
O PostgreSQL já provou seu valor - ele funciona muito bem, é usado por empresas digitais da moda como Alibaba e TripAdvisor, e a falta de royalties o torna uma alternativa tentadora a monstros como MS SQL ou Oracle DB. Mas assim que começamos a pensar sobre PostgreSQL no cenário Enterprise, imediatamente nos deparamos com requisitos difíceis: “Mas e a tolerância a falhas de configuração? resistência a desastres? onde está o monitoramento abrangente? e os backups automatizados? que tal usar bibliotecas de fitas, armazenamento direto e secundário? "
Por outro lado, o PostgreSQL não possui recursos de backup embutidos, como o DBMS "adulto", como RMAN para banco de dados Oracle ou SAP Database Backup. Por outro lado, os fornecedores de sistemas de backup corporativo (Veeam, Veritas, Commvault), embora suportem PostgreSQL, na verdade só trabalham com uma determinada configuração (geralmente autônoma) e com um conjunto de várias restrições.
Sistemas de backup especialmente projetados para PostgreSQL como Barman, Wal-g, pg_probackup são extremamente populares em pequenas instalações de PostgreSQL ou onde backups pesados de outros elementos do ambiente de TI não são necessários. Por exemplo, além do PostgreSQL, a infraestrutura pode ter servidores físicos e virtuais, OpenShift, Oracle, MariaDB, Cassandra, etc. Tudo isso deve ser feito com uma ferramenta comum. Colocar uma solução separada exclusivamente para PostgreSQL é uma má ideia: os dados serão copiados em algum lugar para o disco e, em seguida, eles precisam ser removidos para a fita. Essa duplicação do backup aumenta o tempo de backup e também, de forma mais crítica, a recuperação.
Em uma solução corporativa, é feito backup de uma instalação com um certo número de nós em um cluster dedicado. Ao mesmo tempo, por exemplo, o Commvault pode trabalhar apenas com um cluster de dois nós, no qual o Primário e o Secundário são rigidamente atribuídos a determinados nós. E faz sentido fazer backup apenas com o Primário, porque o backup com o Secundário tem suas limitações. Devido às peculiaridades do SGBD, não é criado um dump no Secundário e, portanto, resta apenas a possibilidade de um backup de arquivo.
Para mitigar os riscos de tempo de inatividade, a criação de um sistema tolerante a falhas cria uma configuração de cluster ao vivo, e o Primário pode migrar gradualmente entre diferentes servidores. Por exemplo, o próprio software Patroni inicia Primário em um nó de cluster selecionado aleatoriamente. A SRK não tem como rastrear isso imediatamente e, se a configuração mudar, os processos serão interrompidos. Ou seja, a introdução do controle externo evita que o SRK funcione de maneira eficaz, porque o servidor de controle simplesmente não entende de onde e de quais dados devem ser copiados.
Outro problema é a implementação do backup no Postgres. É possível via dump e funciona em bases pequenas. Mas, em grandes bancos de dados, o despejo leva muito tempo, requer muitos recursos e pode levar a uma falha da instância do banco de dados.
O backup de arquivo corrige a situação, mas em grandes bancos de dados é lento porque funciona no modo de thread único. Além disso, os fornecedores têm uma série de restrições adicionais. Você não pode usar backups de arquivo e despejo ao mesmo tempo ou a desduplicação não é suportada. Existem muitos problemas e, na maioria das vezes, é mais fácil escolher um DBMS caro, mas comprovado, em vez de Postgres.
Nenhum lugar para recuar! Atrás dos desenvolvedores de Moscou !
Porém, recentemente nossa equipe enfrentou um difícil desafio: no projeto de criação do AIS OSAGO 2.0, onde fizemos a infraestrutura de TI, os desenvolvedores do novo sistema escolheram o PostgreSQL.
É muito mais fácil para grandes desenvolvedores de software usar soluções de código aberto "na moda". O Facebook tem especialistas suficientes para apoiar o trabalho deste DBMS. E no caso do PCA, todas as tarefas do “segundo dia” caíram sobre os nossos ombros. Fomos solicitados a fornecer tolerância a falhas, montar um cluster e, é claro, estabelecer um backup. A lógica das ações era a seguinte:
- Ensine o SRK a fazer um backup do nó primário do cluster. Para fazer isso, o SRK deve encontrá-lo, o que significa que ele precisa da integração com uma ou outra solução para gerenciar o cluster PostgreSQL. No caso do PCA, o software Patroni foi usado para isso.
- Decida o tipo de backup com base na quantidade de dados e nos requisitos de recuperação. Por exemplo, quando for necessário restaurar páginas granularmente, use um despejo e, se os bancos de dados forem grandes e a restauração granular não for necessária, trabalhe no nível do arquivo.
- Anexe o recurso de backup em bloco à solução para criar um backup multithread.
