Nós da Lyft decidimos mover nossa infraestrutura de servidor para Kubernetes, um sistema de orquestração de contêineres distribuído, para aproveitar os benefícios que a automação tem a oferecer. Eles queriam uma plataforma sólida e confiável que pudesse se tornar a base para futuros desenvolvimentos, bem como reduzir os custos gerais e aumentar a eficiência.
Os sistemas distribuídos podem ser difíceis de entender e analisar, e o Kubernetes não é exceção a esse respeito. Apesar de seus muitos benefícios, identificamos vários gargalos ao mudar para o CronJob , um sistema integrado ao Kubernetes para realizar tarefas repetitivas em uma programação. Nesta série de duas partes, discutiremos as desvantagens técnicas e operacionais do Kubernetes CronJob quando usado em um grande projeto e compartilharemos com você nossa experiência de superá-las.
Primeiro, descreveremos as deficiências dos Kubernetes CronJobs que encontramos ao usá-los no Lyft. Em seguida, (na segunda parte) - contaremos como eliminamos essas deficiências na pilha do Kubernetes, aumentando a usabilidade e melhorando a confiabilidade.
Parte 1. Introdução
Quem se beneficiará com esses artigos?
- Usuários do Kubernetes CronJob.
- , Kubernetes.
- , Kubernetes .
- , Kubernetes , .
- Contributor' Kubernetes.
?
- , Kubernetes ( , CronJob) .
- , Kubernetes Lyft , .
:
- cron'.
- , CronJob, — , CronJob, Job' Pod', . CronJob Unix cron' .
- sidecar- , . Lyft sidecar- , runtime- Envoy, statsd .., sidecar-, , .
- ronjobcontroller — Kubernetes, CronJob'.
- , cron , ( ).
- Lyft Engineering , ( «», « », « ») — Lyft ( «», « », «» «»). , , «-» .
CronJob' Lyft
Hoje, nosso ambiente de produção multilocatário tem quase 500 cron jobs chamados mais de 1.500 vezes por hora.
Tarefas agendadas e recorrentes são amplamente utilizadas pelo Lyft para uma variedade de propósitos. Antes de mudar para o Kubernetes, eles eram executados diretamente em máquinas Linux usando cron Unix normal. As equipes de desenvolvimento foram responsáveis por escrever as
crontabdefinições e provisionar as instâncias que as executaram usando os pipelines Infrastructure As Code (IaC), e a equipe de infraestrutura foi responsável por mantê-los.
Como parte de um esforço maior para colocar em contêineres e migrar cargas de trabalho para nossa própria plataforma Kubernetes, decidimos mudar para CronJob *, substituindo o cron Unix clássico por sua contraparte Kubernetes. Como muitos outros, o Kubernetes foi escolhido por causa de suas vastas vantagens (pelo menos em teoria), incluindo eficiência de recursos.
Imagine uma tarefa cron que seja executada uma vez por semana durante 15 minutos. Em nosso antigo ambiente, a máquina dedicada a essa tarefa ficava ociosa 99,85% do tempo. No caso do Kubernetes, os recursos computacionais (CPU, memória) são usados apenas durante a chamada. No resto do tempo, as capacidades não utilizadas podem ser usadas para lançar outros CronJobs ou simplesmente reduzirgrupo. Dada a maneira anterior de executar cron jobs, nos beneficiaríamos muito com a mudança para um modelo no qual os jobs são efêmeros.

Limites de responsabilidade para desenvolvedores e engenheiros de plataforma na pilha Lyft
Depois de mudar para a plataforma Kubernetes, as equipes de desenvolvimento pararam de alocar e operar suas próprias instâncias de computação. A equipe da plataforma agora é responsável por manter e operar recursos de computação e dependências de tempo de execução na pilha do Kubernetes. Além disso, ela está envolvida na criação dos próprios objetos CronJob. Os desenvolvedores precisam apenas configurar a programação de tarefas e o código do aplicativo.
No entanto, tudo parece bom no papel. Na prática, identificamos vários gargalos ao migrar de um ambiente cron Unix tradicional bem pesquisado para um ambiente CronJob efêmero distribuído no Kubernetes.
* Embora o CronJob fosse e ainda tenha (a partir do Kubernetes v1.18) o status beta, descobrimos que ele era bastante satisfatório para nossas necessidades na época e também se encaixava perfeitamente com o resto do kit de ferramentas de infraestrutura do Kubernetes que tínhamos ...
