
Os últimos anos de aprendizado profundo têm sido uma série contínua de conquistas: desde derrotar pessoas no jogo Go até a liderança mundial em reconhecimento de imagem, reconhecimento de voz, tradução de texto e outras tarefas. Mas esse progresso foi acompanhado por um aumento insaciável no apetite por poder de computação. Um grupo de cientistas do MIT, da Yeonse University (Coreia) e da Brasília University publicou uma meta-análise de 1.058 artigos científicos sobre aprendizado de máquina . Isso mostra claramente que o progresso no aprendizado de máquina (ML) é um derivado do poder de computação do sistema . O desempenho do computador sempre limitou a funcionalidade do ML, mas agora as necessidades dos novos modelos de ML estão crescendo muito mais rápido do que o desempenho do computador.
O estudo demonstra que os avanços no aprendizado de máquina são, na verdade, pouco mais que uma consequência da Lei de Moore. E por este motivo, muitos problemas de ML nunca serão resolvidos devido às limitações físicas do computador.
Os pesquisadores analisaram artigos científicos sobre classificação de imagens (ImageNet), reconhecimento de objetos (MS COCO), respostas a perguntas (SQuAD 1.1), reconhecimento de entidades nomeadas (COLLN 2003) e tradução automática (WMT 2014 En-to-Fr).

Consultas de computação ML, escala de log O
progresso em todas as cinco áreas mostrou ser altamente dependente do aumento da capacidade de computação. Extrapolar essa relação deixa claro que o progresso nessas áreas está rapidamente se tornando econômica, técnica e ambientalmente insustentável. Assim, um maior progresso nessas aplicações exigirá métodos computacionalmente mais eficientes.
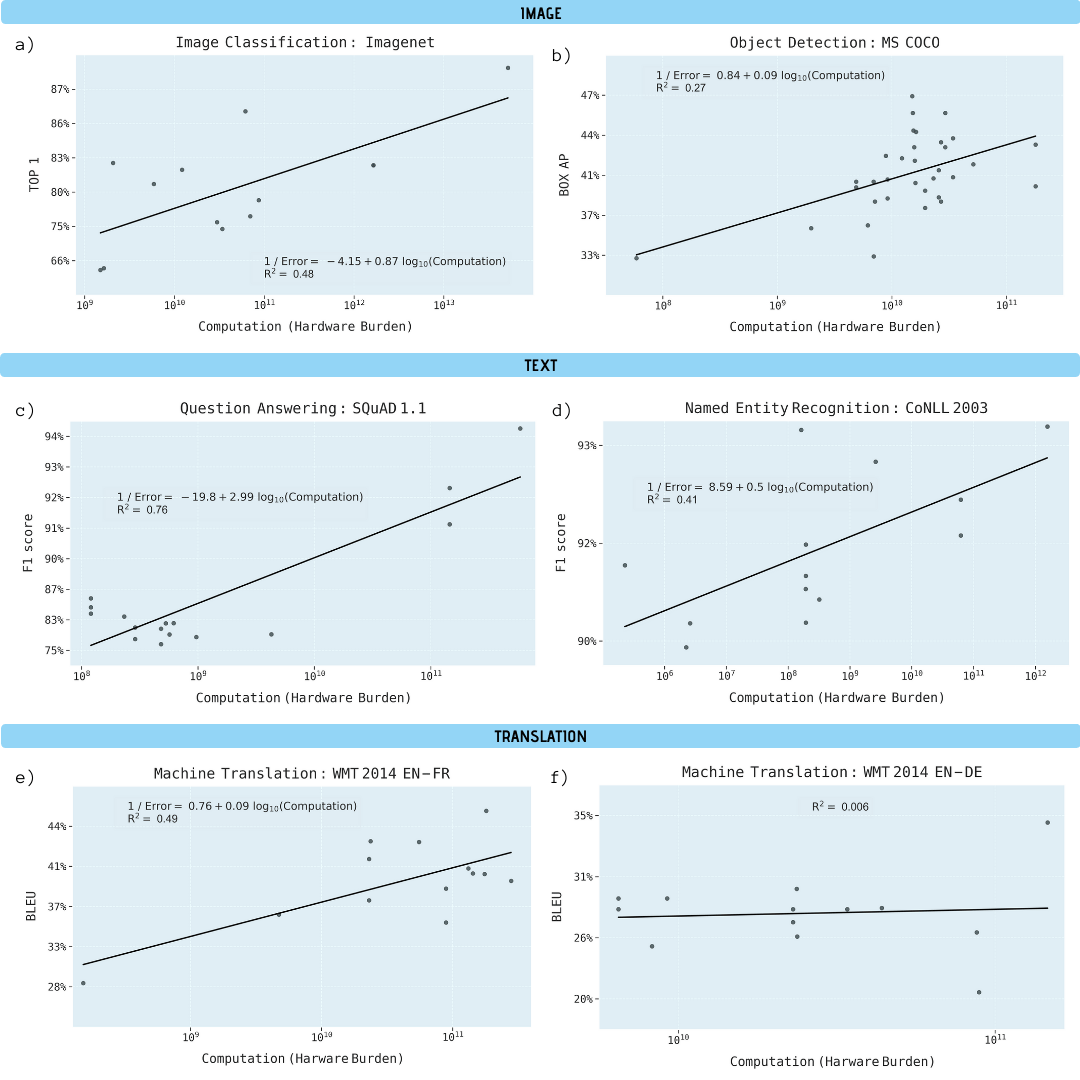
Melhoria de desempenho em várias tarefas de aprendizado de máquina em função do poder computacional do modelo de aprendizado (em gigaflops)
Por que o aprendizado de máquina é tão dependente do poder computacional
Existem razões importantes para acreditar que o aprendizado profundo é inerentemente mais dependente do computador do que outros métodos. Em particular, devido ao papel da hiperparametrização e como o sistema é ampliado, quando dados de treinamento adicionais são usados para melhorar a qualidade do resultado (por exemplo, para reduzir a taxa de erros de classificação, o erro quadrático médio da raiz da regressão, etc.).