Ao mesmo tempo, inicialmente nos propusemos a criar um sistema eficaz e simples, sem amarrações monstruosas de componentes adicionais. Quanto menos muletas, menor a carga de trabalho da equipe e menor o risco de falha da SII. Nós imediatamente descartamos as abordagens que usavam Veeam e RMAN, porque um conjunto de duas soluções já indica a falta de confiabilidade do sistema.
Um pouco de mágica para uma empresa
Portanto, precisávamos garantir um backup confiável para 10 clusters de 3 nós cada, enquanto a mesma infraestrutura é espelhada no data center de backup. Os centros de dados no plano PostgreSQL funcionam com base no princípio ativo-passivo. A quantidade total de bancos de dados foi de 50 TB. Qualquer SRC de nível corporativo pode lidar facilmente com isso. Mas a nuance é que inicialmente o Postgres não tem um gancho para compatibilidade total e profunda com sistemas de backup. Portanto, tivemos que buscar uma solução que inicialmente tivesse a máxima funcionalidade em conjunto com o PostgreSQL, e modificar o sistema.
Conduzimos três "hackathons" internos - examinamos mais de cinquenta desenvolvimentos, testamos, fizemos mudanças em relação às nossas hipóteses e os testamos novamente. Depois de analisar as opções disponíveis, escolhemos Commvault. Fora da caixa, este produto poderia funcionar com a instalação mais simples do PostgreSQL em cluster e sua arquitetura aberta deu origem à esperança (que se tornou realidade) para um refinamento e integração bem-sucedidos. Além disso, o Commvault pode fazer backup dos logs do PostgreSQL. Por exemplo, o Veritas NetBackup na parte PostgreSQL é capaz de fazer apenas backups completos.
Aprenda mais sobre arquitetura. Os servidores de gerenciamento Commvault foram instalados em cada um dos dois datacenters em uma configuração HA do CommServ. O sistema é espelhado, gerenciado por meio de um único console e, do ponto de vista de HA, atende a todos os requisitos da empresa.
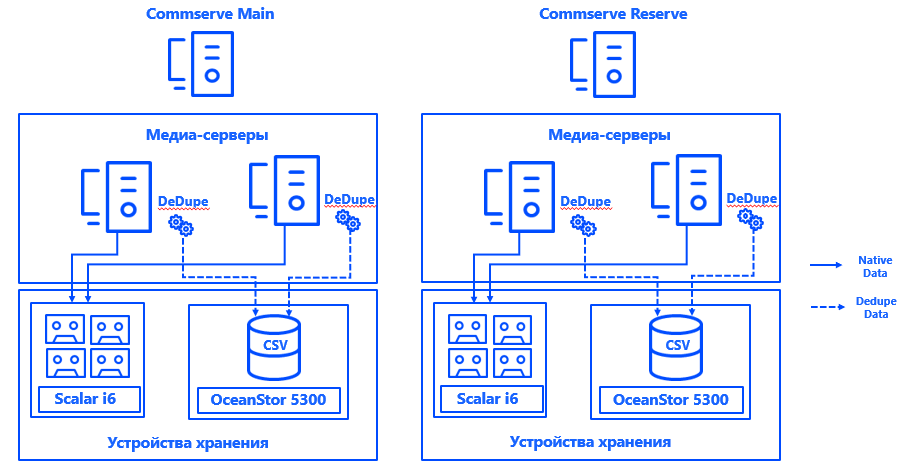
Também lançamos dois servidores de mídia física em cada data center, aos quais conectamos matrizes de disco e bibliotecas de fitas dedicadas especificamente para backups por meio de SAN via Fibre Channel. As amplas bases de desduplicação garantiram a resiliência dos servidores de mídia e a conexão de cada servidor a cada CSV garantiu a operação contínua em caso de falha de qualquer componente. A arquitetura do sistema permite que o backup continue mesmo se um dos data centers cair.
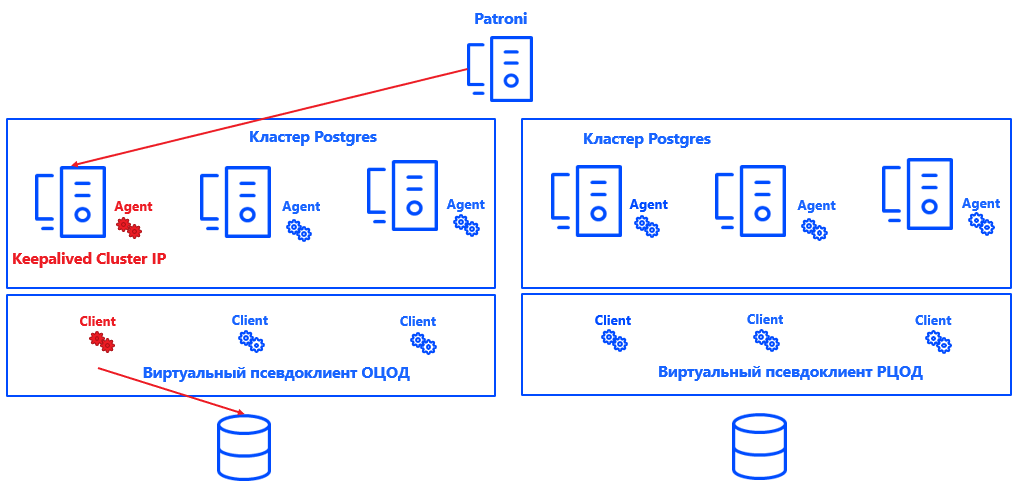
Patroni define um nó primário para cada cluster. Pode ser qualquer nó livre no data center - mas apenas no principal. No backup, todos os nós são secundários.