Qual é a diferença entre Kubernetes CronJob e Unix cron?
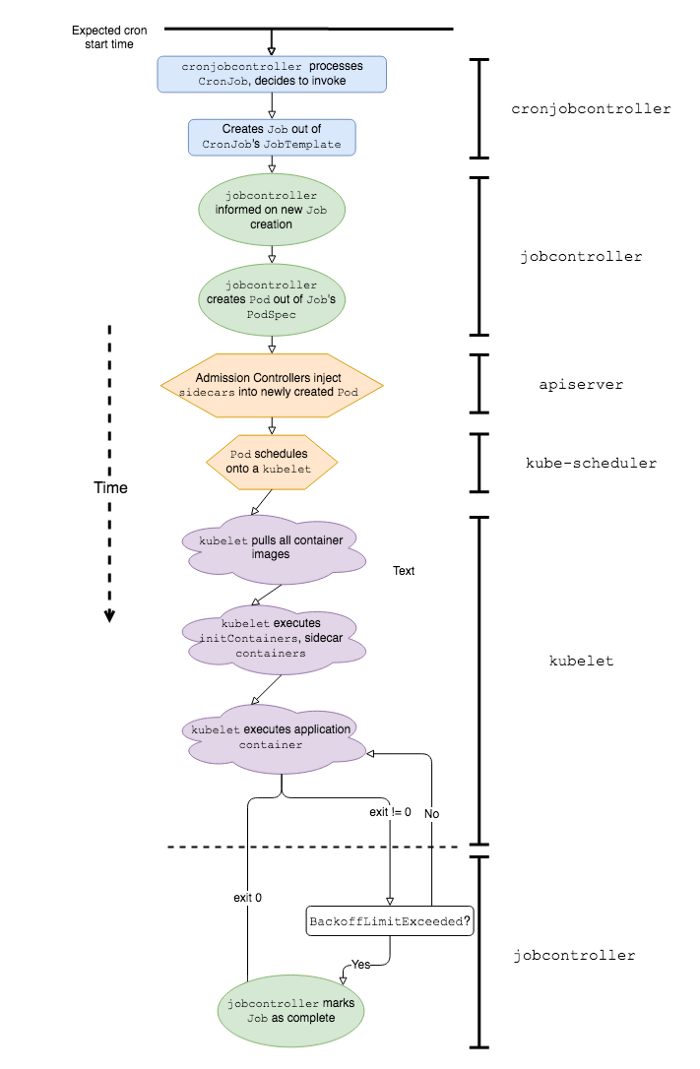
Uma sequência simplificada de eventos e componentes de software K8s envolvidos no trabalho do Kubernetes CronJob
Para explicar melhor por que trabalhar com o Kubernetes CronJob em um ambiente de produção está associado a certas dificuldades, vamos primeiro definir como eles diferem do clássico. Espera-se que o CronJob funcione da mesma maneira que os cron jobs no Linux ou Unix; entretanto, existem pelo menos algumas diferenças importantes em seu comportamento: velocidade de inicialização e tratamento de falhas .
Velocidade de lançamento
Atraso no início (atraso no início) é definido como o tempo decorrido do cron de início agendado até o início real do código do aplicativo. Em outras palavras, se o cron estiver programado para iniciar às 00:00:00 e o aplicativo começar a ser executado às 00:00:22, o atraso para iniciar esse cron específico será de 22 segundos.
No caso de crons Unix clássicos, o atraso na inicialização é mínimo. Na hora certa, esses comandos são simplesmente executados. Vamos confirmar isso com o seguinte exemplo:
# date
0 0 * * * date >> date-cron.log
Com uma configuração cron como esta, provavelmente obteremos a seguinte saída em
date-cron.log:
Mon Jun 22 00:00:00 PDT 2020
Tue Jun 23 00:00:00 PDT 2020
…
Por outro lado, o Kubernetes CronJob pode enfrentar atrasos de inicialização significativos porque o aplicativo é precedido por uma série de eventos. Aqui estão alguns deles:
-
cronjobcontrollerprocessa e decide ligar para o CronJob; -
cronjobcontrollercria um trabalho com base na especificação de trabalho CronJob; -
jobcontrollerpercebe um novo trabalho e cria um pod; - O Admission Controller insere dados do contêiner secundário na especificação do Pod *;
-
kube-schedulerplanejando um Pod no kubelet; -
kubeletinicia o Pod (buscando todas as imagens do contêiner); -
kubeletinicia todos os contêineres de sidecar *; -
kubeletinicia o contêiner do aplicativo *.
