente conectada em Pytorch etc. Após o treinamento, o AutoML retorna um pipeline sklearn que inclui as classes mencionadas, bem como o modelo de ML,que apresentou o melhor resultado na validação cruzada para a métrica selecionada.
Além do modelo, é feito um relatório sobre a influência de eventuais sinais em uma previsão específica. Esse relatório permite que os geólogos olhem sob o capô de uma caixa preta misteriosa. Assim, o AutoML recebe o conjunto de dados marcado usando o DataService e, após o treinamento, forma o modelo final. A seguir, podemos obter a estimativa final da qualidade do modelo carregando o conjunto de dados de teste, gerando previsões e calculando as métricas de qualidade. A etapa final é o upload de um arquivo binário do modelo gerado, sua descrição e métricas para o ModelService, enquanto as previsões e informações sobre a influência dos recursos são retornadas para o DataService.
Assim, nosso modelo é colocado em um tubo de ensaio e está pronto para ser lançado no prod. A qualquer momento, podemos usá-lo para gerar previsões com base em dados novos e relevantes.
2.4 Interface
O usuário final de nosso produto é um geólogo e precisa interagir de alguma forma com o modelo de ML. A forma mais conveniente para ele é um módulo em software especializado. Nós o implementamos.
O front-end disponível para o nosso usuário parece uma loja online: você pode selecionar o campo desejado e obter uma lista dos poços com maior probabilidade de sucesso. No cartão do poço, o usuário vê o crescimento previsto após o fraturamento hidráulico e decide por si mesmo se deseja adicioná-lo à "cesta" e considerar com mais detalhes.

Interface do módulo no aplicativo.

É assim que a placa do poço aparece no apêndice.
Além dos ganhos de óleo e líquido projetados, o usuário também pode saber quais características influenciaram o resultado proposto. A importância dos recursos é calculada no estágio de criação de um modelo usando o método shap e, em seguida, carregada na interface do software com DataService.

O aplicativo mostra claramente quais recursos foram mais importantes para as previsões do modelo.
O usuário também pode olhar para análogos do poço de interesse. A busca por análogos é implementada no lado do cliente usando o algoritmo de árvore Kd .
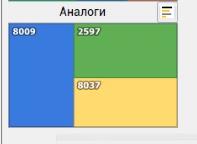
O módulo exibe poços com parâmetros geológicos semelhantes.
2. COMO MELHORAMOS O MODELO DE ML

Parece que vale a pena executar o AutoML com os dados disponíveis, e ficaremos felizes. Mas acontece que a qualidade das previsões obtidas automaticamente não pode ser comparada com os resultados das impressoras de dados. O fato é que os analistas costumam apresentar e testar várias hipóteses para melhorar os modelos. Se a ideia melhorar a precisão da previsão de dados reais, ela será implementada no AutoML. Assim, ao adicionar novos recursos, melhoramos a previsão automática o suficiente para avançar para a criação de modelos e previsões com envolvimento mínimo de analistas. Aqui estão algumas hipóteses que foram testadas e implementadas em nosso AutoML:
1. Alteração do método de preenchimento
Nos primeiros modelos, preenchemos quase todas as lacunas das características com a média, exceto as categóricas - para elas foi utilizado o significado mais comum. Posteriormente, com o trabalho conjunto de analistas e um especialista, da área de domínio, foi possível selecionar os valores mais adequados para preencher as lacunas em 80% dos recursos. Também tentamos mais alguns métodos de preenchimento usando as bibliotecas sklearn e missingpy. Os melhores resultados foram obtidos com enchimento constante e computador KNN - até 5% MAPE.

Resultados de uma experiência de preenchimento de lacunas com diferentes métodos.
2. Geração de recursos
Adicionar novos recursos é um processo iterativo para nós. Para melhorar os modelos, tentamos adicionar novos recursos com base nas recomendações de um especialista no domínio, com base na experiência de artigos científicos e nas nossas próprias conclusões dos dados.