Para que a Commvault entenda qual nó do cluster é o Primário, integramos o sistema (graças à arquitetura aberta da solução) com o Postgres. Para fazer isso, foi criado um script que relata a localização atual do nó primário para o servidor de gerenciamento Commvault.
Em geral, o processo se parece com o seguinte:
Patroni seleciona Primário → Keepalived abre o cluster IP e executa o script → Agente Commvault no nó do cluster selecionado recebe uma notificação de que é Primário → Commvault reconfigura automaticamente o backup dentro do pseudo-cliente.
A vantagem dessa abordagem é que a solução não afeta a consistência ou a exatidão dos logs ou a recuperação da instância do Postgres. Também é facilmente escalonável, porque agora não é necessário consertar os nós primário e secundário para Commvault. É suficiente que o sistema entenda onde está o Primário, e o número de nós pode ser aumentado para quase qualquer valor.
A solução não tem a pretensão de ser ideal e tem nuances próprias. O Commvault pode fazer backup apenas de uma instância inteira, não de bancos de dados individuais. Portanto, uma instância separada foi criada para cada banco de dados. Os clientes reais são combinados em pseudo-clientes virtuais. Cada pseudo-cliente Commvault é um cluster UNIX. Ele adiciona os nós de cluster nos quais o agente Commvault para Postgres está instalado. Como resultado, todos os nós virtuais do pseudo-cliente são submetidos a backup como uma instância.
Dentro de cada pseudo-cliente, o nó ativo do cluster é indicado. Isso é o que nossa solução de integração para Commvault define. O princípio de sua operação é bastante simples: se um IP de cluster aumenta em um nó, o script define o parâmetro "nó ativo" no binário do agente Commvault - na verdade, o script define "1" na parte necessária da memória. O agente envia esses dados ao CommServe e o Commvault faz um backup do nó desejado. Além disso, a exatidão da configuração é verificada no nível do script, ajudando a evitar erros ao iniciar o backup.
Ao mesmo tempo, grandes bancos de dados são copiados em blocos em vários threads, atendendo aos requisitos de RPO e janelas de backup. A carga no sistema é insignificante: cópias completas não ocorrem com tanta frequência, em outros dias apenas os logs são coletados, além disso, durante os períodos de baixa carga.
A propósito, aplicamos políticas separadas para fazer backup dos logs arquivados do PostgreSQL - eles são armazenados de acordo com regras diferentes, copiados de acordo com uma programação diferente, e a desduplicação não está habilitada para eles, uma vez que esses logs contêm dados exclusivos.
Para garantir a consistência de toda a infraestrutura de TI, clientes de arquivo Commvault separados são instalados em cada um dos nós do cluster. Eles excluem arquivos Postgres dos backups e destinam-se apenas a backups de sistemas operacionais e aplicativos. Essa parte dos dados também tem sua própria política e seu próprio período de armazenamento.

Agora o SRK não afeta os serviços produtivos, mas se a situação mudar, será possível habilitar o sistema de limitação de carga em Commvault.
Isso é bom? Boa!
Assim, obtivemos não apenas um viável, mas também um backup totalmente automatizado para uma instalação PostgreSQL em cluster, que atende a todos os requisitos de chamadas corporativas.
Os parâmetros RPO e RTO em 1 hora e 2 horas são sobrepostos por uma margem, o que significa que o sistema irá combiná-los mesmo com um aumento significativo no volume de dados armazenados. Apesar de muitas dúvidas, o PostgreSQL e o ambiente corporativo mostraram-se bastante compatíveis. E agora sabemos por experiência própria que um backup para esse DBMS é possível em uma ampla variedade de configurações.
Claro que, ao longo do caminho, tivemos que usar sete pares de botas de ferro, superar uma série de dificuldades, pisar em alguns ancinhos e corrigir alguns erros. Mas agora a abordagem já foi testada e pode ser usada para implementar código aberto em vez de DBMS proprietário no ambiente corporativo hostil.
Você experimentou o PostgreSQL em um ambiente corporativo?
Autores:
Oleg Lavrenov, engenheiro de projeto de sistemas de armazenamento de dados Jet Infosystems
Dmitry Erykin, engenheiro de projeto de sistemas de computação Jet Infosystems