* Esses estágios são exclusivos da pilha Lyft Kubernetes.
Descobrimos que os itens 1, 5 e 7 fazem a contribuição mais significativa para a latência, uma vez que atingimos uma determinada escala de CronJob no ambiente Kubernetes.
Atraso causado pelo trabalho cronjobcontroller'
Para entender melhor de onde vem a latência, vamos examinar o código-fonte embutido
cronjobcontroller'. No Kubernetes 1.18, ele cronjobcontrollerapenas verifica todos os CronJobs a cada 10 segundos e executa alguma lógica em cada um.
A implementação
cronjobcontroller'faz isso de forma síncrona, fazendo pelo menos uma chamada de API adicional para cada CronJob. Quando o número de CronJob excede um determinado número, essas chamadas de API começam a sofrer restrições do lado do cliente .
O ciclo de pesquisa de 10 segundos e as chamadas de API do lado do cliente levam a um aumento significativo no atraso de inicialização do CronJob.
Agendamento de pods com crons
Devido à natureza da programação cron, a maioria deles é executada no início do minuto (XX: YY: 00). Por exemplo, o
@hourlycron (de hora em hora) é executado às 01:00:00, 02:00:00, etc. No caso de uma plataforma cron multi-tenant com muitos crones em execução a cada hora, a cada quarto de hora, a cada 5 minutos, etc., isso leva a gargalos (pontos de acesso) quando vários crons são iniciados ao mesmo tempo. Nós da Lyft notamos que um desses lugares é o início do expediente (XX: 00: 00). Esses pontos de acesso criam uma carga e levam a uma limitação adicional da frequência de solicitações nos componentes da camada de controle envolvidos na execução do CronJob, como kube-schedulere kube-apiserver, o que leva a um aumento perceptível no atraso de inicialização.
Além disso, se você não provisionar energia de computação para cargas de pico (e / ou usar instâncias de computação do serviço de nuvem) e, em vez disso, usar o mecanismo de escalonamento automático de cluster para escalonar nós dinamicamente, o tempo necessário para iniciar os nós adiciona uma contribuição adicional à latência de inicialização. pods CronJob.
Lançamento do pod: contêineres auxiliares
Uma vez que o pod CronJob foi agendado com sucesso
kubelet, o último deve buscar e executar as imagens de contêiner de todos os sidecars e do próprio aplicativo. Devido às especificações de lançamento de contêineres no Lyft (contêineres secundários começam antes dos contêineres de aplicativos), o atraso no início de qualquer arquivo secundário afetará inevitavelmente o resultado, levando a um atraso adicional no início da tarefa.
Portanto, atrasos na inicialização, antes da execução do código do aplicativo necessário, juntamente com um grande número de CronJobs em um ambiente multilocatário, levam a atrasos de inicialização perceptíveis e imprevisíveis. Como veremos um pouco mais tarde, na vida real, esse atraso pode afetar negativamente o comportamento do CronJob, ameaçando perder lançamentos.
Tratamento de colisões de contêineres
Em geral, é recomendável ficar de olho no trabalho dos crons. Para sistemas Unix, isso é bastante fácil de fazer. Crones Unix interpretam o comando fornecido usando o shell especificado
$SHELL, e depois que o comando sai (com sucesso ou não), aquela chamada em particular é considerada completa. Você pode acompanhar a execução de um cron no Unix usando um script simples como este:
#!/bin/sh
my-cron-command
exitcode=$?
if [[ $exitcode -ne 0 ]]; then
# stat-and-log is pseudocode for emitting metrics and logs
stat-and-log "failure"
else
stat-and-log "success"
fi
exit $exitcode
No caso do Unix, o cron
stat-and-logserá executado exatamente uma vez para cada chamada do cron - independentemente de $exitcode. Portanto, essas métricas podem ser usadas para organizar as notificações mais simples sobre chamadas malsucedidas.
No caso do CronJob Kubernetes, em que as tentativas de repetição em caso de falhas são definidas por padrão, e a própria falha pode ser causada por vários motivos (falha de trabalho ou falha de contêiner), o monitoramento não é tão simples e direto.