Está comprovado que vantagens significativas são proporcionadas pela hiperparametrização, ou seja, a implementação de redes neurais com o número de parâmetros maior do que o número de pontos de dados disponíveis para seu treinamento. Classicamente, isso levaria ao overfitting. Mas as técnicas de otimização de gradiente estocástico fornecem um efeito de regularização às custas de uma parada precoce, colocando as redes neurais no modo de interpolação onde os dados de treinamento se ajustam quase exatamente, enquanto mantém previsões razoáveis nos pontos intermediários. Um exemplo de redes de grande escala com hiperparametrização é um dos melhores sistemas de reconhecimento de padrões NoisyStudent , que possui 480 milhões de parâmetros para 1,2 milhão de pontos de dados ImageNet.
O problema da hiperparametrização é que o número de parâmetros de aprendizado profundo deve crescer conforme o número de pontos de dados aumenta. Como o custo de treinamento de um modelo de aprendizado profundo é dimensionado com o produto do número de parâmetros e do número de pontos de dados, isso significa que o requisito computacional cresce pelo menos o quadrado do número de pontos de dados em um sistema hiperparametrizado. O escalonamento quadrático ainda não estima suficientemente a velocidade com que as redes de aprendizado profundo precisam crescer, uma vez que a quantidade de dados de treinamento deve escalar muito mais rápido do que linearmente para obter melhorias de desempenho linear.
Considere um modelo gerador que tenha 10 valores diferentes de zero entre 1000 possíveis e considere quatro modelos para tentar descobrir esses parâmetros:
- : 10
- : 9 1
- : 1000 ,
- : , 1000 , ()
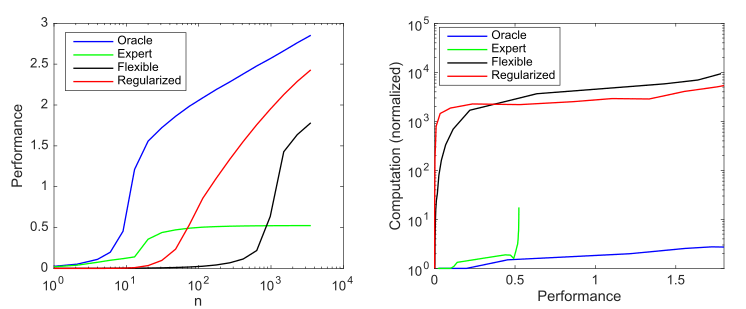
Impacto da complexidade e regularização do modelo no desempenho do modelo (medido como erro quadrático médio normalizado log 10 negativo versus o preditor ótimo) e nos requisitos computacionais em média acima de 1000 simulações por caso; a) produtividade média conforme o tamanho da amostra aumenta; b) Cálculo médio necessário para melhorar o desempenho
Este gráfico resume o princípio descrito por Andrew Ng: Os métodos tradicionais de aprendizado de máquina funcionam melhor com pequenos dados, mas os modelos de ML flexíveis funcionam melhor com big data. Um fenômeno comum dos modelos ágeis é que eles têm um potencial maior, mas também têm muito mais dados e necessidades computacionais.