Testar as hipóteses apresentadas pela equipe ajuda a introduzir novos recursos.
Um dos primeiros foram os recursos identificados com base no agrupamento. Na verdade, simplesmente selecionamos os clusters no conjunto de dados com base em parâmetros geológicos e geramos estatísticas básicas para outras características com base em clusters - isso deu um pequeno aumento na qualidade.
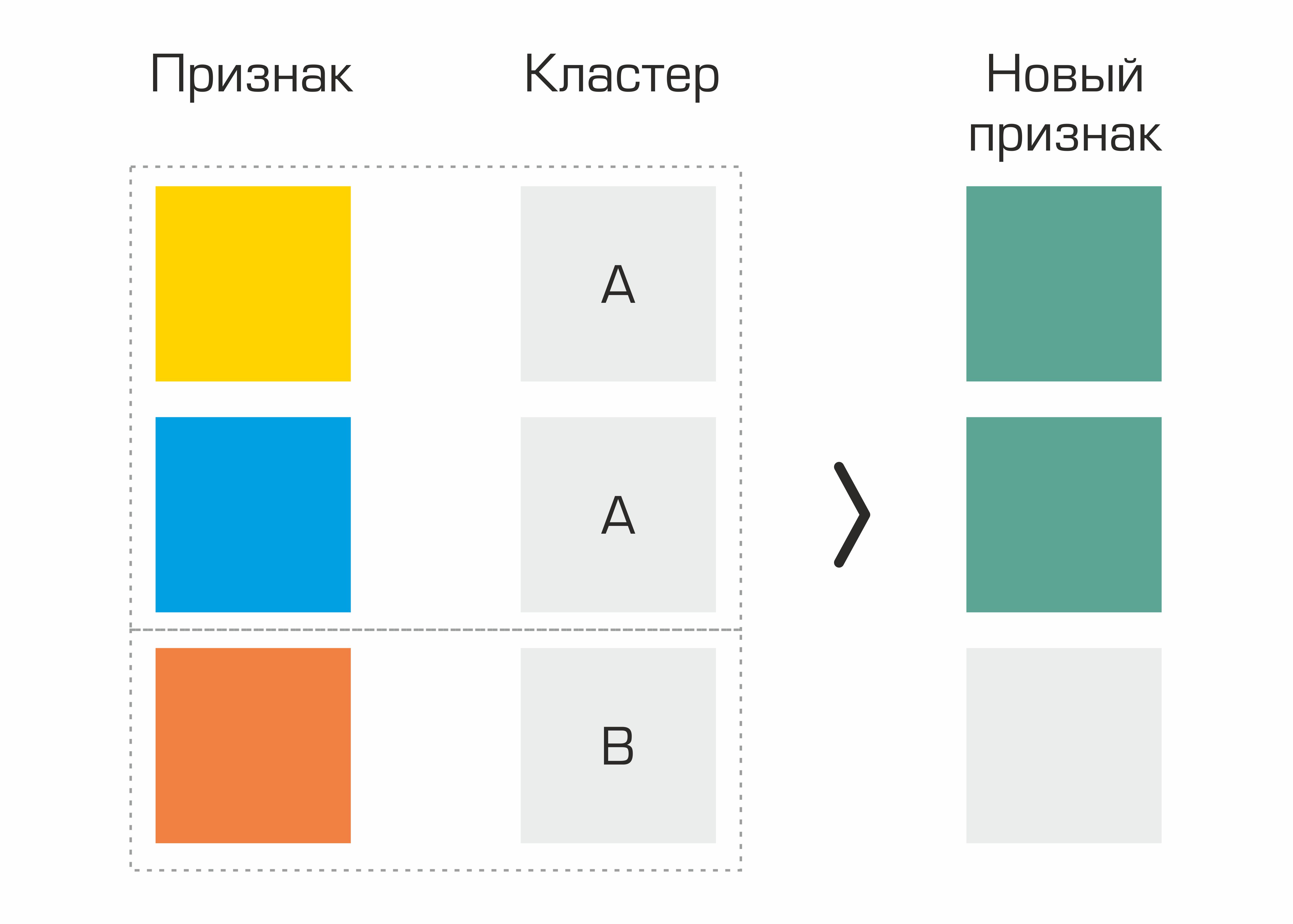
O processo de criação de um recurso com base na seleção de clusters.
Acrescentamos também os sinais que inventamos quando imersos na região do domínio: produção cumulativa de óleo normalizada para a idade do poço em meses, injeção acumulada normalizada para a idade do poço em meses, parâmetros incluídos na fórmula de Dupuis. Mas a geração do conjunto padrão de PolynomialFeatures de sklearn não nos deu um aumento na qualidade.
3.
Seleção de recursos Realizamos a seleção de recursos várias vezes: manualmente junto com um especialista do domínio e usando métodos de seleção de recursos padrão. Após várias iterações, decidimos remover dos dados alguns recursos que não afetam o destino. Assim, conseguimos reduzir o tamanho do conjunto de dados, mantendo a mesma qualidade, o que permitiu acelerar significativamente a criação de modelos.
E agora sobre as métricas recebidas ...
Em um dos campos, obtivemos os seguintes indicadores de qualidade do modelo:

Deve-se notar que o resultado do fraturamento hidráulico também depende de uma série de fatores externos que não são previstos. Portanto, não podemos falar em reduzir MAPE a 0.
Conclusão A
seleção de poços candidatos para fraturamento hidráulico usando ML é um projeto ambicioso que reuniu 7 pessoas: engenheiros de dados, cientistas de dados, especialistas de domínio e gerentes. Hoje, o projeto já está pronto para ser lançado e já está sendo testado em diversas subsidiárias da Companhia.
A empresa está aberta à experimentação, por isso cerca de 20 poços foram selecionados da lista e fraturados. O desvio da previsão com o valor real da taxa de fluxo de óleo inicial (MAPE) foi de cerca de 10%. E esse é um resultado muito bom!
Não sejamos astutos: especialmente no estágio inicial, vários de nossos poços propostos revelaram-se opções inadequadas.
Escreva perguntas e comentários - tentaremos respondê-los.
Inscreva-se no nosso blog, temos muito mais ideias e projetos interessantes, sobre os quais com certeza escreveremos!