Usando um script semelhante no container da aplicação e com Jobs configurados para reiniciar em caso de falha, o CronJob tentará executar a tarefa em caso de falha, gerando métricas e logs no processo, até atingir BackoffLimit(número máximo de tentativas). Assim, um desenvolvedor que tenta determinar a causa de um problema terá que separar uma grande quantidade de "lixo" desnecessário. Além disso, o alerta do script de shell em resposta à primeira falha também pode se tornar um ruído comum no qual é impossível basear outras ações, já que o contêiner do aplicativo pode se recuperar e concluir a tarefa por conta própria com êxito.
Você pode implementar alertas no nível do trabalho, em vez de no nível do contêiner do aplicativo. Para isso, estão disponíveis métricas de nível de API para falhas de trabalho, como
kube_job_status_failedde kube-state-metrics. A desvantagem dessa abordagem é que o engenheiro de plantão só toma conhecimento do problema depois que o Job atinge o “estágio de falha final” e atinge o limite BackoffLimit, o que pode acontecer muito mais tarde do que a primeira falha do container do aplicativo.
CronJob'
Os ciclos de reinicialização e atraso substanciais introduzem latência adicional que pode impedir que o Kubernetes CronJob seja executado novamente. No caso de CronJob's que são chamados com frequência, ou aqueles com tempos de execução significativamente maiores do que o tempo ocioso, esse atraso adicional pode causar problemas com a próxima chamada agendada. Se o CronJob tiver uma política
ConcurrencyPolicy: Forbidque proíba a simultaneidade , o atraso resultará em chamadas futuras não sendo concluídas a tempo e atrasadas.

Um exemplo de linha do tempo (do ponto de vista de um cronjobcontroller) em que o inícioDeadlineSeconds é excedido para um CronJob de hora em hora específico: ele pula seu início agendado e não será chamado até o próximo horário agendado
Há também um cenário mais desagradável (encontramos no Lyft), devido ao qual o CronJob pode pular completamente as chamadas - é quando o CronJob é instalado
startingDeadlineSeconds. Nesse cenário, se o atraso de inicialização exceder startingDeadlineSeconds, o CronJob irá pular totalmente a inicialização.
Além disso, se
ConcurrencyPolicyCronJob estiver definido como Forbid, o ciclo de reinicialização em caso de falha da chamada anterior também pode interferir na próxima chamada CronJob.
Problemas com a operação do Kubernetes CronJob em condições do mundo real
Desde que começamos a migrar tarefas repetitivas de calendário para o Kubernetes, descobriu-se que usar o mecanismo CronJob inalterado leva a momentos desagradáveis, tanto do ponto de vista do desenvolvedor quanto do ponto de vista da equipe da plataforma. Infelizmente, eles começaram a negar os benefícios e benefícios para os quais originalmente escolhemos o Kubernetes CronJob. Logo percebemos que nem os desenvolvedores nem a equipe da plataforma tinham as ferramentas necessárias à disposição para explorar o CronJob e entender seus intrincados ciclos de vida.
Os desenvolvedores tentaram explorar seu CronJob e configurá-los, mas, como resultado, eles nos procuraram com muitas reclamações e perguntas como estas:
- Por que meu cron não está funcionando?
- Parece que meu cron parou de funcionar. Como você pode confirmar se ele está realmente funcionando?
- Não sabia que o cron não estava funcionando e pensei que estava tudo bem.
- Como faço para "consertar" um cron ausente? Não posso simplesmente fazer o login via SSH e executar o comando sozinho.
- Você pode dizer por que este cron parece ter perdido várias execuções entre X e Y?
- Temos X (grande número) crons, cada um com suas próprias notificações, e torna-se bastante tedioso / difícil manter todos eles.
- Pod, Job, side-car - que tipo de bobagem é essa?
Como equipe de plataforma , não fomos capazes de responder a perguntas como:
- Como quantificar o desempenho da plataforma cron do Kubernetes?
- Como a ativação de CronJobs adicionais afetará nosso ambiente Kubernetes?
- Kubernetes CronJob' ( multi-tenant) single-tenant cron' Unix?
- Service-Level-Objectives (SLOs — ) ?
- , , , ?