Podemos ver que o aprendizado profundo funciona bem porque usa hiperparametrização para criar um modelo muito flexível e regularização (implícita) para reduzir a complexidade da amostra a níveis aceitáveis. Ao mesmo tempo, no entanto, o aprendizado profundo é significativamente mais intensivo em termos de computação do que os modelos mais eficientes. Assim, aumentar a flexibilidade do ML implica na dependência de grandes quantidades de dados e computação.
Limites computacionais
O desempenho do computador sempre limitou o poder dos sistemas de ML.
Por exemplo, Frank Rosenblatt descreveu a primeira rede neural de três camadas em 1960. Esperava-se que ela "demonstrasse as possibilidades de usar o perceptron como um dispositivo de reconhecimento de padrões". Mas Rosenblatt descobriu que "conforme o número de conexões na rede aumenta, a carga em um computador digital típico logo se torna excessiva". Mais tarde, em 1969, Minsky e Papert explicaram as limitações das redes de 3 camadas, incluindo a incapacidade de aprender uma função XOR simples. Mas eles notaram uma solução potencial: “Os experimentadores encontraram uma maneira interessante de contornar essa dificuldade introduzindo cadeias mais longas de unidades intermediárias” (ou seja, construindo redes neurais mais profundas). Apesar dessa possível solução alternativa, grande parte do trabalho acadêmico nessa área foi abandonado.porque naquela época simplesmente não havia poder de computação suficiente.
Nas décadas seguintes, as melhorias no hardware resultaram em ganhos de desempenho de cerca de 50.000 vezes, e as redes neurais aumentaram proporcionalmente suas necessidades computacionais, conforme mostrado no KDPV. Como o aumento de um dólar no poder de computação quase igualou o poder de computação por chip, os custos econômicos de execução de tais modelos permaneceram estáveis ao longo do tempo.
Apesar dessa aceleração significativa da CPU, os modelos de aprendizado profundo ainda eram muito lentos para aplicativos de grande escala em 2009. Isso forçou os pesquisadores a se concentrar em modelos em escala menor ou usar menos exemplos de treinamento.
O ponto de inflexão foi a transferência do aprendizado profundo para a GPU, que imediatamente acelerou5-15 vezes , que em 2012 havia crescido para 35 vezes e que levou a uma importante vitória da AlexNet na competição Imagenet 2012 . Mas o reconhecimento de imagem foi apenas o primeiro benchmark em que os sistemas de aprendizado profundo venceram. Eles logo venceram na detecção de objetos, chamados de reconhecimento de entidades, tradução automática, resposta a perguntas e reconhecimento de fala.
A adoção de aprendizado profundo em GPUs (e depois ASICs) levou à adoção generalizada desses sistemas. Mas a quantidade de capacidade de computação em sistemas de ML modernos cresceu ainda mais rápido, cerca de 10 vezes por ano de 2012 a 2019. Essa velocidade é muito mais rápida do que a melhoria geral da mudança para as GPUs, o ganho modesto do último suspiro da Lei de Moore ou do aumento da eficiência do treinamento de redes neurais.
Em vez disso, o principal ganho em eficiência de ML veio da execução de modelos por períodos mais longos em mais máquinas. Por exemplo, em 2012, o AlexNet treinou em duas GPUs por 5 a 6 dias, em 2017 o ResNeXt-101 treinou em oito GPUs por mais de 10 dias e em 2019 o NoisyStudent treinou em cerca de mil TPUs por 6 dias. Outro exemplo extremo é o sistema de tradução automática Evolved Transformer , que usou mais de 2 milhões de horas de GPU em treinamento, que custou milhões de dólares.
O escalonamento dos cálculos de aprendizado profundo aumentando os relógios de hardware ou mais chips é problemático no longo prazo. Porque implica que os custos são escalonados aproximadamente na mesma taxa que os aumentos no poder de computação, e isso torna rapidamente impossível um crescimento posterior.
Futuro
Triste conclusão do exposto.
A tabela a seguir mostra quanto poder computacional e custo do sistema atingirão certos objetivos em problemas de ML, se extrapolarmos a partir dos modelos atuais. As tarefas de aprendizado de máquina serão executadas nos supercomputadores mais poderosos. Os autores do trabalho científico acreditam que os requisitos para os objetivos traçados não serão cumpridos . Embora estejam considerando opções teoricamente possíveis para alcançá-los: melhorar a eficiência sem aumentar o desempenho, aceleradores de hardware como TPU e FPGA, computação neuromórfica, computação quântica e outros, nenhuma dessas tecnologias (ainda) permite superar os limites computacionais do ML.

. .