Depurar falhas do CronJob não é uma tarefa fácil. Geralmente, é preciso intuição para entender onde ocorrem as falhas e onde procurar evidências. Às vezes, essas pistas são muito difíceis de obter - como, por exemplo, registros
cronjobcontroller', que são registrados apenas se o alto nível de detalhe estiver ativado. Além disso, as faixas podem simplesmente desaparecer após um certo período de tempo, o que torna a depuração semelhante ao jogo "toupeira de lucro" (falando sobre isso - canetas aprox ..), - por exemplo, Eventos Kubernetes para CronJob'ov, Job'ov e Pod'ov que, por padrão, são mantidos por apenas uma hora. Nenhum desses métodos é fácil de usar e nenhum deles se adapta bem em termos de suporte à medida que o número de CronJobs na plataforma aumenta.
Além disso, às vezes o Kubernetes apenaspara de tentar executar o CronJob se ele perder muitas execuções. Neste caso, deve ser reiniciado manualmente. Na vida real, isso acontece com muito mais frequência do que você pode imaginar, e a necessidade de corrigir o problema manualmente a cada vez torna-se bastante dolorosa.
Isso conclui meu mergulho nos problemas técnicos e operacionais que encontramos ao usar o Kubernetes CronJob em um projeto movimentado. Na segunda parte, falaremos sobre como eliminamos o Kubernetes em nossa pilha, melhoramos a usabilidade e aumentamos a confiabilidade do CronJob.
Parte 2. Introdução
Ficou claro que o Kubernetes CronJob, inalterado, não pode se tornar um substituto simples e conveniente para suas contrapartes Unix. Para transferir com segurança todos os nossos crones para o Kubernetes, precisávamos não apenas eliminar as deficiências técnicas dos CronJobs, mas também melhorar a usabilidade deles . A saber:
1. Ouça os desenvolvedores para entender as respostas às perguntas sobre as velhas com que eles estão mais preocupados. Por exemplo: meu cron começou? O código do aplicativo foi executado? O lançamento foi bem-sucedido? Quanto tempo o cron rodou? (Quanto tempo o código do aplicativo demorou?)
2. Simplifique a manutenção da plataforma tornando o CronJob mais compreensível, seu ciclo de vida mais transparente e os limites da plataforma / aplicativo mais claros.
3. Complementar nossa plataforma com métricas e alertas padrão para reduzir a quantidade de configuração de alerta customizado e reduzir o número de ligações cron duplicadas que os desenvolvedores precisam escrever e manter.
4. Desenvolva ferramentas para fácil recuperação de falhas e teste de novas configurações do CronJob.
5. Corrija problemas técnicos de longa data no Kubernetes , como um bug TooManyMissedStarts que requer intervenção manual para corrigir e causa uma falha em um cenário de falha crítica ( quando o inícioDeadlineSeconds não está definido ) passando despercebido.
Decisão
Resolvemos todos esses problemas da seguinte maneira:
- (observability). CronJob', (Service Level Objectives, SLOs) .
- CronJob' « » Kubernetes.
- Kubernetes.
CronJob'

Um exemplo de painel gerado pela plataforma para monitorar um CronJob específico
Adicionamos as seguintes métricas à pilha do Kubernetes (elas são definidas para todos os CronJob no Lyft):
1.
started.count- este contador é incrementado quando o contêiner do aplicativo é iniciado pela primeira vez quando o CronJob é chamado. Isso ajuda a responder à pergunta: “ O código do aplicativo foi executado? "
2.
{success, failure}.count- esses contadores são incrementados quando uma determinada chamada CronJob atinge o estado do terminal (ou seja, o trabalho terminou seu trabalho e jobcontrollernão tenta mais executá-lo). Eles respondem à pergunta: “ O lançamento foi bem-sucedido? "
3.
scheduling-decision.{invoke, skip}.count- esses contadorespermitem que você descubra sobre as decisões que são tomadas cronjobcontrollerao chamar o CronJob. Em particular, skip.countajuda a responder à pergunta: “ Por que meu cron não está funcionando? " Os rótulos a seguir atuam como seus parâmetros reason:
-
reason = concurrencyPolicy-cronjobcontrollerperdeu a chamada para o CronJob, pois caso contrário iria interrompê-laConcurrencyPolicy; -
reason = missedDeadline-cronjobcontrollerrecusou-se a chamar o CronJob porque perdeu a janela de chamada especificada.spec.startingDeadlineSeconds; -
reason = errorÉ um parâmetro comum para todos os outros erros que ocorrem ao tentar chamar um CronJob.
4.
app-container-duration.seconds- Este cronômetro mede a vida útil do contêiner do aplicativo. Isso ajuda a responder à pergunta: “Por quanto tempo o código do aplicativo foi executado? " Nesse cronômetro, deliberadamente não incluímos o tempo necessário para agendamento de pods, lançamento de contêineres secundários, etc., pois são responsabilidade da equipe da plataforma e estão incluídos no atraso de lançamento.
5.
start-delay.seconds- Este temporizador mede o atraso de início. Essa métrica, quando agregada em toda a plataforma, permite que os engenheiros que a mantêm não apenas avaliem, monitorem e ajustem o desempenho da plataforma, mas também serve como uma base para determinar SLOs para parâmetros como atraso de inicialização e frequência máxima de cronograma.
Com base nessas métricas, criamos alertas padrão. Eles notificam os desenvolvedores quando:
- Seu CronJob não começou dentro do prazo (
rate(scheduling-decision.skip.count) > 0); - Seu CronJob falhou (
rate(failure.count) > 0).
Os desenvolvedores não precisam mais definir seus próprios alertas e métricas para crons no Kubernetes - a plataforma fornece seus equivalentes prontos.
Executando crons quando necessário
Nós o adaptamos
kubectl create job test-job --from=cronjob/<your-cronjob>para nossa ferramenta CLI interna. Os engenheiros da Lyft o usam para interagir com seus serviços no Kubernetes para chamar o CronJob quando necessário para:
- recuperação de travamentos intermitentes do CronJob;
- runtime- , 3:00 ( , CronJob', Job' Pod' ), — , ;
- runtime- CronJob' Unix cron', , .
TooManyMissedStarts
Temos fixa um bug com TooManyMissedStarts de modo que é agora cronjob não "travar" após 100 partidas perdidas consecutivos. Este patch não apenas remove a necessidade de intervenção manual, mas também permite que você realmente controle quando os tempos são
startingDeadlineSeconds excedidos . Obrigado a Vallery Lancey por projetar e construir este patch, Tom Wanielista por ajudar a projetar o algoritmo. Nós abriu um PR para trazer este patch para o ramo principal Kubernetes (no entanto, nunca foi adotado, e fechou devido à inatividade -. Aprox. Transl) .
Implementando monitoramento cron

Em que fases do ciclo de vida do Kubernetes CronJob adicionamos mecanismos para exportar métricas
Alertas que não dependem de cronogramas
A parte mais complicada da implementação de notificações de chamadas perdidas do cron é lidar com seus cronogramas ( crontab.guru foi útil para decifrá-los ). Por exemplo, considere a seguinte programação:
# 5
*/5 * * * *
Você pode fazer o contador para este incremento cron toda vez que ele sair (ou usar uma ligação cron ). Então, no sistema de notificação, você pode escrever uma expressão condicional no formato: "Veja os 60 minutos anteriores e me avise se o contador aumentar menos de 12". Problema resolvido, certo?
Mas e se sua programação for assim:
# 9 17
# .
# , (9-17, -)
0 9–17 * * 1–5
Nesse caso, você terá que consertar a condição (embora, talvez seu sistema tenha uma função de notificação apenas para o horário comercial?). Seja como for, esses exemplos ilustram que as notificações de vinculação a cronogramas têm várias desvantagens:
- Ao alterar a programação, você deve fazer alterações na lógica de notificação.
- Alguns cronogramas requerem consultas bastante complexas para replicar usando séries temporais.
- É necessário que haja algum tipo de "período de espera" para as velhas que não começam seu trabalho exatamente a tempo de minimizar os falsos positivos.
A etapa 2 sozinha torna a geração de notificações por padrão para todos os crones na plataforma uma tarefa muito difícil, e a etapa 3 é especialmente relevante para plataformas distribuídas como Kubernetes CronJob, nas quais o atraso de inicialização é um fator significativo. Além disso, existem soluções que usam " interruptores de homem morto ", o que mais uma vez nos traz de volta à necessidade de vincular a notificação ao cronograma do cron e / ou algoritmos de detecção de anomalias que requerem algum treinamento e não funcionam imediatamente para novos CronJob ou mudanças em seus calendário.
Outra maneira de ver o problema é se perguntando: o que significa que o cron deveria ter iniciado, mas não foi?
No Kubernetes, se você esquecer os bugs
cronjobcontroller'ou a possibilidade de uma queda no próprio plano de controle (embora você deva ver isso imediatamente se rastrear o estado do cluster corretamente) - isso significa que cronjobcontrollero CronJob avaliou e decidiu (de acordo com a programação do cron) que deveria ser chamado, mas por algum motivo pelo motivo que deliberadamente decidi não fazer .
Soa familiar? Isso é exatamente o que nossa métrica faz
scheduling-decision.skip.count! Agora só precisamos rastrear a alteração rate(scheduling-decision.skip.count)para notificar o usuário de que seu CronJob deveria ter sido acionado, mas não foi.
Esta solução separa a programação cron da notificação em si, fornecendo vários benefícios:
- Agora você não precisa reconfigurar os alertas ao alterar os horários.
- Não há necessidade de solicitações e condições de tempo complexas.
- Você pode gerar facilmente alertas padrão para todos os CronJob na plataforma.
Isso, combinado com outras séries temporais e alertas mencionados anteriormente, ajuda a criar uma imagem mais completa e compreensível do estado do CronJob.
Implementando um temporizador de atraso de início
Devido à natureza complexa do ciclo de vida do CronJob, precisamos considerar cuidadosamente os pontos específicos do posicionamento do kit de ferramentas na pilha para medir essa métrica de forma confiável e precisa. Como resultado, tudo se resumiu a fixar dois pontos no tempo:
- T1: quando o cron deve ser iniciado (de acordo com sua programação).
- T2: quando o código do aplicativo realmente começa a ser executado.
Neste caso
start delay(atraso de início) = 2 — 1. Para corrigir o momento T1, incluímos o código na lógica da chamada do cron no cronjobcontroller'. Ele registra a hora de início esperada como .metadata.Annotationos objetos de trabalho que cronjobcontrollercria quando o CronJob é chamado. Agora ele pode ser recuperado usando qualquer cliente API usando uma solicitação normal GET Job.
Tudo ficou mais complicado com o T2. Como precisamos obter o valor o mais próximo possível do real, T2 deve coincidir com o momento em que o contêiner com o aplicativo é iniciado pela primeira vez . Se você atirar em T2 em qualquerquando o contêiner é iniciado (incluindo reinicializações), atrasar a inicialização, neste caso, incluirá o tempo de execução do próprio aplicativo. Portanto, decidimos atribuir outro
.metadata.Annotationobjeto Job sempre que descobrimos que o container do aplicativo para um determinado Job primeiro recebeu um status Running. Assim, em essência, um bloqueio distribuído foi criado e as futuras inicializações do contêiner de aplicativos para este Job foram ignoradas (apenas o momento da primeira inicialização foi salvo ).
resultados
Depois de lançar novas funcionalidades e corrigir bugs, recebemos muitos comentários positivos dos desenvolvedores. Agora, desenvolvedores que usam nossa plataforma Kubernetes CronJob:
- não precisam mais se preocupar com suas próprias ferramentas de monitoramento e alertas;
- , CronJob' , .. alert' , ;
- CronJob' , CronJob' « »;
- (
app-container-duration.seconds).
Além disso, os engenheiros de manutenção da plataforma agora têm um novo parâmetro ( atraso de início ) para medir a experiência do usuário e o desempenho da plataforma.
Finalmente (e talvez nossa maior vitória), ao tornar o CronJob (e seus estados) mais transparentes e rastreáveis, simplificamos bastante o processo de depuração para desenvolvedores e engenheiros de plataforma. Eles agora podem depurar juntos usando os mesmos dados, então muitas vezes acontece que os desenvolvedores encontram o problema por conta própria e o resolvem usando as ferramentas fornecidas pela plataforma.
Conclusão
Orquestrar tarefas distribuídas e agendadas não é fácil. O CronJob Kubernetes é apenas uma maneira de organizá-lo. Embora estejam longe do ideal, os CronJobs são bastante capazes de trabalhar em projetos globais, se, é claro, você estiver pronto para investir tempo e esforço em aprimorá-los: aumentando a observabilidade, entendendo as causas e as especificidades das falhas e complementando com ferramentas que facilitam o uso.
Observação: há uma proposta de aprimoramento do Kubernetes (KEP) aberta para corrigir as deficiências do CronJob e traduzir sua versão atualizada para o GA.
Agradecemos a Rithu John , Scott Lau, Scarlett Perry , Julien Silland e Tom Wanielista por sua ajuda na revisão desta série de artigos.
PS do tradutor
Leia também em nosso blog: